









Введение
Представьте себе базу данных, которая не только хранит данные, но и понимает их. В последние годы приложения ИИ произвели революцию практически во всех отраслях и изменили будущее вычислительной техники.
Векторные базы данных меняют наш подход к управлению неструктурированными данными, позволяя хранить знания, отражая взаимосвязи, сходства и контекст. В отличие от традиционных баз данных, которые в основном опираются на структурированные данные, хранящиеся в таблицах, и фокусируются на точных совпадениях, векторные базы данных позволяют хранить неструктурированные данные, такие как изображения, текст и аудио, в формате, который модели машинного обучения могут понимать и сравнивать.
Вместо того, чтобы полагаться на точные совпадения, векторные базы данных могут находить “ближайшие” совпадения и обеспечивать эффективный поиск альтернативных или семантически схожих элементов. В современную эпоху, когда искусственный интеллект управляет всем, векторные базы данных стали незаменимыми для приложений, включая большие языковые модели и модели машинного обучения, которые генерируют и обрабатывают вложения.
Итак, что же такое встраивание? Мы рассмотрим это в этой статье.
Векторные базы данных стали мощным решением для хранения данных, позволяющим нам получать доступ к данным и взаимодействовать с ними новыми и интересными способами — будь то рекомендательные системы или диалоговый искусственный интеллект.
Теперь давайте рассмотрим, какие базы данных используются чаще всего:
- SQL: хранит структурированные данные и использует таблицы для хранения данных с определённой схемой. Наиболее распространённые — MySQL, Oracle Database и PostgreSQL.
- NoSQL: очень гибкая и не требующая схем база данных. Она также известна тем, что обрабатывает неструктурированные или полуструктурированные данные. Она отлично подходит для многих веб-приложений реального времени и больших данных. Наиболее распространённые — MongoDB и Cassandra.
- Graph: Затем появился Graph, который хранит данные в виде узлов и рёбер и предназначен для управления взаимосвязанными данными. Примеры: Neo4j, ArangoDB.
- Вектор: Базы данных, предназначенные для хранения и запроса многомерных векторов, позволяющие осуществлять поиск по сходству и аугментацию для задач искусственного интеллекта/машинного обучения. Наиболее распространённые — Pinecone, Weaviate и Chroma.
Предпосылки
- Знание мер подобия: понимание таких мер, как косинусное подобие, евклидово расстояние или скалярное произведение для сравнения векторных данных.
- Базовые концепции машинного обучения и искусственного интеллекта: знание моделей и приложений машинного обучения, особенно тех, которые генерируют вложения (например, обработка естественного языка, компьютерное зрение).
- Знакомство с концепциями баз данных: общие знания о базах данных, включая принципы индексирования, запросов и хранения данных.
- Навыки программирования: свободное владение Python или аналогичными языками, обычно используемыми в библиотеках машинного обучения и векторных базах данных.
Почему мы используем векторные базы данных и чем они отличаются?
Предположим, мы храним данные в традиционной базе данных SQL, где каждая точка данных преобразуется в эмбеддинг и сохраняется. При построении запроса он также преобразуется в эмбеддинг, а затем мы пытаемся найти наиболее релевантные из них, сравнивая эмбеддинг запроса с сохранёнными эмбеддингами с помощью косинусного сходства.
Однако этот метод может оказаться неэффективным по нескольким причинам:
- Высокая размерность: вложения обычно имеют высокую размерность. Это может привести к увеличению времени выполнения запросов, поскольку каждое сравнение может потребовать полного сканирования всех сохранённых вложений.
- Проблемы масштабируемости: вычислительные затраты на вычисление косинусного сходства между миллионами векторных представлений становятся непомерно высокими при работе с большими наборами данных. Традиционные базы данных SQL не оптимизированы для этой задачи, что затрудняет поиск данных в режиме реального времени.
Поэтому традиционные базы данных могут испытывать трудности с эффективным поиском больших объёмов данных. Более того, значительный объём ежедневно генерируемых данных неструктурирован и не может быть сохранен в традиционных базах данных.

