









Введение
Представьте, что вы можете вести диалог со своими неструктурированными данными и легко извлекать ценную информацию. В современном мире, где данные играют ключевую роль, извлечение значимых выводов из неструктурированных документов остается сложной задачей, препятствующей принятию решений и инновациям. В этом руководстве мы познакомимся с эмбеддингами, изучим использование Amazon Open Search в качестве векторной базы данных и интегрируем фреймворк Langchain с большими языковыми моделями (LLM) для создания веб-сайта со встроенным чат-ботом на основе обработки естественного языка (NLP). Мы рассмотрим основы LLM для извлечения значимых выводов из неструктурированного документа с помощью большой языковой модели с открытым исходным кодом. К концу этого руководства вы получите всестороннее понимание того, как извлекать значимые выводы из неструктурированных документов, и сможете использовать эти навыки для исследования и внедрения инноваций с помощью аналогичных комплексных решений на основе искусственного интеллекта.
Предпосылки
- У вас должна быть активная учетная запись AWS. Если у вас ее нет, вы можете зарегистрироваться на веб-сайте AWS.
- Убедитесь, что на вашем локальном компьютере установлен интерфейс командной строки AWS (CLI), и что он правильно настроен с необходимыми учетными данными и регионом по умолчанию. Вы можете настроить его с помощью команды `aws configure`.
- Загрузите и установите Docker Engine. Следуйте инструкциям по установке для вашей операционной системы.
Что мы собираемся построить?
В этом примере мы хотим смоделировать проблему, с которой сталкиваются многие компании. Большая часть современных данных неструктурирована, а точнее, представлена в виде аудио- и видеозаписей, PDF- и Word-документов, руководств, отсканированных заметок, расшифровок сообщений в социальных сетях и т. д. В качестве модели LLM мы будем использовать модель Flan-T5 XXL. Эта модель может генерировать резюме и ответы на вопросы из неструктурированных текстов. На изображении ниже показана архитектура различных строительных блоков.

Начнём с основ.
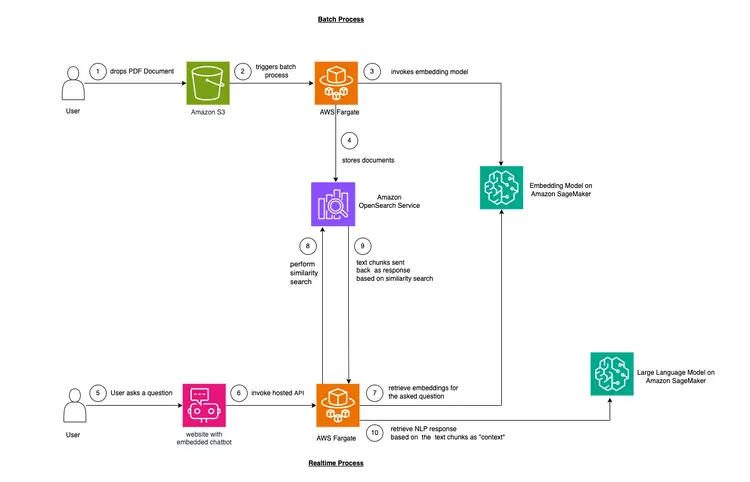
Мы будем использовать метод, называемый контекстным обучением, чтобы внедрить в нашу модель обучения с подробным описанием предметной области или конкретного случая “контекст”. В данном случае у нас есть неструктурированное PDF-руководство по эксплуатации автомобиля, которое мы хотим добавить в качестве «контекста» для модели обучения, и мы хотим, чтобы модель обучения отвечала на вопросы по этому руководству. Всё просто! Наша цель — пойти дальше и создать API в реальном времени, который будет получать вопросы, отправлять их на наш бэкэнд и будет доступен через встроенного в веб-сайт чат-бота с открытым исходным кодом. Этот учебный материал позволит нам создать полный пользовательский интерфейс и получить представление о различных концепциях и инструментах на протяжении всего процесса.
- Первым шагом для обеспечения обучения непосредственно в тексте является обработка PDF-документа и преобразование его в текстовые фрагменты, генерация векторных представлений этих текстовых фрагментов, называемых “эмбеддингами”, и, наконец, сохранение этих эмбеддингов в векторной базе данных.
