

Amazon S3 Simple Storage Service is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means that customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases such as data lakes, websites, mobile applications, backup and recovery, archiving, enterprise applications, IoT devices, and large data analytics. Amazon S3 provides you with easy-to-use management features so you can organize your data and set fine-grained access controls to meet your specific business, organizational, and compliance needs. Amazon S3 is designed for 99.999999999% (11 9) uptime and stores data for millions of applications for companies around the world.
Amazon S3
Object storage built to store and retrieve any amount of data from anywhere
benefits
Unparalleled Security, Compliance, and Auditing Capabilities
Store your data in Amazon S3 and secure it from unauthorized access with encryption features and access management tools. S3 is the only object storage service that lets you block public access to all your objects at the bucket or account level with S3 Block Public Access. S3 maintains compliance programs such as PCI-DSS, HIPAA/HITECH, FedRAMP, the EU Data Protection Directive, and FISMA to help you meet regulatory requirements. S3 integrates with Amazon Macie to discover and protect your sensitive data. AWS also supports numerous auditing capabilities to monitor requests to access your S3 resources.
A wide range of affordable storage classes
Save money by storing data in S3 storage classes that support different levels of data access at a corresponding rate, without sacrificing performance. You can use S3 storage class analysis to identify data that needs to be moved to a lower-cost storage class based on access patterns, and configure S3 lifecycle policies to enforce the move. You can also store data with changing or unknown access patterns in S3 Intelligent-Tiering, which classifies objects based on changing access patterns and automatically delivers cost savings. With the S3 Outposts storage class, you can meet data residency requirements and store data in Outposts using S3 in an Outposts environment.
Leading performance, scalability, availability, and durability
Scaling up and down your storage resources to meet changing demands without upfront investment or resource cycles. Amazon S3 is designed for 99.999999999% (11 9) data durability because it automatically creates and stores copies of all S3 objects on multiple systems. This means your data is available when you need it and is protected from failures, errors, and threats. Amazon S3 also offers strong read-after-write consistency automatically, at no cost, and without any change in performance or availability.
Easily manage data and access controls
S3 gives you powerful capabilities for managing access, cost, replication, and data protection. S3 Access Points make it easy to manage data access with specific permissions for your applications using a shared dataset. S3 Replication manages data replication across regions or regions. S3 Batch Operations helps manage large-scale changes to billions of objects. S3 Storage Lens provides an organization with visibility into object storage usage and activity trends. Because S3 is AWS Lambda works, you can log activities, define alerts, and automate workflows without managing additional infrastructure.
On-Premise Analytics Services for Analytics
Perform big data analytics across your S3 objects (and other datasets in AWS) with On-Premise Search Services. To analyze data stored in your AWS data warehouses and S3 resources, use Amazon Athena to search S3 data with standard SQL expressions and Amazon Redshift Spectrum. You can also use S3 Select to retrieve subsets of object data, instead of the entire object, and improve query performance by up to 400%.
Easily manage data and access controls
S3 gives you powerful capabilities for managing access, cost, replication, and data protection. S3 Access Points make it easy to manage data access with specific permissions for your applications using a shared dataset. S3 Replication manages data replication across regions or regions. S3 Batch Operations helps manage large-scale changes to billions of objects. S3 Storage Lens provides an organization with visibility into object storage usage and activity trends. Because S3 works with AWS Lambda, you can log activities, define alerts, and automate workflows without managing additional infrastructure.
