









giriiş
Yapılandırılmamış verilerinizle sohbet edebildiğinizi ve değerli bilgileri kolayca çıkarabildiğinizi hayal edin. Günümüzün veri odaklı ortamında, yapılandırılmamış belgelerden anlamlı bilgiler çıkarmak, karar alma ve inovasyonu engelleyen bir zorluk olmaya devam ediyor. Bu eğitimde, yerleştirmeleri tanıyacak, Amazon Open Search'ü bir vektör veritabanı olarak kullanmayı keşfedecek ve Langchain çerçevesini Büyük Dil Modelleri (LLM'ler) ile entegre ederek gömülü bir NLP sohbet robotuna sahip bir web sitesi oluşturacağız. Açık kaynaklı bir Büyük Dil Modeli yardımıyla yapılandırılmamış bir belgeden anlamlı bilgiler çıkarmak için LLM'lerin temellerini ele alacağız. Bu eğitimin sonunda, yapılandırılmamış belgelerden anlamlı bilgiler elde etme konusunda kapsamlı bir anlayışa sahip olacak ve benzer Tam Yığın Yapay Zeka tabanlı çözümlerle keşif ve inovasyon yapma becerilerini kullanacaksınız.
Ön koşullar
- Etkin bir AWS hesabınız olmalıdır. Hesabınız yoksa, AWS web sitesinden kaydolabilirsiniz.
- Yerel makinenize AWS Komut Satırı Arayüzü'nü (CLI) yüklediğinizden ve gerekli kimlik bilgileri ve varsayılan bölgeyle düzgün bir şekilde yapılandırıldığından emin olun. Bunu aws configure komutunu kullanarak yapılandırabilirsiniz.
- Docker Engine'i indirip yükleyin. İşletim sisteminize özel kurulum talimatlarını izleyin.
Ne inşa edeceğiz?
Bu örnekte, birçok şirketin karşılaştığı bir sorunu taklit etmek istiyoruz. Günümüz verilerinin çoğu yapılandırılmamış, daha ziyade yapılandırılmamış olup ses ve video transkriptleri, PDF ve Word belgeleri, kılavuzlar, taranmış notlar, sosyal medya transkriptleri vb. şeklinde gelir. LLM olarak Flan-T5 XXL modelini kullanacağız. Bu model, yapılandırılmamış metinlerden özetler ve soru-cevaplar üretebilir. Aşağıdaki görsel, farklı yapı taşlarının mimarisini göstermektedir.

Temellerden başlayalım.
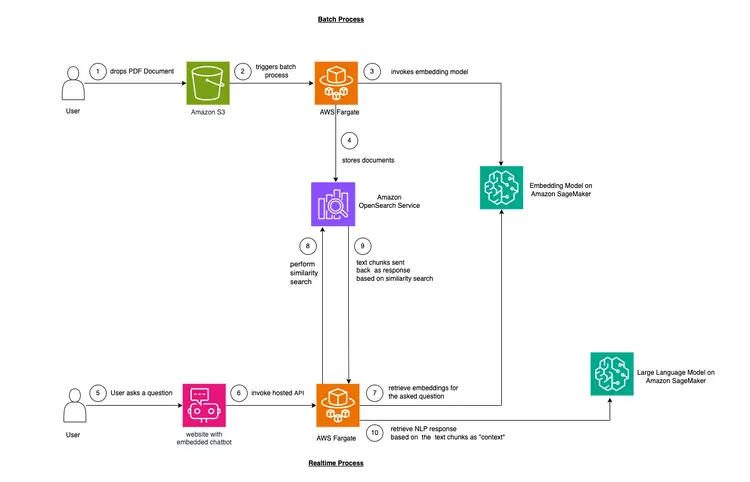
LLM programımıza alan veya vakaya özgü "Bağlam" eklemek için bağlam içi öğrenme adı verilen bir teknik kullanacağız. Bu örnekte, LLM programımız için "Bağlam" olarak eklemek istediğimiz yapılandırılmamış bir PDF araba kılavuzumuz var ve LLM'nin bu kılavuzla ilgili soruları yanıtlamasını istiyoruz. İşte bu kadar basit! Amacımız, soruları alıp arka uç sistemimize gönderen ve web sitesine yerleştirilmiş açık kaynaklı bir sohbet robotu aracılığıyla erişilebilen gerçek zamanlı bir API oluşturarak bunu bir adım öteye taşımak. Bu eğitim, kullanıcı deneyimini baştan sona oluşturmamızı ve süreç boyunca çeşitli kavram ve araçlar hakkında bilgi edinmemizi sağlayacak.
- Metin içi öğrenmeyi sağlamanın ilk adımı, PDF belgesini alıp metin parçalarına dönüştürmek, bu metin parçalarının "gömme" adı verilen vektör gösterimlerini oluşturmak ve son olarak bu gömmeleri bir vektör veritabanında depolamaktır.
