









Введение
Современные веб-приложения могут выйти на новый уровень благодаря интеграции искусственного интеллекта. Этот курс посвящен продвинутой разработке многофункциональных ботов, использующих обработку естественного языка, генерацию изображений и распознавание речи. Эти боты обеспечивают уникальный пользовательский опыт и вовлекают пользователей посредством различных способов взаимодействия.
В этом руководстве мы разрабатываем многофункционального бота, используя Django Big Language Model и OpenAI для разговорного ИИ, Whisper для точной транскрипции речи и DALL-E для генерации изображений. В нём описывается создание веб-приложения, генерирующего истории с сопровождающими изображениями. Пользователи могут указать тему истории голосом или текстом, а приложение отвечает сгенерированной историей, украшенной визуальными эффектами.
К концу этого руководства вы создадите приложение, которое сможет распознавать и реагировать на пользовательский ввод в различных формах, включая текст, аудио и изображения. Это значительно повышает удобство взаимодействия пользователя с приложением, делая его более интуитивно понятным и доступным.
Предпосылки
- Базовое понимание Python и Django
- Ключ API OpenAI: для этого руководства вам потребуется взаимодействовать с моделями OpenAI GPT-4 и DALL-E, для чего требуется ключ API от OpenAI.
- Шепот
- Пакет OpenAI Python
После активации среды выполните следующую команду для установки пакета OpenAI Python:
(env)sammy@ubuntu:$ pip install openaiШаг 1 — Интеграция OpenAI Whisper для распознавания речи
На этом этапе вы настроите OpenAI Whisper в своём приложении Django, чтобы оно могло преобразовывать речь в текст. Whisper — это надёжная модель распознавания речи, обеспечивающая точную транскрипцию, что является важной функцией для нашего многофункционального бота. Благодаря интеграции Whisper наше приложение сможет понимать голосовой ввод пользователя.
Сначала убедитесь, что вы работаете в каталоге проекта Django. После изучения подготовительных уроков вам потребуется подготовить проект Django для этой интеграции. Откройте терминал, перейдите в каталог проекта Django и убедитесь, что виртуальная среда активна:
sammy@ubuntu:$ cd path_to_your_django_project
sammy@ubuntu:$ source env/bin/activateНастройка Whisper в вашем приложении Django
Теперь нужно создать функцию, которая будет использовать Whisper для транскрибации аудиофайлов в текст. Создайте новый файл Python с именем whisper_transcribe.py.
(env)sammy@ubuntu:$ touch whisper_transcribe.pyОткройте файл whisper_transcribe.py в текстовом редакторе и введите Whisper. Далее определим функцию, которая принимает путь к аудиофайлу в качестве входных данных, обрабатывает его с помощью Whisper и возвращает расшифровку:
import whisper
model = whisper.load_model("base")
def transcribe_audio(audio_path):
result = model.transcribe(audio_path)
return result["text"]В этом фрагменте кода используется “базовая” модель транскрипции. Whisper предлагает различные модели для удовлетворения различных требований к точности и производительности. Вы можете легко экспериментировать с другими моделями в зависимости от ваших потребностей.
Транскрипционный тест
Чтобы протестировать транскрипцию, сохраните аудиофайл в каталоге проекта Django. Убедитесь, что формат файла поддерживается Whisper (например, MP3, WAV). Теперь измените файл whisper_transcribe.py, добавив следующие строки в конец:
# For testing purposes
if __name__ == "__main__":
print(transcribe_audio("path_to_your_audio_file"))Запустите whisper_transcribe.py с Python, чтобы увидеть транскрипцию вашего аудиофайла в терминале:
(env)sammy@ubuntu:$ python whisper_transcribe.pyЕсли всё настроено правильно, вы увидите расшифрованный текст в терминале. Эта функция лежит в основе голосового взаимодействия в нашем боте.
Шаг 2 — Создание текстовых ответов с помощью GPT-4
На этом этапе вы используете GPT-4 LLM для генерации текстовых ответов на основе пользовательского ввода или транскрипции речи, полученной на предыдущем этапе. GPT-4, благодаря своей обширной языковой модели, может генерировать связные и контекстно-зависимые ответы, что делает его идеальным выбором для нашего мультимодального бота.