How to - S3 Features
Get a holistic view of your organization on storage usage, activity trends, and get actionable recommendations
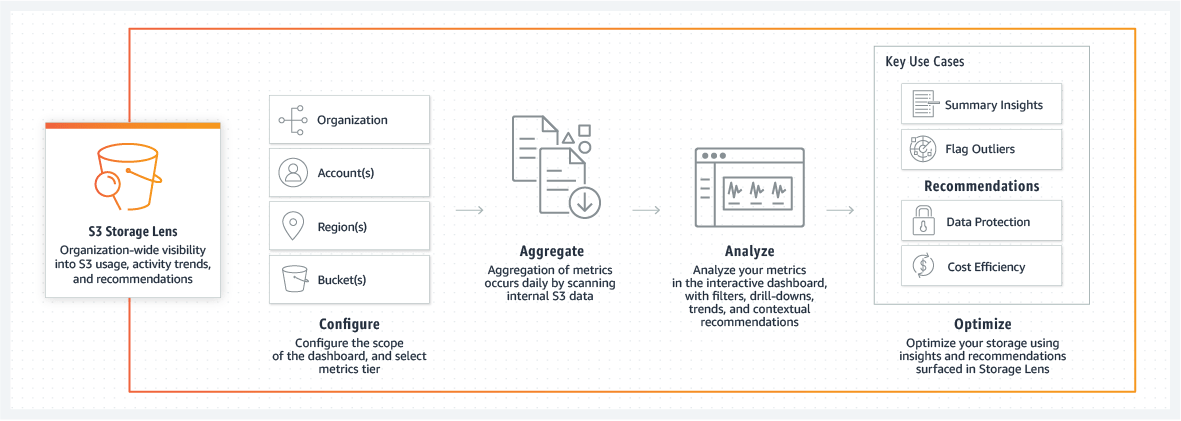
S3 Storage Lens provides enterprise-wide visibility into object storage usage, activity trends, and provides actionable recommendations to improve cost efficiency and implement data protection best practices. S3 Storage Lens is the first cloud storage analytics solution that can provide a single view of object storage usage and activity across hundreds or even thousands of accounts in an organization, with drill-down to provide insights at the account, bucket, or even prefix level. S3 Storage Lens analyzes metrics across the entire organization to provide contextual recommendations to find ways to reduce storage costs and implement data protection best practices.
After enabling S3 Storage Lens in the S3 console, you’ll receive an interactive dashboard containing pre-configured views to visualize storage usage and activity trends, with contextual recommendations that make it easy to take action. You can also export metrics to an S3 bucket in CSV or Parquet format. You can use the Summary view, Cost-optimized view, or Data Protection view to see metrics relevant to your use case. In addition to the dashboard in the S3 console, you can export metrics in CSV or Parquet format to your desired S3 bucket for further use.
Optimize Storage Costs with S3 Intelligent-Tiering
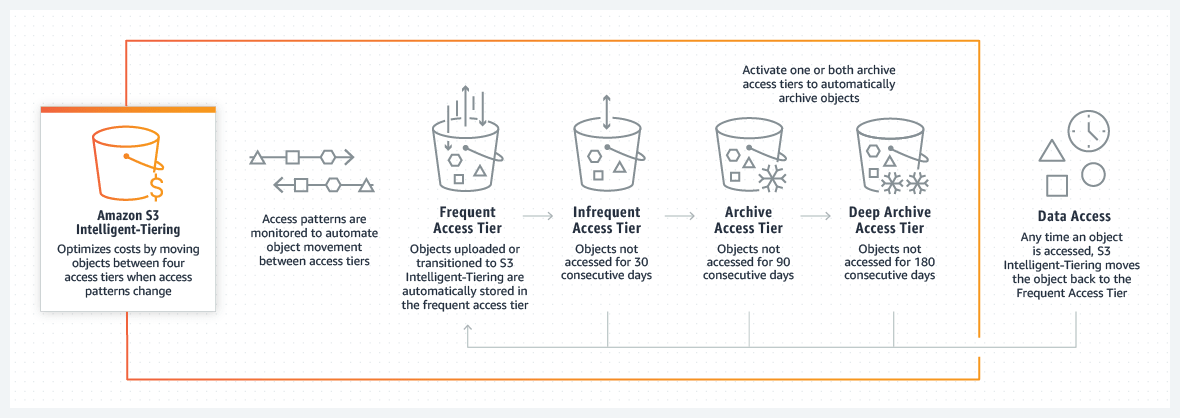
Objects uploaded or moved to S3 Intelligent-Tiering are automatically stored in the frequent access tier. S3 Intelligent-Tiering works by monitoring access patterns and then moving objects that have not been accessed for 30 consecutive days to the infrequent access tier. When you enable one or both of the archive access levels, S3 Intelligent-Tiering moves objects that have not been accessed for 90 consecutive days to the Archive Access level, and then to the Deep Archive Access tier after 180 consecutive days of inaccessibility. If you access the objects later, S3 Intelligent-Tiering moves the objects back to the Frequent Access level.
