









介绍
本教程讲解如何在运行 Ubuntu 或 Debian 的服务器上安装 Ollama 以运行语言模型。此外,它还展示了如何使用 Open WebUI 设置聊天界面以及如何使用自定义语言模型。.
先决条件
- 一台运行 Ubuntu/Debian 系统的服务器
- 您需要root用户权限或具有sudo权限的用户权限。.
- 开始之前,您需要完成一些初始设置,包括防火墙设置。.
步骤 1 – 安装 Ollama
以下步骤说明如何手动安装 Ollama。为了快速入门,您可以使用安装脚本并继续执行“步骤 2 – 安装 Ollama WebUI”。.
要自行安装 Ollama,请按照以下步骤操作:
如果您的服务器配备了 Nvidia GPU,请确保已安装 CUDA 驱动程序。
nvidia-smi
如果您尚未安装 CUDA 驱动程序,请立即安装。在此配置中,您可以选择您的操作系统并选择安装程序类型,以查看您需要运行的命令。.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
下载 Ollama 二进制文件并创建 Ollama 用户
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama创建服务文件。默认情况下,您可以通过端口 11434 和 127.0.0.1 访问 Ollama API。这意味着该 API 仅适用于本地主机。.
如果您需要从外部访问 Ollama,您可以 环境 移除并设置用于访问 Ollama API 的 IP 地址。. 0.0.0.0 允许您通过服务器的公共 IP 地址访问 API。如果您使用 环境 如果您正在使用,请确保您的服务器防火墙允许访问您在此处配置的端口。 11434 如果你只有一台服务器,则无需更改以下命令。.
复制并粘贴以下代码块的全部内容。这个新文件 /etc/systemd/system/ollama.service 创建和交叉内容 EOF 添加到新文件中。.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
重新加载 systemd 守护进程并启用 Ollama 服务。
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama使用 systemctl status olama 检查 Olama 的状态。如果 Olama 没有启动并运行,请确保运行 systemctl start olama。.
现在,您可以在终端中启动语言模型并提出问题。例如:
ollama run llama2
下一步将说明如何安装网页界面,以便您可以通过网页浏览器在美观的界面中提出问题。.
步骤 2 – 安装 Open WebUI
在 GitHub 上的 Olama 文档中,您可以找到各种 Web 和终端集成的列表。本示例解释了如何安装 Open WebUI。.
您可以将 Open WebUI 和 Ollama 安装在同一台服务器上,也可以将 Ollama 和 Open WebUI 安装在两台不同的服务器上。如果您将 Open WebUI 安装在单独的服务器上,请确保 Ollama API 已在您的网络上公开。为了再次确认, /etc/systemd/system/olama.service 查看安装了 Ollama 的服务器及其值 OLLAMA_HOST 确认。.
以下步骤说明了如何安装该接口:
- 手动
- 使用 Docker
手动安装 Open WebUI
安装 npm 和 pip,克隆 WebUI 仓库,并创建示例环境文件的副本:
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .env在 环境。. 连接到 Ollama API 的地址设置为默认值。 localhost:11434 已设置。如果您已将 Ollama API 安装在与 Open WebUI 相同的服务器上,则可以保留这些设置不变。如果您已将 Open WebUI 安装在与 Ollama API 不同的服务器上, 环境。. 编辑并替换默认值为 Olama 安装所在的服务器地址。.
列出的依赖项 package.json 安装并运行名为 建造 跑步:
npm i && npm run build
安装所需的 Python 软件包:
cd backend
sudo pip install -r requirements.txt -UWeb界面 olama-webui/backend/start.sh 开始。.
sh start.sh在 开始脚本端口设置为 8080。这意味着您可以通过该端口访问 Open WebUI。 http:// 8080 访问权限。如果您的服务器上启用了防火墙,则需要先允许端口才能访问聊天界面。为此,您可以跳至«步骤 3 – 允许 Web 界面端口»。如果您没有启用防火墙(不建议这样做),则可以跳至«步骤 4 – 添加模型»。.
