









giriiş
DeepSeek R1, son haftalarda haklı olarak yapay zeka/makine öğrenimi topluluğunu kasıp kavurdu ve hatta ekonomi ve politika açısından önemli sonuçlar doğurarak daha geniş bir alana yayıldı. Bu durum, büyük ölçüde model paketinin açık kaynaklı yapısından ve SOTA yapay zeka modellerini eğitmenin daha önce düşünüldüğü kadar büyük bir sermaye veya özel araştırma gerektirmediğini gösteren inanılmaz derecede düşük eğitim maliyetinden kaynaklanmaktadır.
Bu serinin ilk bölümünde DeepSeek R1'i tanıttık ve Olama kullanarak modelin nasıl çalıştırılacağını gösterdik. Bu devam bölümünde, R1'i gerçekten özel kılan şeylere daha derinlemesine bir bakış atacağız. Hukuk alanında lisans derecesi (LLM) öğrencilerinin akıl yürütme becerilerinin yalnızca RL aracılığıyla nasıl geliştirilebileceğini görmek için modelin benzersiz takviyeli öğrenme (RL) paradigmasını analiz etmeye odaklanacağız. Ardından, bu teknikleri diğer modellere entegre etmenin, bu yetenekleri mevcut sürümlerle paylaşmamızı nasıl sağladığını ele alacağız. Son olarak, GPU Droplets'in 1-Tık Modeli'ni kullanarak GPU Droplets ile DeepSeek R1 modellerinin nasıl kurulup çalıştırılacağına dair kısa bir gösteri ile bitireceğiz.
Ön koşullar
- Derin öğrenme: Bu makale, sinir ağlarının eğitimi ve takviyeli öğrenme ile ilgili orta ve ileri düzey konuları kapsamaktadır.
- DigitalOcean Hesabı: R1'i test etmek için özellikle DigitalOcean'ın HuggingFace 1-Click Model GPU Droplet'lerini kullanacağız.
DeepSeek R1 Genel Bakış
DeepSeek R1 araştırma projesi, güçlü akıl yürütme modelleri olan OpenAI'nin O1 modelinin sergilediği etkili akıl yürütme yeteneklerini yeniden yaratmayı amaçladı. Bu hedefe ulaşmak için, mevcut çalışmaları olan DeepSeek-v3-Base'i salt takviyeli öğrenme kullanarak geliştirmeye çalıştılar. Bu, akıl yürütme metriklerinde mükemmel performans gösteren, ancak insan yorumlama yeteneklerinden yoksun ve dil karıştırma gibi bazı sıra dışı davranışlar sergileyen DeepSeek R1 Zero'nun ortaya çıkmasına yol açtı.
Bu sorunları iyileştirmek için, az miktarda soğuk başlatma verisi ve çok aşamalı bir eğitim hattı içeren DeepSeek R1'i önerdiler. R1, DeepSeek-v3-Base modelini binlerce soğuk başlatma veri örneği üzerinde ince ayar yaparak, ardından bir takviyeli öğrenme turu daha çalıştırarak, ardından argüman veri kümesi üzerinde denetimli ince ayar yaparak ve son olarak son bir takviyeli öğrenme turuyla bitirerek SOTA LLM'nin okunabilirliğini ve uygulanabilirliğini elde ettiler. Daha sonra, R1'den toplanan veriler üzerinde denetimli ince ayar yaparak bu tekniği diğer modellere de uyguladılar.
Bu geliştirme aşamalarına daha derinlemesine bir bakış ve modelin DeepSeek R1'in yeteneklerine ulaşmak için nasıl yinelemeli olarak iyileştirilebileceğine dair bir tartışma için bizi izlemeye devam edin.
DeepSeek R1 Zero Eğitimi
R1'in geliştirildiği temel model olan DeepSeek R1 Zero'yu oluşturmak için araştırmacılar, herhangi bir SFT verisi olmadan doğrudan temel modele RL uyguladılar. Seçtikleri RL paradigmasına grup göreli politika optimizasyonu (GRPO) adı verildi. Bu süreç, DeepSeekMath makalesinden uyarlanmıştır.