Прежде чем продолжить, убедитесь, что пакет OpenAI Python установлен в вашей виртуальной среде, как описано в предварительных требованиях. Для доступа к модели GPT-4 требуется ключ API, поэтому убедитесь, что он у вас есть. Вы можете добавить ключ API OpenAI в переменные среды, а не добавлять его напрямую в файл Python:
(env)sammy@ubuntu:$ export OPENAI_KEY="your-api-key"Настройка завершения чата
Перейдите в каталог приложения Django и создайте новый файл Python с именем chat_completion.py. Этот скрипт будет взаимодействовать с моделью GPT-4 для генерации ответов на основе введённого текста.
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_story(input_text):
# Call the OpenAI API to generate the story
response = get_story(input_text)
# Format and return the response
return format_response(response)Этот фрагмент кода сначала настраивает ключ API, необходимый для аутентификации в сервисах OpenAI. Затем он вызывает отдельную функцию get_story для обращения к API OpenAI для получения истории, а затем ещё одну функцию format_response для форматирования ответа API.
Теперь сосредоточимся на функции get_story. Добавьте следующий код в конец файла chat_completion.py:
def get_story(input_text):
# Construct the system prompt. Feel free to experiment with different prompts.
system_prompt = f"""You are a story generator.
You will be provided with a description of the story the user wants.
Write a story using the description provided."""
# Make the API call
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": input_text},
],
temperature=0.8
)
# Return the API response
return responseВ этой функции вы сначала задаете системную команду, которая информирует модель о задаче, которую ей необходимо выполнить, а затем запрашиваете API ChatCompletion для генерации истории с использованием введенного пользователем текста.
Наконец, вы можете реализовать функцию format_response. Добавьте следующий код в конец файла chat_completion.py:
def format_response(response):
# Extract the generated story from the response
story = response.choices[0].message.content
# Remove any unwanted text or formatting
story = story.strip()
# Return the formatted story
return storyПроверьте сгенерированные ответы
Чтобы протестировать генерацию текста, измените chat_completion.py, добавив несколько строк внизу:
# For testing purposes
if __name__ == "__main__":
user_input = "Tell me a story about a dragon"
print(generate_story(user_input))Чтобы увидеть сгенерированный ответ в терминале, запустите chat_completion.py с помощью Python:
(env)sammy@ubuntu:$ python chat_completion.pyВ соответствии с подсказкой вы должны увидеть креативный ответ от GPT-4. Поэкспериментируйте с разными входными данными, чтобы увидеть разные ответы.
На следующем этапе вы добавляете изображения к сгенерированным историям.
Шаг 3 — Создание изображений с помощью DALL-E
Разработанный для создания точных изображений из текстовых сообщений, DALL-E позволяет вашему многогранному роботу дополнять истории визуальным творчеством.
Создайте новый файл Python с именем image_generation.py в вашем приложении Django. Этот скрипт использует модель DALL-E для генерации изображения:
(env)sammy@ubuntu:$ touch image_generation.pyДавайте создадим функцию в image_generation.py, которая отправляет уведомление в DALL-E и извлекает сгенерированное изображение:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_KEY"])
def generate_image(text_prompt):
response = client.images.generate(
model="dall-e-3",
prompt=text_prompt,
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
return image_urlЭта функция отправляет запрос к модели DALL-E с указанием текстовой команды, количества изображений для генерации (n=1) и их размера. Затем она извлекает и возвращает URL-адрес сгенерированного изображения.
Тестовый сценарий
Чтобы продемонстрировать использование этой функции в проекте Django, вы можете добавить следующий пример в конец файла image_generation.py:
# For testing purposes
if __name__ == "__main__":
prompt = "Generate an image of a pet and a child playing in a yard."
print(generate_image(prompt))Запустите image_generation.py с Python, чтобы создать изображение на основе заданной команды:
(env)sammy@ubuntu:$ python image_generation.pyЕсли скрипт отработает успешно, вы увидите URL-адрес сгенерированного изображения в терминале. Вы можете просмотреть изображение, перейдя по этому URL-адресу в веб-браузере.
На следующем этапе вы объедините распознавание речи с генерацией текста и изображений для обеспечения бесперебойного взаимодействия с пользователем.
Шаг 4 — Объедините методы для обеспечения бесперебойной работы
На этом этапе вы интегрируете возможности, разработанные на предыдущих этапах, для обеспечения бесперебойной работы пользователя.
