









介绍
想象一下,能够与非结构化数据进行对话,并轻松提取有价值的信息。在当今数据驱动的环境中,从非结构化文档中提取有意义的洞察仍然是一项挑战,阻碍了决策和创新。在本教程中,我们将了解词嵌入,探索如何使用 Amazon Open Search 作为向量数据库,并将 Langchain 框架与大型语言模型 (LLM) 集成,以构建一个嵌入了自然语言处理 (NLP) 聊天机器人的网站。我们将介绍 LLM 的基础知识,并借助开源的大型语言模型从非结构化文档中提取有意义的洞察。在本教程结束时,您将全面了解如何从非结构化文档中获取有意义的洞察,并运用这些技能探索和创新类似的基于全栈 AI 的解决方案。.
先决条件
- 您必须拥有有效的AWS账户。如果您还没有账户,可以在AWS网站上注册。.
- 请确保已在本地计算机上安装 AWS 命令行界面 (CLI),并已使用所需的凭证和默认区域正确配置。您可以使用 `aws configure` 命令进行配置。.
- 下载并安装 Docker Engine。请按照适用于您操作系统的安装说明进行操作。.
我们要建造什么?
在这个例子中,我们想要模拟许多公司面临的一个问题。如今,大量数据都是非结构化的,而且结构非常不规范,例如音频和视频转录、PDF 和 Word 文档、手册、扫描笔记、社交媒体文字记录等等。我们将使用 Flan-T5 XXL 模型作为逻辑学习模型 (LLM)。该模型可以从非结构化文本中生成摘要和问答。下图展示了不同构建模块的架构。.

让我们从基础知识开始。
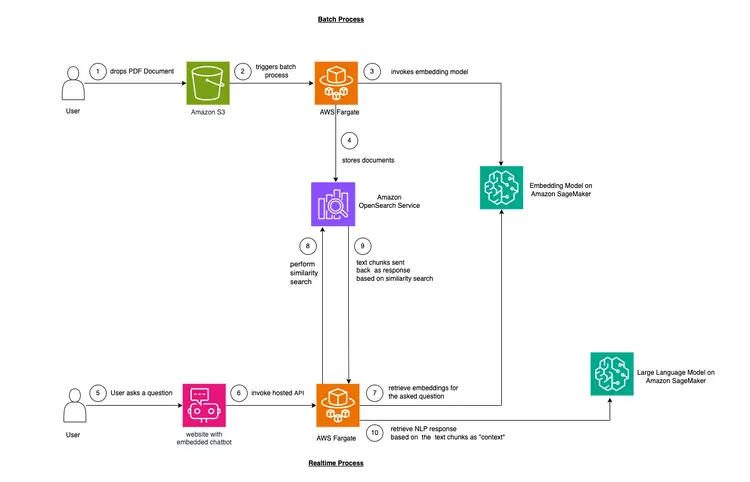
我们将使用一种名为“上下文学习”的技术,将特定领域或案例的«上下文»注入到我们的学习型模型(LLM)中。在这个例子中,我们有一份非结构化的汽车PDF手册,我们希望将其作为LLM的“上下文”,并让LLM能够回答关于这份手册的问题。就这么简单!我们的目标是更进一步,创建一个实时API,它可以接收问题,将问题发送到我们的后端,并通过嵌入网站的开源聊天机器人进行访问。本教程将帮助我们构建完整的用户体验,并在整个过程中深入了解各种概念和工具。.
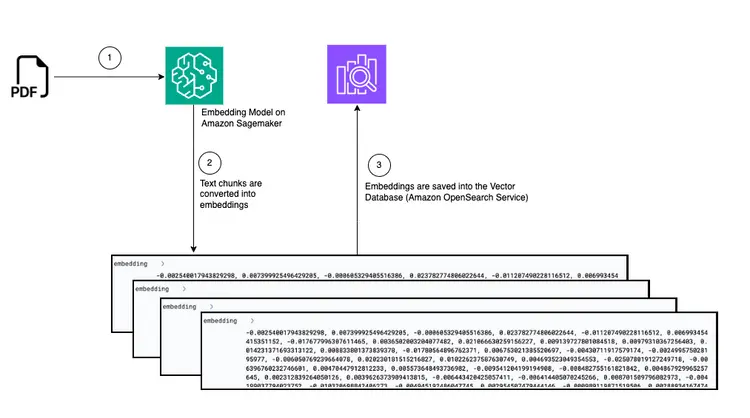
- 实现文本内学习的第一步是导入 PDF 文档并将其转换为文本块,生成这些文本块的向量表示(称为“嵌入”),最后将这些嵌入存储在向量数据库中。.