Для решения этой проблемы мы используем векторную базу данных. В векторной базе данных существует концепция индекса, которая обеспечивает эффективный поиск по сходству для многомерных данных. Организация векторных вложений играет важную роль в ускорении запросов и позволяет базе данных быстро находить векторы, похожие на вектор запроса, даже в больших наборах данных. Векторные индексы сокращают область поиска и позволяют масштабировать систему до миллионов и миллиардов векторов. Это обеспечивает быстрый ответ на запрос даже в больших наборах данных.
В традиционных базах данных мы ищем строки, соответствующие нашему запросу. В векторных базах данных мы используем меры сходства, чтобы найти вектор, наиболее похожий на наш запрос.
Векторные базы данных используют комбинацию алгоритмов поиска по приближенному методу ближайшего соседа (ИНС), которые оптимизируют поиск с помощью хеширования, квантизации или графовых методов. Эти алгоритмы работают вместе в конвейере, обеспечивая быстрые и точные результаты. Поскольку векторные базы данных обеспечивают приблизительное сопоставление, существует компромисс между точностью и скоростью: более высокая точность может замедлить выполнение запроса.
Основы векторных представлений
Что такое векторы?
Векторы можно рассматривать как массивы чисел, хранящиеся в базе данных. Любые данные, такие как изображения, текст, PDF-файлы и аудио, можно преобразовать в числовые значения и сохранить в векторной базе данных в виде массива. Такое числовое представление данных позволяет проводить поиск по сходству.
Прежде чем разбираться в векторах, давайте попробуем разобраться в семантическом поиске и встраивании.
Что такое семантический поиск?
Семантический поиск — это способ поиска значения слов и контекста, а не сопоставления точных фраз. Вместо того, чтобы сосредоточиться на ключевом слове, семантический поиск пытается понять его значение. Например, слово “python”. В традиционном поиске слово “python” может возвращать результаты как по запросу «программирование на Python», так и по запросу «змеи на Python», поскольку поисковая система распознаёт только само слово. При семантическом поиске поисковая система ищет контекст. Если недавние поисковые запросы были о «языках программирования» или «машинном обучении», она, скорее всего, покажет результаты о программировании на Python. Но если поисковые запросы были о «странных животных» или «рептилиях», поисковая система предположит, что питоны — это змеи, и соответствующим образом скорректирует результаты.

Выявляя контекст, семантический поиск помогает выявить наиболее релевантную информацию, исходя из фактического намерения.
