









介绍
近几周来,DeepSeek R1 在人工智能/机器学习领域引起了轰动,这并非偶然,其影响甚至波及到更广泛的领域,对经济和政策产生了重大影响。这主要归功于该模型套件的开源特性以及极低的训练成本,它向更广泛的群体表明,训练最先进的人工智能模型并不需要像之前认为的那样投入大量资金或进行专门的研究。.
在本系列的第一部分中,我们介绍了 DeepSeek R1 模型,并演示了如何使用 Olama 运行该模型。在本文中,我们将深入探讨 R1 模型的独特之处。我们将重点分析该模型独特的强化学习 (RL) 范式,了解如何仅通过 RL 来增强 LLM 的推理能力。然后,我们将讨论如何将这些技术提炼到其他模型中,从而使现有版本也能拥有这些能力。最后,我们将简要演示如何使用 GPU Droplets 的一键式模型来设置和运行 DeepSeek R1 模型。.
先决条件
- 深度学习: 本文涵盖了与神经网络训练和强化学习相关的中高级主题。.
- DigitalOcean账号: 我们将专门使用 DigitalOcean 的 HuggingFace 1-Click Model GPU Droplets 来测试 R1。.
DeepSeek R1 概述
DeepSeek R1 研究项目旨在重现强大推理模型(例如 OpenAI 的 O1)所展现的有效推理能力。为了实现这一目标,他们尝试使用纯强化学习来改进现有的 DeepSeek-v3-Base。由此诞生了 DeepSeek R1 Zero,该模型在推理指标上表现出色,但缺乏人类可理解性,并且表现出一些异常行为,例如语言混合。.
为了改进这些问题,他们提出了DeepSeek R1,该模型仅需少量冷启动数据,并采用多阶段训练流程。R1通过在数千个冷启动数据样本上对DeepSeek-v3-Base模型进行微调,然后运行另一轮强化学习,接着在论证数据集上进行监督式微调,最后再进行一轮强化学习,从而实现了目前最先进的LLM模型的可读性和适用性。之后,他们通过在R1收集的数据上监督其他模型的微调,将该技术推广到其他模型。.
敬请期待我们对这些开发阶段的深入探讨,以及如何迭代改进该模型以达到 DeepSeek R1 的功能。.
DeepSeek R1 Zero教程
为了创建 DeepSeek R1 Zero(R1 的基础模型),研究人员直接对基础模型应用了强化学习 (RL),而没有使用任何 SFT 数据。他们选择的强化学习范式称为群体相对策略优化 (GRPO)。该过程改编自 DeepSeekMath 论文。.
GRPO 与其他常见的强化学习系统类似,但有一个重要的区别:它不使用基准模型。GRPO 通过群体得分来估计基线。该系统的奖励模型包含两条规则,分别奖励模板的准确性和对特定模式的遵循程度。这些奖励随后作为训练信号的来源,用于调整强化学习优化的方向。这种基于规则的系统使得强化学习过程能够迭代地改进模型。.

训练模板本身是一个简单的书面格式,用于指导基础模型按照上述指定的指令进行训练。该模型会测量强化学习每个步骤中对«公告»集的响应。“这是一项重大成就,因为它突显了该模型仅通过强化学习就能有效学习和泛化的能力”(来源)。.
这种模型的自我演化使其发展出强大的推理能力,包括自我反思和考虑替代方案。在训练过程中,模型研究团队称之为“顿悟时刻”的时刻强化了这种能力。在这个阶段,DeepSeek-R1-Zero 通过重新评估其初始方法,学会投入更多时间思考问题。这种行为不仅证明了模型推理能力的不断提升,也生动地展现了强化学习如何带来意想不到的复杂结果。(来源).
DeepSeek R1 Zero 在各项基准测试中表现出色,但与真正人性化的语言学习模型相比,其可读性和易用性方面存在显著不足。因此,研究团队提出了 DeepSeek R1,旨在进一步提升模型在人类水平任务中的表现。.
从 DeepSee R1 Zero 到 DeepSee R1
为了从相对难以驾驭的 DeepSeek R1 Zero 过渡到功能更强大的 DeepSeek R1,研究人员引入了几个训练阶段。.
