









مقدمه
برنامه های کاربردی وب مدرن را می توان با یکپارچه سازی هوش مصنوعی به سطح بعدی ارتقا داد. این آموزش بر روی توسعه پیشرفته رباتهای چند وجهی تمرکز دارد که از پردازش زبان طبیعی، تولید تصویر و تشخیص گفتار استفاده میکنند. این ربات ها تجربه کاربری منحصر به فردی را ارائه می دهند و کاربران را از طریق حالت های مختلف تعامل درگیر می کنند.
این آموزش به توسعه یک ربات چند وجهی با استفاده از مدل زبان بزرگ جنگو و OpenAI برای هوش مصنوعی مکالمهای، Whisper برای رونویسی دقیق گفتار و DALL-E برای تولید تصویر میپردازد. ساخت یک برنامه وب را توصیف می کند که داستان هایی را با تصاویر همراه آنها تولید می کند. کاربران می توانند موضوع داستان را با صدا یا متن مشخص کنند و برنامه با یک داستان تولید شده که با تصاویر بصری تزئین شده است پاسخ می دهد.
در پایان این آموزش، شما یک برنامه کاربردی ایجاد کرده اید که می تواند ورودی های کاربر را به اشکال مختلف از جمله متن، صدا و تصویر درک کند و به آن پاسخ دهد. این به طور قابل توجهی تعامل کاربر با برنامه را افزایش می دهد و آن را بصری تر و در دسترس تر می کند.
پیش نیازها
- درک اولیه پایتون و جنگو
- یک کلید OpenAI API: این آموزش از شما میخواهد با مدلهای GPT-4 و DALL-E OpenAI تعامل داشته باشید، که به یک کلید API از OpenAI نیاز دارند.
- Whisper
- بسته OpenAI Python
هنگامی که محیط شما فعال است، برای نصب بسته OpenAI Python، موارد زیر را اجرا کنید:
(env)sammy@ubuntu:$ pip install openaiمرحله 1 – یکپارچه سازی OpenAI Whisper برای تشخیص گفتار
در این مرحله، OpenAI Whisper را در برنامه جنگو خود راهاندازی میکنید تا به آن اجازه دهید گفتار را به متن رونویسی کند. Whisper یک مدل تشخیص گفتار قوی است که میتواند رونویسیهای دقیقی را ارائه دهد، یک ویژگی مهم برای ربات چند وجهی ما. با یکپارچه سازی Whisper، برنامه ما قادر خواهد بود ورودی های کاربر ارائه شده از طریق صدا را درک کند.
ابتدا مطمئن شوید که در دایرکتوری پروژه جنگو کار می کنید. پس از آموزش های پیش نیاز، باید یک پروژه جنگو را برای این ادغام آماده کنید. ترمینال خود را باز کنید، به فهرست پروژه جنگو بروید و مطمئن شوید که محیط مجازی شما فعال است:
sammy@ubuntu:$ cd path_to_your_django_project
sammy@ubuntu:$ source env/bin/activateراه اندازی Whisper در برنامه جنگو شما
کاری که اکنون باید انجام شود ایجاد تابعی است که از Whisper برای رونویسی فایل های صوتی به متن استفاده می کند. یک فایل پایتون جدید با نام whisper_transcribe.py ایجاد کنید.
(env)sammy@ubuntu:$ touch whisper_transcribe.pywhisper_transcribe.py را در ویرایشگر متن خود باز کنید و Whisper را وارد کنید. سپس، اجازه دهید تابعی را تعریف کنیم که مسیر یک فایل صوتی را به عنوان ورودی می گیرد، از Whisper برای پردازش فایل استفاده می کند و سپس رونویسی را برمی گرداند:
import whisper
model = whisper.load_model("base")
def transcribe_audio(audio_path):
result = model.transcribe(audio_path)
return result["text"]در این قطعه کد، از مدل “پایه” برای رونویسی استفاده می کنید. Whisper مدلهای مختلفی را با توجه به نیازهای مختلف دقت و عملکرد ارائه میکند. به راحتی می توانید مدل های دیگر را بر اساس نیاز خود آزمایش کنید.
