









Введение
При проектировании базы данных могут возникнуть ситуации, когда вам потребуется наложить ограничения на данные, допустимые в определённых столбцах. Например, если вы создаёте таблицу с информацией о небоскрёбах, вам может понадобиться запретить отрицательные значения в столбце, содержащем высоту каждого здания.
Системы управления реляционными базами данных (СУРБД) позволяют контролировать, какие данные добавляются в таблицу, с помощью ограничений. Ограничение — это особое правило, применяемое к одному или нескольким столбцам (или ко всей таблице) и ограничивающее изменения, которые можно внести в данные таблицы с помощью оператора. ВСТАВЛЯТЬ, ОБНОВЛЯТЬ, или УДАЛИТЬ Это ограничивает.
В этой статье подробно рассматриваются ограничения и их применение в реляционных СУБД. Также рассматриваются все пять ограничений, определённых в стандарте SQL, и объясняются соответствующие функции.
Какие существуют ограничения?
В SQL ограничение — это любое правило, применяемое к столбцу или таблице, которое ограничивает данные, которые можно вставить в неё. При любой попытке выполнить операцию, изменяющую данные, хранящиеся в таблице, например, оператор INSERT, UPDATE или DELETE, СУБД проверяет, нарушают ли эти данные существующие ограничения, и, если это так, возвращает ошибку.
Администраторы баз данных часто полагаются на ограничения, чтобы гарантировать соответствие базы данных определённому набору бизнес-правил. В контексте базы данных бизнес-правило — это любая политика или процедура, которой следует компания или другая организация и которой должны соответствовать её данные. Например, предположим, что вы создаёте базу данных для каталогизации инвентаря магазина клиента. Если клиент указывает, что каждая запись о товаре должна иметь уникальный идентификационный номер, вы можете создать столбец с ограничением UNIQUE, которое гарантирует, что в этом столбце не будет двух одинаковых записей.
Ограничения также полезны для поддержания целостности данных. Целостность данных — это широкий термин, часто используемый для описания общей точности, согласованности и рациональности данных, хранящихся в базе данных, в зависимости от конкретных вариантов использования. Таблицы в базе данных часто связаны, и столбцы одной таблицы зависят от значений в другой таблице. Поскольку ввод данных часто подвержен человеческим ошибкам, ограничения полезны в подобных случаях, поскольку они могут гарантировать, что никакие ошибочно введённые данные не повлияют на эти связи и, таким образом, не нарушат целостность данных базы данных.
Представьте, что вы разрабатываете базу данных с двумя таблицами: одна для списка текущих учеников школы, а другая — для списка игроков баскетбольной команды этой школы. Вы можете применить ограничение внешнего ключа к столбцу таблицы «Баскетбольная команда», который ссылается на столбец таблицы «Школа». Это устанавливает связь между двумя таблицами, требуя, чтобы каждая запись в таблице «Команда» ссылалась на запись в таблице «Ученики».
Пользователи задают ограничения при создании таблицы или могут добавить их позже с помощью оператора ALTER TABLE, если они не конфликтуют с данными, уже имеющимися в таблице. При создании ограничения система базы данных автоматически присваивает ему имя, но в большинстве реализаций SQL можно добавить собственное имя для каждого ограничения. Эти имена используются для ссылки на ограничения в операторах ALTER TABLE при их изменении или удалении.
Стандарт SQL формально определяет только пять ограничений:
- Первичный ключ
- Внешний ключ
- Уникальный
- Обзор
- Он не пустой.
Теперь, когда у вас есть общее представление о том, как используются ограничения, давайте подробнее рассмотрим каждое из этих пяти ограничений.
Первичный ключ
Ограничение PRIMARY KEY требует, чтобы каждая запись в данном столбце была уникальной и не имела значения NULL, что позволяет использовать этот столбец для идентификации каждой отдельной строки в таблице.
В реляционной модели ключ — это столбец или набор столбцов в таблице, где каждое значение гарантированно уникально и не содержит значений NULL. Первичный ключ — это специальный ключ, значения которого используются для идентификации отдельных строк в таблице, а столбец или столбцы, составляющие первичный ключ, могут использоваться для идентификации таблицы в остальной части базы данных.