Easily manage access to shared datasets with S3 Access
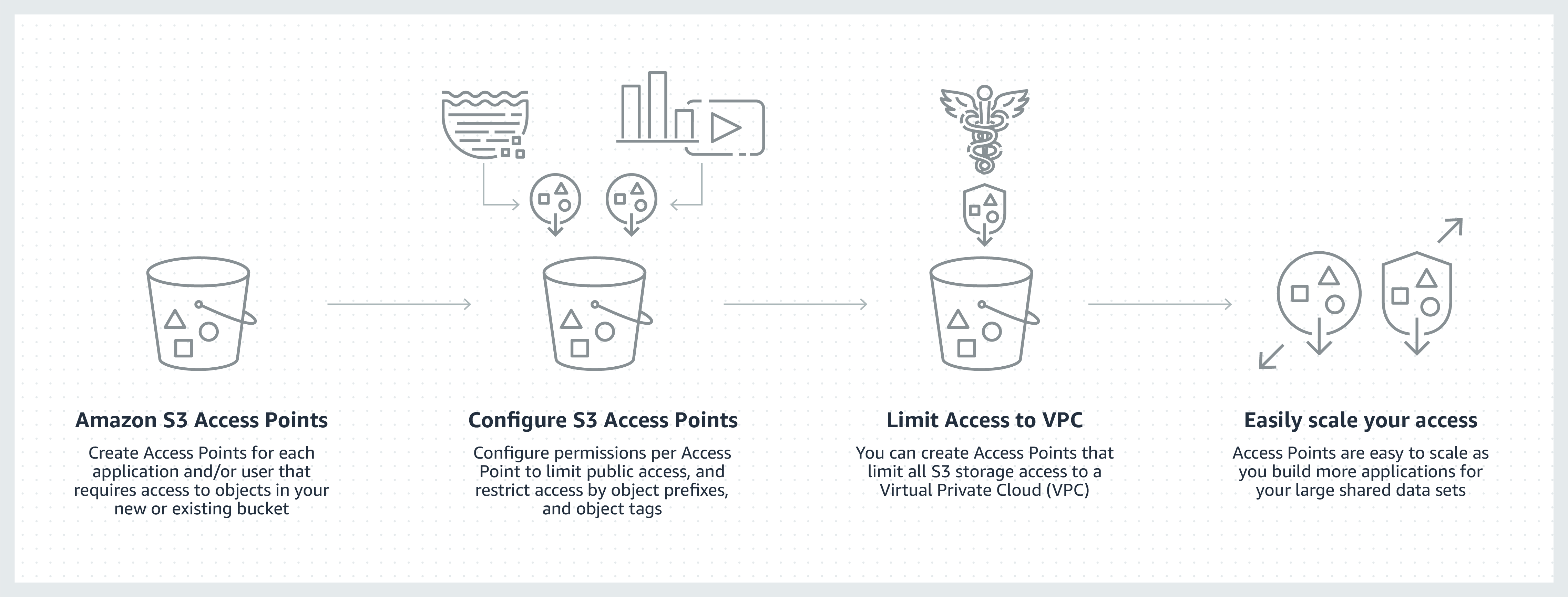
Amazon S3 Access Points, an S3 feature, manages data access at scale for applications using shared datasets in S3 Access points are unique hostnames that customers create to apply distinct permissions and network controls to any requests made through the access point.
Customers with shared data sets, including data lakes, media archives, and user-generated content, can easily scale access to hundreds of applications by creating unique access points with custom names and permissions for each application. Each access point can be restricted to a Virtual Private Cloud (VPC) to access S3 firewall data within customers’ private networks, and AWS Service Control policies can be used to ensure VPC restrictions are applied to all access points.
Manage tens of billions of objects at scale with S3 Batch Operations
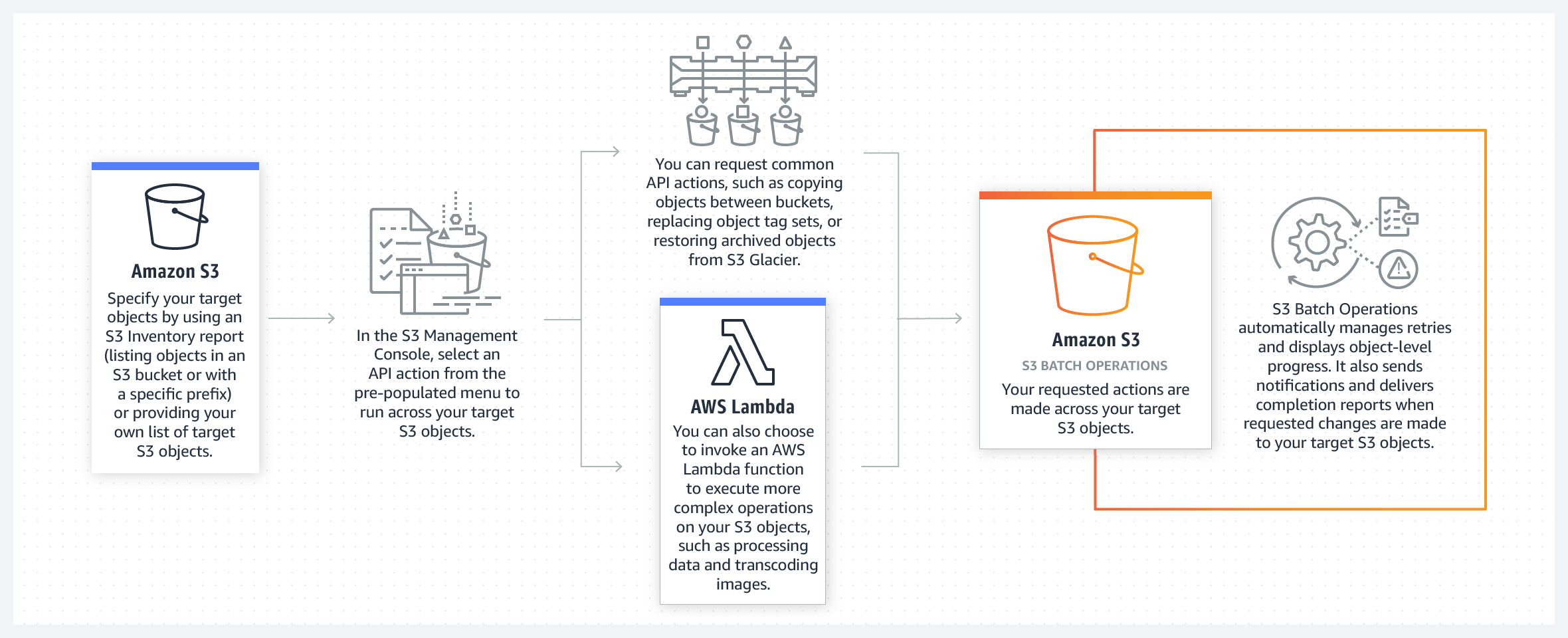