GRPO, bilinen ve diğer RL sistemlerine benzer, ancak önemli bir noktada farklılık gösterir: kritik bir model kullanmaz. Bunun yerine, GRPO temel değeri grup puanlarından tahmin eder. Ödül modellemesinin bu sistem için iki kuralı vardır ve her biri şablonun bir kalıba uygunluğunu ve doğruluğunu ödüllendirir. Ödül daha sonra RL optimizasyonunun yönünü değiştirmek için kullanılan eğitim sinyallerinin kaynağı olarak işlev görür. Bu kural tabanlı sistem, RL sürecinin modeli yinelemeli olarak iyileştirmesine ve geliştirmesine olanak tanır.

Eğitim şablonu, temel modelin yukarıda belirtilen talimatlarımızı izlemesini sağlayan basit bir yazılı formattır. Model, RL'nin her adımı için belirlenen "duyuru" setine verilen yanıtları ölçer. "Bu, modelin yalnızca RL aracılığıyla etkili bir şekilde öğrenme ve genelleme yapma yeteneğini vurguladığı için önemli bir başarıdır" (kaynak).
Modelin bu kendi kendini evrimleştirmesi, öz-yansıtma ve alternatif yaklaşımları değerlendirme gibi güçlü akıl yürütme yetenekleri geliştirmesine yol açar. Bu durum, eğitim sırasında modelin araştırma ekibinin "aha anı" olarak adlandırdığı bir an ile pekiştirilir. Bu aşamada DeepSeek-R1-Zero, ilk yaklaşımını yeniden değerlendirerek bir probleme daha fazla düşünme zamanı ayırmayı öğrenir. Bu davranış, yalnızca modelin gelişen akıl yürütme yeteneklerinin bir kanıtı değil, aynı zamanda takviyeli öğrenmenin beklenmedik ve karmaşık sonuçlara nasıl yol açabileceğinin de büyüleyici bir örneğidir. (Kaynak).