- 向量数据库使我们能够对它们存储的文本嵌入执行«相似性搜索»。.
- Amazon SageMaker JumpStart 提供一键部署解决方案模板,用于设置开源预训练模型的基础架构。我们将使用 Amazon SageMaker JumpStart 来部署嵌入模型和大型语言模型。.
- Amazon OpenSearch 是一个搜索和分析引擎,可以搜索向量空间中点的最近邻,因此适合用作向量数据库。.
图表:将 PDF 文件转换为可嵌入矢量数据库的格式
步骤 1 - 使用 Amazon SageMaker JumpStart 部署 GPT-J 6B FP16 嵌入模型
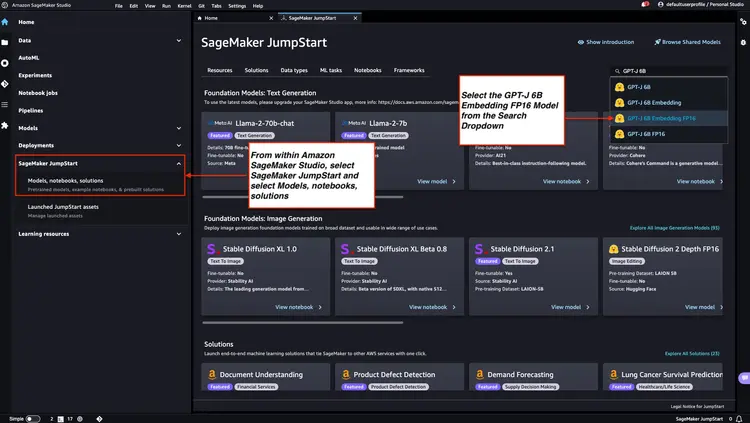
按照 Amazon SageMaker 文档中的步骤操作——打开并使用 JumpStart 部分,从 Amazon SageMaker Studio 的主菜单启动 Amazon SageMaker JumpStart 节点。选择‘模型、笔记本、解决方案’,然后选择 GPT-J 6B Embedding FP16 嵌入模型(如下图所示)。接下来,单击“部署”,Amazon SageMaker JumpStart 将负责设置基础架构,以便将此预训练模型部署到 SageMaker 环境。.
步骤 2 - 使用 Amazon SageMaker JumpStart 部署 Flan T5 XXL LLM
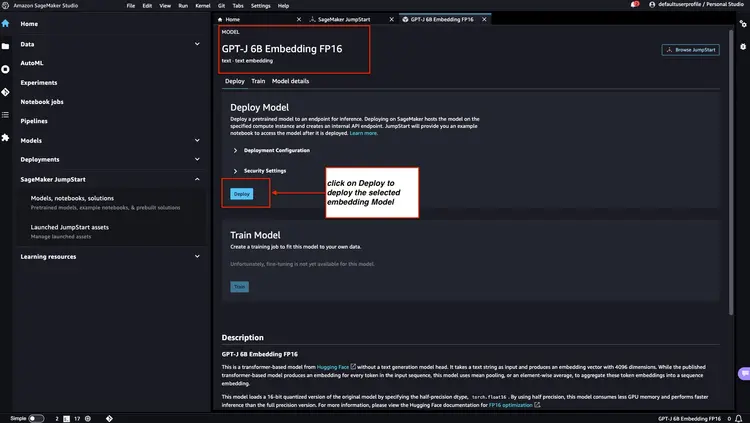
接下来,在 Amazon SageMaker JumpStart 中,选择 Flan-T5 XXL LLM,然后单击‘部署’以开始自动基础架构设置并将模型端点部署到 Amazon SageMaker 环境。.