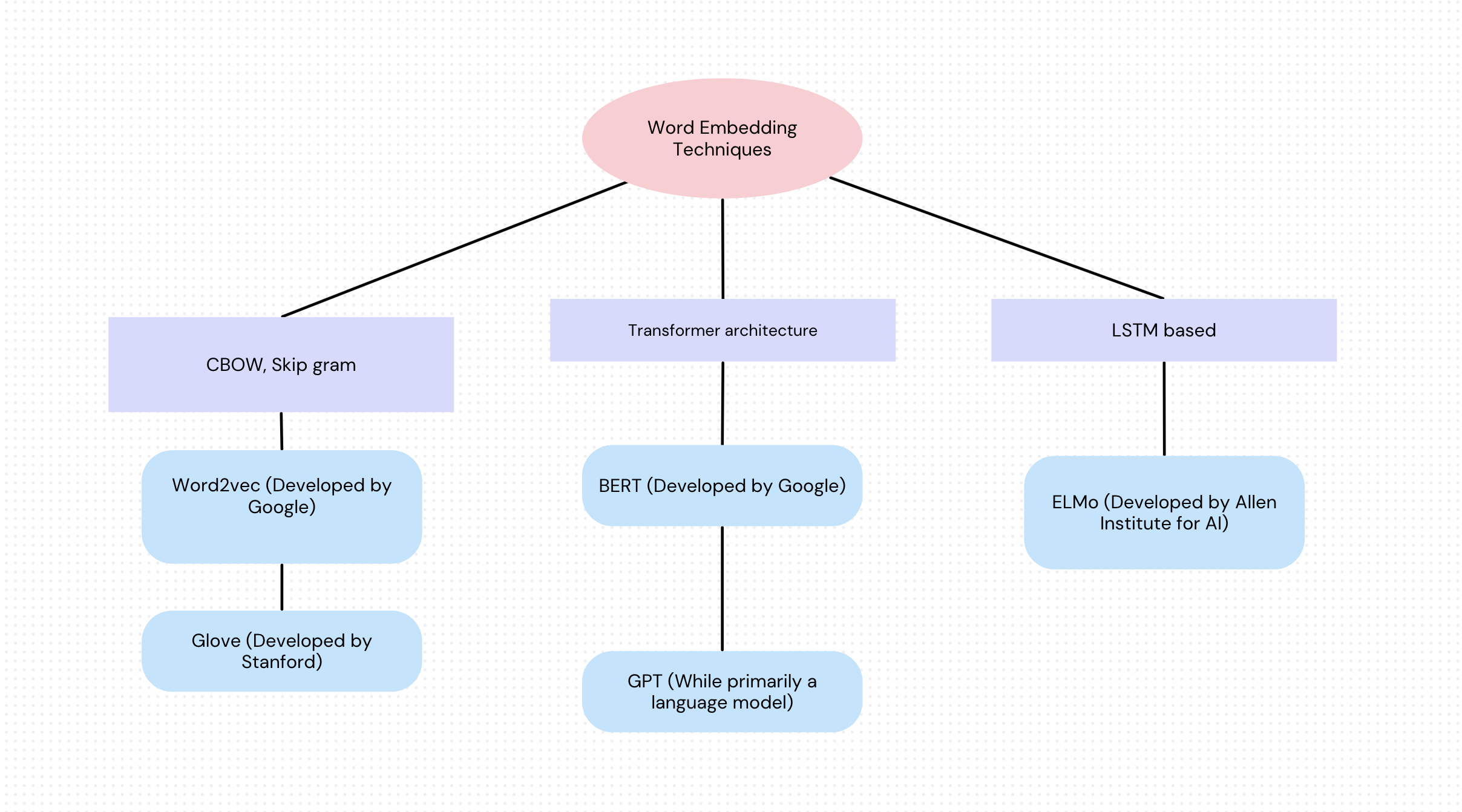
Что такое встраивание?
Вложения — это способ представления слов в виде числовых векторов (пока что давайте думать о векторах как о списках чисел; например, слово «cat» может стать [.1,.8,.75,.85]. В многомерном пространстве компьютеры быстро обрабатывают это числовое представление слова.
Слова имеют разные значения и взаимосвязи. Например, в векторных представлениях слова “король” и “королева” имеют схожие векторы, как и слова “король” и “автомобиль”.
Эмбеддинги позволяют уловить контекст слова, основываясь на его использовании в предложениях. Например, слово “банк” может означать финансовое учреждение или берег реки, а эмбеддинги помогают распознавать эти значения на основе окружающих слов. Эмбеддинги — это более интеллектуальный способ для компьютеров понимать слова, их значения и взаимосвязи.
Один из способов представить себе вложение слов — это сопоставить различные признаки или характеристики слова, а затем присвоить значения каждому из этих признаков. Это даёт последовательность чисел, называемую вектором. Существуют различные методы создания таких вложений слов. Таким образом, векторное вложение — это способ представления предложения или документа, состоящего из слов, в числах, которые могут отражать значение и взаимосвязи. Векторные вложения позволяют представить эти слова в виде точек в пространстве, где похожие слова расположены близко друг к другу.
Эти векторные вложения позволяют выполнять математические операции, такие как сложение и вычитание, которые можно использовать для описания взаимосвязей. Например, известная векторная операция “король – мужчина + женщина” может дать вектор, близкий к “королеве”.
Критерии подобия в векторных пространствах
В настоящее время для измерения сходства каждого вектора используются математические инструменты, позволяющие количественно оценить сходство или различие. Некоторые из них перечислены ниже:
- Подобие косинуса: косинус измеряет угол между двумя векторами в диапазоне от -1 до 1. Где -1 означает полную противоположность, 1 означает идентичные векторы, 0 означает ортогональность или непохожесть.
- Евклидово расстояние: измеряет расстояние по прямой между двумя точками в векторном пространстве. Меньшие значения указывают на большее сходство.
- Манхэттенское расстояние (норма L1): измеряет расстояние между двумя точками путем суммирования абсолютных разностей их соответствующих компонентов.
- Расстояние Минковского: обобщение евклидова и манхэттенского расстояний.
Это наиболее распространенные метрики расстояния или сходства, используемые в алгоритмах машинного обучения.