تست رونویسی
برای آزمایش رونویسی، یک فایل صوتی را در فهرست راهنمای پروژه جنگو خود ذخیره کنید. اطمینان حاصل کنید که فایل دارای فرمتی است که Whisper پشتیبانی می کند (مانند MP3، WAV). اکنون، whisper_transcribe.py را با افزودن خطوط زیر در پایین تغییر دهید:
# For testing purposes
if __name__ == "__main__":
print(transcribe_audio("path_to_your_audio_file"))whisper_transcribe.py را با پایتون اجرا کنید تا رونویسی فایل صوتی خود را در ترمینال خود مشاهده کنید:
(env)sammy@ubuntu:$ python whisper_transcribe.pyاگر همه چیز به درستی تنظیم شده باشد، باید خروجی متن رونویسی شده را در ترمینال ببینید. این قابلیت به عنوان پایه ای برای تعاملات مبتنی بر صدا در ربات ما عمل می کند.
مرحله 2 – ایجاد پاسخ های متنی با GPT-4
در این مرحله، از GPT-4 LLM برای تولید پاسخ های متنی بر اساس ورودی کاربر یا رونویسی گفتار به دست آمده در مرحله قبل استفاده می کنید. GPT-4، با مدل زبان بزرگ خود، میتواند پاسخهای منسجم و مرتبط با زمینه ایجاد کند، و آن را به یک انتخاب ایدهآل برای برنامه ربات چندوجهی ما تبدیل میکند.
قبل از ادامه، اطمینان حاصل کنید که بسته OpenAI Python در محیط مجازی شما همانطور که در پیش نیازها توضیح داده شده است، نصب شده است. مدل GPT-4 برای دسترسی به کلید API نیاز دارد، بنابراین مطمئن شوید که آن را آماده کرده اید. می توانید کلید OpenAI API را به متغیرهای محیطی خود اضافه کنید تا مستقیماً آن را به فایل پایتون اضافه نکنید:
(env)sammy@ubuntu:$ export OPENAI_KEY="your-api-key"راه اندازی تکمیل چت
به دایرکتوری برنامه جنگو خود بروید و یک فایل پایتون جدید با نام chat_completion.py ایجاد کنید. این اسکریپت ارتباط با مدل GPT-4 را برای ایجاد پاسخ بر اساس متن ورودی انجام می دهد.
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_story(input_text):
# Call the OpenAI API to generate the story
response = get_story(input_text)
# Format and return the response
return format_response(response)این قطعه کد ابتدا کلید API لازم برای احراز هویت با خدمات OpenAI را تنظیم می کند. سپس یک تابع جداگانه، get_story را فراخوانی میکند تا API را با OpenAI برای داستان و سپس تابع دیگری به نام format_response را برای قالببندی پاسخ API فراخوانی کند.
حالا بیایید روی تابع get_story تمرکز کنیم. موارد زیر را به پایین فایل chat_completion.py خود اضافه کنید:
def get_story(input_text):
# Construct the system prompt. Feel free to experiment with different prompts.
system_prompt = f"""You are a story generator.
You will be provided with a description of the story the user wants.
Write a story using the description provided."""
# Make the API call
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": input_text},
],
temperature=0.8
)
# Return the API response
return responseدر این تابع، ابتدا دستور سیستم را تنظیم میکنید، که مدل را در مورد وظیفهای که باید انجام دهد، مطلع میکند و سپس از ChatCompletion API درخواست میکنید تا با استفاده از متن ورودی کاربر، داستانی تولید کند.
در نهایت می توانید تابع format_response را پیاده سازی کنید. موارد زیر را به پایین فایل chat_completion.py خود اضافه کنید:
def format_response(response):
# Extract the generated story from the response
story = response.choices[0].message.content
# Remove any unwanted text or formatting
story = story.strip()
# Return the formatted story
return storyتست پاسخ های تولید شده
برای آزمایش تولید متن، chat_completion.py را با افزودن چند خط در پایین تغییر دهید:
# For testing purposes
if __name__ == "__main__":
user_input = "Tell me a story about a dragon"
print(generate_story(user_input))برای مشاهده پاسخ تولید شده در ترمینال خود، chat_completion.py را با پایتون اجرا کنید:
(env)sammy@ubuntu:$ python chat_completion.pyبر اساس اعلان، شما باید یک پاسخ خلاقانه از GPT-4 را مشاهده کنید. با ورودی های مختلف آزمایش کنید تا پاسخ های مختلف را ببینید.