使用 Docker 安装 Open WebUI
这一步需要安装 Docker。如果您还没有安装 Docker,可以参考本教程进行安装。.
如前所述,您可以选择将 Open WebUI 安装在与 Ollama 相同的服务器上,或者将 Ollama 和 Open WebUI 安装在两个不同的服务器上。.
在同一台 Ollama 服务器上安装 Open WebUI
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
在与 Ollama 不同的服务器上安装 Open WebUI
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
在上面的 Docker 命令中,端口设置为 3000。这意味着您可以通过该端口访问 Open WebUI。 http:// 3000 访问权限。如果您的服务器上启用了防火墙,则需要先允许端口访问才能访问聊天界面。下一步将对此进行详细说明。.
步骤 3 – 允许端口访问 Web UI
如果您启用了防火墙,请确保其允许访问 Open WebUI 端口。如果您是手动安装的,则需要手动打开该端口。 8080 TCP 如果您使用 Docker 安装,则需要允许端口。 3000 TCP 让我。.
要再次检查,您可以使用 netstat 使用并查看哪些端口正在被使用。.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN有好几种不同的防火墙工具。本教程将介绍如何配置 Ubuntu 的默认防火墙工具。 ufw 如果您使用的是其他防火墙,请确保它允许入站流量通过 TCP 端口 8080 或 3000。.
管理防火墙规则 ufw:
- 查看当前防火墙设置
检查防火墙是否有效 ufw 如果已启用且您已设置任何规则,则可以使用以下方法:
sudo ufw status
- 允许 TCP 端口 8080 或 3000
如果防火墙已启用,请运行以下命令以允许传入 TCP 端口 8080 或 3000 的流量:
sudo ufw allow proto tcp to any port 8080
- 查看新的防火墙设置
现在应该已经添加了新规则。要查看规则,请访问:
sudo ufw status
第四步——添加模型
访问网页界面后,您需要创建第一个账户。该用户将拥有管理员权限。要开始您的第一次聊天,您需要选择一个模特。您可以在 llama 官方网站上浏览模特列表。在本例中,我们将添加“llama2”。.
在右上角,选择设置图标。
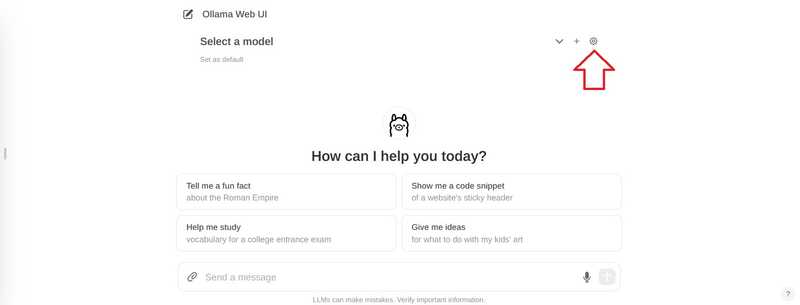
前往“模型”页面,输入模型名称,然后选择下载按钮。.
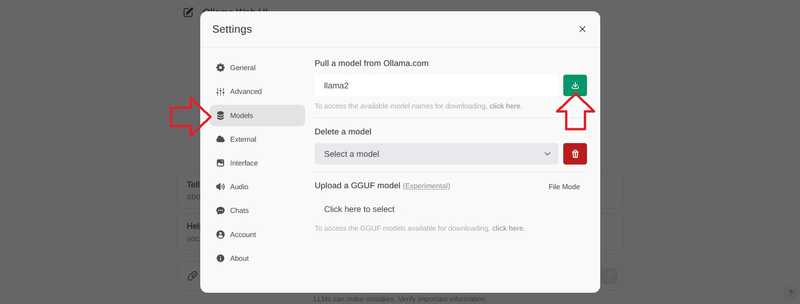
请等待出现以下消息:
Model 'llama2' has been successfully downloaded.