Ваше веб-приложение сможет обрабатывать текстовый и голосовой ввод пользователей, генерировать истории и дополнять их соответствующими изображениями.
Создайте единое представление
Сначала убедитесь, что ваш проект Django организован и что в каталоге приложения Django есть whisper_transcribe.py, chat_completion.py и image_generation.py. Теперь вам нужно создать представление, объединяющее эти компоненты.
Откройте файл views.py и импортируйте необходимые модули и функции. Затем создайте новое представление с именем get_story_from_description:
import uuid
from django.core.files.storage import FileSystemStorage
from django.shortcuts import render
from .whisper_transcribe import transcribe_audio
from .chat_completion import generate_story
from .image_generation import generate_image
# other views
def get_story_from_description(request):
context = {}
user_input = ""
if request.method == "GET":
return render(request, "story_template.html")
else:
if "text_input" in request.POST:
user_input += request.POST.get("text_input") + "\n"
if "voice_input" in request.FILES:
audio_file = request.FILES["voice_input"]
file_name = str(uuid.uuid4()) + (audio_file.name or "")
FileSystemStorage(location="/tmp").save(file_name, audio_file)
user_input += transcribe_audio(f"/tmp/{file_name}")
generated_story = generate_story(user_input)
image_prompt = (
f"Generate an image that visually illustrates the essence of the following story: {generated_story}"
)
image_url = generate_image(image_prompt)
context = {
"user_input": user_input,
"generated_story": generated_story.replace("\n", "<br/>"),
"image_url": image_url,
}
return render(request, "story_template.html", context)Это представление получает текстовый и/или аудиоввод от пользователя. Если существует аудиофайл, он сохраняется под уникальным именем (с помощью библиотеки uuid) и преобразует речь в текст с помощью функции transcribe_audio. Затем оно использует функцию gene_story для генерации текстового ответа и функцию gene_image для генерации соответствующего изображения. Эти выходные данные отправляются в текстовый словарь, который затем визуализируется с помощью story_template.html.
Создать шаблон
Затем создайте файл с именем story_template.html и добавьте следующее:
<div style="padding:3em; font-size:14pt;">
<form method="post" enctype="multipart/form-data">
{% csrf_token %}
<textarea name="text_input" placeholder=" Describe the story you would like" style="width:30em;"></textarea>
<br/><br/>
<input type="file" name="voice_input" accept="audio/*" style="width:30em;">
<br/><br/>
<input type="submit" value="Submit" style="width:8em; height:3em;">
</form>
<p>
<strong>{{ user_input }}</strong>
</p>
{% if image_url %}
<p>
<img src="{{ image_url }}" alt="Generated Image" style="max-width:80vw; width:30em; height:30em;">
</p>
{% endif %}
{% if generated_story %}
<p>{{ generated_story | safe }}</p>
{% endif %}
</div>Эта простая форма позволяет пользователям отправлять запросы текстом или загружать аудиофайлы. Затем она отображает текст и изображение, сгенерированные приложением.
Создать URL для просмотра
Теперь, когда у вас готово представление get_story_from_description, вам нужно сделать его доступным, создав конфигурацию URL.
Откройте файл urls.py в приложении Django и добавьте шаблон для представления get_story_from_description:
from django.urls import path
from . import views
urlpatterns = [
# other patterns
path('generate-story/', views.get_story_from_description, name='get_story_from_description'),
]Унифицированное тестирование опыта
Теперь вы можете открыть страницу http://your_domain/generate-story/ в веб-браузере. Вы должны увидеть форму, заданную в файле story_template.html. Попробуйте отправить текстовый запрос через поле ввода текста или загрузить аудиофайл через поле ввода файла. После отправки ваш запрос обработает введенные данные, сгенерирует историю и сопутствующее изображение и отобразит их на странице.
Например, вот пример рассказа-задания: “Расскажи мне историю о домашнем животном и ребенке, играющих во дворе”.”