DeepSeek R1 Zero, kıyaslamalarda oldukça iyi performans gösterdi, ancak okunabilirlik ve kullanılabilirlik açısından, gerçek, insan dostu LLM programlarına kıyasla büyük ölçüde geriledi. Bu nedenle araştırma ekibi, modeli insan düzeyindeki görevler için daha iyi hale getirmek amacıyla DeepSeek R1'i önerdi.
DeepSeek R1 Zero'dan DeepSeek R1'e
Nispeten evcilleştirilmemiş DeepSeek R1 Zero'dan çok daha işlevsel DeepSeek R1'e geçmek için araştırmacılar birkaç eğitim aşaması tanıttı.
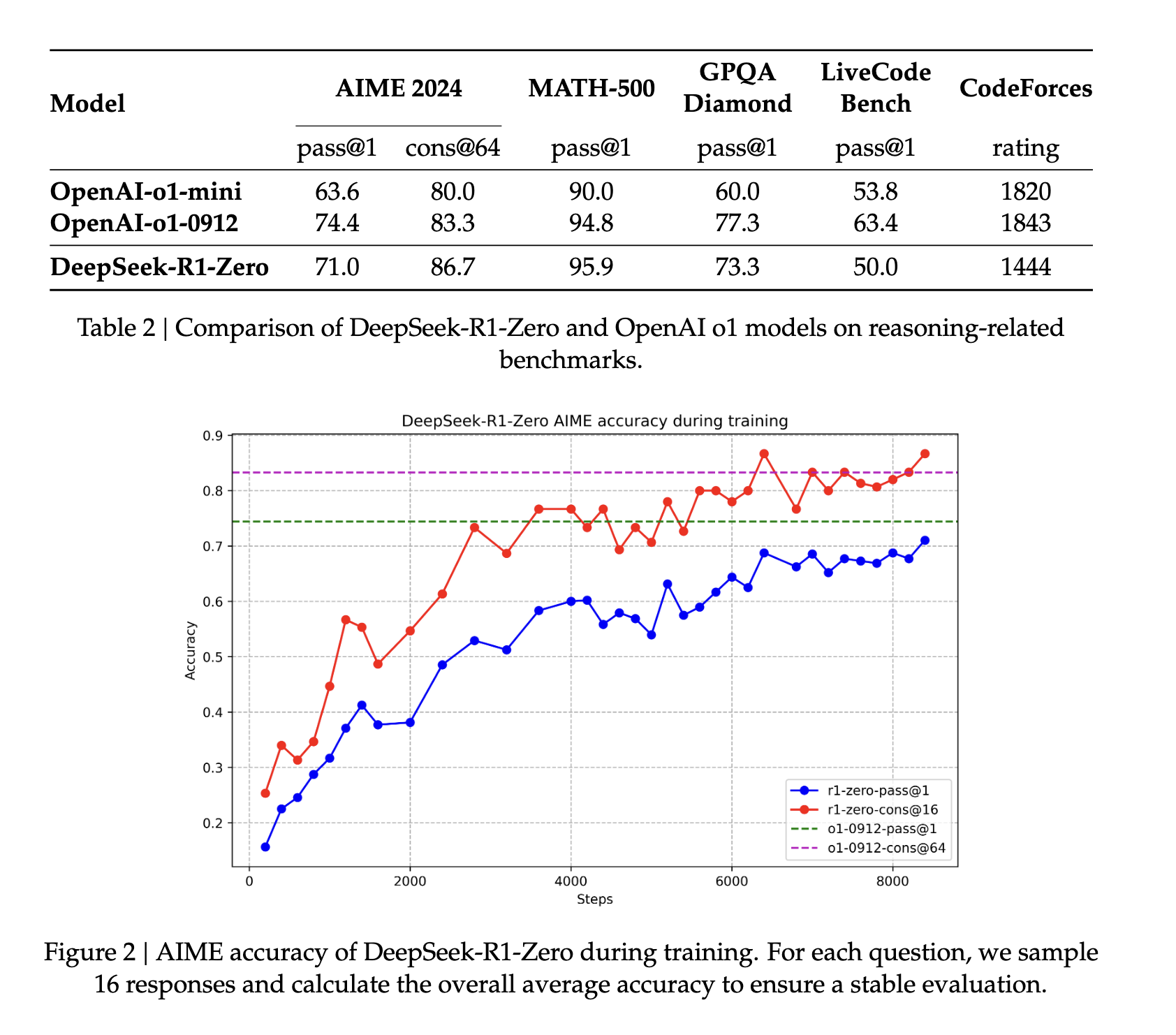
Başlangıç olarak, DeepSeek-v3-Base, DeepSeek R1 Zero için kullanılan aynı RL paradigmasını çalıştırmadan önce binlerce soğuk başlangıç veri parçası üzerinde ince ayar yapıldı ve çıktılarda tutarlı bir dilin ek avantajı sağlandı. Uygulamada, bu adım, özellikle net çözümleri olan iyi tanımlanmış problemleri içeren kodlama, matematik, fen ve mantıksal akıl yürütme gibi akıl yürütme görevlerinde modelin akıl yürütme yeteneklerini geliştirmeye yarar (kaynak).
Bu RL aşaması tamamlandığında, ortaya çıkan model, denetlenen ince ayar için yeni veriler toplamak amacıyla kullanılır. "Öncelikle muhakemeye odaklanan ilk soğuk başlangıç verilerinin aksine, bu aşama, modelin yazma, rol yapma ve diğer genel amaçlı görevlerdeki yeteneklerini geliştirmek için diğer alanlardan verileri birleştirir" (kaynak).
