Введение
DeepSeek R1 в последние недели произвел настоящий фурор в сообществе ИИ/машинного обучения, и это не случайно. Он даже распространился за его пределы, оказав значительное влияние на экономику и политику. Во многом это объясняется открытым исходным кодом набора моделей и невероятно низкой стоимостью обучения, что показало широкому сообществу, что для обучения современных моделей ИИ требуется гораздо меньше капитала и специальных исследований, чем считалось ранее.
В первой части этой серии мы представили DeepSeek R1 и показали, как запустить модель с помощью Olama. В этой части мы начнем с более глубокого изучения того, что делает R1 по-настоящему особенной. Мы сосредоточимся на анализе уникальной парадигмы обучения с подкреплением (RL), чтобы увидеть, как можно стимулировать способности к рассуждению у моделей с линейной логикой (LLM) исключительно с помощью RL, а затем поговорим о том, как внедрение этих методов в другие модели позволяет нам делиться этими возможностями с существующими версиями. В заключение мы кратко продемонстрируем, как настроить и запустить модели DeepSeek R1 с помощью GPU Droplets, используя функцию 1-Click Model от GPU Droplets.
Предпосылки
- Глубокое обучение: В данной статье рассматриваются темы среднего и продвинутого уровня, связанные с обучением нейронных сетей и обучением с подкреплением.
- Аккаунт DigitalOcean: Для тестирования R1 мы будем использовать, в частности, GPU Droplets HuggingFace 1-Click Model от DigitalOcean.
Обзор DeepSeek R1
Исследовательский проект DeepSeek R1 был направлен на воссоздание эффективных возможностей рассуждения, демонстрируемых мощными моделями рассуждения, а именно моделью O1 от OpenAI. Для достижения этой цели они стремились улучшить свою существующую работу, DeepSeek-v3-Base, используя чистое обучение с подкреплением. Это привело к появлению DeepSeek R1 Zero, который демонстрирует отличные результаты по метрикам рассуждения, но не обладает возможностями человеческой интерпретации и проявляет некоторые необычные особенности поведения, такие как смешение языков.
Для решения этих проблем они предложили DeepSeek R1, который включает в себя небольшой объем данных для холодного старта и многоэтапный конвейер обучения. R1 достиг читаемости и применимости SOTA LLM за счет тонкой настройки модели DeepSeek-v3-Base на тысячах образцов данных для холодного старта, затем запуска еще одного раунда обучения с подкреплением, за которым последовала контролируемая тонкая настройка на наборе данных аргументов и, наконец, завершилась финальным раундом обучения с подкреплением. Затем они распространили эту технику на другие модели, контролируя их тонкую настройку на данных, собранных из R1.
Следите за обновлениями, чтобы узнать больше об этих этапах разработки и обсудить, как модель можно итеративно улучшать, чтобы достичь возможностей DeepSeek R1.
Учебное пособие по DeepSeek R1 Zero
Для создания DeepSeek R1 Zero, базовой модели, на основе которой был разработан R1, исследователи применили обучение с подкреплением непосредственно к базовой модели без каких-либо данных SFT. Выбранная ими парадигма обучения с подкреплением называется групповой относительной оптимизацией политики (GRPO). Этот процесс адаптирован из статьи DeepSeekMath.
GRPO похожа на известные и другие системы обучения с подкреплением, но отличается одним важным моментом: она не использует критическую модель. Вместо этого GRPO оценивает базовый уровень на основе групповых оценок. Моделирование вознаграждения имеет два правила для этой системы, каждое из которых вознаграждает точность и соответствие шаблона определенному образцу. Затем вознаграждение служит источником обучающих сигналов, которые используются для изменения направления оптимизации в процессе обучения с подкреплением. Эта система, основанная на правилах, позволяет процессу обучения с подкреплением итеративно уточнять и улучшать модель.

Сам шаблон обучения представляет собой простой письменный формат, который направляет базовую модель к выполнению указанных выше инструкций. Модель измеряет реакции на «объявление», заданное для каждого шага обучения с подкреплением. “Это значительное достижение, поскольку оно подчеркивает способность модели эффективно учиться и обобщать знания исключительно с помощью обучения с подкреплением” (источник).
Самоэволюция модели приводит к развитию у нее мощных аналитических способностей, включая самоанализ и рассмотрение альтернативных подходов. Это подкрепляется моментом во время обучения, который исследовательская группа называет “моментом озарения”. На этом этапе DeepSeek-R1-Zero учится уделять больше времени обдумыванию проблемы, переоценивая свой первоначальный подход. Такое поведение не только свидетельствует о растущих аналитических способностях модели, но и является захватывающим примером того, как обучение с подкреплением может приводить к неожиданным и сложным результатам. (Источник).
DeepSeek R1 Zero показал очень хорошие результаты во всех тестах, но значительно уступал по читаемости и удобству использования полноценным, удобным для человека LLM-моделям. Поэтому исследовательская группа предложила DeepSeek R1 для улучшения модели при решении задач, требующих человеческого подхода.