- Vektör veritabanları, depoladıkları metin gömmelerine karşı «benzerlik aramaları» yapmamızı sağlar.
- Amazon SageMaker JumpStart, açık kaynaklı, önceden eğitilmiş modeller için altyapı kurmak üzere tek tıklamayla dağıtım çözümü şablonları sunar. Gömme modelini ve Büyük Dil modelini dağıtmak için Amazon SageMaker JumpStart'ı kullanacağız.
- Amazon OpenSearch, vektör uzayındaki noktaların en yakın komşularını arayabilen bir arama ve analiz motorudur ve bu özelliği sayesinde vektör veritabanı olarak kullanılmaya uygundur.
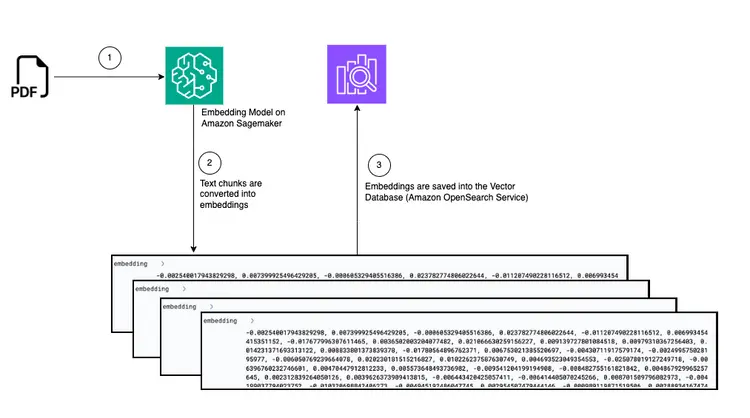
Grafik: PDF'den vektör veritabanına yerleştirmeye dönüştürün
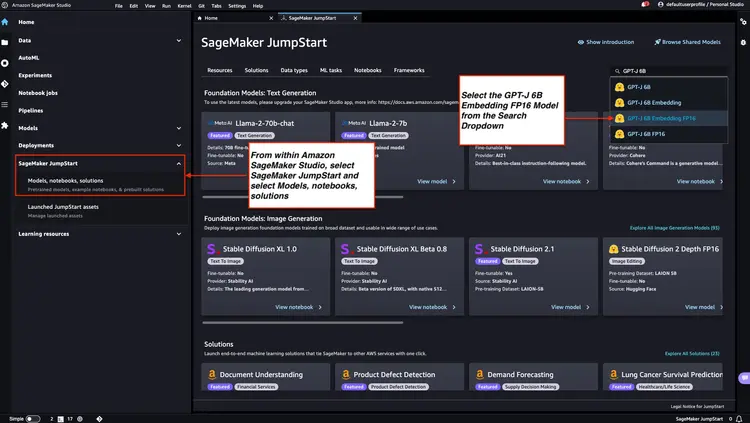
Adım 1 - GPT-J 6B FP16 Yerleştirme Modelini Amazon SageMaker JumpStart ile Dağıtın
Amazon SageMaker Belgeleri'nde belirtilen adımları izleyin: Amazon SageMaker Studio'nun ana menüsünden bir Amazon SageMaker JumpStart düğümü başlatmak için JumpStart bölümünü açın ve kullanın. Aşağıdaki görselde gösterildiği gibi "Modeller, not defterleri, çözümler"i seçin ve GPT-J 6B Embedding FP16 yerleştirme modelini seçin. Ardından "Dağıt"a tıklayın; Amazon SageMaker JumpStart, bu önceden eğitilmiş modeli SageMaker ortamına dağıtmak için altyapıyı kuracaktır.
Adım 2 - Flan T5 XXL LLM'yi Amazon SageMaker JumpStart ile Dağıtın
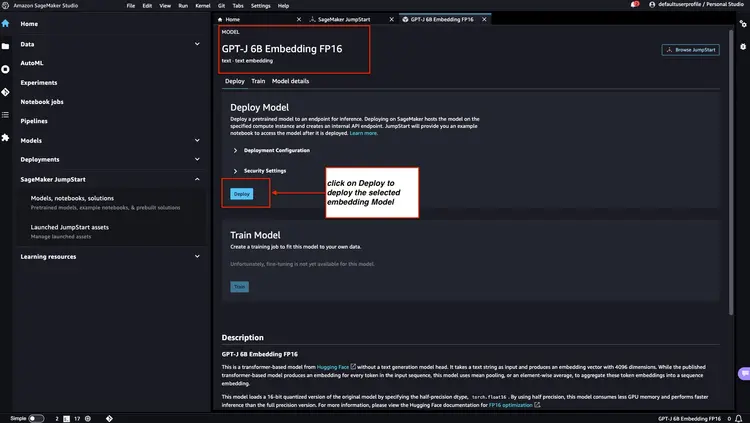
Ardından, Amazon SageMaker JumpStart'ta Flan-T5 XXL LLM'yi seçin ve ardından otomatik altyapı kurulumunu başlatmak ve model uç noktasını Amazon SageMaker ortamına dağıtmak için 'Dağıt'a tıklayın.