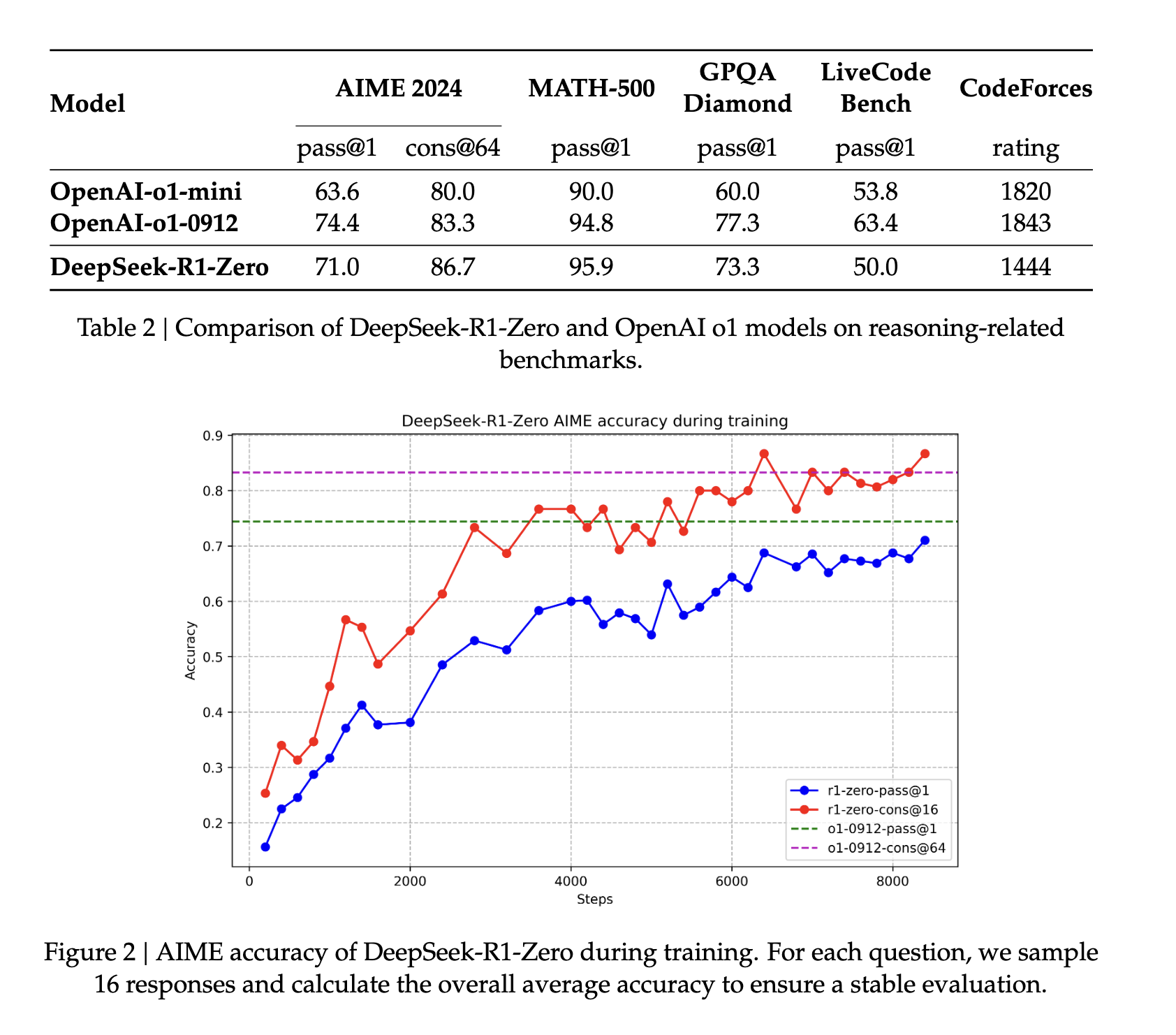
首先,DeepSeek-v3-Base 在运行与 DeepSeek R1 Zero 相同的强化学习范式之前,已使用数千个冷启动数据集进行了微调,并且输出结果的语言更加一致。实际上,这一步骤有助于增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等涉及明确定义问题和清晰解决方案的推理任务中(来源)。.
强化学习阶段完成后,生成的模型将用于收集新数据,以进行监督式微调。«与主要侧重于推理的初始冷启动数据不同,此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力»(来源)。.
