









Введение
В этом руководстве объясняется, как установить Ollama для запуска языковых моделей на сервере под управлением Ubuntu или Debian. Также показано, как настроить чат-интерфейс с Open WebUI и использовать пользовательскую языковую модель.
Предпосылки
- Сервер с Ubuntu/Debian
- Вам нужен доступ пользователя root или пользователь с правами sudo.
- Прежде чем начать, вам необходимо выполнить начальную настройку, включая брандмауэр.
Шаг 1 — Установка Олламы
Ниже описана процедура ручной установки Ollama. Для быстрого старта вы можете воспользоваться скриптом установки и перейти к разделу “Шаг 2 – Установка Ollama WebUI”.
Чтобы установить Ollama самостоятельно, выполните следующие действия:
Если на вашем сервере установлен графический процессор Nvidia, убедитесь, что установлены драйверы CUDA.
nvidia-smi
Если у вас ещё не установлены драйверы CUDA, установите их сейчас. В этой конфигурации вы можете выбрать операционную систему и тип установщика, чтобы увидеть команды, которые необходимо выполнить с вашими настройками.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
Загрузите двоичный файл Ollama и создайте пользователя Ollama.
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaСоздайте файл сервиса. По умолчанию доступ к API Ollama осуществляется через порт 11434 127.0.0.1. Это означает, что API доступен только для локального хоста.
Если вам нужен внешний доступ к Олламе, вы можете Среда Удалите и установите IP-адрес для доступа к API Ollama. 0.0.0.0 Позволяет получить доступ к API через публичный IP-адрес сервера. Если вы используете Среда Если вы используете , убедитесь, что брандмауэр вашего сервера разрешает доступ к порту, который вы здесь настроили. 11434 Если у вас только один сервер, вам не нужно менять команду ниже.
Скопируйте и вставьте всё содержимое следующего блока кода. Этот новый файл /etc/systemd/system/ollama.service Создает и интерконтент ЭОФ Добавляет в новый файл.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
Перезагрузите демон systemd и включите службу Ollama.
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaПроверьте статус с помощью команды systemctl status olama. Если Olama не запущена, выполните команду systemctl start olama.
В терминале теперь можно запускать языковые модели и задавать вопросы. Например:
ollama run llama2
Следующий шаг объясняет, как установить веб-интерфейс, чтобы вы могли задавать свои вопросы в красивом интерфейсе через веб-браузер.
Шаг 2 — Установка Open WebUI
В документации Olama на GitHub вы найдете список различных веб- и терминальных интеграций. Этот пример объясняет, как установить Open WebUI.
Вы можете установить Open WebUI на том же сервере, что и Ollama, или Ollama и Open WebUI на двух отдельных серверах. Если вы устанавливаете Open WebUI на отдельном сервере, убедитесь, что API Ollama доступен в вашей сети. Для дополнительной проверки: /etc/systemd/system/olama.service Посмотрите сервер, на котором установлена Ollama, и значение OLLAMA_HOST Подтверждать.
Следующие шаги объясняют, как установить интерфейс:
- Вручную
- С Докером
Установить Open WebUI вручную
Установите npm и pip, клонируйте репозиторий WebUI и создайте копию файла примера среды:
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .envВ среда. Адрес для подключения к API Ollama установлен по умолчанию. локальный хост:11434 Если вы установили Ollama API на том же сервере, что и Open WebUI, вы можете оставить эти настройки без изменений. Если вы установили Open WebUI на другом сервере, чем Ollama API, среда. Отредактируйте и замените значение по умолчанию на адрес сервера, на котором установлен Olama.
Зависимости, перечисленные в пакет.json Установите и запустите скрипт с именем строить Бегать:
npm i && npm run build
Установите необходимые пакеты Python:
cd backend
sudo pip install -r requirements.txt -UВеб-интерфейс с olama-webui/backend/start.sh Начинать.
sh start.shВ старт.ш, порт установлен на 8080. Это означает, что вы можете получить доступ к Open WebUI в http:// :8080 Доступ. Если на вашем сервере активен брандмауэр, вам необходимо разрешить порт, прежде чем вы сможете получить доступ к интерфейсу чата. Для этого перейдите к разделу «Шаг 3 – Разрешение портов для веб-интерфейса». Если брандмауэра у вас нет (что не рекомендуется), перейдите к разделу «Шаг 4 – Добавление моделей».
Установить Open WebUI с Docker
Для этого шага вам потребуется установить Docker. Если вы ещё не установили Docker, вы можете сделать это сейчас, следуя этой инструкции.
Как упоминалось ранее, вы можете установить Open WebUI на тот же сервер, что и Ollama, или установить Ollama и Open WebUI на два отдельных сервера.
Установить Open WebUI на тот же сервер Ollama
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Установить Open WebUI на другой сервер, нежели Ollama
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
В приведенной выше команде Docker порт установлен на 3000. Это означает, что вы можете получить доступ к Open WebUI на http:// :3000 Доступ. Если на вашем сервере активен брандмауэр, вам необходимо разрешить порт, прежде чем вы сможете получить доступ к интерфейсу чата. Это объясняется в следующем шаге.
Шаг 3 — Разрешить порт для веб-интерфейса
Если у вас есть брандмауэр, убедитесь, что он разрешает доступ к порту Open WebUI. Если вы установили его вручную, вам потребуется открыть порт. 8080 TCP Если вы установили его с помощью Docker, вам нужно разрешить порт 3000 ТКП Разрешите.