Adım 3 - Dağıtılan model uç noktalarının durumunu kontrol edin
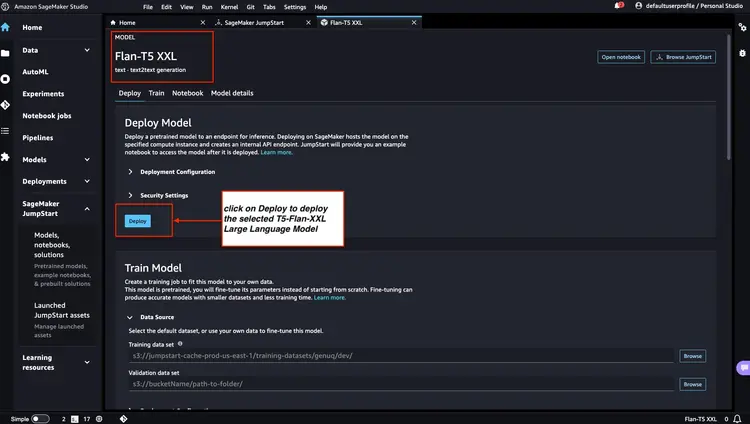
1. ve 2. Adım'da dağıtılan model uç noktalarının durumunu Amazon SageMaker konsolunda kontrol ediyor ve kodumuzda kullanacağımız uç nokta adlarını not ediyoruz. Model uç noktalarını dağıttıktan sonra konsolum aşağıdaki gibi görünüyor.
4. Adım – Amazon Açık Arama Kümesini Oluşturun
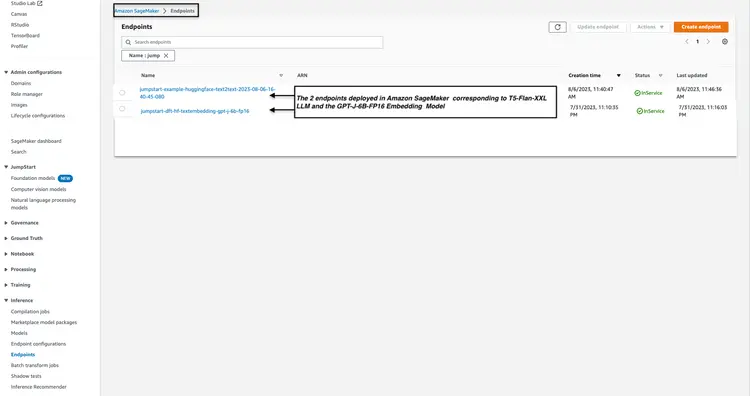
Amazon OpenSearch, k-En Yakın Komşular (kNN) algoritmasını destekleyen bir arama ve analiz hizmetidir. Bu özellik, benzerliğe dayalı aramalar için paha biçilmezdir ve OpenSearch'ü bir vektör veritabanı olarak etkili bir şekilde kullanmamızı sağlar. kNN eklentisini destekleyen Elasticsearch/OpenSearch sürümleri hakkında daha fazla bilgi edinmek ve daha fazla bilgi edinmek için lütfen şu bağlantıya bakın: k-NN Eklenti Belgeleri.
AWS CloudFormation şablon dosyasını GitHub konumundan dağıtmak için AWS CLI'yi kullanıyoruz. Altyapı/opensearch-vectordb.yaml Aws komutunu kullanacağız. bulut oluşumu yığın oluşturma Amazon Open Search kümesi oluşturmak için aşağıdaki komutu çalıştırın. Komutu çalıştırmadan önce değerlerinizi değiştirmeniz gerekir. kullanıcı adı Ve şifre Hadi yapalım.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> Adım 5 – Belge yakalama ve yerleştirme iş akışını oluşturun
Bu adımda, bir PDF belgesi Amazon Simple Storage Service (S3) kovasına yerleştirildiğinde okumak üzere tasarlanmış bir alım ve işleme hattı oluşturacağız. Bu hat aşağıdaki görevleri gerçekleştirecektir:
- PDF belgesinden metin çıkarın.
- Metin parçalarını gömmelere (vektör gösterimlerine) dönüştürün.
- Amazon Açık Arama'da gömülü öğeleri kaydedin.