步骤 3 - 检查已部署模型端点的状态
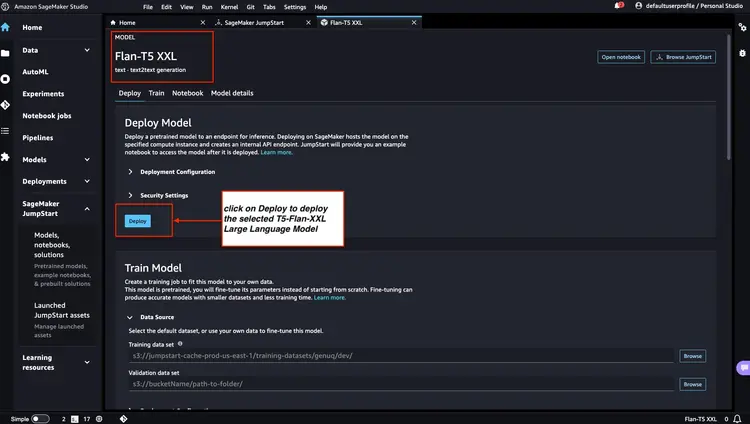
我们在 Amazon SageMaker 控制台中检查步骤 1 和步骤 2 中部署的模型端点的状态,并记下它们的端点名称,因为我们将在代码中使用它们。以下是部署模型端点后我的控制台显示的内容。.
步骤 4 – 创建 Amazon Open Search 集群
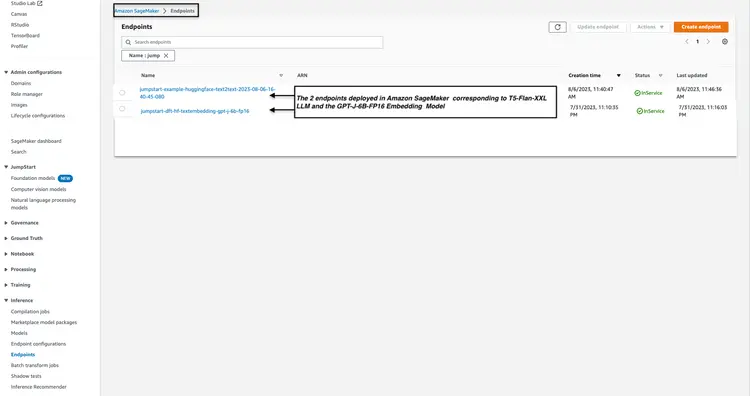
Amazon OpenSearch 是一项搜索和分析服务,支持 k 近邻 (kNN) 算法。这项功能对于基于相似性的搜索至关重要,使我们能够有效地将 OpenSearch 用作向量数据库。要进一步了解支持 kNN 插件的 Elasticsearch/OpenSearch 版本,请参阅以下链接:kNN 插件文档。.
我们使用 AWS CLI 从 GitHub 位置部署 AWS CloudFormation 模板文件。 Infrastructure/opensearch-vectordb.yaml 我们将使用aws命令。 cloudformation 创建堆栈 运行以下命令创建 Amazon Open Search 集群。运行命令前,您需要将命令中的值替换为您自己的值。 用户名 和 密码 我们开始做吧。.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> 步骤 5 – 构建文档捕获和嵌入工作流程
在此步骤中,我们将创建一个摄取和处理管道,用于读取放置在 Amazon Simple Storage Service (S3) 存储桶中的 PDF 文档。此管道将执行以下任务:
- 从PDF文档中提取文本。.
- 将文本片段转换为嵌入(向量表示)。.
- 在亚马逊开放搜索中保存嵌入内容。.
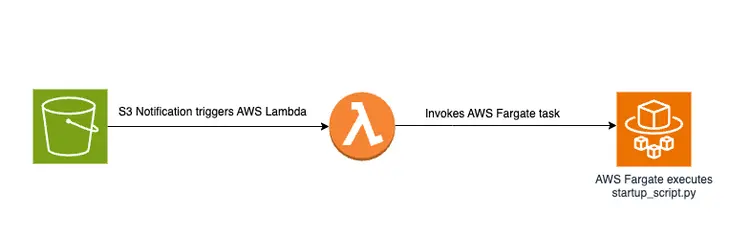
将 PDF 文件拖放到 S3 存储桶中会触发一个事件驱动型工作流,其中包括一个 AWS Fargate 作业。该作业负责将文本转换为嵌入内容并将其插入到 Amazon Open Search 中。.