Чтобы проверить еще раз, вы можете использовать netstat Используйте и посмотрите, какие порты используются.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTENСуществует несколько различных инструментов для управления брандмауэром. В этом руководстве мы настроим брандмауэр по умолчанию для Ubuntu. УФВ Если вы используете другой брандмауэр, убедитесь, что он разрешает входящий трафик на TCP-порт 8080 или 3000.
Управление правилами брандмауэра УФВ:
- Просмотреть текущие настройки брандмауэра
Чтобы проверить, есть ли брандмауэр УФВ активен и у вас уже есть какие-либо правила, вы можете использовать следующее:
sudo ufw status
- Разрешить TCP-порт 8080 или 3000
Если брандмауэр включен, выполните эту команду, чтобы разрешить входящий трафик на TCP-порт 8080 или 3000:
sudo ufw allow proto tcp to any port 8080
- Просмотреть новые настройки брандмауэра
Теперь должны быть добавлены новые правила. Чтобы проверить, перейдите по ссылке:
sudo ufw status
Шаг 4 — Добавление моделей
После входа в веб-интерфейс вам необходимо создать свою первую учётную запись. У этого пользователя будут права администратора. Чтобы начать первый чат, вам необходимо выбрать модель. Список моделей можно посмотреть на официальном сайте llama. В этом примере мы добавим “llama2”.
В правом верхнем углу выберите значок настроек.
Перейдите в раздел “Модели”, введите модель и нажмите кнопку загрузки.
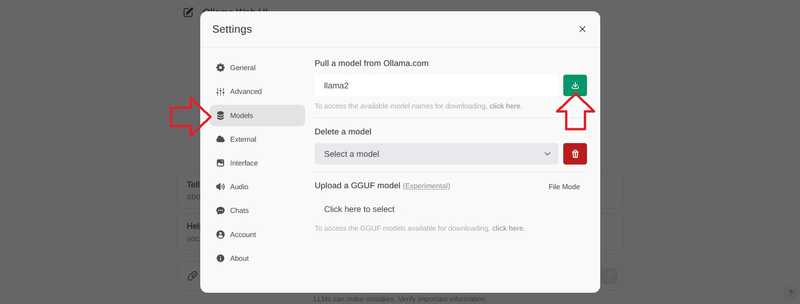
Дождитесь появления этого сообщения:
Model 'llama2' has been successfully downloaded.
Закройте настройки, чтобы вернуться в чат.
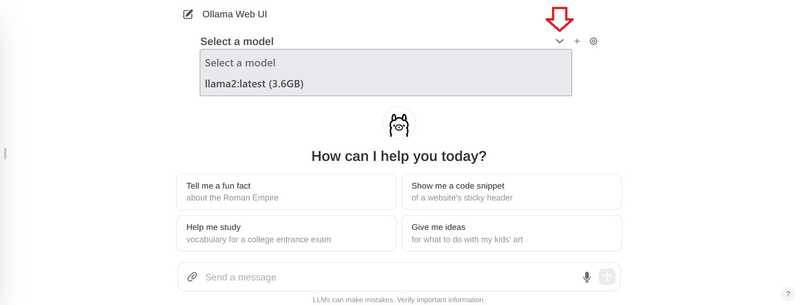
В чате нажмите “Выбрать модель” вверху и добавьте свою модель.
Если вы хотите добавить несколько моделей, вы можете использовать знак + вверху.
Добавив нужные модели, вы можете начать задавать вопросы. Если вы добавили несколько моделей, вы можете переключаться между ответами.

Шаг 5 — Добавьте свою модель
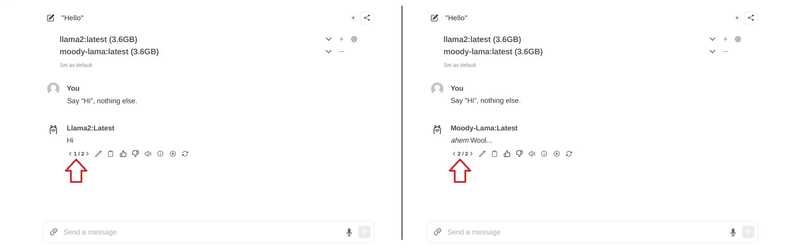
Если вы хотите добавить новые модели через интерфейс, вы можете сделать это через http:// :8080/modelfiles/create/ Сделай это. Если нужно. 8080 с 3000 Заменять.
Далее мы рассмотрим добавление новой модели через терминал. Для начала вам необходимо подключиться к серверу, на котором установлен Olama. Из списка мир Используйте для просмотра списка моделей, доступных на данный момент.
- Создать файл модели
Требования к файлу модели можно найти в документации Olama на GitHub. В первой строке файла модели FROM Вы можете указать, какую модель хотите использовать. В этом примере мы изменим существующую модель llama2. Если вы хотите добавить совершенно новую модель, необходимо указать путь к файлу модели (например, FROM ./my-model.gguf).
nano new-model
Сохраните этот контент:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
SYSTEM You are a moody lama that only talks about its own fluffy wool.Создать модель из файла модели
ollama create moody-lama -f ./new-model
- Проверьте, доступна ли новая модель.
Используйте команду olama для получения списка всех моделей. Moody-lama также должна быть в списке.
ollama list
- Используйте свою модель в WebUI
Когда вы вернётесь в веб-интерфейс, модель должна появиться в списке выбора. Если она ещё не отображается, возможно, вам потребуется быстро обновить страницу.
Результат
В этом уроке вы узнали, как разместить чат ИИ на своем собственном сервере и как добавлять собственные модели.