- Векторные базы данных позволяют нам выполнять «поиск сходства» по хранящимся в них векторным представлениям текста.
- Amazon SageMaker JumpStart предоставляет шаблоны решений для развертывания в один клик, позволяющие настроить инфраструктуру для предварительно обученных моделей с открытым исходным кодом. Мы будем использовать Amazon SageMaker JumpStart для развертывания модели Embedding и модели Large Language.
- Amazon OpenSearch — это поисковая и аналитическая система, которая может искать ближайших соседей точек в векторном пространстве, что делает её подходящей в качестве векторной базы данных.
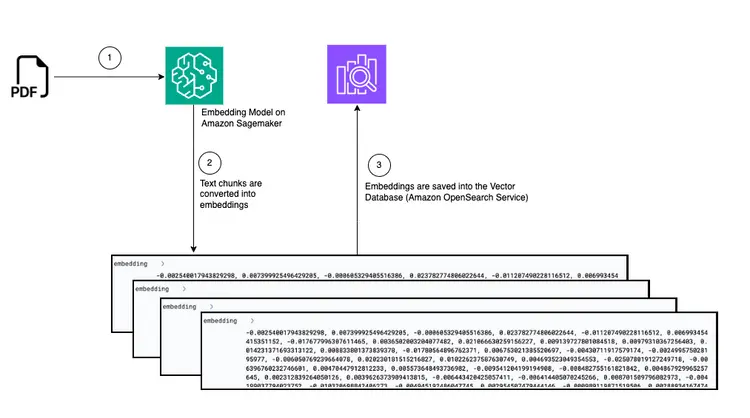
Диаграмма: Преобразование из PDF-файла для встраивания в векторную базу данных.
Шаг 1 — Разверните модель встраивания GPT-J 6B FP16 с помощью Amazon SageMaker JumpStart
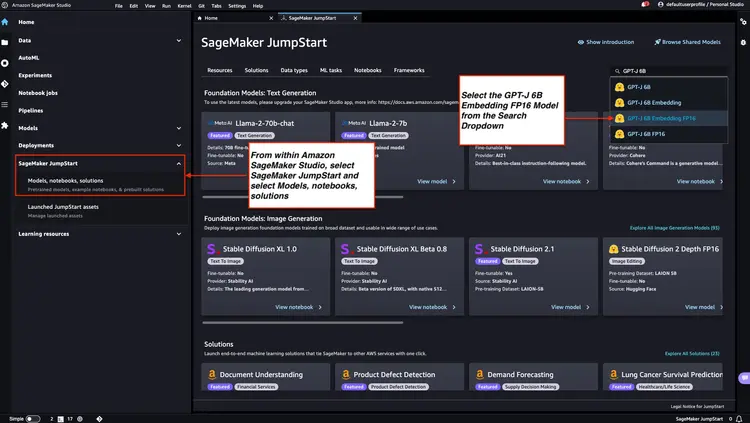
Следуйте инструкциям, указанным в документации Amazon SageMaker: откройте и используйте раздел JumpStart, чтобы запустить узел Amazon SageMaker JumpStart из главного меню Amazon SageMaker Studio. Выберите ‘Модели’, «Записные книжки», «Решения» и выберите модель встраивания GPT-J 6B Embedding FP16, как показано на изображении ниже. Затем нажмите «Развернуть», и Amazon SageMaker JumpStart позаботится о настройке инфраструктуры для развертывания этой предварительно обученной модели в среде SageMaker.
Шаг 2 — Развертывание Flan T5 XXL LLM с помощью Amazon SageMaker JumpStart
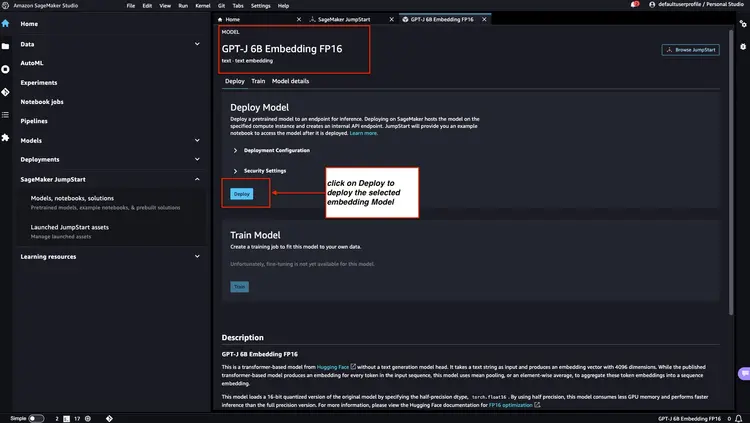
Далее в Amazon SageMaker JumpStart выберите Flan-T5 XXL LLM, а затем нажмите ‘Развернуть’, чтобы начать автоматическую настройку инфраструктуры и развернуть конечную точку модели в среде Amazon SageMaker.