در مرحله بعد تصاویری را به استوری های تولید شده اضافه می کنید.
مرحله 3 – تولید تصاویر با DALL-E
DALL-E برای ایجاد تصاویر دقیق از پیامهای متنی طراحی شده است و ربات چند وجهی شما را قادر میسازد تا داستانها را با خلاقیت بصری تقویت کند.
یک فایل پایتون جدید با نام image_generation.py در برنامه جنگو خود ایجاد کنید. این اسکریپت از مدل DALL-E برای تولید تصویر استفاده می کند:
(env)sammy@ubuntu:$ touch image_generation.pyبیایید یک تابع در image_generation.py ایجاد کنیم که یک اعلان به DALL-E می فرستد و تصویر تولید شده را بازیابی می کند:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_image(text_prompt):
response = client.images.generate(
model="dall-e-3",
prompt=text_prompt,
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
return image_urlاین تابع درخواستی را به مدل DALL-E ارسال میکند که دستور متن، تعداد تصاویر تولید شده (n=1) و اندازه تصاویر را مشخص میکند. سپس URL تصویر تولید شده را استخراج و برمی گرداند.
تست اسکریپت
برای نشان دادن استفاده از این تابع در پروژه جنگو، می توانید مثال زیر را در پایین فایل image_generation.py خود اضافه کنید:
# For testing purposes
if __name__ == "__main__":
prompt = "Generate an image of a pet and a child playing in a yard."
print(generate_image(prompt))image_generation.py را با پایتون اجرا کنید تا یک تصویر بر اساس دستور داده شده ایجاد کنید:
(env)sammy@ubuntu:$ python image_generation.pyاگر اسکریپت با موفقیت اجرا شود، URL تصویر تولید شده را در ترمینال خواهید دید. سپس می توانید تصویر را با پیمایش به این URL در مرورگر وب خود مشاهده کنید.
در مرحله بعدی، تشخیص گفتار را همراه با تولید متن و تصویر برای یک تجربه کاربری یکپارچه خواهید آورد.
مرحله 4 – ترکیب روش ها برای یک تجربه یکپارچه
در این مرحله، قابلیتهای توسعهیافته در مراحل قبلی را برای ارائه یک تجربه کاربری یکپارچه یکپارچه خواهید کرد.
برنامه وب شما قادر به پردازش متن و ورودی صوتی کاربران، تولید داستان و تکمیل آنها با تصاویر مرتبط خواهد بود.
ایجاد نمای یکپارچه
ابتدا، مطمئن شوید که پروژه جنگو شما سازماندهی شده است و whisper_transcribe.py، chat_completion.py، و image_generation.py را در فهرست برنامه جنگو دارید. اکنون یک نمای ایجاد خواهید کرد که این اجزا را ترکیب می کند.