Популярные векторные базы данных
Вот некоторые из наиболее популярных векторных баз данных, которые широко используются сегодня:
- Pinecone: полностью управляемая векторная база данных, известная простотой использования, масштабируемостью и быстрым поиском по методу ближайшего соседа (ИНС). Pinecone известна своей интеграцией с процессами машинного обучения, особенно с системами семантического поиска и рекомендаций.
- FAISS (Facebook AI Similarity Search): Разработанная компанией Meta (ранее Facebook), FAISS — это высокооптимизированная библиотека для поиска сходства и кластеризации плотных векторов. Она имеет открытый исходный код, эффективна и широко используется в академических и промышленных исследованиях, особенно для крупномасштабного поиска сходства.
- Weaviate: векторная база данных с открытым исходным кодом, облачная, поддерживающая возможности векторного и гибридного поиска. Weaviate известен своей интеграцией с моделями Hugging Face, OpenAI и Cohere, что делает его отличным выбором для приложений семантического поиска и обработки естественного языка.
- Milvus: векторная база данных с открытым исходным кодом, высокомасштабируемая и оптимизированная для крупномасштабных приложений ИИ. Milvus поддерживает различные методы индексации и обладает широкой экосистемой интеграций, что делает её популярной для систем рекомендаций в режиме реального времени и задач компьютерного зрения.
- Qdrant: Высокопроизводительная векторная база данных, ориентированная на удобство использования, Qdrant предлагает такие функции, как индексация в реальном времени и распределенная поддержка. Она разработана для обработки многомерных данных, что делает ее подходящей для рекомендательных систем, персонализации и задач обработки естественного языка.
- Chroma: Chroma с открытым исходным кодом, разработанная специально для приложений LLM, предоставляет хранилище встраиваемых данных для LLM и поддерживает аналогичные поисковые запросы. Chroma часто используется с LangChain для диалогового ИИ и других приложений на основе LLM.
Что вам следует использовать
Теперь давайте рассмотрим некоторые варианты использования векторных баз данных.
- Векторные базы данных могут использоваться для чат-агентов, которым требуется долговременное хранение информации. Это легко реализуется с помощью Langchain и позволяет чат-агенту запрашивать и сохранять историю разговоров в векторной базе данных. По мере взаимодействия пользователей бот извлекает контекстно-релевантные фрагменты из прошлых разговоров, улучшая пользовательский опыт.
- Векторные базы данных могут использоваться для семантического поиска и извлечения информации путем поиска семантически схожих документов или текстов. Они находят контент, текстово связанный с запросом, а не точно совпадающий с ключевыми словами.
- Такие платформы, как электронная коммерция, потоковая музыка или социальные сети, используют векторные базы данных для генерации рекомендаций. Представляя товары и предпочтения пользователя в виде векторов, система может находить товары, песни или контент, похожие на его предыдущие интересы.
- Платформы изображений и видео используют векторные базы данных для поиска визуально похожего контента.
Проблемы векторных баз данных
- Масштабируемость и производительность: По мере роста объёмов данных обеспечение быстрой работы и масштабируемости векторных баз данных при сохранении точности может стать сложной задачей. Баланс между скоростью и точностью также может представлять собой потенциальную проблему при формировании точных результатов поиска.
- Стоимость и ресурсоемкость: Многомерные векторные операции могут быть ресурсоемкими, требуя мощного оборудования и эффективной индексации, что может привести к увеличению затрат на хранение и вычислительные затраты.
- Компромисс между точностью и приближением: векторные базы данных используют методы ближайшего соседа (ИНС) для ускорения поиска, но могут приводить к приблизительным, а не точным совпадениям.
- Интеграция с традиционными системами: Интеграция векторных баз данных с существующими традиционными базами данных может оказаться сложной задачей, поскольку они используют разные структуры данных и методы поиска.
Результат
Векторные базы данных меняют способы хранения и поиска сложных данных, таких как изображения, аудио, текст и рекомендации, позволяя осуществлять поиск на основе сходства в многомерных пространствах. В отличие от традиционных баз данных, требующих точных совпадений, векторные базы данных используют вложения и оценки сходства для поиска «достаточно близких» результатов, что делает их идеальными для таких приложений, как персонализированные рекомендации, семантический поиск и обнаружение аномалий.