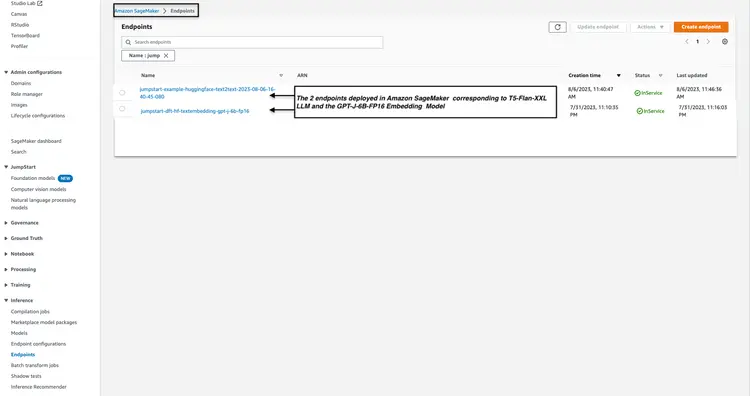
Шаг 3 — Проверьте состояние развернутых конечных точек модели.
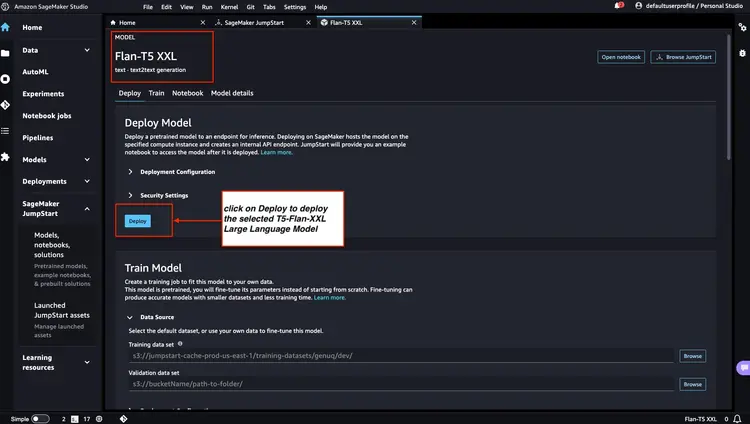
Мы проверяем статус развернутых конечных точек модели из шагов 1 и 2 в консоли Amazon SageMaker и записываем их имена, поскольку будем использовать их в нашем коде. Вот как выглядит моя консоль после развертывания конечных точек модели.
Шаг 4 – Создание кластера Amazon Open Search
Amazon OpenSearch — это сервис поиска и аналитики, поддерживающий алгоритм k-ближайших соседей (kNN). Эта возможность бесценна для поиска по сходству и позволяет эффективно использовать OpenSearch в качестве векторной базы данных. Для получения дополнительной информации о версиях Elasticsearch/OpenSearch, поддерживающих плагин kNN, перейдите по следующей ссылке: Документация по плагину k-NN.
Для развертывания файла шаблона AWS CloudFormation из репозитория GitHub мы используем AWS CLI. Infrastructure/opensearch-vectordb.yaml Мы воспользуемся командой aws. cloudformation create-stack Выполните следующую команду для создания кластера Amazon Open Search. Перед выполнением команды необходимо заменить значения на свои собственные. имя пользователя и пароль Давай сделаем это.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> Шаг 5 – Создание рабочего процесса захвата и встраивания документов
На этом этапе мы создадим конвейер для приема и обработки PDF-документов, предназначенный для чтения документов, помещенных в хранилище Amazon Simple Storage Service (S3). Этот конвейер будет выполнять следующие задачи:
- Извлечение текста из PDF-документа.
- Преобразовать фрагменты текста в векторные представления (эмбеддинги).
- Сохраняйте встроенные элементы в Amazon Open Search.