فایل views.py خود را باز کنید و ماژول ها و توابع لازم را وارد کنید. سپس یک نمای جدید به نام get_story_from_description ایجاد کنید:
import uuid
from django.core.files.storage import FileSystemStorage
from django.shortcuts import render
from .whisper_transcribe import transcribe_audio
from .chat_completion import generate_story
from .image_generation import generate_image
# other views
def get_story_from_description(request):
context = {}
user_input = ""
if request.method == "GET":
return render(request, "story_template.html")
else:
if "text_input" in request.POST:
user_input += request.POST.get("text_input") + "\n"
if "voice_input" in request.FILES:
audio_file = request.FILES["voice_input"]
file_name = str(uuid.uuid4()) + (audio_file.name or "")
FileSystemStorage(location="/tmp").save(file_name, audio_file)
user_input += transcribe_audio(f"/tmp/{file_name}")
generated_story = generate_story(user_input)
image_prompt = (
f"Generate an image that visually illustrates the essence of the following story: {generated_story}"
)
image_url = generate_image(image_prompt)
context = {
"user_input": user_input,
"generated_story": generated_story.replace("\n", "<br/>"),
"image_url": image_url,
}
return render(request, "story_template.html", context)این نما متن و/یا ورودی صوتی را از کاربر بازیابی می کند. اگر فایل صوتی وجود داشته باشد، آن را با یک نام منحصر به فرد (با استفاده از کتابخانه uuid) ذخیره می کند و از تابع transcribe_audio برای تبدیل گفتار به متن استفاده می کند. سپس از تابعgene_story برای تولید یک پاسخ متنی و تابعgene_image برای تولید یک تصویر مرتبط استفاده می کند. این خروجی ها به فرهنگ لغت متن ارسال می شوند، سپس با story_template.html ارائه می شوند.
ایجاد الگو
سپس یک فایل به نام story_template.html ایجاد کنید و موارد زیر را اضافه کنید:
<div style="padding:3em; font-size:14pt;">
<form method="post" enctype="multipart/form-data">
{% csrf_token %}
<textarea name="text_input" placeholder=" Describe the story you would like" style="width:30em;"></textarea>
<br/><br/>
<input type="file" name="voice_input" accept="audio/*" style="width:30em;">
<br/><br/>
<input type="submit" value="Submit" style="width:8em; height:3em;">
</form>
<p>
<strong>{{ user_input }}</strong>
</p>
{% if image_url %}
<p>
<img src="{{ image_url }}" alt="Generated Image" style="max-width:80vw; width:30em; height:30em;">
</p>
{% endif %}
{% if generated_story %}
<p>{{ generated_story | safe }}</p>
{% endif %}
</div>این فرم ساده به کاربران اجازه می دهد تا درخواست های خود را از طریق متن یا با بارگذاری یک فایل صوتی ارسال کنند. سپس متن و تصویر تولید شده توسط برنامه را نمایش می دهد.
ایجاد URL برای View
اکنون که نمای get_story_from_description را آماده کرده اید، باید با ایجاد یک پیکربندی URL، آن را در دسترس قرار دهید.
فایل urls.py خود را در برنامه جنگو باز کنید و یک الگو برای نمای get_story_from_description اضافه کنید:
from django.urls import path
from . import views
urlpatterns = [
# other patterns
path('generate-story/', views.get_story_from_description, name='get_story_from_description'),
]آزمایش تجربه یکپارچه
اکنون می توانید از http://your_domain/generate-story/ در مرورگر وب خود بازدید کنید. باید فرم تعریف شده در story_template.html را ببینید. سعی کنید یک درخواست متنی را از طریق قسمت ورودی متن ارسال کنید یا یک فایل صوتی را با استفاده از ورودی فایل آپلود کنید. پس از ارسال، درخواست شما ورودی(های) را پردازش می کند، یک داستان و یک تصویر همراه ایجاد می کند و آنها را در صفحه نمایش می دهد.
به عنوان مثال، در اینجا یک داستان نمونه برای درخواست وجود دارد: “به من داستانی در مورد یک حیوان خانگی و یک کودک در حال بازی در حیاط بگو.”
