









giriiş
Modern web uygulamaları, yapay zekânın entegrasyonuyla bir üst seviyeye taşınabilir. Bu ders, doğal dil işleme, görüntü oluşturma ve konuşma tanıma kullanan çok yönlü botların ileri düzey geliştirilmesine odaklanmaktadır. Bu botlar, benzersiz bir kullanıcı deneyimi sunar ve kullanıcıları birden fazla etkileşim moduyla meşgul eder.
Bu eğitimde, konuşma yapay zekası için Django Big Language Model ve OpenAI, doğru konuşma transkripsiyonu için Whisper ve görüntü oluşturma için DALL-E kullanan çok yönlü bir bot geliştirilmiştir. Eğitimde, eşlik eden görsellerle birlikte hikayeler üreten bir web uygulaması oluşturulması anlatılmaktadır. Kullanıcılar hikayenin konusunu sesli veya yazılı olarak belirtebilir ve uygulama, görsellerle süslenmiş, oluşturulmuş bir hikaye ile yanıt verir.
Bu eğitimin sonunda, metin, ses ve görüntü dahil olmak üzere çeşitli biçimlerdeki kullanıcı girdilerini anlayabilen ve bunlara yanıt verebilen bir uygulama oluşturmuş olacaksınız. Bu, uygulamayla kullanıcı etkileşimini önemli ölçüde artırarak, uygulamayı daha sezgisel ve erişilebilir hale getirir.
Ön koşullar
- Python ve Django hakkında temel bilgi
- OpenAI API anahtarı: Bu eğitim, OpenAI'nin GPT-4 ve DALL-E modelleriyle etkileşim kurmanızı gerektirir ve bu da OpenAI'den bir API anahtarı gerektirir.
- Fısıltı
- OpenAI Python paketi
Ortamınız aktif hale geldikten sonra, OpenAI Python paketini yüklemek için aşağıdaki komutu çalıştırın:
(env)sammy@ubuntu:$ pip install openaiAdım 1 – Konuşma Tanıma için OpenAI Whisper'ı Entegre Edin
Bu adımda, konuşmayı metne dönüştürmesini sağlamak için Django uygulamanıza OpenAI Whisper'ı entegre edeceksiniz. Whisper, çok yönlü botumuz için önemli bir özellik olan doğru transkripsiyonlar sağlayabilen güçlü bir konuşma tanıma modelidir. Whisper'ı entegre ederek, uygulamamız ses yoluyla sağlanan kullanıcı girdisini anlayabilecektir.
Öncelikle, Django proje dizininde çalıştığınızdan emin olun. Ön koşul eğitimlerinden sonra, bu entegrasyon için bir Django projesi hazırlamanız gerekecek. Terminalinizi açın, Django proje dizinine gidin ve sanal ortamınızın etkin olduğundan emin olun:
sammy@ubuntu:$ cd path_to_your_django_project
sammy@ubuntu:$ source env/bin/activateDjango uygulamanızda Whisper'ı kurma
Şimdi yapılması gereken, Whisper kullanarak ses dosyalarını metne dönüştüren bir fonksiyon oluşturmaktır. whisper_transcribe.py adında yeni bir Python dosyası oluşturun.
(env)sammy@ubuntu:$ touch whisper_transcribe.pyWhisper_transcribe.py dosyasını metin düzenleyicinizde açın ve Whisper yazın. Ardından, ses dosyasının yolunu girdi olarak alan, dosyayı işlemek için Whisper'ı kullanan ve daha sonra transkripsiyonu döndüren bir fonksiyon tanımlayalım:
import whisper
model = whisper.load_model("base")
def transcribe_audio(audio_path):
result = model.transcribe(audio_path)
return result["text"]Bu kod parçacığında, transkripsiyon için "temel" modeli kullanıyorsunuz. Whisper, farklı doğruluk ve performans ihtiyaçlarına uygun farklı modeller sunar. İhtiyaçlarınıza göre diğer modellerle kolayca deneme yapabilirsiniz.