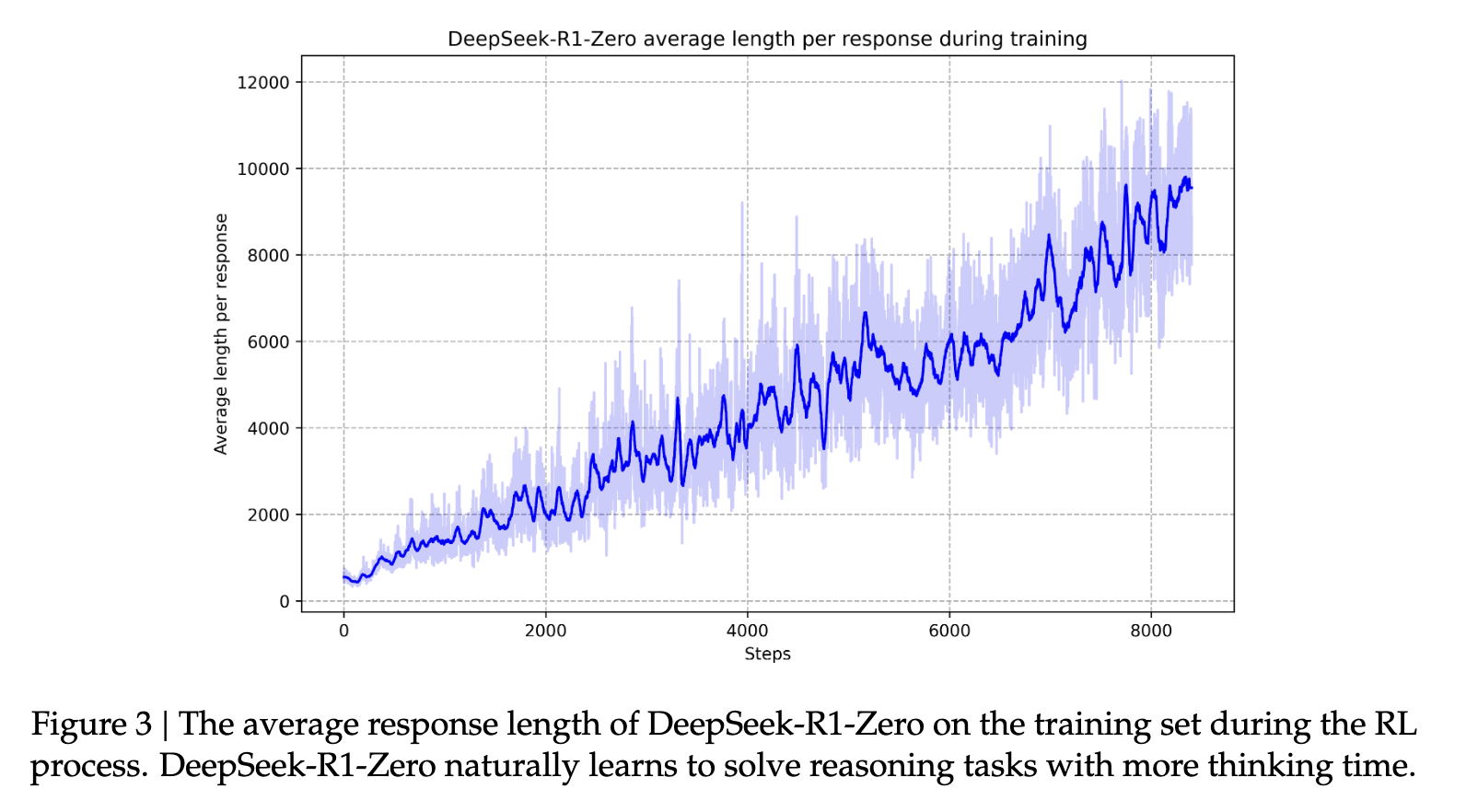
接下来,强化学习的第二阶段旨在“提高模型的实用性和无害性,同时提升其推理能力”(来源)。通过在各种带有奖励信号的快速分布上进一步训练模型,可以训练出一个在推理方面表现卓越,同时又兼顾实用性和无害性的模型。这有助于模型在响应速度上变得“像人类一样”。这也有助于模型发展出其为人称道的强大推理能力。随着时间的推移,这个过程有助于模型形成其特有的长链思维和推理能力。.