图解概述
下图展示了将嵌入式文本片段存储到 Amazon OpenSearch 矢量数据库中的文档传输管道:
启动脚本和文件结构
文件的主要逻辑 create-embeddings-save-in-vectordb\startup_script.py 此Python脚本位于 startup_script.py该脚本执行与文档处理、文本嵌入和插入 Amazon Open Search 集群相关的多项任务。它从 Amazon S3 存储桶下载 PDF 文档,然后将下载的文档分割成更小的文本块。对于每个文本块,脚本会将文本内容发送到部署在 Amazon SageMaker 中的 GPT-J 6B FP16 嵌入模型端点(可通过环境变量 TEXT_EMBEDDING_MODEL_ENDPOINT_NAME 获取)以创建文本嵌入。创建的嵌入将与其他信息一起放入 Amazon Open Search 索引中。该脚本从环境变量中检索配置和验证参数,并确保这些参数在不同环境中保持一致。该脚本旨在 Docker 容器中统一运行。.
构建并发布 Docker 镜像
在理解了代码之后 startup_script.py我们从该文件夹构建 Dockerfile。 创建嵌入并保存到 VectorDB 接下来,我们将把镜像推送到 Amazon Elastic Container Registry (Amazon ECR)。Amazon Elastic Container Registry (Amazon ECR) 是一个完全托管的容器注册表,提供高性能托管服务,因此我们可以可靠地将应用程序镜像和工件部署到任何位置。我们将使用 AWS CLI 和 Docker CLI 来构建 Docker 镜像并将其推送到 Amazon ECR。在以下所有命令中,请替换为正确的AWS账户号码。.
在 AWS CLI 中检索身份验证令牌并对 Docker 客户端进行身份验证,使其能够访问注册表。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com 使用以下命令构建 Docker 镜像。.
docker build -t save-embedding-vectordb .
构建完成后,给镜像打上标签,以便我们可以将镜像推送到此仓库:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
运行以下命令将此镜像推送到新的 Amazon ECR 存储库:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Docker 镜像上传到 Amazon ECR 存储库后,应该类似于下图:
构建基于事件的 PDF 嵌入工作流程的基础架构
我们可以使用 AWS 命令行界面 (AWS CLI) 和提供的参数为事件驱动型工作流创建 CloudFormation 堆栈。CloudFormation 模板可在 GitHub 存储库中找到。 Infrastructure/fargate-embeddings-vectordb-save.yaml 我们需要忽略参数以匹配 AWS 环境。.
以下是需要在命令中更新的关键参数 aws cloudformation create-stack 文中指出:
- BucketName:此参数表示我们将存放 PDF 文档的 Amazon S3 存储桶。.
- VpcId 和 SubnetId:这些参数指定 Fargate 任务将在哪里运行。.
- ImageName:这是 Amazon Elastic Container Registry (ECR) 中 save-embedding-vectordb 的 Docker 镜像的名称。.
- TextEmbeddingModelEndpointName:使用此参数提供在步骤 1 中部署在 Amazon SageMaker 中的 Embedding 模型的名称。.
- VectorDatabaseEndpoint:指定 Amazon OpenSearch 域的端点地址。.
- VectorDatabaseUsername 和 VectorDatabasePassword:这些参数是访问步骤 4 中创建的 Amazon Open Search 集群所需的凭证。.
- VectorDatabaseIndex:设置 Amazon Open Search 中存储 PDF 文档嵌入的索引名称。.
更新参数值后,要执行 CloudFormation 堆栈创建,我们使用以下 AWS CLI 命令:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanual通过创建上述 CloudFormation 堆栈,我们设置了一个 S3 存储桶并创建了 S3 通知,该通知会启动一个 Lambda 函数。此 Lambda 函数进而启动一个 Fargate 任务。Fargate 任务会创建一个包含该文件的 Docker 容器。 启动脚本.py 实现负责在名为“新 OpenSearch 索引”的 Amazon OpenSearch 索引下创建嵌入式内容的功能。 汽车手册 这是。.
使用 PDF 样本进行测试
CloudFormation 堆栈运行后,将机器手册的 PDF 文件上传到您的 S3 存储桶。我已从此处下载了机器手册。事件驱动传输管道运行完毕后,Amazon Open Search 集群应包含以下配置文件: 汽车手册 嵌入方式如下所示。.