Transkripsiyon testi
Transkripsiyonu test etmek için, bir ses dosyasını Django projenizin dizinine kaydedin. Dosyanın Whisper'ın desteklediği bir formatta (örneğin MP3, WAV) olduğundan emin olun. Şimdi, whisper_transcribe.py dosyasının sonuna aşağıdaki satırları ekleyerek dosyayı değiştirin:
# For testing purposes
if __name__ == "__main__":
print(transcribe_audio("path_to_your_audio_file"))Ses dosyanızın transkripsiyonunu terminalinizde görmek için `whisper_transcribe.py` dosyasını Python ile çalıştırın:
(env)sammy@ubuntu:$ python whisper_transcribe.pyHer şey doğru şekilde ayarlanmışsa, terminalde yazıya dökülmüş metni görmelisiniz. Bu işlev, botumuzdaki ses tabanlı etkileşimlerin temelini oluşturmaktadır.
Adım 2 – GPT-4 ile metin yanıtları oluşturma
Bu adımda, kullanıcı girdisine veya önceki adımda elde edilen konuşma transkripsiyonuna dayanarak metin yanıtları oluşturmak için GPT-4 LLM'yi kullanıyorsunuz. Geniş dil modeliyle GPT-4, tutarlı ve bağlamla ilgili yanıtlar üretebildiği için çok modlu bot uygulamamız için ideal bir seçimdir.
Devam etmeden önce, ön koşullarda açıklandığı gibi OpenAI Python paketinin sanal ortamınıza yüklendiğinden emin olun. GPT-4 modeline erişmek için bir API anahtarı gereklidir, bu nedenle anahtarınızın hazır olduğundan emin olun. OpenAI API anahtarını doğrudan Python dosyasına eklemek yerine ortam değişkenlerinize ekleyebilirsiniz:
(env)sammy@ubuntu:$ export OPENAI_KEY="your-api-key"Sohbetin tamamlanması ayarlanıyor
Django uygulamanızın dizinine gidin ve chat_completion.py adında yeni bir Python dosyası oluşturun. Bu betik, girilen metne göre yanıtlar oluşturmak için GPT-4 modeliyle iletişim kuracaktır.
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_story(input_text):
# Call the OpenAI API to generate the story
response = get_story(input_text)
# Format and return the response
return format_response(response)Bu kod parçası öncelikle OpenAI hizmetleriyle kimlik doğrulaması yapmak için gereken API anahtarını oluşturur. Ardından, hikaye için OpenAI API'sini çağırmak üzere ayrı bir fonksiyon olan `get_story`'yi ve daha sonra API yanıtını biçimlendirmek için başka bir fonksiyon olan `format_response`'u çağırır.
Şimdi get_story fonksiyonuna odaklanalım. chat_completion.py dosyanızın sonuna aşağıdakileri ekleyin:
def get_story(input_text):
# Construct the system prompt. Feel free to experiment with different prompts.
system_prompt = f"""You are a story generator.
You will be provided with a description of the story the user wants.
Write a story using the description provided."""
# Make the API call
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": input_text},
],
temperature=0.8
)
# Return the API response
return responseBu fonksiyonda öncelikle sisteme yapması gereken görevi bildiren sistem komutunu ayarlarsınız ve ardından kullanıcının girdiği metni kullanarak bir hikaye oluşturmak için ChatCompletion API'sinden istekte bulunursunuz.
Son olarak, format_response fonksiyonunu uygulayabilirsiniz. chat_completion.py dosyanızın sonuna aşağıdakileri ekleyin:
def format_response(response):
# Extract the generated story from the response
story = response.choices[0].message.content
# Remove any unwanted text or formatting
story = story.strip()
# Return the formatted story
return storyOluşturulan yanıtları test edin.