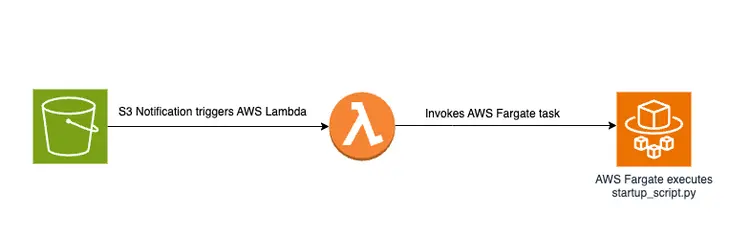
Bir PDF dosyasını bir S3 kovasına bırakmak, AWS Fargate işini içeren olay odaklı bir iş akışını tetikler. Bu iş, metni gömülü metinlere dönüştürüp Amazon Open Search'e eklemekten sorumlu olacaktır.
Şematik genel bakış
Aşağıda, Amazon OpenSearch vektör veritabanında gömülü metin parçacıklarını depolamak için belge aktarım hattını gösteren bir diyagram bulunmaktadır:
Başlatma betiği ve dosya yapısı
Dosyadaki ana mantık create-embeddings-save-in-vectordb\startup_script.py Bu Python betiği şu adreste bulunur: başlangıç_betiği.py, belge işleme, metin yerleştirme ve bir Amazon Open Search kümesine ekleme ile ilgili çeşitli görevleri gerçekleştirir. Betik, bir Amazon S3 kovasından bir PDF belgesi indirir ve ardından indirilen belgeyi daha küçük metin parçalarına böler. Her parça için metin içeriği, metin yerleştirmeleri oluşturmak üzere Amazon SageMaker'da dağıtılan GPT-J 6B FP16 Yerleştirme modeli uç noktasına gönderilir (TEXT_EMBEDDING_MODEL_ENDPOINT_NAME ortam değişkeninden alınır). Oluşturulan yerleştirmeler, diğer bilgilerle birlikte Amazon Open Search dizinine yerleştirilir. Betik, yapılandırma ve doğrulama parametrelerini ortam değişkenlerinden alır ve ortamlar arasında tutarlı hale getirir. Betiğin bir Docker konteynerinde tek tip olarak çalışması amaçlanmıştır.
Docker görüntüsünü oluşturun ve yayınlayın
Kodu anladıktan sonra başlangıç_betiği.py, Dockerfile'ı klasörden oluşturacağız create-embeddings-save-in-vectordb Görüntüyü Amazon Elastic Container Registry'ye (Amazon ECR) aktaracağız. Amazon Elastic Container Registry (Amazon ECR), yüksek performanslı barındırma sağlayan, tamamen yönetilen bir kapsayıcı kayıt defteridir, böylece uygulama görüntülerini ve yapıtlarını her yere güvenilir bir şekilde dağıtabiliriz. Docker görüntüsünü oluşturmak ve Amazon ECR'ye aktarmak için AWS CLI ve Docker CLI'yi kullanacağız. Aşağıdaki tüm komutlarda, Doğru AWS hesap numarasıyla değiştirin.
Bir kimlik doğrulama belirteci alın ve Docker istemcisini AWS CLI'daki kayıt defterinde doğrulayın.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com Aşağıdaki komutu kullanarak Docker imajınızı oluşturun.
docker build -t save-embedding-vectordb .
Derleme tamamlandıktan sonra, görüntüyü etiketleyin, böylece görüntüyü bu depoya gönderebiliriz:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Bu görüntüyü yeni Amazon ECR deposuna göndermek için aşağıdaki komutu çalıştırın:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Docker görüntüsü Amazon ECR deposuna yüklendiğinde aşağıdaki görüntüye benzemelidir:
Olay tabanlı PDF yerleştirme iş akışı için bir altyapı oluşturun
Sağlanan parametrelerle olay odaklı bir iş akışı için bir CloudFormation yığını oluşturmak üzere AWS Komut Satırı Arayüzü'nü (AWS CLI) kullanabiliriz. CloudFormation şablonuna GitHub deposundan ulaşabilirsiniz: Altyapı/fargate-gömme-vektördb-kaydetme.yaml AWS ortamına uyum sağlamak için parametreleri göz ardı etmemiz gerekiyor.
Komutta güncellenecek temel parametreler şunlardır: aws cloudformation create-stack Şöyle denilmektedir:
- BucketName: Bu parametre, PDF belgelerini bırakacağımız Amazon S3 kovasını temsil eder.
- VpcId ve SubnetId: Bu parametreler Fargate görevinin nerede çalışacağını belirtir.
- ImageName: Bu, save-embedding-vectordb için Amazon Elastic Container Registry'deki (ECR) Docker görüntüsünün adıdır.
- TextEmbeddingModelEndpointName: Bu parametreyi, 1. adımda Amazon SageMaker'da dağıtılan Gömme modelinin adını sağlamak için kullanın.