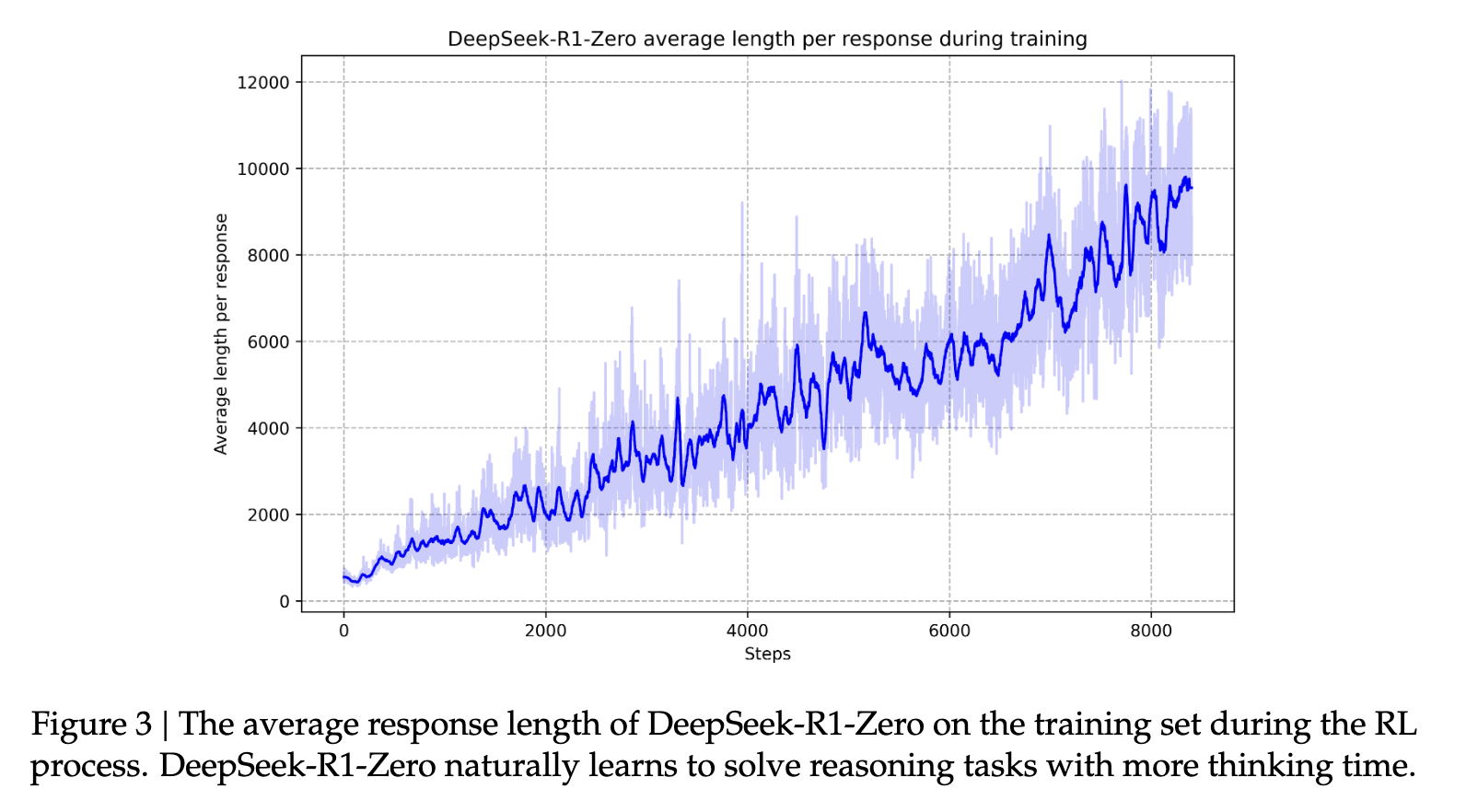
Ardından, RL'nin ikinci aşaması, "modelin kullanışlılığını ve zararsızlığını artırırken aynı zamanda muhakeme yeteneklerini de geliştirmek" için uygulanır (kaynak). Modeli ödül sinyalleriyle çeşitli hızlı dağıtımlar üzerinde daha fazla eğiterek, kullanışlılık ve zararsızlığa öncelik verirken muhakemede mükemmel olan bir model eğitebilirler. Bu, modellerin tepkiselliklerinde "insan benzeri" hale gelmelerine yardımcı olur. Bu, modelin bilinen inanılmaz muhakeme yeteneklerini geliştirmesine yardımcı olur. Zamanla, bu süreç modelin kendisini karakterize eden uzun düşünce ve muhakeme zincirleri geliştirmesine yardımcı olur.