Metin oluşturmayı test etmek için, chat_completion.py dosyasının sonuna birkaç satır ekleyerek dosyayı değiştirin:
# For testing purposes
if __name__ == "__main__":
user_input = "Tell me a story about a dragon"
print(generate_story(user_input))Oluşturulan yanıtı terminalinizde görmek için chat_completion.py dosyasını Python ile çalıştırın:
(env)sammy@ubuntu:$ python chat_completion.pyVerilen yönergeye göre, GPT-4'ten yaratıcı bir yanıt görmelisiniz. Farklı yanıtlar görmek için farklı girdilerle denemeler yapın.
Sonraki adımda, oluşturulan hikayelere görseller ekliyorsunuz.
3. Adım – DALL-E ile görüntüler oluşturun
Metin mesajlarından doğru görüntüler oluşturmak üzere tasarlanan DALL-E, çok yönlü robotunuzun görsel yaratıcılıkla hikayeleri zenginleştirmesini sağlar.
Django uygulamanızda image_generation.py adında yeni bir Python dosyası oluşturun. Bu betik, görüntüyü oluşturmak için DALL-E modelini kullanır:
(env)sammy@ubuntu:$ touch image_generation.pyimage_generation.py dosyasında DALL-E'ye bildirim gönderen ve oluşturulan görüntüyü alan bir fonksiyon oluşturalım:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_image(text_prompt):
response = client.images.generate(
model="dall-e-3",
prompt=text_prompt,
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
return image_urlBu fonksiyon, metin komutunu, oluşturulacak görüntü sayısını (n=1) ve görüntülerin boyutunu belirterek DALL-E modeline bir istek gönderir. Ardından oluşturulan görüntünün URL'sini çıkarır ve döndürür.
Komut dosyası testi
Bu fonksiyonun bir Django projesinde kullanımını göstermek için, image_generation.py dosyanızın sonuna aşağıdaki örneği ekleyebilirsiniz:
# For testing purposes
if __name__ == "__main__":
prompt = "Generate an image of a pet and a child playing in a yard."
print(generate_image(prompt))Verilen komuta göre bir görüntü oluşturmak için image_generation.py dosyasını Python ile çalıştırın:
(env)sammy@ubuntu:$ python image_generation.pyKomut dosyası başarıyla çalışırsa, terminalde oluşturulan resim URL'sini göreceksiniz. Daha sonra web tarayıcınızda bu URL'ye giderek resmi görüntüleyebilirsiniz.
Bir sonraki adımda, kusursuz bir kullanıcı deneyimi için konuşma tanıma özelliğini metin ve görüntü oluşturma ile bir araya getireceksiniz.
4. Adım – Kusursuz bir deneyim için yöntemleri birleştirin
Bu aşamada, kusursuz bir kullanıcı deneyimi sağlamak için önceki aşamalarda geliştirilen yetenekleri entegre edeceksiniz.
Web uygulamanız, kullanıcıların metin ve ses girişlerini işleyebilecek, hikayeler oluşturabilecek ve bunları ilgili görsellerle destekleyebilecektir.
Birleşik bir görünüm oluşturun
Öncelikle, Django projenizin düzenli olduğundan ve Django uygulama dizininizde whisper_transcribe.py, chat_completion.py ve image_generation.py dosyalarının bulunduğundan emin olun. Şimdi bu bileşenleri birleştiren bir görünüm oluşturacaksınız.
views.py dosyasını açın ve gerekli modülleri ve fonksiyonları içe aktarın. Ardından get_story_from_description adında yeni bir görünüm oluşturun:
import uuid
from django.core.files.storage import FileSystemStorage
from django.shortcuts import render
from .whisper_transcribe import transcribe_audio
from .chat_completion import generate_story
from .image_generation import generate_image
# other views
def get_story_from_description(request):
context = {}
user_input = ""
if request.method == "GET":
return render(request, "story_template.html")
else:
if "text_input" in request.POST:
user_input += request.POST.get("text_input") + "\n"
if "voice_input" in request.FILES:
audio_file = request.FILES["voice_input"]
file_name = str(uuid.uuid4()) + (audio_file.name or "")
FileSystemStorage(location="/tmp").save(file_name, audio_file)
user_input += transcribe_audio(f"/tmp/{file_name}")
generated_story = generate_story(user_input)
image_prompt = (
f"Generate an image that visually illustrates the essence of the following story: {generated_story}"
)
image_url = generate_image(image_prompt)
context = {
"user_input": user_input,
"generated_story": generated_story.replace("\n", "<br/>"),
"image_url": image_url,
}
return render(request, "story_template.html", context)Bu görünüm, kullanıcıdan metin ve/veya ses girdisi alır. Ses dosyası mevcutsa, onu benzersiz bir adla (uuid kütüphanesini kullanarak) kaydeder ve konuşmayı metne dönüştürmek için `transcribe_audio` fonksiyonunu kullanır. Ardından, metin yanıtı oluşturmak için `gene_story` fonksiyonunu ve ilişkili bir görüntü oluşturmak için `gene_image` fonksiyonunu kullanır. Bu çıktılar, daha sonra `story_template.html` ile işlenen metin sözlüğüne gönderilir.
