









TensorFlow
TensorFlow Это библиотека машинного и глубокого обучения, разработанная Google, которая используется в различных приложениях для улучшения пользовательского опыта. Например, когда вы начинаете поиск, Google автоматически дополняет ваш текст.
Машинное обучение используют три группы людей: 1. Исследователи 2. Специалисты по анализу данных 3. Программисты. Чтобы удовлетворить потребности этих людей, команда Google Brain создала библиотеку TensorFlow. TensorFlow может работать на различных процессорах и графических процессорах и работать с различными языками программирования, такими как C++, Python или Java. TensorFlow можно использовать на серверах и даже на мобильных телефонах.
История TensorFlow
По мере увеличения объема данных глубокое обучение стало вытеснять алгоритмы глубокого обучения, и компания Google пришла к выводу, что может улучшить свои сервисы с помощью этих глубоких нейронных сетей, и начала создавать фреймворк под названием TensorFlow, который мог бы помочь разработчикам и исследователям одновременно работать вместе над моделями ИИ.
Когда проект был достаточно развит и масштабируем, он был представлен публике в 2015 году. Однако стабильная версия была выпущена только в 2017 году.
Важной особенностью TensorFlow является то, что он имеет открытый исходный код и лицензирован Apache, поэтому вы можете легко использовать его, редактировать и публиковать свой дистрибутив. Вы даже можете зарабатывать на нём, не платя Google. .
Архитектура TensorFlow
Архитектура TensorFlow состоит из трёх частей: 1. Предварительная обработка данных; 2. Построение модели; 3. Обучение и оценка модели. Название TensorFlow обусловлено тем, что на входе он получает многомерные массивы, имена которых тензор И затем вы можете запустить серию графиков операций над вашими данными, которые блок-схема Да.
Где это делается?
Использование этой библиотеки состоит из двух этапов:
Фаза разработки: Наступает момент, когда вы обучаете модель, и этот этап обычно выполняется на вашем ноутбуке или системе.
Фаза реализации: После завершения обучения вы сможете запускать свою модель где угодно: на настольных компьютерах, серверах и даже мобильных телефонах.
Таким образом, обучение и запуск модели можно осуществлять на разных машинах.
Помимо использования центральных процессоров, TensorFlow также можно запускать на графических процессорах.
В матричных вычислениях, поскольку один и тот же оператор применяется к большому объему информации, этот тип вычислений совместим со структурой графических процессоров, как обнаружили исследователи из Стэнфорда в конце 2010 года.
Ещё один плюс — эта библиотека написана на C++, поэтому она очень быстрая. Конечно, её можно использовать и с другими языками, например, с Python.
Важной функцией TensorFlow является TensorBoard, который позволяет вам видеть, что делает TensorFlow.
Компоненты TensorFlow
Тензор
Тензор — это массив N-мерных матриц, которые могут представлять различные типы информации. Каждое значение тензора содержит информацию одинаковой формы.
Тензоры могут быть входными или выходными данными расчета.
График
В TensorFlow все операции выполняются в графе. Каждый граф представляет собой набор вычислений, выполняемых последовательно. Каждое вычисление называется узлом операции и связано друг с другом.
А почему именно график?
- Может работать на разных системах.
- График можно сохранить для использования в будущем.
- Все вычисления в графике производятся путем соединения тензоров между собой.
- Короче говоря, в графах каждое ребро — это значение (тензор), а каждый узел — это оператор (например, сложение).
Почему TensorFlow так популярен?
TensorFlow — лучший инструмент, поскольку он разработан для всеобщего использования и использует API, которые можно использовать в различных масштабах с архитектурами глубокого обучения, такими как рекуррентные и сверточные нейронные сети. Благодаря графовым вычислениям, TensorFlow позволяет визуализировать нейронные сети внутри TensorBoard, что очень полезно для отладки. Кроме того, TensorFlow разработан с учётом масштабируемости при развёртывании.
Хорошей новостью является то, что у него самое большое сообщество среди различных фреймворков глубокого обучения на GitHub.
Сколько алгоритмов поддерживает TensorFlow?
- Линейная регрессия: tf.estimator.LinearRegressor
- Классификация: tf.estimator.LinearClassifier
- Глубокая классификация: tf.estimator.DNNClassifier
- Глубокое обучение и очистка: tf.estimator.DNNLinearCombinedClassifier
- Регрессия бустерного дерева: tf.estimator.BoostedTreesRegressor
- Улучшенная классификация деревьев: tf.estimator.BoostedTreesClassifier
Несколько простых примеров
- 12импортировать numpy как np
- импортировать тензорный поток как tf
В двух строках выше мы импортируем библиотеки numpy и tensorflow.
В этом примере мы хотим перемножить X_1 и X_2. Сначала нам нужно создать график, а затем запустить сеанс TensorFlow для вычисления результата.
Давайте начнем.
Шаг 1: Определите переменную
Первый шаг — создание входных узлов X_1, X_2. В TensorFlow нам нужно указать тип создаваемого узла. Здесь мы выбираем тип плейсхолдера.
заполнитель:
Этот тип присваивает тензору новое значение каждый раз, когда мы выполняем вычисление.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
Как видите, мы ввели тип этого узла как float, а его имя как имя переменной.
Шаг 2: Определите расчет
- 1умножить = tf.multiply(X_1, X_2, имя = “умножить”)
С помощью приведенной выше строки мы создаем вершину, которая действует как оператор оператора умножения.
Это входные данные вершин, которые мы хотим умножить, и мы назвали их умножением.
Итак, мы создали наш первый график.
Шаг 3: Выполнение операции
Для выполнения операции необходимо создать сеанс. Этот сеанс создаётся с помощью tf.Session() и запускается при вызове run.