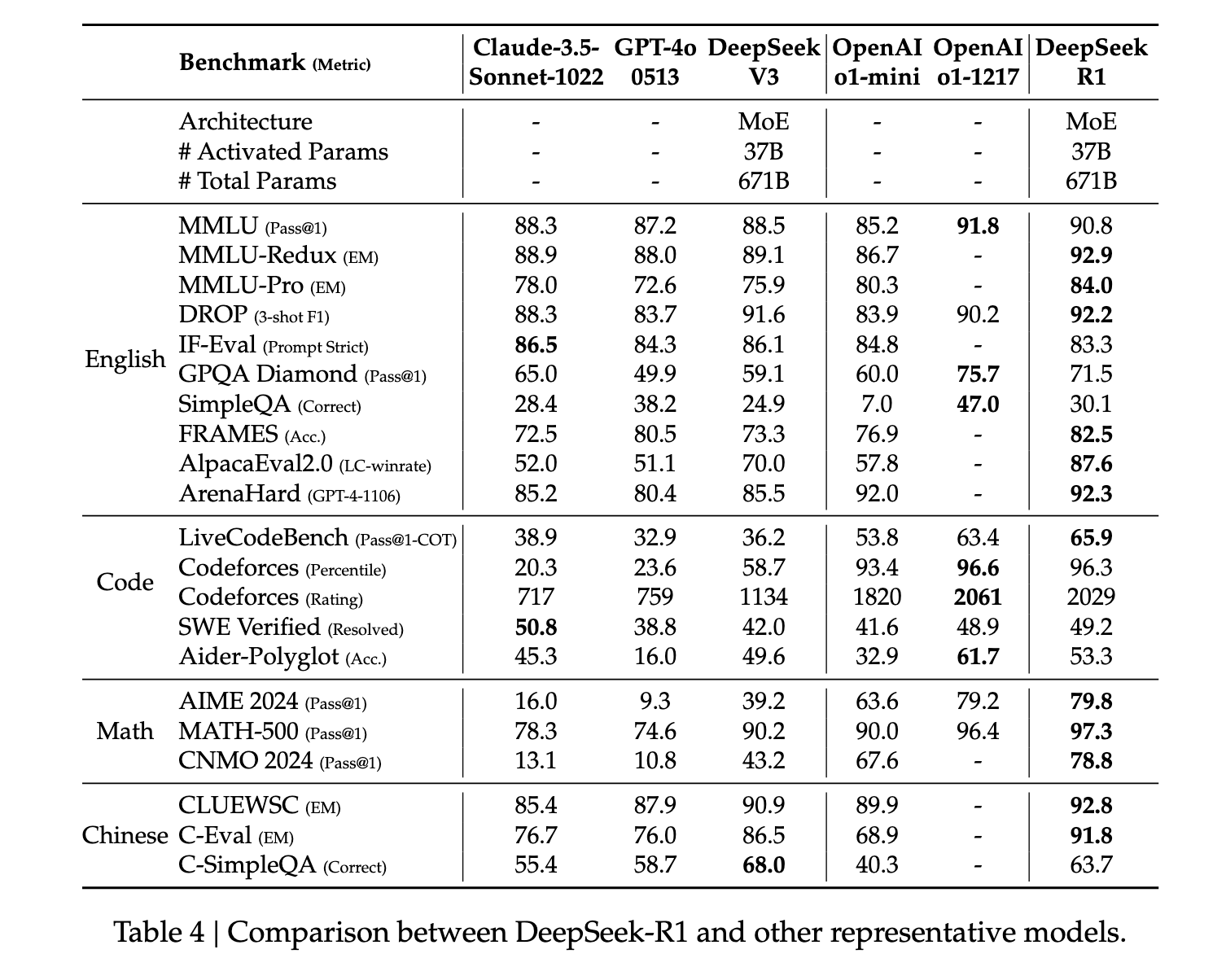
Genel olarak, R1 muhakeme ölçümlerinde en son teknoloji performansını göstermektedir. Matematik gibi bazı görevlerde, O1 için yayınlanmış kıyaslamalardan bile daha iyi performans gösterdiği gösterilmiştir. Genel olarak, büyük ölçekli takviyeli öğrenmeye atfedilen STEM ile ilgili sorularda da oldukça güçlü bir performans sergilemektedir. STEM derslerine ek olarak, model soruları yanıtlama, eğitimsel görevler ve karmaşık muhakeme konusunda oldukça yeteneklidir. Yazarlar, bu iyileştirmelerin ve artan yeteneklerin, takviyeli öğrenme yoluyla düşünce zinciri işleme modellerinin evriminden kaynaklandığını savunmaktadır. Takviyeli öğrenme ve ince ayar sırasında uzun düşünce zinciri verileri kullanılarak modelin daha uzun ve daha içe dönük çıktılar üretmesi teşvik edilmektedir.