步骤 6 – 实现支持 LLM 文本的实时问答 API
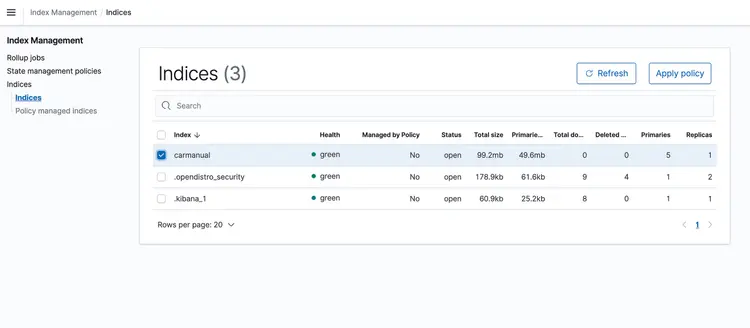
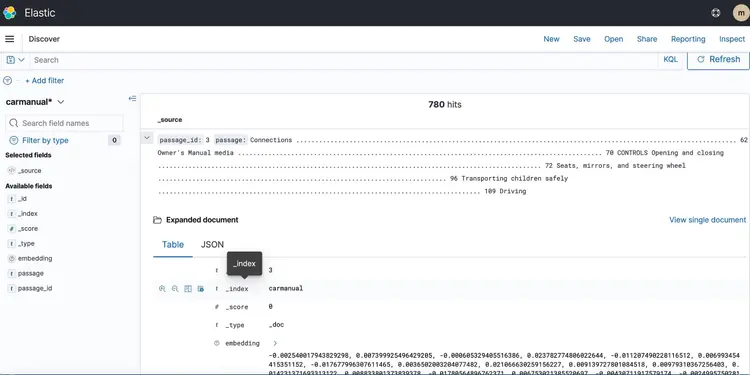
现在我们已经将文本嵌入到由 Amazon Open Search 提供支持的矢量数据库中,接下来让我们进入下一步。在这里,我们将利用 T5 Flan XXL LLM 的功能,为我们的汽车手册提供实时答案。.
我们利用存储在向量数据库中的词嵌入为语言学习模型(LLM)提供上下文信息。这种上下文信息使LLM能够有效地理解并回答有关我们汽车手册的问题。为了实现这一点,我们将使用一个名为LangChain的框架,该框架简化了LLM设计的实时、文本感知问答系统所需的各种组件的协调工作。.
存储在向量数据库中的词嵌入描述了词语的含义和关系,并允许我们基于语义相似性进行计算。词嵌入创建文本片段的向量表示以捕捉其含义和关系,而T5 Flan LLM则专注于根据注入到请求和查询中的上下文创建上下文相关的答案。其目标是通过为问题创建词嵌入,然后衡量这些词嵌入与存储在向量数据库中的其他词嵌入的相似度,从而将用户问题与文本片段进行匹配。.
通过将文本片段和用户查询表示为向量,我们可以进行数学计算,从而实现上下文感知相似性搜索。为了衡量两个数据点之间的相似性,我们使用多维空间中的距离度量。.
下图展示了 LangChain 和我们的 T5 Flan LLM 提供的实时问答工作流程。.
T5-Flan-XXL LLM 实时问答支持的图形化概览
构建 API
现在我们已经回顾了 LangChain 和 T5 Flask LLM 的工作流程,接下来让我们深入了解 API 代码,该代码接收用户提问并提供上下文相关的答案。这个实时问答 API 位于我们 GitHub 仓库的 RAG-langchain-questionanswer-t5-llm 文件夹中,其核心逻辑位于 app.py 文件中。这个基于 Flask 的应用程序定义了一个用于回答问题的 /qa 路由。.
当用户向 API 提交查询时,API 会使用环境变量 TEXT_EMBEDDING_MODEL_ENDPOINT_NAME 并指向 Amazon SageMaker 端点,将查询转换为称为嵌入的数值向量表示。这些嵌入捕捉了文本的语义含义。.
该 API 还利用 Amazon OpenSearch 执行上下文感知相似性搜索,使其能够根据用户查询中获取的嵌入信息,从 OpenSearch 目录工作指南中提取相关的文本片段。之后,API 会调用由环境变量 T5FLAN_XXL_ENDPOINT_NAME 标识的 T5 Flan LLM 端点,该端点也部署在 Amazon SageMaker 中。该端点使用从 Amazon OpenSearch 检索到的文本片段作为上下文来生成响应。这些从 Amazon OpenSearch 获取的文本片段为 T5 Flan LLM 端点提供了重要的上下文信息,使其能够为用户查询提供有意义的响应。API 代码使用 LangChain 来协调所有这些交互。.