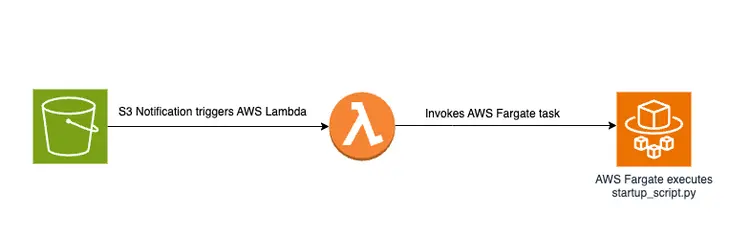
Загрузка PDF-файла в хранилище S3 запускает управляемый событиями рабочий процесс, включающий задание AWS Fargate. Это задание будет отвечать за преобразование текста в встроенные элементы и их вставку в Amazon Open Search.
Схематический обзор
Ниже представлена схема, демонстрирующая конвейер передачи документов для хранения встроенных текстовых фрагментов в векторной базе данных Amazon OpenSearch:
Скрипт запуска и структура файлов
Основная логика в файле create-embeddings-save-in-vectordb\startup_script.py Этот скрипт на Python находится по адресу: startup_script.pyЭтот скрипт выполняет несколько задач, связанных с обработкой документов, встраиванием текста и его добавлением в кластер Amazon Open Search. Скрипт загружает PDF-документ из хранилища Amazon S3, а затем разбивает загруженный документ на более мелкие текстовые фрагменты. Для каждого фрагмента текстовое содержимое отправляется в конечную точку модели встраивания GPT-J 6B FP16, развернутую в Amazon SageMaker (получается из переменной среды TEXT_EMBEDDING_MODEL_ENDPOINT_NAME), для создания текстовых встраиваний. Созданные встраивания помещаются в индекс Amazon Open Search вместе с другой информацией. Скрипт извлекает параметры конфигурации и проверки из переменных среды и обеспечивает их согласованность во всех средах. Скрипт предназначен для унифицированного запуска в контейнере Docker.
Создайте и опубликуйте образ Docker.
После понимания кода в startup_script.pyМы создадим Dockerfile из этой папки. create-embeddings-save-in-vectordb Мы загрузим образ в Amazon Elastic Container Registry (Amazon ECR). Amazon Elastic Container Registry (Amazon ECR) — это полностью управляемый реестр контейнеров, обеспечивающий высокопроизводительный хостинг, позволяющий надежно развертывать образы приложений и артефакты в любом месте. Для сборки и загрузки образа Docker в Amazon ECR мы будем использовать AWS CLI и Docker CLI. Во всех приведенных ниже командах... Замените на правильный номер учетной записи AWS.
Получите токен аутентификации и выполните аутентификацию клиента Docker в реестре с помощью AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com Создайте образ Docker, используя следующую команду.
docker build -t save-embedding-vectordb .
После завершения сборки добавьте тег к образу, чтобы мы могли загрузить его в этот репозиторий:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Выполните следующую команду, чтобы загрузить этот образ в новый репозиторий Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
После загрузки образа Docker в репозиторий Amazon ECR он должен выглядеть следующим образом:
Создайте инфраструктуру для рабочего процесса встраивания PDF-файлов на основе событий.
Мы можем использовать интерфейс командной строки AWS (AWS CLI) для создания стека CloudFormation для событийно-ориентированного рабочего процесса с предоставленными параметрами. Шаблон CloudFormation доступен в репозитории GitHub по адресу: Infrastructure/fargate-embeddings-vectordb-save.yaml Нам необходимо игнорировать параметры, чтобы соответствовать среде AWS.
Вот основные параметры, которые необходимо обновить в команде. aws cloudformation create-stack Утверждается:
- BucketName: Этот параметр обозначает корзину Amazon S3, куда мы будем помещать PDF-документы.
- VpcId и SubnetId: Эти параметры определяют, где будет выполняться задача Fargate.
- ImageName: Это имя образа Docker в реестре Amazon Elastic Container Registry (ECR) для save-embedding-vectordb.
- TextEmbeddingModelEndpointName: Используйте этот параметр, чтобы указать имя модели Embedding, развернутой в Amazon SageMaker на шаге 1.
- VectorDatabaseEndpoint: Укажите адрес конечной точки домена Amazon OpenSearch.