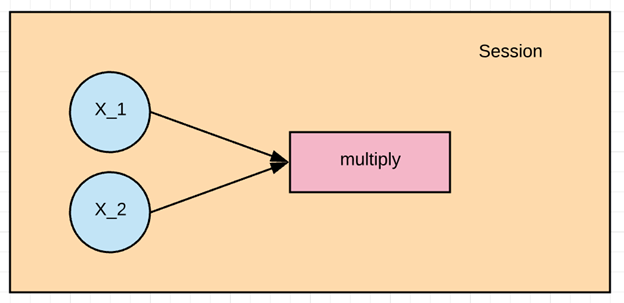
Для выполнения умножения нам необходимо передать на вход значения тензоров x1 и x2. Это делается с помощью назначения feed_dict. В этом примере значения от 1 до 3 присваиваются x1, а от 4 до 6 — x2. Результат выводится на экран.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
- 1умножить = tf.multiply(X_1, X_2, имя = “умножить”)
- с tf.Session() в качестве сеанса:
- результат = сеанс.выполнить(умножить, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- печать(результат)
- [ 4. 10. 18.]
Различные способы импорта данных в TensorFlow
Итак, одним из первых шагов перед обучением модели является импорт данных, который имеет два режима:
- Ввод данных в оперативную память: существует простой способ ввода данных в массив памяти, например, путем написания строки кода на Python.
- Использование конвейера данных TensorFlow: TensorFlow предоставляет набор API, которые помогают вам получать данные, выполнять над ними ряд операций и затем передавать их вашему алгоритму. Этот метод очень эффективен, особенно когда данные очень большие. Например, изображения имеют огромный объём и не помещаются в оперативную память. В этом случае конвейер данных берёт на себя управление оперативной памятью.
Теперь вопрос в том, какой из них использовать.
Если объём ваших данных меньше 10 ГБ, вы можете легко использовать первый метод, например, для этого есть известная библиотека pandas. В противном случае, например, если у вас 30 ГБ данных и объём оперативной памяти составляет 12 ГБ, вы, естественно, не сможете использовать этот метод и вам следует обратиться к API конвейера. Конвейер группирует данные, и каждый пакет поступает в конвейер и используется для обучения модели. Использование конвейера позволяет использовать параллельную обработку. Это означает, что TensorFlow может обучать модель на нескольких разных процессорах одновременно.
Короче говоря, если у вас небольшой объём данных, загружайте их полностью в оперативную память, например, с помощью Pandas. В противном случае, или если вы хотите использовать несколько процессоров, используйте конвейер TensorFlow.
Создание конвейера в TensorFlow
Шаг 1) Создание данных
Мы генерируем два случайных числа с помощью библиотеки numpy.
- 123импортировать numpy как np
- x_input = np.random.sample((1,2))
- печать(x_input)
- 1[[0.8835775 0.23766977]]
Шаг 2) Создайте заполнитель
На этом этапе мы создаем заполнитель с именем X как массив с двумя элементами типа float.
- используя заполнителя #
- x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
Шаг 3: Создайте набор данных
На этом этапе нам необходимо определить набор данных, в который мы поместим значение-заполнитель x.
- 1tf.data.Dataset.from_tensor_slices
- 1набор данных = tf.data.Dataset.from_tensor_slices(x)
Шаг 4: Постройте трубопровод
На этом этапе нам необходимо инициализировать конвейер. Первым шагом является создание итератора, который будет перебирать данные. С помощью метода get_next мы получаем следующее значение. В этом примере пакет содержит только два значения.
- 12итератор = набор данных.make_initializable_iterator()
- get_next = итератор.get_next()
Шаг 5: Выполните расчет
На последнем этапе мы запускаем сеанс, входными данными которого являются итератор и входные значения, созданные numpy, и для каждого из них мы выводим его значение.
- с tf.Session() в качестве сеанса:
- # наполняет заполнителем данными
- sess.run(итератор.инициализатор, feed_dict={ x: x_input })
- печать(sess.run(get_next))
- 1[0.8835775 0.23766978]
Краткое содержание
TensorFlow — самая известная библиотека для глубокого обучения, которую можно использовать для создания любого фреймворка. Компания Google Brain разработала этот проект, чтобы сократить разрыв между исследовательскими группами и командами разработчиков, и Google использует его практически во всех своих проектах. Одна из главных причин использования TensorFlow — простота масштабирования при развертывании. TensorFlow можно использовать как на мощных серверах, так и на устройствах Android и iOS.
TensorFlow работает в сеансе, где каждый сеанс определяется графиком с различными вычислениями.
В качестве простого примера в TensorFlow умножение выглядит следующим образом:
1. Определение переменной
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
2. Определение расчета
- 1умножить = tf.multiply(X_1, X_2, имя = “умножить”)
3. Выполнение операций
- с tf.Session() в качестве сеанса:
- результат = сеанс.выполнить(умножить, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- печать(результат)
Распространенной практикой в TensorFlow является создание конвейера для загрузки данных в оперативную память, что выполняется с помощью следующих шагов:
1. Создание данных
- импортировать numpy как np
- x_input = np.random.sample((1,2))
- печать(x_input)
2. Создайте заполнитель
- 1x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
3. Определение метода набора данных
- 1набор данных = tf.data.Dataset.from_tensor_slices(x)
4. Строительство трубопровода
- 1итератор = набор данных.make_initializable_iterator() get_next = итератор.get_next()
5. Выполнение программы
- с tf.Session() в качестве сеанса:
- sess.run(итератор.инициализатор, feed_dict={ x: x_input })
- печать(sess.run(get_next))