S3 Batch Operations is an Amazon S3 data management feature that lets you manage billions of objects at scale with just a few clicks in the Amazon S3 Management Console or an API request.
To perform work in S3 Batch Operations, you create a job. This job contains a list of objects, an action to perform, and a set of parameters that you specify for that type of operation. You can create and run multiple jobs in S3 Batch Operations at the same time, or use job priorities as needed to prioritize each job and ensure that the most important work happens first. S3 Batch Operations also handles retries, tracks progress, sends completion notifications, generates reports, and delivers events to AWS CloudTrail for all changes made and tasks performed.
Block public access to your S3 data now and in the future
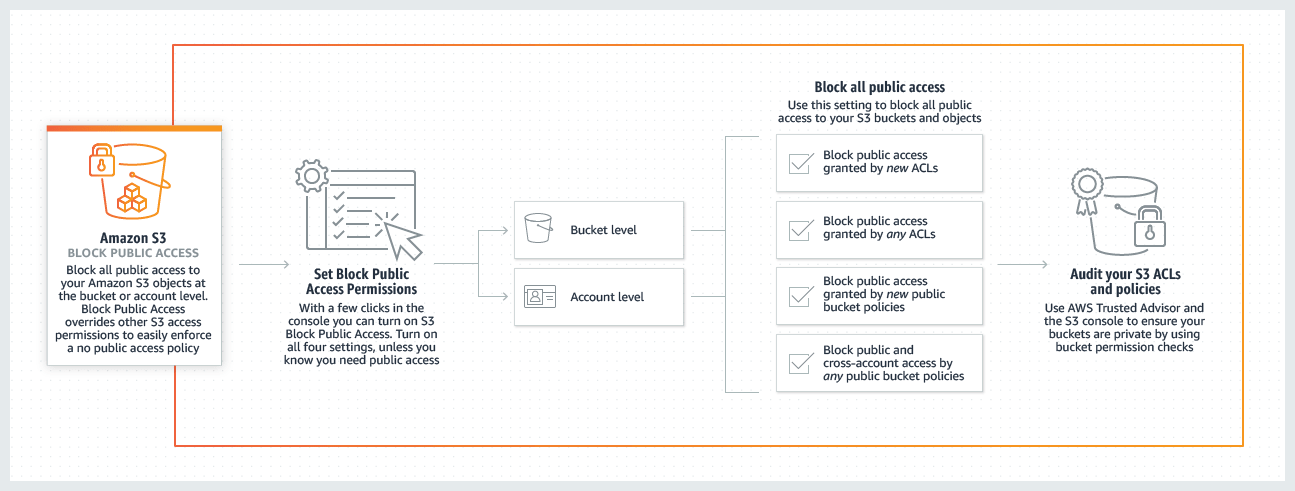
S3 Block Public Access provides controls at the AWS account-wide or individual S3 bucket level to ensure that objects are never, now or in the future, publicly accessible.
