









TensorFlow
TensorFlow 这是一个由谷歌发布的机器学习和深度学习库,谷歌已在多个方面使用该库来提升用户体验。例如,当您开始搜索时,谷歌会自动补全您的搜索词。.
机器学习主要面向三类人群:1. 研究人员;2. 数据科学家;3. 程序员。为了满足这些人的需求,谷歌大脑团队开发了 TensorFlow 库。TensorFlow 可以在不同的 CPU 和 GPU 上运行,并支持多种编程语言,例如 C++、Python 和 Java。TensorFlow 既可以部署在服务器上,也可以部署在移动设备上。.
TensorFlow 的发展历程
随着数据量的增加,深度学习开始超越深度学习算法,谷歌得出结论,它可以利用这些深度神经网络来增强其服务,并开始构建一个名为 TensorFlow 的框架,该框架可以帮助开发人员和研究人员同时协作开发 AI 模型。.
当该项目发展到足够完善且具有可扩展性后,于 2015 年公开发布。然而,稳定版本直到 2017 年才发布。.
TensorFlow 的重要特性在于它是开源的,并采用 Apache 许可,因此您可以轻松地使用它、编辑它并发布您自己的发行版。您甚至可以从中获利,而无需向 Google 付费。 .
TensorFlow架构
TensorFlow 架构包含三个部分:1. 数据预处理;2. 模型构建;3. 模型训练和评估。之所以这样命名,是因为 TensorFlow 接收多维数组作为输入,这些数组的名称是 张量 然后,您可以对数据运行一系列操作图,这些操作图是: 流程图 是的。.
演出地点在哪里?
使用此库分为两个阶段:
开发阶段: 训练模型需要一定的时间,这个阶段通常是在你的笔记本电脑或系统上完成的。.
实施阶段: 训练完成后,你可以在任何地方运行你的模型,从台式机到服务器,甚至手机。.
因此,模型的训练和运行可以在不同的机器上进行。.
除了使用 CPU,你还可以在 GPU 上运行 TensorFlow。.
在矩阵计算中,由于对大量信息执行相同的运算,因此这种类型的计算与 GPU 的结构兼容,这是斯坦福大学的研究人员在 2010 年末发现的。.
另一点是,这个库是用 C++ 编写的,所以速度非常快。当然,你也可以把它和其他语言一起使用,例如 Python。.
TensorFlow 的一个重要特性是 TensorBoard,它可以让您看到 TensorFlow 正在做什么。.
TensorFlow 组件
张量
张量是由N维矩阵组成的数组,可以表示各种类型的信息。张量中的每个值都包含相同形状的信息。.
张量既可以作为计算的输入,也可以作为计算的输出。.
图形
在TensorFlow中,所有操作都在一个图中执行。每个图都是一系列按顺序执行的计算的集合。每个计算被称为一个操作节点(op节点),它们彼此相连。.
那么,为什么要用到图表呢?
- 可在不同的系统上运行。
- 该图表可以保存以备后用。
- 图中的所有计算都是通过将张量连接起来完成的。.
- 简而言之,在图中,每条边都是一个值(张量),每个节点都是一个运算符(例如加法)。.
TensorFlow为何如此出名?
TensorFlow之所以是最佳选择,是因为它面向所有用户,并提供可用于不同规模的深度学习架构(例如RNN、CNN)的API。由于它基于图计算,因此能够在TensorBoard中可视化神经网络,这对于调试非常有用。总而言之,TensorFlow在部署过程中就考虑到了可扩展性。.
好消息是,它在 GitHub 上拥有各种深度学习框架中最大的社区。.
TensorFlow 支持多少种算法?
- 线性回归:tf.estimator.LinearRegressor
- 分类:tf.estimator.LinearClassifier
- 深度分类:tf.estimator.DNNClassifier
- 深度学习擦除和深度:tf.estimator.DNNLinearCombinedClassifier
- BoostedTreesRegressor:tf.estimator.BoostedTreesRegressor
- 提升树分类:tf.estimator.BoostedTreesClassifier
几个简单的例子
- 12导入 numpy 库并将其命名为 np
- 导入 tensorflow as tf
以上两行代码导入了 numpy 和 tensorflow 库。.
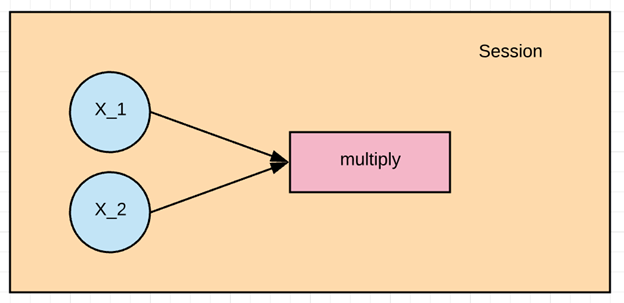
在这个例子中,我们要计算 X_1 和 X_2 的乘积。首先,我们需要创建计算图,然后运行 TensorFlow 会话来计算结果。.