DeepSeek R1 Damıtılmış Modeller
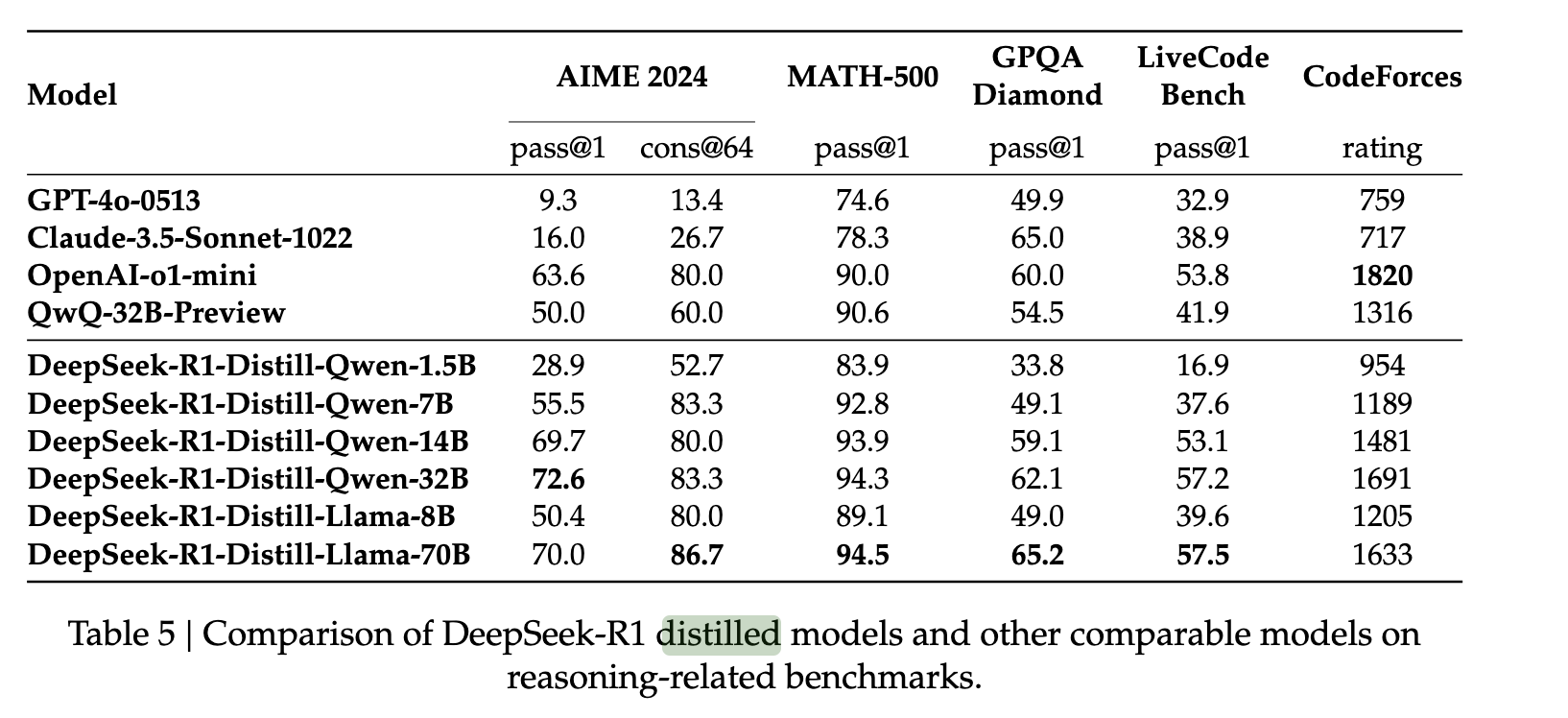 DeepSeek R1'in yeteneklerini daha küçük modellere genişletmek için yazarlar, 800.000 DeepSeek R1 örneği topladı ve bunları QWEN ve LLAMA gibi modelleri ince ayar yapmak için kullandı. Bu nispeten basit damıtma yönteminin, R1'in akıl yürütme yeteneklerinin bu yeni modellere yüksek bir başarıyla aktarılmasını sağladığını buldular. Bunu herhangi bir ek RL kullanmadan yaparak, orijinal modelin model damıtma işlemine verdiği tepkilerin sağlamlığını kanıtladılar.
DeepSeek R1'in yeteneklerini daha küçük modellere genişletmek için yazarlar, 800.000 DeepSeek R1 örneği topladı ve bunları QWEN ve LLAMA gibi modelleri ince ayar yapmak için kullandı. Bu nispeten basit damıtma yönteminin, R1'in akıl yürütme yeteneklerinin