Это один из важных аспектов реляционных баз данных: благодаря первичному ключу пользователям не нужно знать, что их данные физически хранятся на компьютере, а их СУБД может отслеживать каждую запись и извлекать их по мере необходимости. В свою очередь, это означает, что записи не имеют определённого логического порядка, и пользователи могут извлекать данные в любом порядке или с помощью любого фильтра.
Первичный ключ в SQL можно создать с помощью ограничения PRIMARY KEY, которое, по сути, представляет собой комбинацию ограничений UNIQUE и NOT NULL. После определения первичного ключа СУБД автоматически создаёт связанный с ним индекс. Индекс — это структура базы данных, которая ускоряет извлечение данных из таблицы. Подобно индексу в учебнике, запросам достаточно просматривать только записи индексированного столбца, чтобы найти соответствующие значения. Именно это позволяет первичному ключу выступать в качестве идентификатора каждой строки в таблице.
Таблица может иметь только один первичный ключ, но, как и обычные ключи, первичный ключ может состоять из нескольких столбцов. При этом определяющей характеристикой первичных ключей является то, что они используют только минимальный набор атрибутов, необходимых для уникальной идентификации каждой строки в таблице. Чтобы проиллюстрировать эту идею, представьте себе таблицу, хранящую информацию об учениках школы, используя следующие три столбца:
студенческий идентификатор: используется для хранения уникального идентификационного номера каждого учащегосяимя: используется для хранения имени каждого ученикаФамилия: Используется для хранения фамилии каждого студента.
Возможно, у некоторых учеников в школе одинаковые имена, поэтому столбец firstName не подойдёт для первичного ключа. То же самое относится и к столбцу lastName. Первичный ключ, состоящий из столбцов firstName и lastName, может подойти, но всё равно существует вероятность, что у двух учеников могут быть одинаковые имя и фамилия.
Первичный ключ, состоящий из идентификатора студента и столбцов firstName или lastName, может подойти, но поскольку номер идентификатора каждого студента уникален, включение каждого столбца с именем в первичный ключ излишне. Таким образом, в данном случае минимальный набор атрибутов, позволяющий идентифицировать каждую строку и, следовательно, являющийся хорошим выбором для первичного ключа таблицы, — это только столбец studentID.
Если ключ состоит из наблюдаемых, пригодных для использования данных (т. е. данных, представляющих реальные сущности, события или свойства), он называется естественным ключом. Если ключ генерируется внутри системы и не представляет ничего вне базы данных, он называется суррогатным или искусственным ключом. Некоторые системы баз данных не рекомендуют использовать естественные ключи, поскольку даже кажущиеся фиксированными точки данных могут изменяться непредсказуемым образом.
Внешний ключ
Ограничение FOREIGN KEY требует, чтобы каждая запись в данном столбце уже существовала в определенном столбце другой таблицы.
Если у вас есть две таблицы, которые вы хотите связать друг с другом, один из способов сделать это — определить внешний ключ с ограничением FOREIGN KEY. Внешний ключ — это столбец в одной таблице (дочерней), значения которого берутся из ключа в другой таблице (родительской). Это способ выражения связи между двумя таблицами: ограничение FOREIGN KEY требует, чтобы значения в столбце, к которому оно применяется, существовали в столбце, на который оно ссылается.