我们开始吧。
步骤 1:定义变量
第一步是创建输入节点 X_1、X_2。在 TensorFlow 中,我们需要指定要创建的节点类型,这里我们选择占位符类型。.
占位符:
这种类型每次执行计算时都会为张量分配一个新值。.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
如您所见,我们将此节点的类型输入为浮点数,并将其名称输入为变量名。.
步骤 2:定义计算
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
通过上面的代码,我们创建了一个顶点,它充当乘法运算符。
这就是我们要进行乘法运算的顶点的输入,我们将其命名为 multiply。
现在我们已经创建了第一个图表。.
步骤 3:执行操作
要执行此操作,我们需要创建一个会话。此会话使用 tf.Session() 创建,并在我们使用 run 时执行。.
当我们要进行乘法运算时,需要将张量 x1 和 x2 的值作为输入。这可以通过赋值 feed_dict 来实现。在本例中,x1 被赋值为 1 到 3,x2 被赋值为 4 到 6。然后我们打印结果。.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
- 使用 tf.Session() 作为 session:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- 打印(结果)
- [ 4. 10. 18.]
将数据导入 TensorFlow 的不同方法
训练模型之前的首要步骤之一是导入数据,导入数据有两种模式:
- 将数据输入 RAM:有一种简单的方法可以将数据输入内存数组,例如,通过编写一行 Python 代码。.
- 使用 TensorFlow 数据管道:TensorFlow 提供了一系列 API,可以帮助您接收数据、对其执行一系列操作,然后将其提供给您的算法。这种方法非常有效,尤其是在数据量非常大的情况下。例如,图像通常非常大,无法全部加载到内存中。这时,数据管道可以帮您管理内存。.
现在的问题是该用哪一个。
如果您的数据小于 10 GB,您可以轻松使用第一种方法,例如,pandas 就是一个著名的数据处理库。否则,例如,如果您有 30 GB 的数据,而您的内存只有 12 GB,那么您自然无法使用此方法,而应该使用 Pipeline API。Pipeline 会对数据进行分批处理,并将每个批次的数据输入到 Pipeline 中,用于训练模型。使用 Pipeline 可以让您使用并行处理。这意味着 TensorFlow 可以同时在多个不同的 CPU 上训练模型。.
简而言之,如果数据量较小,可以将其完全加载到内存中,例如使用 pandas。否则,或者如果您想使用多个 CPU,请使用 TensorFlow 流水线。.
在 TensorFlow 中创建管道
步骤 1)创建数据
我们使用 numpy 库生成两个随机数。
- 123导入 numpy 库并将其命名为 np
- x_input = np.random.sample((1,2))
- print(x_input)
- 1[[0.8835775 0.23766977]]
步骤 2)创建占位符
在此步骤中,我们创建一个名为 X 的占位符,它是一个包含两个浮点类型成员的数组。
- 使用占位符 #
- x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
步骤 3:创建数据集
此时,我们需要定义一个数据集,我们将把占位符值 x 放入其中。.
- 1tf.data.Dataset.from_tensor_slices
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
第四步:构建管道
在这一步中,我们需要初始化管道。第一步是创建一个迭代器来遍历数据。使用 `get_next` 方法可以获取下一个值。在本例中,有一个批次只有两个值。.
- 12iterator = dataset.make_initializable_iterator()
- get_next = iterator.get_next()
步骤 5:运行计算
最后一步,我们运行一个会话,其输入是一个迭代器和由 numpy 创建的输入值,并打印每个迭代器的值。.
- 使用 tf.Session() 作为 session:
- # 将数据提供给占位符
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))
- 1[0.8835775 0.23766978]
概括
TensorFlow 是最著名的深度学习库,可用于构建任何深度学习框架。Google Brain 开发此项目旨在弥合研究团队和开发团队之间的鸿沟,Google 几乎在其所有项目中都使用它。使用 TensorFlow 的主要原因之一是其部署时的可扩展性。TensorFlow 可用于从高性能服务器到 Android 和 iOS 手机的各种应用场景。.
TensorFlow 在会话中运行,每个会话都由一个包含不同计算的图定义。.
以 TensorFlow 中的乘法为例,简单来说如下:
1. 变量定义
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
2. 计算的定义
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
3. 操作执行
- 使用 tf.Session() 作为 session:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- 打印(结果)
在 TensorFlow 中,一种常见的做法是创建一个管道将数据加载到 RAM 中,这可以通过以下步骤完成:
1. 数据创建
- 导入 numpy 库并将其命名为 np
- x_input = np.random.sample((1,2))
- print(x_input)
2. 创建占位符
- 1x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
3. 数据集方法定义
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
4. 管道建设
- 1iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
5. 程序执行
- 使用 tf.Session() 作为 session:
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))