Public access to buckets and objects is granted through access control lists (ACLs), bucket policies, or both. To ensure that public access is blocked to all of your S3 buckets and objects, block public access at the account level. This setting applies to all current and future buckets across the entire account. S3 Overrides Public Access Settings S3 permissions that allow public access make it easy for an account administrator to create a centralized control to prevent changes to the security configuration regardless of how an object is added or the bucket is created.
use items
Archive
Retire physical infrastructure and archive data with S3 Glacier and S3 Glacier Deep Archive. These S3 storage classes retain objects over the long term at the lowest rate. To archive objects throughout their lifecycle, easily create an S3 lifecycle policy or upload objects directly to archive storage classes. With S3 Object Lock, you can apply retention dates to protect objects from deletion and meet compliance requirements. Unlike tape libraries, S3 Glacier lets you restore archived objects in as little as a minute for fast restores and 3-5 hours for standard restores. Bulk data recovery from S3 Glacier and all recoveries from S3 Glacier Deep Archive are completed within 12 hours.
Data Lake and Big Data Analytics
Accelerate innovation by building a data lake in Amazon S3 and using in-place search, analytics, and machine learning tools, Extract valuable insights. As your data lake grows, use S3 Access Points to easily configure access to your data, with specific permissions for each application or set of applications. You can use AWS Data Lake Formation to quickly create a data lake, as well as define and enforce security, governance, and auditing policies. This service collects data from your database and S3 resources, moves it to a new data lake in Amazon S3, and cleans and classifies it using machine learning algorithms. All AWS resources can be scaled to store your growing data – without any upfront investment.
Cloud Storage Hybrid
Create a private connection between Amazon S3 and on-premises with AWS PrivateLink. You can provision private endpoints in your VPC to provide direct access to S3 from on-premises via IP using private IPs from your VPC. AWS Storage Gateway lets you connect and extend your on-premises applications to AWS Storage while storing data locally for low-latency access. You can also transfer data between on-premises storage, including S3 on Outposts, and Amazon S3 using AWS DataSync, which can transfer data up to 10 times faster than open source data transfer tools. You can also move files directly into and out of Amazon S3 with AWS Transfer Family—a fully managed, simple, and hassle-free service that enables secure file exchange with third parties using SFTP, FTPS, and FTP. Another way to enable a hybrid cloud storage space is to work with an APN gateway provider.
Cloud Native Apps
Build fast, cost-effective mobile and web-based applications using AWS and Amazon S3 services to store development and production data shared by the microservices that make up cloud-native applications. With Amazon S3, you can upload and access any amount of data to deploy applications faster and reach more end users. Storing data in Amazon S3 means you can access the latest AWS developer tools, S3 APIs, and machine learning and analytics services to innovate and optimize your cloud-native applications.
Disaster Recovery (DR)
From data, applications, and information systems Protect critical data running in the AWS Cloud or on your premises without the cost of a second physical site. With Amazon S3 storage, S3 Cross-Region Replication, and other AWS compute, networking, and database services, you can create a DR architecture to quickly and easily recover from natural disasters, system failures, and human error.
Backup and Recovery
Build scalable, durable, and secure backup and recovery solutions by leveraging Amazon S3 and other AWS services like S3 Glacier, Amazon EFS, and Amazon EBS to Enhance or replace existing on-premises capabilities. AWS and APN partners can help you meet your recovery time objectives (RTO), recovery point objectives (RPO), and compliance requirements. With AWS, you can back up data in the AWS Cloud or use AWS Storage Gateway, a hybrid storage service, to back up on-premises data to AWS.
Case studies

Georgia-Pacific is building a central data lake based on Amazon S3, enabling it to ingest and analyze structured and unstructured data at scale efficiently.
Nasdaq stores data in Amazon S3 Glacier for up to seven years to comply with industry rules and regulations. Using AWS, the company is able to recover data while optimizing its long-term storage costs.
Sysco consolidates its data into a single data lake built on Amazon S3 and Amazon S3 Glacier to perform data analytics and gain business insights.
Nielsen creates a new local, cloud-based TV ratings platform that can store 30 petabytes of data in Amazon S3 and leverages Amazon Redshift, AWS Lambda, and Amazon EMR.