На следующей диаграмме показана такая связь между двумя таблицами: одна используется для записи информации о сотрудниках компании, а другая — для отслеживания продаж. В этом примере на первичный ключ таблицы EMPLOYEES ссылается внешний ключ таблицы SALES:
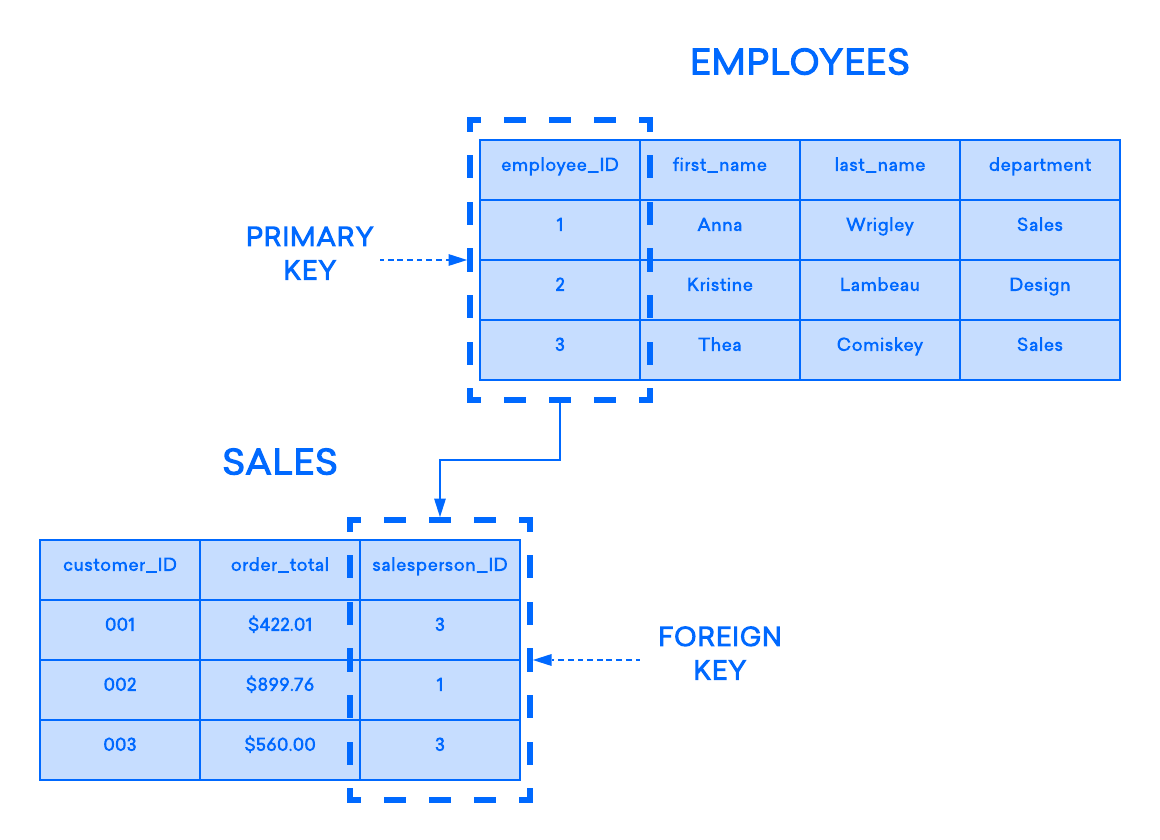
Если вы попытаетесь вставить запись в дочернюю таблицу, а значение, введённое в столбец внешнего ключа, отсутствует в первичном ключе родительской таблицы, оператор вставки будет недействительным. Это помогает поддерживать целостность данных на уровне связей, поскольку строки обеих таблиц всегда корректно связаны.
Чаще всего внешний ключ таблицы является первичным ключом родительской таблицы, но это не всегда так. В большинстве СУБД любой столбец родительской таблицы, имеющий ограничение UNIQUE или PRIMARY KEY, может быть доступен по внешнему ключу дочерней таблицы.
Уникальный
Ограничение UNIQUE предотвращает добавление повторяющихся значений в указанный столбец.
Как следует из названия, ограничение UNIQUE требует, чтобы каждая запись в заданном столбце была уникальным значением. Любая попытка добавить значение, уже присутствующее в столбце, приведёт к ошибке.
Ограничения UNIQUE полезны для обеспечения связи типа «один к одному» между таблицами. Как упоминалось ранее, связь между двумя таблицами можно установить с помощью внешнего ключа, но существует несколько типов связей между таблицами:
یک به یکОдин ко многим: В отношении «многие к любому» строка родительской таблицы может быть связана с несколькими строками дочерней таблицы, но каждая строка дочерней таблицы может быть связана только с одной строкой родительской таблицы.Сколько?: Если строки родительской таблицы могут быть связаны с несколькими строками дочерней таблицы и наоборот, то говорят, что между ними существует связь «многие ко многим».