关闭设置即可返回聊天界面。.
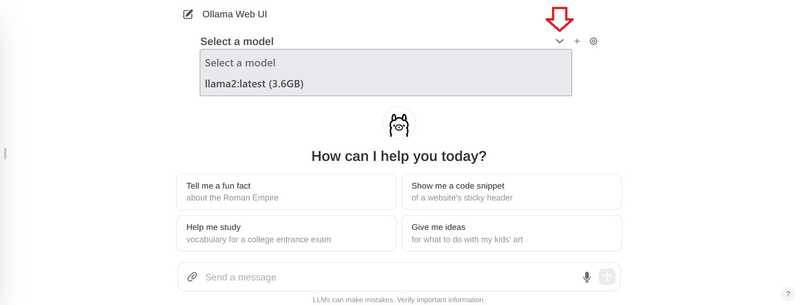
在聊天窗口中,点击顶部的“选择模型”,然后添加您的模型。.
如果要添加多个模型,可以使用顶部的“+”号。.
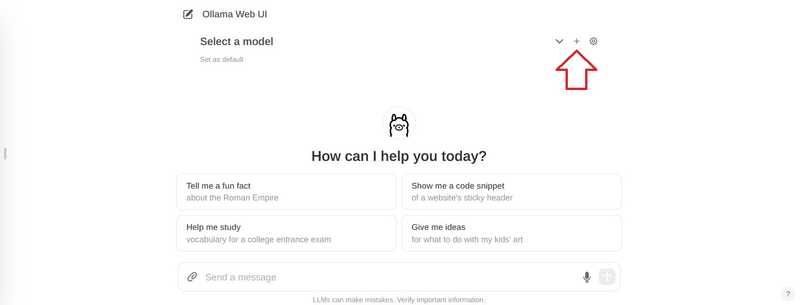
添加完想要使用的模型后,就可以开始提问了。如果添加了多个模型,可以在不同的答案之间切换。.

步骤 5 – 添加您的模型
如果您想通过界面添加新模型,可以通过以下方式操作: http:// :8080/modelfiles/create/ 必要时,去做。 8080 和 3000 代替。.
以下将重点介绍如何通过终端添加新模型。首先,您需要连接到已安装 Olama 的服务器。从列表中选择要添加的模型。 世界 用于列出目前可用的型号。.
- 创建模型文件
您可以在 GitHub 上的 Olama 文档中找到模型文件的要求。模型文件的第一行是 FROM您可以指定要使用的模型。在本例中,我们将修改现有的 llama2 模型。如果要添加一个全新的模型,则需要指定模型文件的路径(例如 FROM ./my-model.gguf)。.
nano new-model
保存此内容:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
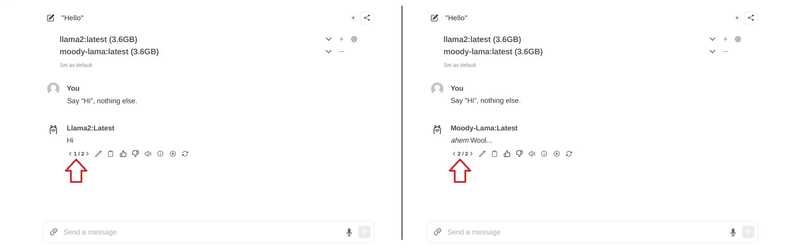
SYSTEM You are a moody lama that only talks about its own fluffy wool.从模型文件创建模型
ollama create moody-lama -f ./new-model
- 查看新型号是否有货。
使用 olama 命令列出所有型号。Moody-lama 也应该列在内。.
ollama list
- 在 WebUI 中使用您的模型
返回网页界面后,该模型应该会出现在模型选择列表中。如果尚未显示,您可能需要刷新页面。.
结果
在本教程中,您学习了如何在自己的服务器上托管 AI 聊天以及如何添加自己的模型。.