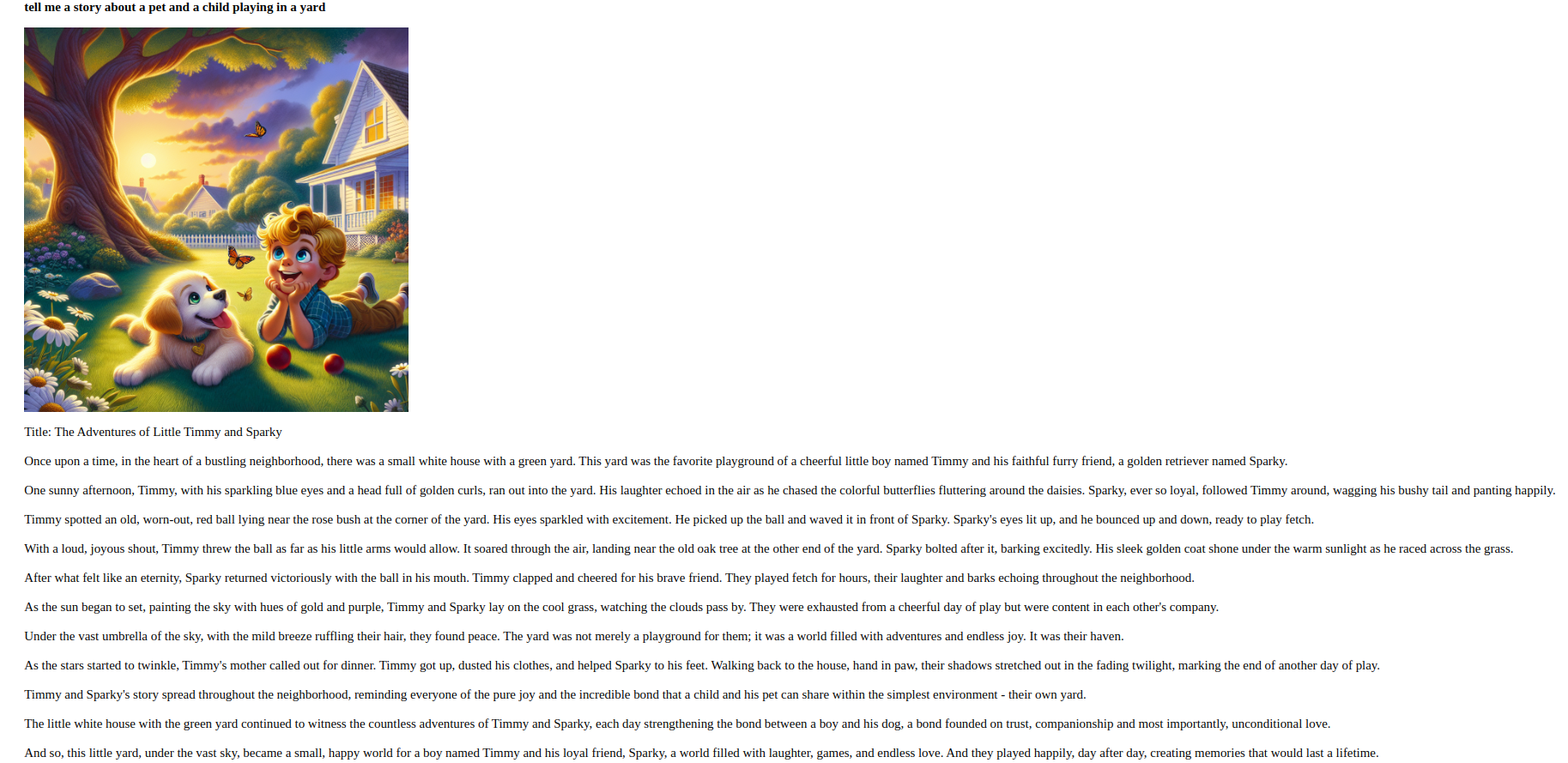
Выполнив этот шаг, вы создали приложение, которое обрабатывает и реагирует на пользовательский ввод в различных формах.
Результат
В этом руководстве вы успешно разработали многофункционального бота на Django с интеграцией Whisper для распознавания речи, GPT-4 для генерации текста и DALL-E для генерации изображений. Теперь ваша программа может понимать и реагировать на пользовательский ввод в различных форматах.
Для дальнейшей разработки рекомендуется изучить альтернативные версии моделей Whisper, GPT и DALL-E, улучшить UI/UX-дизайн вашего приложения или расширить функционал бота, включив в него дополнительные интерактивные функции.