Добавляя ограничение UNIQUE к столбцу, к которому применено ограничение FOREIGN KEY, можно гарантировать, что каждая запись родительской таблицы появится в дочерней таблице только один раз, тем самым устанавливая отношение «один к одному» между двумя таблицами.
Обратите внимание, что ограничения UNIQUE можно определять как на уровне таблицы, так и на уровне столбцов. При определении на уровне таблицы ограничение UNIQUE может применяться к нескольким столбцам. В подобных случаях каждый столбец в ограничении может содержать повторяющиеся значения, но каждая строка должна содержать уникальную комбинацию значений в ограниченных столбцах.
Обзор
Ограничение CHECK определяет условие для столбца, известное как предикат, которому должно соответствовать любое введенное в него значение.
Предикаты ограничения CHECK записываются в виде выражения, которое может быть результатом TRUE, FALSE или потенциально неизвестно. Если вы попытаетесь ввести значение в ограничение CHECK, и это значение приведёт к тому, что выражение вернёт значение TRUE или неизвестно (что происходит со значениями NULL), операция будет выполнена успешно. Однако, если выражение вернёт значение FALSE, операция завершится ошибкой.
Предикаты CHECK часто используют математический оператор сравнения (например, <, >, <=, OR >=) для ограничения диапазона данных, допустимых в данном столбце. Например, одно из распространённых применений ограничений CHECK — предотвращение хранения отрицательных значений в некоторых столбцах в случаях, когда отрицательное значение не имеет смысла, как в примере ниже.
Этот оператор CREATE TABLE создаёт таблицу productInfo со столбцами для наименования, идентификационного номера и цены каждого товара. Поскольку отрицательная цена товара не имеет смысла, этот оператор применяет ограничение CHECK к столбцу цены, чтобы гарантировать, что он будет содержать только положительные значения:
CREATE TABLE productInfo (
productID int,
name varchar(30),
price decimal(4,2)
CHECK (price > 0)
);В предикате CHECK не должно использоваться математического оператора сравнения. Как правило, в предикате проверки можно использовать любой оператор SQL, который может принимать значения «истина», «ложь» или «неизвестно», включая LIKE, BETWEEN, IS NOT NULL и т. д. Некоторые, но не все, реализации SQL даже позволяют включать подзапрос в предикат CHECK. Однако следует отметить, что большинство реализаций не позволяют ссылаться на другую таблицу в выражении.
Он не пустой.
Ограничение NOT NULL предотвращает добавление любых значений NULL в указанный столбец.
В большинстве реализаций SQL, если вы вставляете строку данных, не указав значение для конкретного столбца, система базы данных по умолчанию представляет отсутствующие данные как NULL. В SQL NULL — это специальное ключевое слово, используемое для обозначения неизвестного, отсутствующего или неуказанного значения. Однако NULL — это не само значение, а состояние неизвестного значения.
Чтобы проиллюстрировать это различие, представьте себе таблицу, используемую для отслеживания клиентов в агентстве по подбору персонала, в которой есть столбцы для имени и фамилии каждого клиента. Если клиент использует только одно имя, например, “Шер”, “Ашер” или “Бейонсе”, администратор базы данных может ввести только одно имя в столбец “Имя”, что приведёт к тому, что СУБД вставит значение NULL в столбец «Фамилия». База данных не считает фамилию клиента буквально «пустой». Это просто означает, что значение столбца «Фамилия» в этой строке неизвестно или что поле не относится к данной конкретной записи.
Как следует из названия, ограничение NOT NULL предотвращает появление в заданном столбце значений NULL. Это означает, что для любого столбца с ограничением NOT NULL необходимо указать значение при вставке новой строки. В противном случае операция INSERT завершится ошибкой.
Результат
Ограничения — важный инструмент для тех, кто стремится разработать базу данных с высоким уровнем целостности и безопасности данных. Ограничивая данные, вводимые в столбец, можно гарантировать, что связи между таблицами будут поддерживаться должным образом, а база данных будет соответствовать бизнес-правилам, определяющим её назначение.