- VectorDatabaseUsername и VectorDatabasePassword: Эти параметры предназначены для ввода учетных данных, необходимых для доступа к кластеру Amazon Open Search, созданному на шаге 4.
- VectorDatabaseIndex: Укажите имя индекса в Amazon Open Search, где хранятся встроенные PDF-документы.
Для создания стека CloudFormation после обновления значений параметров мы используем следующую команду AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualСоздав описанный выше стек CloudFormation, мы настраиваем корзину S3 и создаём уведомления S3, которые запускают функцию Lambda. Эта функция Lambda, в свою очередь, запускает задачу Fargate. Задача Fargate создаёт контейнер Docker с файлом startup-script.py Реализация, отвечающая за создание встроенных данных в Amazon OpenSearch в рамках нового индекса OpenSearch, называемого руководство по эксплуатации автомобиля Это.
Протестируйте на примере PDF-файла.
После запуска стека CloudFormation, поместите PDF-файл с руководством пользователя в свой S3-корзину. Я скачал руководство пользователя, доступное здесь. После завершения работы конвейера передачи данных на основе событий, кластер Amazon Open Search должен содержать следующий профиль: руководство по эксплуатации автомобиля С использованием представленных ниже векторных представлений.
Шаг 6 – Реализация API для вопросов и ответов в реальном времени с поддержкой LLM-текста
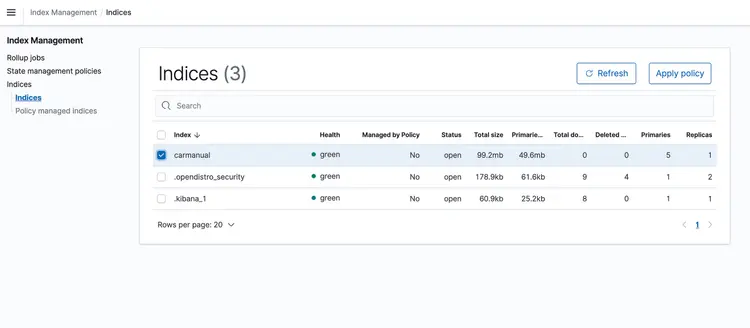
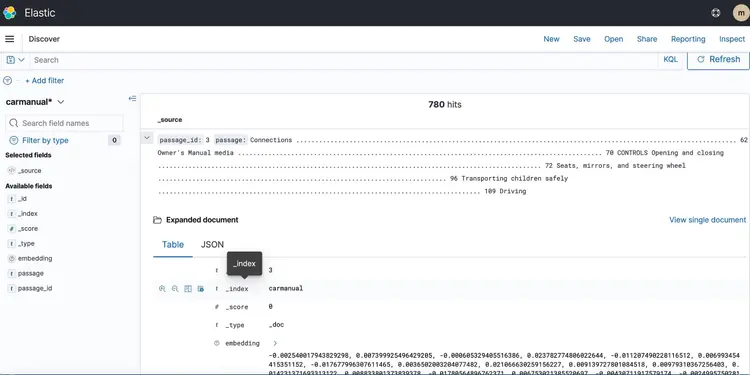
Теперь, когда у нас есть встроенные текстовые данные в векторной базе данных, работающей на базе Amazon Open Search, перейдем к следующему шагу. Здесь мы воспользуемся возможностями T5 Flan XXL LLM, чтобы предоставлять ответы в режиме реального времени по руководству по эксплуатации нашего автомобиля.
Мы используем векторные представления, хранящиеся в базе данных векторов, чтобы обеспечить контекст для LLM. Этот контекст позволяет LLM эффективно понимать и отвечать на вопросы о нашем руководстве по эксплуатации автомобиля. Для этого мы будем использовать фреймворк LangChain, который упрощает координацию различных компонентов, необходимых для нашей системы вопросов и ответов в реальном времени, учитывающей текст, разработанной LLM.
Векторные представления, хранящиеся в базе данных, отображают значения и взаимосвязи слов и позволяют выполнять вычисления на основе семантического сходства. В то время как векторные представления создают фрагменты текста для фиксации значений и взаимосвязей, программа T5 Flan LLM специализируется на создании контекстно-релевантных ответов на основе контекста, заложенного в запросы и вопросы. Цель состоит в том, чтобы сопоставить вопросы пользователей с фрагментами текста, создавая векторные представления для вопросов, а затем измеряя их сходство с другими векторными представлениями, хранящимися в базе данных.