- VectorDatabaseEndpoint: Amazon OpenSearch etki alanının uç nokta adresini belirtin.
- VectorDatabaseUsername ve VectorDatabasePassword: Bu parametreler, 4. adımda oluşturulan Amazon Open Search kümesine erişmek için gereken kimlik bilgilerine yöneliktir.
- VectorDatabaseIndex: Amazon Open Search'te PDF belge yerleştirmelerinin saklandığı dizinin adını ayarlayın.
CloudFormation yığını oluşturma işlemini gerçekleştirmek için, parametre değerlerini güncelledikten sonra aşağıdaki AWS CLI komutunu kullanırız:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualYukarıdaki CloudFormation yığınını oluşturarak bir S3 kovası oluşturuyor ve bir Lambda işlevi başlatan S3 bildirimleri oluşturuyoruz. Bu Lambda işlevi de bir Fargate görevi başlatıyor. Fargate görevi, dosyayı içeren bir Docker konteyneri oluşturuyor. başlangıç-betiği.py Amazon OpenSearch'te yeni bir OpenSearch dizini altında gömülü öğeler oluşturmaktan sorumlu olan uygulamalar araba kılavuzu Öyledir.
PDF örneğiyle test edin
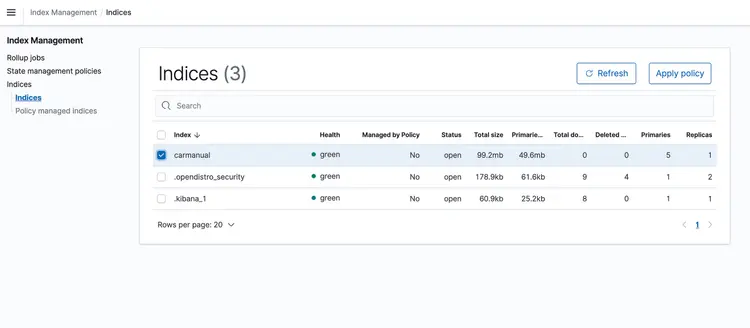
CloudFormation yığını çalışmaya başladıktan sonra, makine kılavuzunu temsil eden bir PDF dosyasını S3 kovanıza bırakın. Ben buradan indirdiğim bir makine kılavuzuna erişebilirsiniz. Olay tabanlı taşıma hattının çalışması tamamlandıktan sonra, Amazon Open Search kümesi aşağıdaki profili içermelidir: araba kılavuzu Aşağıda gösterilen yerleştirmelerle.
Adım 6 – Llm Metin Desteğiyle Gerçek Zamanlı Soru-Cevap API'sini Uygulayın
Artık metin yerleştirmelerimizi Amazon Open Search destekli bir vektör veritabanına yerleştirdiğimize göre, bir sonraki adıma geçelim. Burada, T5 Flan XXL LLM'nin yeteneklerini kullanarak araç kılavuzumuz hakkında gerçek zamanlı yanıtlar sağlayacağız.
LLM'ye bağlam sağlamak için vektör veritabanında depolanan yerleştirmeleri kullanıyoruz. Bu bağlam, LLM'nin araç kılavuzumuzla ilgili soruları etkili bir şekilde anlamasını ve yanıtlamasını sağlıyor. Bunu başarmak için, LLM tarafından tasarlanan gerçek zamanlı, metin tabanlı soru-cevap sistemimiz için gereken çeşitli bileşenlerin koordinasyonunu kolaylaştıran LangChain adlı bir çerçeve kullanacağız.
Bir vektör veritabanında depolanan yerleştirmeler, kelimelerin anlamlarını ve ilişkilerini gösterir ve anlamsal benzerliklere dayalı hesaplamalar yapmamızı sağlar. Yerleştirmeler, anlamları ve ilişkileri yakalamak için metin parçacıklarının vektör temsillerini oluştururken, T5 Flan LLM, isteklere ve sorgulara eklenen bağlam temelinde bağlamla ilgili yanıtlar oluşturma konusunda uzmanlaşmıştır. Amaç, sorular için yerleştirmeler oluşturarak ve ardından vektör veritabanında depolanan diğer yerleştirmelerle benzerliklerini ölçerek kullanıcı sorularını metin parçacıklarıyla eşleştirmektir.
Metin parçacıklarını ve kullanıcı sorgularını vektör olarak temsil ederek, bağlama duyarlı benzerlik aramaları gerçekleştirmek için matematiksel hesaplamalar yapabiliriz. İki veri noktası arasındaki benzerliği ölçmek için çok boyutlu bir alanda mesafe ölçümlerini kullanırız.