构建并发布 API 的 Docker 镜像
在理解了 app.py 中的代码之后,我们将继续从 RAG-langchain-questionanswer-t5-llm 文件夹构建 Dockerfile,并将镜像推送到 Amazon ECR。我们将使用 AWS CLI 和 Docker CLI 来构建 Docker 镜像并将其推送到 Amazon ECR。在以下所有命令中,请替换为正确的AWS账户号码。.
在 AWS CLI 中检索身份验证令牌并对 Docker 客户端进行身份验证,使其能够访问注册表。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
使用以下命令构建 Docker 镜像。.
docker build -t qa-container .
构建完成后,给镜像打上标签,以便我们可以将镜像推送到此仓库:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
运行以下命令将此镜像推送到新的 Amazon ECR 存储库:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Docker 镜像上传到 Amazon ECR 存储库后,应该类似于下图:
构建 CloudFormation 堆栈以托管 API 端点
我们将使用 AWS 命令行界面 (CLI) 为托管 Fargate 任务以公开 API 的 Amazon ECS 集群创建一个 CloudFormation 堆栈。CloudFormation 模板位于 GitHub 仓库的 Infrastructure/fargate-api-rag-llm-langchain.yaml 文件中。我们需要覆盖参数以匹配 AWS 环境。以下是需要在 `aws cloudformation create-stack` 命令中更新的关键参数:
- DemoVPC:此参数指定您的服务将在其中运行的虚拟私有云 (VPC)。.
- PublicSubnetIds:此参数需要一个公共子网 ID 列表,负载均衡器和任务将位于这些子网中。.
- IMAGENAME:提供 Amazon Elastic Container Registry (ECR) 中 qa 容器的 Docker 镜像名称。.
- TextEmbeddingModelEndpointName:指定在步骤 1 中部署在 Amazon SageMaker 中的 Embeddings 模型的端点名称。.
- T5FlanXXLEndpointName:设置在步骤 2 中部署在 Amazon SageMaker 上的 T5-FLAN 端点名称。.
- VectorDatabaseEndpoint:指定 Amazon OpenSearch 域的端点地址。.
- VectorDatabaseUsername 和 VectorDatabasePassword:这些参数是访问步骤 4 中创建的 OpenSearch 集群所需的凭据。.
- VectorDatabaseIndex:设置 Amazon OpenSearch 中用于存储服务数据的索引名称。本示例中使用的索引名称为 carmanual。.
更新参数值后,要执行 CloudFormation 堆栈创建,我们使用以下 AWS CLI 命令:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanual成功运行上述 CloudFormation 堆栈后,请转到 AWS 控制台并访问 ecs-questionanswer-llm 堆栈的‘CloudFormation 输出’选项卡。在此选项卡中,我们将找到必要的信息,包括 API 端点。以下是输出示例:
测试 API
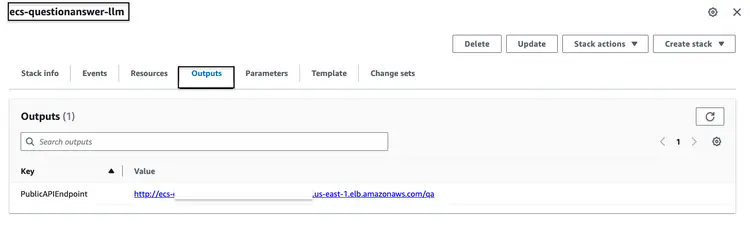
我们可以通过 curl 命令测试 API 端点,如下所示:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
我们会看到类似下面的回应。
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
步骤 7 – 创建并部署一个集成聊天机器人的网站
接下来,我们将进入全栈流水线的最后一步,即将 API 与 HTML 网站中的嵌入式聊天机器人集成。对于这个网站和嵌入式聊天机器人,我们的源代码是一个 Node.js 应用程序,包含一个 index.html 文件,其中集成了开源的 botkit.js 聊天机器人。为了方便起见,我已经创建了一个 Dockerfile,并将其与代码一起放在了 homegrown_website_and_bot 文件夹中。我们将使用 AWS CLI 和 Docker CLI 来构建 Docker 镜像,并将其推送到 Amazon ECR,用于前端网站。以下所有命令中,请替换为正确的AWS账户号码。.
在 AWS CLI 中检索身份验证令牌并对 Docker 客户端进行身份验证,使其能够访问注册表。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
使用以下命令构建 Docker 镜像:
docker build -t web-chat-frontend .