Представляя фрагменты текста и пользовательские запросы в виде векторов, мы можем выполнять математические вычисления для поиска сходства с учетом контекста. Для измерения сходства между двумя точками данных мы используем метрики расстояния в многомерном пространстве.
На приведенной ниже диаграмме показан рабочий процесс вопросов и ответов в режиме реального времени, предоставляемый LangChain и нашей программой T5 Flan LLM.
Графический обзор поддержки вопросов и ответов в режиме реального времени от T5-Flan-XXL LLM
Создайте API
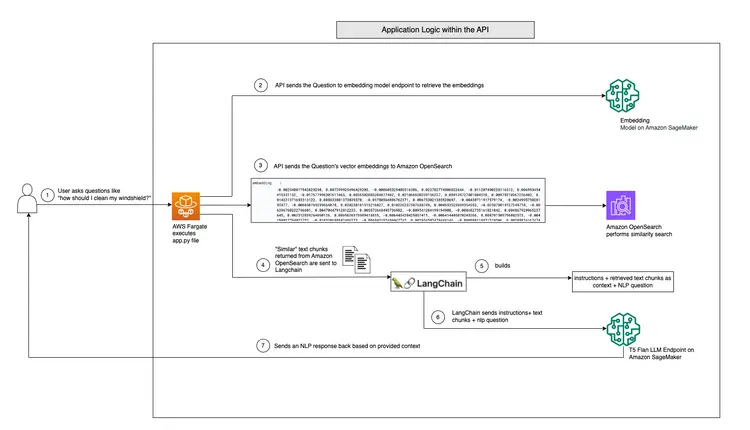
Теперь, когда мы рассмотрели наш рабочий процесс LangChain и T5 Flask LLM, давайте перейдем к коду нашего API, который принимает вопросы пользователей и предоставляет контекстно-зависимые ответы. Этот API для вопросов и ответов в реальном времени находится в папке RAG-langchain-questionanswer-t5-llm нашего репозитория GitHub, а его основная логика находится в файле app.py. Это приложение на основе Flask определяет маршрут /qa для ответов на вопросы.
Когда пользователь отправляет запрос к API, используется переменная среды TEXT_EMBEDDING_MODEL_ENDPOINT_NAME, указывающая на конечную точку Amazon SageMaker, для преобразования запроса в числовые векторные представления, называемые эмбеддингами. Эти эмбеддинги отражают семантическое значение текста.
API дополнительно использует Amazon OpenSearch для выполнения контекстно-зависимого поиска сходства, что позволяет ему получать релевантные текстовые фрагменты из руководства по работе с каталогами OpenSearch на основе векторных представлений, полученных из пользовательских запросов. После этого шага API вызывает конечную точку T5 Flan LLM, идентифицируемую переменной среды T5FLAN_XXL_ENDPOINT_NAME, которая также развернута в Amazon SageMaker. Конечная точка использует текстовые фрагменты, полученные из Amazon OpenSearch, в качестве контекста для генерации ответов. Эти текстовые фрагменты, полученные из Amazon OpenSearch, служат ценным контекстом для конечной точки T5 Flan LLM, позволяя ей предоставлять содержательные ответы на пользовательские запросы. Код API использует LangChain для организации всех этих взаимодействий.
Создайте и опубликуйте образ Docker для API.
После изучения кода в файле app.py мы переходим к сборке Dockerfile из папки RAG-langchain-questionanswer-t5-llm и загрузке образа в Amazon ECR. Для сборки и загрузки образа Docker в Amazon ECR мы будем использовать AWS CLI и Docker CLI. Во всех приведенных ниже командах... Замените на правильный номер учетной записи AWS.
Получите токен аутентификации и выполните аутентификацию клиента Docker в реестре с помощью AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Создайте образ Docker, используя следующую команду.
docker build -t qa-container .
После завершения сборки добавьте тег к образу, чтобы мы могли загрузить его в этот репозиторий:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Выполните следующую команду, чтобы загрузить этот образ в новый репозиторий Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
После загрузки образа Docker в репозиторий Amazon ECR он должен выглядеть следующим образом:
Создайте стек CloudFormation для размещения конечной точки API.