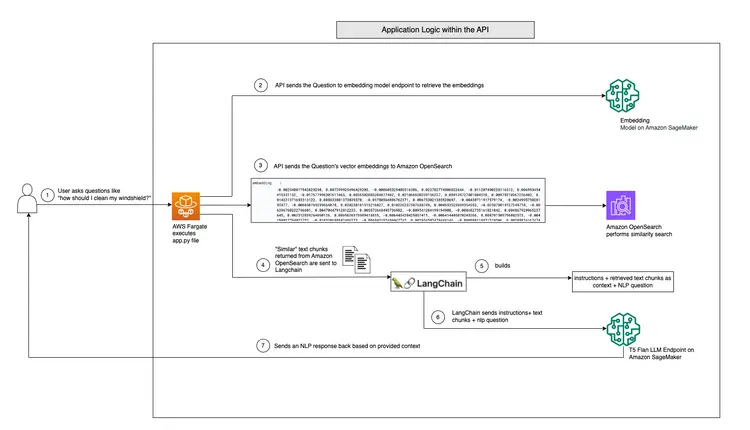
Aşağıdaki diyagram, LangChain ve T5 Flan LLM programımız tarafından sağlanan gerçek zamanlı soru-cevap iş akışını göstermektedir.
T5-Flan-XXL LLM'den Gerçek Zamanlı Soru-Cevap desteğinin grafiksel genel görünümü
API'yi oluşturun
LangChain ve T5 Flask LLM iş akışımızı incelediğimize göre, kullanıcı sorularını kabul eden ve bağlam farkında yanıtlar sağlayan API kodumuza geçelim. Bu gerçek zamanlı Soru-Cevap API'si, GitHub depomuzun RAG-langchain-questionanswer-t5-llm klasöründe bulunur ve temel mantığı app.py dosyasındadır. Bu Flask tabanlı uygulama, soruları yanıtlamak için bir /qa rotası tanımlar.
Bir kullanıcı API'ye bir sorgu gönderdiğinde, TEXT_EMBEDDING_MODEL_ENDPOINT_NAME ortam değişkenini kullanır ve sorguyu gömülü metin adı verilen sayısal vektör gösterimlerine dönüştürmek için bir Amazon SageMaker uç noktasına işaret eder. Bu gömülü metinler, metnin anlamsal anlamını yakalar.
API, bağlam farkında benzerlik aramaları gerçekleştirmek için Amazon OpenSearch'ten daha da yararlanır ve kullanıcı sorgularından elde edilen yerleştirmelere dayanarak OpenSearch dizin çalışma kılavuzundan ilgili metin parçacıklarını almasını sağlar. Bu adımdan sonra API, Amazon SageMaker'da da kullanılan T5FLAN_XXL_ENDPOINT_NAME ortam değişkeniyle tanımlanan T5 Flan LLM uç noktasını çağırır. Uç nokta, yanıt oluşturmak için bağlam olarak Amazon OpenSearch'ten alınan metin parçacıklarını kullanır. Amazon OpenSearch'ten alınan bu metin parçacıkları, T5 Flan LLM uç noktası için değerli bir bağlam görevi görerek kullanıcı sorgularına anlamlı yanıtlar sağlamasını mümkün kılar. API kodu, tüm bu etkileşimleri düzenlemek için LangChain'i kullanır.
API için Docker görüntüsünü oluşturun ve yayınlayın
app.py içindeki kodu anladıktan sonra, RAG-langchain-questionanswer-t5-llm klasöründen Dockerfile'ı oluşturup imajı Amazon ECR'ye göndereceğiz. Docker imajını oluşturmak ve Amazon ECR'ye göndermek için AWS CLI ve Docker CLI'yi kullanacağız. Aşağıdaki tüm komutlarda: Doğru AWS hesap numarasıyla değiştirin.
Bir kimlik doğrulama belirteci alın ve Docker istemcisini AWS CLI'daki kayıt defterinde doğrulayın.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Aşağıdaki komutu kullanarak Docker imajını oluşturun.
docker build -t qa-container .
Derleme tamamlandıktan sonra, görüntüyü etiketleyin, böylece görüntüyü bu depoya gönderebiliriz:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Bu görüntüyü yeni Amazon ECR deposuna göndermek için aşağıdaki komutu çalıştırın:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Docker görüntüsü Amazon ECR deposuna yüklendiğinde aşağıdaki görüntüye benzemelidir:
API uç noktasını barındırmak için bir CloudFormation yığını oluşturun
API'yi kullanıma sunmak için bir Fargate görevi barındıran bir Amazon ECS Kümesi için bir CloudFormation yığını oluşturmak üzere AWS Komut Satırı Arayüzü'nü (CLI) kullanacağız. CloudFormation şablonu, GitHub deposunda Infrastructure/fargate-api-rag-llm-langchain.yaml adresinde bulunmaktadır. Parametreleri AWS ortamıyla eşleştirmek için geçersiz kılmamız gerekiyor. aws cloudformation create-stack komutunda güncellenecek temel parametreler şunlardır:
- DemoVPC: Bu parametre, hizmetinizin çalışacağı sanal özel bulutu (VPC) belirtir.