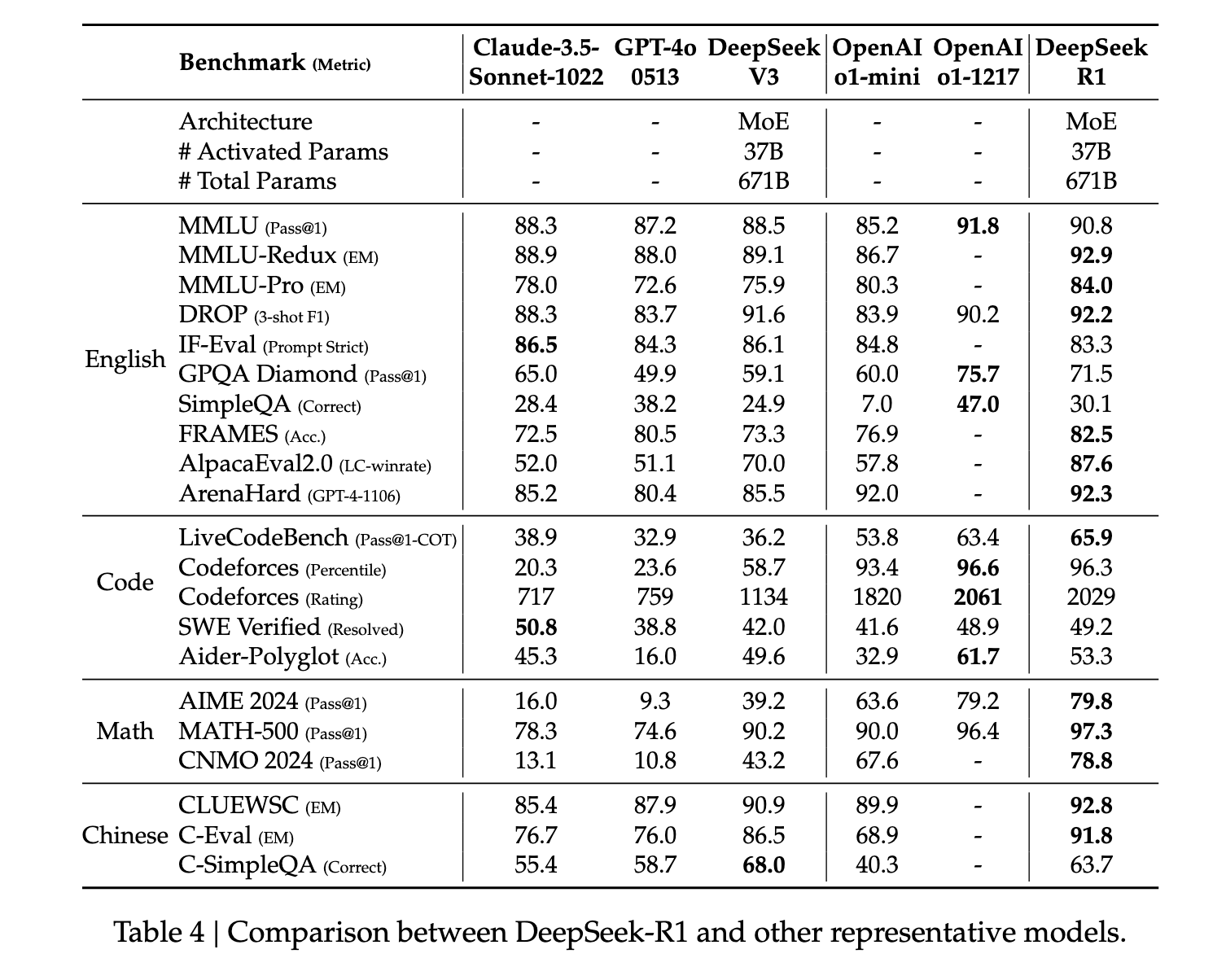
R1 在各项推理指标上均展现出最先进的性能。在某些任务中,例如数学,它甚至超越了已发表的 O1 基准测试结果。此外,它在与 STEM 相关的问题上也表现出色,这主要归功于大规模强化学习。除了 STEM 学科之外,该模型在回答问题、完成教育任务和进行复杂推理方面也表现出色。作者认为,这些改进和能力的提升源于强化学习对思维链处理模型的演进。在强化学习和微调过程中,会使用较长的思维链数据,以促使模型生成更长、更具内省性的输出。.