Мы будем использовать интерфейс командной строки AWS (CLI) для создания стека CloudFormation для кластера Amazon ECS, на котором размещена задача Fargate для предоставления доступа к API. Шаблон CloudFormation находится в репозитории GitHub по адресу Infrastructure/fargate-api-rag-llm-langchain.yaml. Нам необходимо переопределить параметры в соответствии со средой AWS. Вот ключевые параметры, которые необходимо обновить в команде aws cloudformation create-stack:
- DemoVPC: Этот параметр указывает виртуальную частную сеть (VPC), в которой будет работать ваш сервис.
- PublicSubnetIds: Этот параметр требует указания списка идентификаторов публичных подсетей, в которых будут расположены ваш балансировщик нагрузки и задачи.
- IMAGENAME: Укажите имя образа Docker в реестре Amazon Elastic Container Registry (ECR) для контейнера qa.
- TextEmbeddingModelEndpointName: Укажите имя конечной точки модели Embeddings, развернутой в Amazon SageMaker на шаге 1.
- T5FlanXXLEndpointName: Укажите имя конечной точки T5-FLAN, развернутой в Amazon SageMaker на шаге 2.
- VectorDatabaseEndpoint: Укажите адрес конечной точки домена Amazon OpenSearch.
- VectorDatabaseUsername и VectorDatabasePassword: Эти параметры предназначены для ввода учетных данных, необходимых для доступа к кластеру OpenSearch, созданному на шаге 4.
- VectorDatabaseIndex: Укажите имя индекса в Amazon OpenSearch, где будут храниться данные вашей службы. В этом примере мы использовали имя индекса carmanual.
Для создания стека CloudFormation после обновления значений параметров мы используем следующую команду AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualПосле успешного запуска описанного выше стека CloudFormation перейдите в консоль AWS и откройте вкладку ‘Выходные данные CloudFormation’ для стека ecs-questionanswer-llm. На этой вкладке вы найдете необходимую информацию, включая конечную точку API. Ниже приведен пример того, как могут выглядеть выходные данные:
Протестируйте API
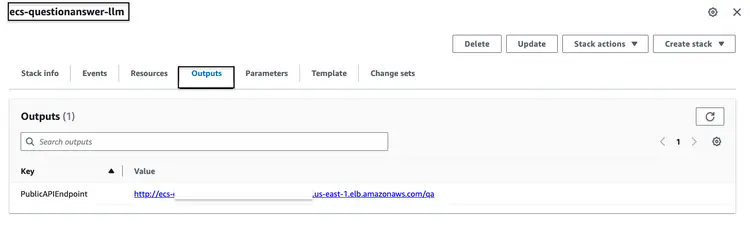
Проверить работоспособность API-интерфейса можно с помощью команды curl следующим образом:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
Мы увидим ответ, подобный приведенному ниже.
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
Шаг 7 – Создайте и разверните веб-сайт со встроенным чат-ботом.
Затем мы переходим к заключительному этапу нашего полного стека разработки, который интегрирует API со встроенным чат-ботом на HTML-сайте. Для этого веб-сайта и встроенного чат-бота наш исходный код представляет собой приложение Nodejs, состоящее из файла index.html, интегрированного с открытым исходным кодом botkit.js в качестве чат-бота. Чтобы упростить задачу, я создал Dockerfile и предоставил его вместе с кодом в папке homegrown_website_and_bot. Мы будем использовать AWS CLI и Docker CLI для сборки и отправки образа Docker в Amazon ECR для фронтенд-сайта. Во всех приведенных ниже командах... Замените на правильный номер учетной записи AWS.
Получите токен аутентификации и выполните аутентификацию клиента Docker в реестре с помощью AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Создайте образ Docker, используя следующую команду:
docker build -t web-chat-frontend .
После завершения сборки добавьте тег к образу, чтобы мы могли загрузить его в этот репозиторий:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Выполните следующую команду, чтобы загрузить этот образ в новый репозиторий Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
После того, как образ Docker для веб-сайта будет загружен в репозиторий ECR, мы создаём стек CloudFormation для фронтенда, запустив файл Infrastructure\fargate-website-chatbot.yaml. Нам необходимо переопределить параметры в соответствии со средой AWS. Вот ключевые параметры, которые необходимо обновить в команде aws cloudformation create-stack:
- DemoVPC: Этот параметр указывает виртуальную частную сеть (VPC), в которой будет развернут ваш веб-сайт.