- PublicSubnetIds: Bu parametre, yük dengeleyicinizin ve görevlerinizin yer alacağı genel alt ağ kimliklerinin bir listesini gerektirir.
- IMAGENAME: QA konteyneri için Amazon Elastic Container Registry'de (ECR) Docker görüntü adını sağlayın.
- TextEmbeddingModelEndpointName: 1. adımda Amazon SageMaker'da dağıtılan Embeddings modelinin uç nokta adını belirtin.
- T5FlanXXLEndpointName: 2. adımda Amazon SageMaker'a dağıtılan T5-FLAN uç nokta adını ayarlayın.
- VectorDatabaseEndpoint: Amazon OpenSearch etki alanının uç nokta adresini belirtin.
- VectorDatabaseUsername ve VectorDatabasePassword: Bu parametreler, 4. adımda oluşturulan OpenSearch Kümesine erişmek için gereken kimlik bilgileri içindir.
- VectorDatabaseIndex: Amazon OpenSearch'te servis verilerinizin depolanacağı dizinin adını belirleyin. Bu örnekte kullandığımız dizin adı carmanual'dır.
CloudFormation yığını oluşturma işlemini gerçekleştirmek için, parametre değerlerini güncelledikten sonra aşağıdaki AWS CLI komutunu kullanırız:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualYukarıda belirtilen CloudFormation yığınını başarıyla çalıştırdıktan sonra, AWS konsoluna gidin ve ecs-questionanswer-llm yığını için 'CloudFormation Çıktıları' sekmesine erişin. Bu sekmede, API uç noktası da dahil olmak üzere gerekli bilgileri bulacağız. Çıktının nasıl görünebileceğine dair bir örnek aşağıda verilmiştir:
API'yi test edin
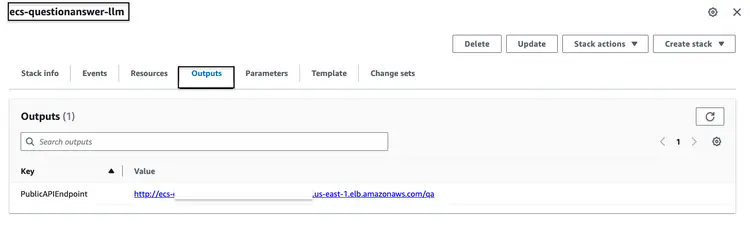
API uç noktasını curl komutuyla aşağıdaki gibi test edebiliriz:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
Aşağıdaki gibi bir cevap göreceğiz.
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
Adım 7 – Entegre bir sohbet robotu içeren bir web sitesi oluşturun ve dağıtın
Ardından, API'yi gömülü sohbet robotuyla bir HTML web sitesine entegre eden tam yığın işlem hattımızın son adımına geçiyoruz. Bu web sitesi ve gömülü sohbet robotu için kaynak kodumuz, sohbet robotu olarak açık kaynaklı botkit.js ile entegre edilmiş bir index.html dosyasından oluşan bir Nodejs uygulamasıdır. İşleri kolaylaştırmak için bir Dockerfile oluşturdum ve bunu homegrown_website_and_bot klasöründeki kodla birlikte verdim. Ön uç web sitesi için Docker Görüntüsünü oluşturup Amazon ECR'ye göndermek için AWS CLI ve Docker CLI'yi kullanacağız. Aşağıdaki tüm komutlarda, Doğru AWS hesap numarasıyla değiştirin.
Bir kimlik doğrulama belirteci alın ve Docker istemcisini AWS CLI'daki kayıt defterinde doğrulayın.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Aşağıdaki komutu kullanarak Docker görüntüsünü oluşturun:
docker build -t web-chat-frontend .
Derleme tamamlandıktan sonra, görüntüyü etiketleyin, böylece görüntüyü bu depoya gönderebiliriz:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Bu görüntüyü yeni Amazon ECR deposuna göndermek için aşağıdaki komutu çalıştırın:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Web sitesinin Docker görüntüsü ECR deposuna yüklendikten sonra, Infrastructure\fargate-website-chatbot.yaml dosyasını çalıştırarak ön uç için CloudFormation yığınını oluşturuyoruz. Parametreleri AWS ortamıyla eşleşecek şekilde geçersiz kılmamız gerekiyor. aws cloudformation create-stack komutunda güncellenecek temel parametreler şunlardır:
- DemoVPC: Bu parametre, web sitenizin dağıtılacağı sanal özel bulutu (VPC) belirtir.
- PublicSubnetIds: Bu parametre, web sitesi yük dengeleyicinizin ve görevlerinizin yerleştirileceği genel alt ağ kimliklerinin bir listesini gerektirir.