bu yeni modellere yüksek bir başarıyla aktarılmasını sağladığını buldular. Bunu herhangi bir ek RL kullanmadan yaparak, orijinal modelin model damıtma işlemine verdiği tepkilerin sağlamlığını kanıtladılar.
GPU Damlacıklarında DeepSeek R1'in Başlatılması
Zaten bir DigitalOcean hesabınız varsa, DeepSeek R1'i GPU Droplets'e kurmak çok kolaydır. Devam etmeden önce giriş yaptığınızdan emin olun.
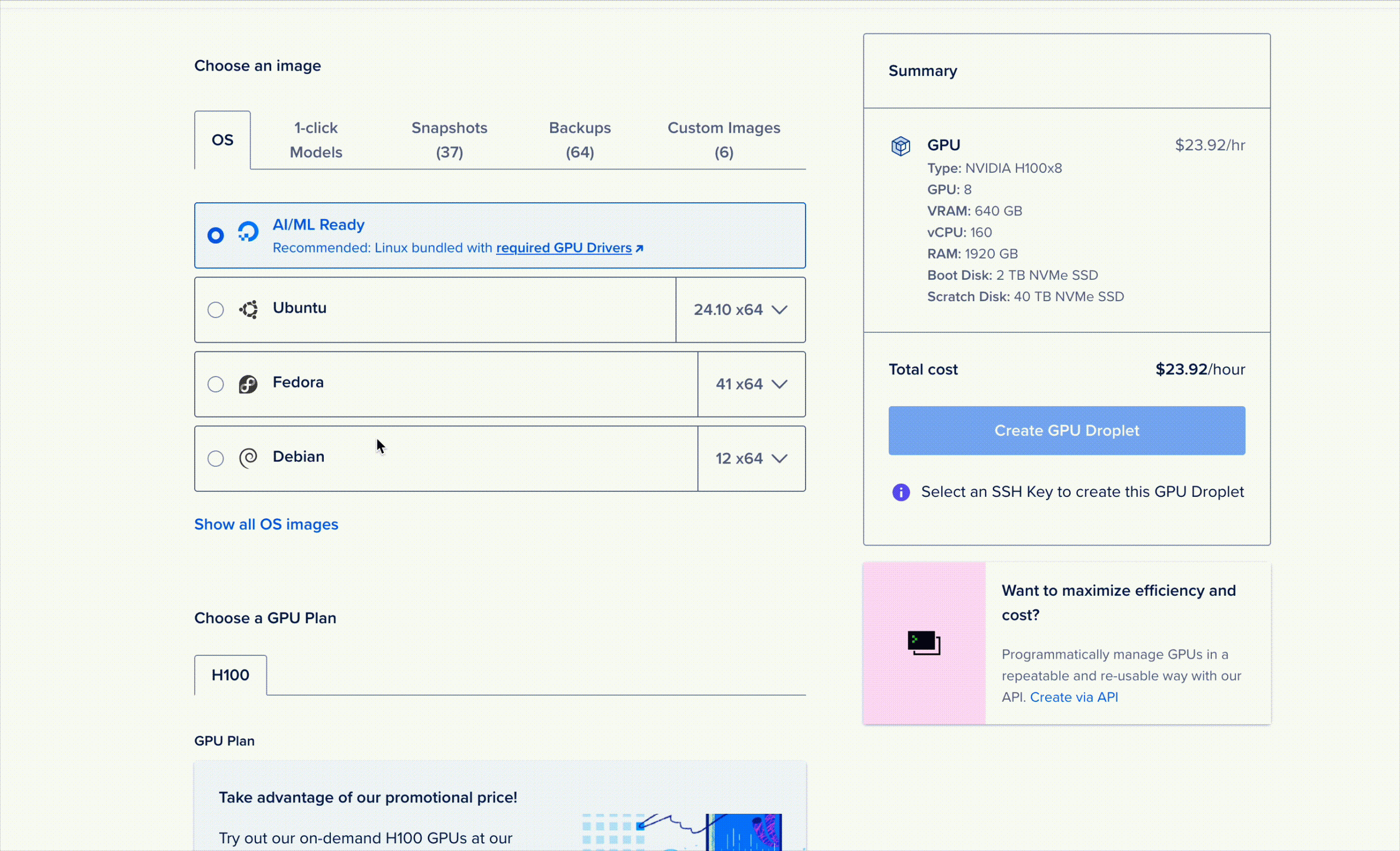
R1'e 1-Tıkla Model GPU Droplet olarak erişim sağlıyoruz. Başlatmak için GPU Droplet konsolunu açın, model seçim penceresindeki "1-Tıkla Modeller" sekmesine gidin ve cihazı başlatın!
Buradan, HuggingFace veya OpenAI yöntemlerini kullanarak modele erişebilir ve modelle iletişim kurabilirsiniz. Aşağıdaki betiği kullanarak Python koduyla modelinizle etkileşim kurabilirsiniz.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)Alternatif olarak, aynı sistemde çalışan özel bir kişisel asistan oluşturduk. Bu görevler için kişisel asistanı kullanmanızı öneririz çünkü her şeyi güzel bir GUI penceresine yerleştirerek modelle doğrudan etkileşim kurmanın karmaşıklığını büyük ölçüde ortadan kaldırır. Kişisel asistan betiğini kullanma hakkında daha fazla bilgi için lütfen bu eğitime göz atın.
Sonuç
Sonuç olarak, R1, LLM geliştirme topluluğu için ileriye doğru atılmış bir adımdır. Süreçleri, gelişmiş kapalı kaynak modellerine eşdeğer, hatta daha iyi bir performans sunarken, eğitim maliyetlerinde milyonlarca dolar tasarruf sağlamayı vaat ediyor. Modelleri uluslararası alanda tanınırlık kazandıkça DeepSeek'in nasıl büyümeye devam ettiğini yakından takip edeceğiz.