Şablon oluşturun
Ardından story_template.html adında bir dosya oluşturun ve içine aşağıdakileri ekleyin:
<div style="padding:3em; font-size:14pt;">
<form method="post" enctype="multipart/form-data">
{% csrf_token %}
<textarea name="text_input" placeholder=" Describe the story you would like" style="width:30em;"></textarea>
<br/><br/>
<input type="file" name="voice_input" accept="audio/*" style="width:30em;">
<br/><br/>
<input type="submit" value="Submit" style="width:8em; height:3em;">
</form>
<p>
<strong>{{ user_input }}</strong>
</p>
{% if image_url %}
<p>
<img src="{{ image_url }}" alt="Generated Image" style="max-width:80vw; width:30em; height:30em;">
</p>
{% endif %}
{% if generated_story %}
<p>{{ generated_story | safe }}</p>
{% endif %}
</div>Bu basit form, kullanıcıların isteklerini metin yoluyla veya ses dosyası yükleyerek göndermelerine olanak tanır. Ardından uygulama tarafından oluşturulan metin ve görseli görüntüler.
Görünüm için URL oluştur
Artık `get_story_from_description` görünümünüz hazır olduğuna göre, bir URL yapılandırması oluşturarak onu kullanılabilir hale getirmeniz gerekiyor.
Django uygulamanızdaki urls.py dosyasını açın ve get_story_from_description görünümü için bir şablon ekleyin:
from django.urls import path
from . import views
urlpatterns = [
# other patterns
path('generate-story/', views.get_story_from_description, name='get_story_from_description'),
]Birleşik Deneyim Testi
Artık web tarayıcınızda http://your_domain/generate-story/ adresini ziyaret edebilirsiniz. story_template.html dosyasında tanımlanan formu görmelisiniz. Metin giriş alanından bir metin isteği göndermeyi veya dosya giriş alanını kullanarak bir ses dosyası yüklemeyi deneyin. Gönderildikten sonra, isteğiniz girilen verileri işleyecek, bir hikaye ve ona eşlik eden bir resim oluşturacak ve bunları sayfada görüntüleyecektir.