- IMAGENAME: Web siteniz için Amazon Elastic Container Registry'deki (ECR) Docker görüntüsünün adını girin.
- QUESTURL: 6. adımda dağıtılan API uç noktasının URL'sini belirtin. Biçimi http://'dir. /qa'dır.
CloudFormation yığını oluşturma işlemini gerçekleştirmek için, parametre değerlerini güncelledikten sonra aşağıdaki AWS CLI komutunu kullanırız:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaAdım 8 – Car Savvy AI Assistant'ı inceleyin
Yukarıda belirtilen CloudFormation yığınını başarıyla oluşturduktan sonra, AWS konsoluna gidin ve ecs-website-chatbot yığını için CloudFormation Çıktıları sekmesine erişin. Bu sekmede, ön uçla ilişkili Uygulama Yük Dengeleyici'nin (ALB) DNS adını bulacağız. Çıktının nasıl görünebileceğine dair bir örnek aşağıda verilmiştir:
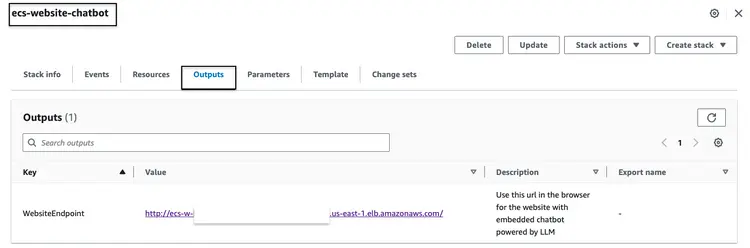
Web sitesinin nasıl göründüğünü görmek için tarayıcıdaki uç nokta URL'sini arayın. Yerleşik sohbet robotuna doğal dil soruları sorun. Sorabileceğimiz sorulardan bazıları şunlardır: "Ön camımı nasıl temizlerim?", "Şasi numarasını nerede bulabilirim?", "Güvenlik kusurunu nasıl bildirebilirim?"“
Sırada ne var?

Umarım yukarıdaki bilgiler, LLM'leriniz için kendi üretime hazır süreçlerinizi nasıl oluşturabileceğinizi ve bu süreci ön uç sohbet robotlarınız ve gömülü NLP'nizle nasıl entegre edebileceğinizi gösterir. Açık kaynak teknolojileri, analitik, makine öğrenimi ve AWS kullanımı hakkında başka neler okumak istediğinizi bana bildirin!
Öğrenme yolculuğunuza devam ederken, Gömmeler, Vektör Veritabanları, LangChain ve diğer birçok LLM programını derinlemesine incelemenizi tavsiye ederim. Bunlar, Amazon SageMaker JumpStart'ın yanı sıra bu eğitimde kullandığımız Amazon OpenSearch, Docker Containers ve Fargate gibi AWS araçlarında da mevcuttur. Bu teknolojilerde uzmanlaşmanıza yardımcı olacak bazı adımlar şunlardır:
- Amazon SageMaker: SageMaker'da ilerledikçe sunduğu diğer algoritmalara da aşina olun.
- AMAZON-AÇIK ARAMA: K-NN algoritması ve diğer mesafe algoritmaları hakkında bilgi edinin
- LangChain: LangChain, LLM kullanarak uygulama oluşturmayı kolaylaştırmak için tasarlanmış bir çerçevedir.
- Gömmeler: Gömme, bir bilgi parçasının (örneğin metin, belgeler, resimler, ses vb.) sayısal bir gösterimidir.
- Amazon SageMaker JumpStart: SageMaker JumpStart, makine öğrenimine başlamanıza yardımcı olmak için çok çeşitli problem türleri için önceden eğitilmiş, açık kaynaklı modeller sunar.
Sil
- AWS CLI'da oturum açın. AWS CLI'nın bu işlemleri gerçekleştirmek için gerekli izinlerle düzgün bir şekilde yapılandırıldığından emin olun.
- Aşağıdaki komutu çalıştırarak PDF dosyasını Amazon S3 kovanızdan silin. Kovanızın adını Amazon S3 kovanızın gerçek adıyla değiştirin ve gerekirse PDF dosyanızın yolunu ayarlayın.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
CloudFormation yığınlarını silin. Yığın adlarını CloudFormation yığınlarınızın gerçek adlarıyla değiştirin.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2Sonuç
Bu eğitimde, AWS teknolojilerini ve açık kaynaklı araçları kullanarak tam kapsamlı bir soru-cevap sohbet robotu geliştirdik. Amazon OpenSearch'ü vektör veritabanı, GPT-J 6B FP16 yerleştirme modeli olarak entegre ettik ve LLM ile Langchain'i kullandık. Sohbet robotu, yapılandırılmamış belgelerden içgörüler elde ediyor.