DeepSeek R1 精炼模型
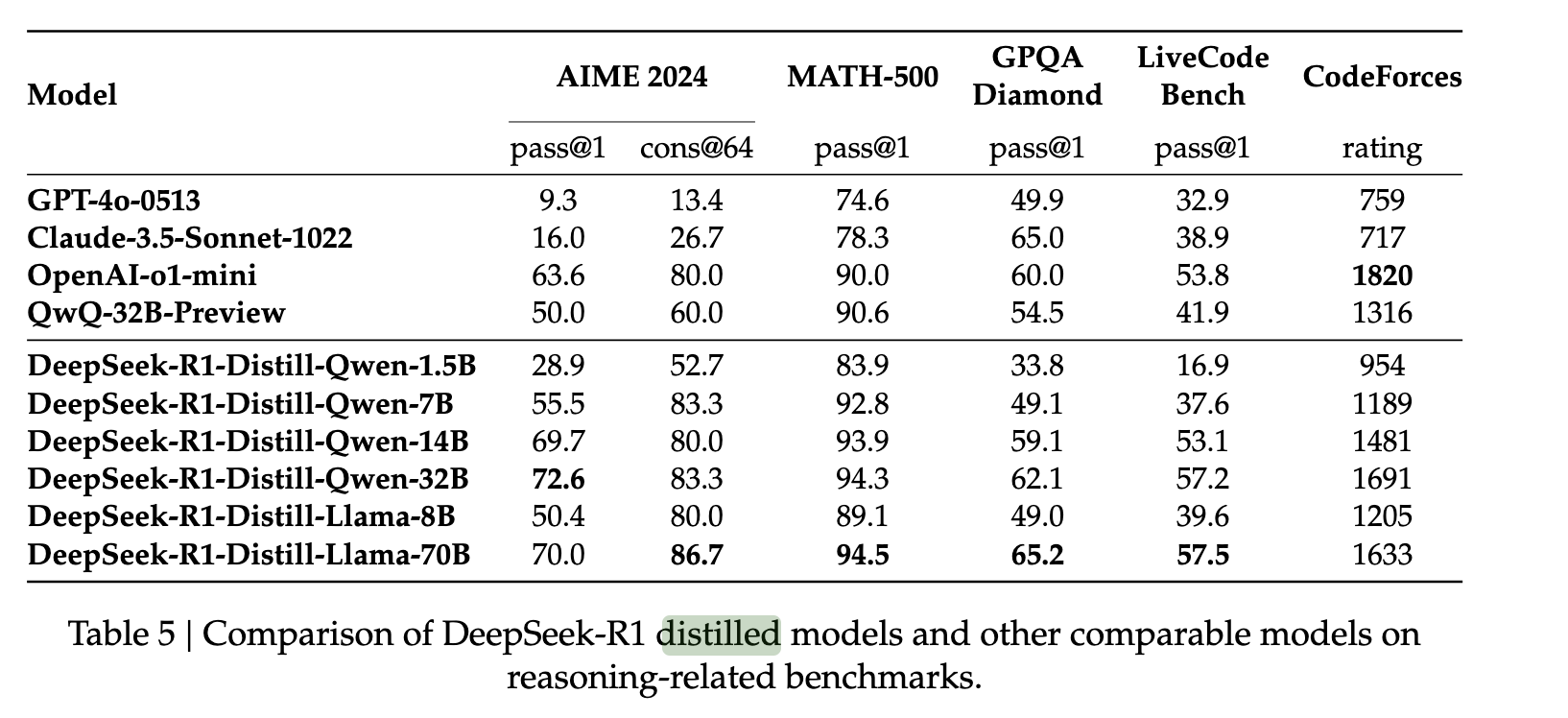 为了将 DeepSeek R1 的功能扩展到更小的模型,作者收集了 80 万个 DeepSeek R1 示例,并用它们来微调 QWEN 和 LLAMA 等模型。他们发现,这种相对简单的模型蒸馏方法能够非常成功地将 R1 的推理能力迁移到这些新模型中。他们无需任何额外的强化学习即可完成这项工作,这证明了原始模型响应对模型蒸馏的鲁棒性。.
为了将 DeepSeek R1 的功能扩展到更小的模型,作者收集了 80 万个 DeepSeek R1 示例,并用它们来微调 QWEN 和 LLAMA 等模型。他们发现,这种相对简单的模型蒸馏方法能够非常成功地将 R1 的推理能力迁移到这些新模型中。他们无需任何额外的强化学习即可完成这项工作,这证明了原始模型响应对模型蒸馏的鲁棒性。.
在 GPU Droplets 上启动 DeepSeek R1
如果您已经拥有 DigitalOcean 帐户,那么在 GPU Droplet 上设置 DeepSeek R1 非常简单。请务必在继续操作前登录。.
我们提供 R1 作为一键式 GPU 实例。要启动它,只需打开 GPU 实例控制台,转到型号选择窗口中的«一键式型号»选项卡,然后启动设备即可!
之后,您可以通过遵循 HuggingFace 或 OpenAI 的方法来访问该模型并与之通信。使用下面的脚本,您可以通过 Python 代码与模型进行交互。.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)此外,我们还创建了一个运行在同一系统上的自定义个人助理。我们建议您使用个人助理来执行这些任务,因为它通过一个简洁的图形用户界面窗口,简化了直接与模型交互的复杂性。有关使用个人助理脚本的更多信息,请参阅此教程。.
结果
总之,R1 是 LLM 开发社区向前迈出的一大步。他们的流程有望节省数百万美元的培训成本,同时还能提供与先进的闭源模型相媲美甚至更优的性能。我们将密切关注 DeepSeek,看看随着他们的模型获得国际认可,他们将如何继续发展壮大。.