Örneğin, işte örnek bir hikaye konusu: "Bana bahçede oynayan bir evcil hayvan ve bir çocuk hakkında bir hikaye anlatın."“
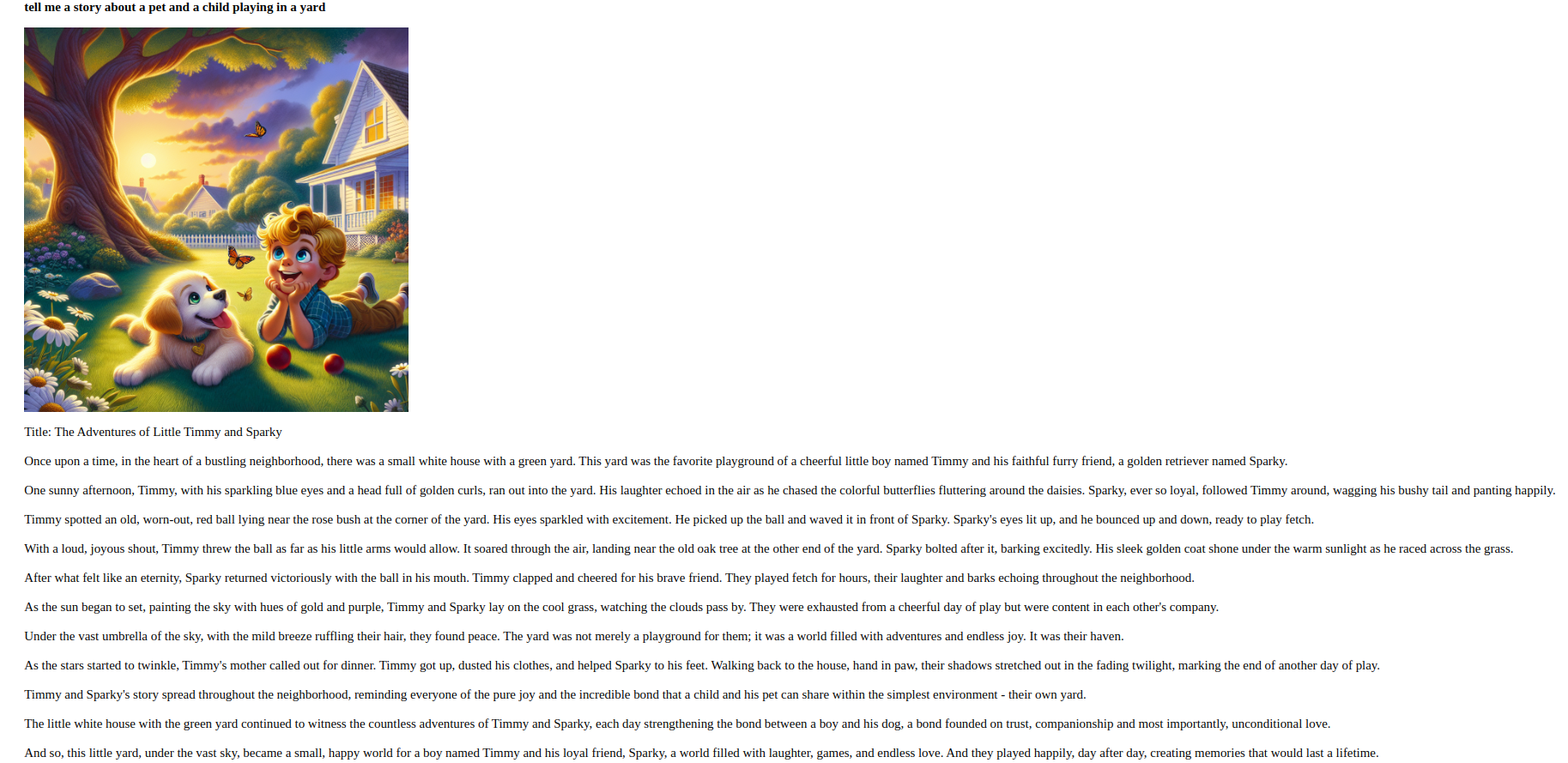
Bu adımı tamamlayarak, çeşitli biçimlerdeki kullanıcı girdilerini işleyen ve bunlara yanıt veren bir uygulama oluşturmuş oldunuz.
Sonuç
Bu eğitimde, Django kullanarak, konuşma tanıma için Whisper, metin oluşturma için GPT-4 ve görüntü oluşturma için DALL-E entegrasyon yeteneklerine sahip çok yönlü bir botu başarıyla geliştirdiniz. Programınız artık çeşitli formatlardaki kullanıcı girdilerini anlayabiliyor ve bunlara tepki verebiliyor.
Daha fazla geliştirme için, Whisper, GPT ve DALL-E modellerinin alternatif sürümlerini incelemeniz, uygulamanızın kullanıcı arayüzü/kullanıcı deneyimi tasarımını iyileştirmeniz veya botun işlevselliğini ek etkileşimli özellikler içerecek şekilde genişletmeniz önerilir.