- PublicSubnetIds: Этот параметр требует указания списка идентификаторов общедоступных подсетей, в которых будут размещены балансировщик нагрузки и задачи вашего веб-сайта.
- IMAGENAME: Введите имя образа Docker в реестре Amazon Elastic Container Registry (ECR) для вашего веб-сайта.
- QUESTURL: Укажите URL-адрес конечной точки API, развернутой на шаге 6. Его формат: http:// Это /qa.
Для создания стека CloudFormation после обновления значений параметров мы используем следующую команду AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaШаг 8 – Ознакомьтесь с интеллектуальным помощником Car Savvy AI Assistant.
После успешного создания описанного выше стека CloudFormation перейдите в консоль AWS и откройте вкладку «Выходные данные CloudFormation» для стека ecs-website-chatbot. На этой вкладке вы найдете DNS-имя балансировщика нагрузки приложений (ALB), связанного с интерфейсом пользователя. Ниже приведен пример того, как может выглядеть вывод:
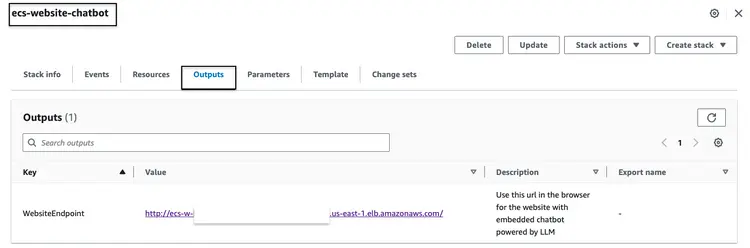
Откройте URL-адрес конечной точки в браузере, чтобы посмотреть, как выглядит веб-сайт. Задавайте встроенному чат-боту вопросы на естественном языке. Вот некоторые из вопросов, которые мы можем задать: “Как почистить лобовое стекло?”, “Где найти VIN-номер?”, “Как сообщить о неисправности, влияющей на безопасность?”
Что дальше?

Надеюсь, вышеизложенное покажет вам, как создавать собственные готовые к использованию конвейеры обработки данных для программ LLM и интегрировать их с вашими фронтенд-чат-ботами и встроенной обработкой естественного языка. Дайте мне знать, о чем еще вы хотели бы почитать об использовании технологий с открытым исходным кодом, аналитики, машинного обучения и AWS!
В процессе обучения я рекомендую вам глубже изучить эмбеддинги, векторные базы данных, LangChain и ряд других программ магистратуры в области машинного обучения. Они доступны в рамках программы Amazon SageMaker JumpStart, а также в инструментах AWS, которые мы использовали в этом руководстве, таких как Amazon OpenSearch, контейнеры Docker и Fargate. Вот несколько следующих шагов, которые помогут вам освоить эти технологии:
- Amazon SageMaker: По мере освоения SageMaker ознакомьтесь с другими предлагаемыми алгоритмами.
- AMAZON-OPEN SEARCH: Узнайте об алгоритме K-NN и других алгоритмах определения расстояния.
- Langchain: LangChain — это фреймворк, разработанный для упрощения создания приложений с использованием LLM.
- Эмбеддинги: Эмбеддинг — это числовое представление фрагмента информации, например, текста, документов, изображений, аудио и т. д.
- Amazon SageMaker JumpStart: SageMaker JumpStart предлагает предварительно обученные модели с открытым исходным кодом для широкого спектра задач, которые помогут вам начать работу с машинным обучением.
Стереть
- Войдите в AWS CLI. Убедитесь, что AWS CLI правильно настроен и имеет необходимые разрешения для выполнения этих действий.
- Удалите PDF-файл из вашего хранилища Amazon S3, выполнив следующую команду. Замените имя вашего хранилища на фактическое имя вашего хранилища Amazon S3 и при необходимости скорректируйте путь к PDF-файлу.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
Удалите стеки CloudFormation. Замените имена стеков на фактические имена ваших стеков CloudFormation.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2Результат
В этом руководстве мы создали полнофункциональный чат-бот для вопросов и ответов, используя технологии AWS и инструменты с открытым исходным кодом. Мы интегрировали Amazon OpenSearch в качестве векторной базы данных, модель встраивания GPT-J 6B FP16 и использовали Langchain с LLM. Чат-бот извлекает полезную информацию из неструктурированных документов.