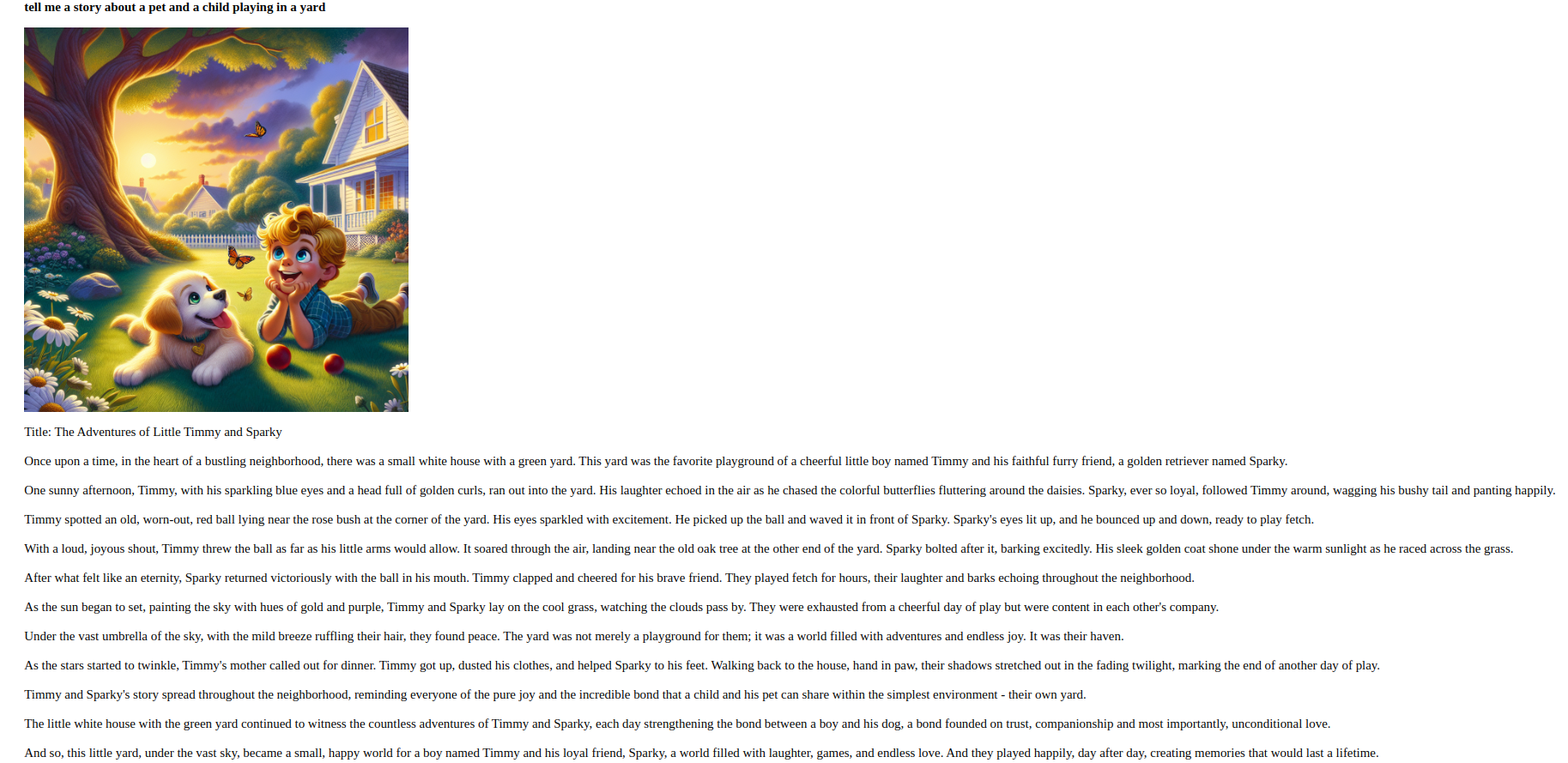
با تکمیل این مرحله، برنامهای ایجاد کردهاید که ورودیهای کاربر را به اشکال مختلف پردازش میکند و به آنها پاسخ میدهد.
نتیجه
در این آموزش، شما با موفقیت یک ربات چند وجهی با استفاده از جنگو، با قابلیت های یکپارچه سازی Whisper برای تشخیص گفتار، GPT-4 برای تولید متن و DALL-E برای تولید تصویر، توسعه داده اید. برنامه شما اکنون می تواند ورودی های کاربر را در قالب های مختلف درک کند و به آن واکنش نشان دهد.
برای توسعه بیشتر، توصیه میشود نسخههای جایگزین مدلهای Whisper، GPT و DALL-E را بررسی کنید، طراحی UI/UX برنامهتان را بهبود ببخشید، یا عملکرد ربات را برای گنجاندن ویژگیهای تعاملی اضافی گسترش دهید.