构建完成后,给镜像打上标签,以便我们可以将镜像推送到此仓库:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
运行以下命令将此镜像推送到新的 Amazon ECR 存储库:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
将网站的 Docker 镜像推送到 ECR 仓库后,我们运行 Infrastructure\fargate-website-chatbot.yaml 文件来创建前端的 CloudFormation 堆栈。我们需要修改一些参数以匹配 AWS 环境。以下是需要在 aws cloudformation create-stack 命令中更新的关键参数:
- DemoVPC:此参数指定您的网站将部署到的虚拟私有云 (VPC)。.
- PublicSubnetIds:此参数需要一个公共子网 ID 列表,您的网站负载均衡器和任务将放置在这些子网中。.
- IMAGENAME:输入您的网站在 Amazon Elastic Container Registry (ECR) 中的 Docker 镜像名称。.
- QUESTURL:指定步骤 6 中部署的 API 端点的 URL。其格式为 http://它是 /qa。.
更新参数值后,要执行 CloudFormation 堆栈创建,我们使用以下 AWS CLI 命令:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qa第 8 步 – 查看汽车智能 AI 助手
成功构建上述 CloudFormation 堆栈后,请转到 AWS 控制台并访问 ecs-website-chatbot 堆栈的 CloudFormation 输出选项卡。在此选项卡中,我们将找到与前端关联的应用程序负载均衡器 (ALB) 的 DNS 名称。以下是输出示例:
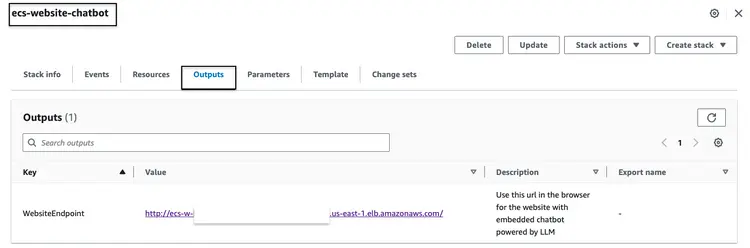
在浏览器中调用端点 URL,即可查看网站外观。向嵌入式聊天机器人提出自然语言问题。我们可以问的问题包括:“如何清洁挡风玻璃?”、“在哪里可以找到车辆识别码 (VIN)?”、“如何报告安全缺陷?”
接下来呢?

希望以上内容能帮助您了解如何构建自己的、可用于生产环境的LLM流程,以及如何将该流程与您的前端聊天机器人和嵌入式NLP集成。如果您还想了解关于使用开源技术、分析、机器学习和AWS的哪些内容,请告诉我!
在您继续学习的过程中,我鼓励您深入研究嵌入、向量数据库、LangChain 以及其他一些语言学习模型 (LLM)。这些内容在 Amazon SageMaker JumpStart 以及我们在本教程中使用的 AWS 工具(例如 Amazon OpenSearch、Docker 容器和 Fargate)中均有提供。以下是一些帮助您掌握这些技术的后续步骤:
- Amazon SageMaker:随着您不断深入使用 SageMaker,请熟悉它提供的其他算法。.
- 亚马逊开放搜索:了解 K-NN 算法和其他距离算法
- Langchain:LangChain 是一个旨在简化使用 LLM 创建应用程序的框架。.
- 嵌入:嵌入是对一段信息(例如文本、文档、图像、音频等)的数值表示。.
- Amazon SageMaker JumpStart:SageMaker JumpStart 提供针对各种问题类型的预训练开源模型,帮助您入门机器学习。.
擦除
- 登录 AWS CLI。确保 AWS CLI 已正确配置,并具有执行这些操作所需的权限。.
- 运行以下命令,从您的 Amazon S3 存储桶中删除 PDF 文件。请将“bucket name”替换为您的 Amazon S3 存储桶的实际名称,并根据需要调整 PDF 文件的路径。.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
删除 CloudFormation 堆栈。将堆栈名称替换为您的 CloudFormation 堆栈的实际名称。.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2结果
在本教程中,我们使用 AWS 技术和开源工具构建了一个全栈问答聊天机器人。我们集成了 Amazon OpenSearch 作为向量数据库、GPT-J 6B FP16 嵌入模型,并使用了带有 LLM 的 Langchain。该聊天机器人能够从非结构化文档中提取信息。.