От DeepSeek R1 Zero до DeepSeek R1
Чтобы перейти от относительно неуправляемого DeepSeek R1 Zero к гораздо более функциональному DeepSeek R1, исследователи ввели несколько этапов обучения.
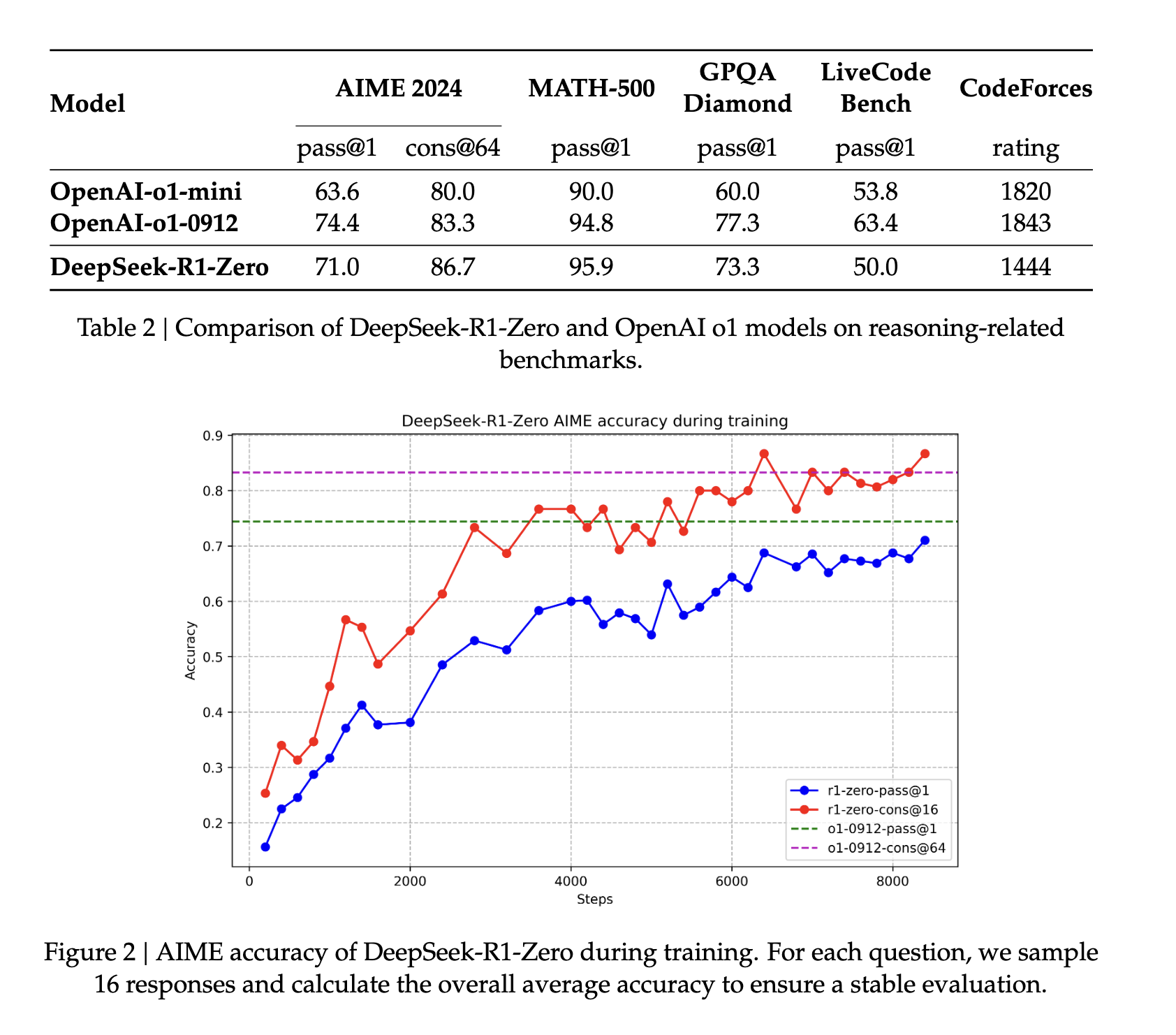
Для начала, модель DeepSeek-v3-Base была доработана на тысячах исходных данных, прежде чем была применена та же парадигма обучения с подкреплением, что и для DeepSeek R1 Zero, с дополнительным преимуществом согласованного языка в выходных данных. На практике этот шаг способствует улучшению логических способностей модели, особенно в таких задачах, как программирование, математика, естественные науки и логическое мышление, которые включают в себя четко определенные проблемы с ясными решениями (источник).
После завершения этого этапа обучения с подкреплением полученная модель используется для сбора новых данных для контролируемой тонкой настройки. «В отличие от исходных данных для холодного старта, которые в основном сосредоточены на рассуждениях, этот этап объединяет данные из других областей для расширения возможностей модели в написании текстов, ролевых играх и других задачах общего назначения» (источник).
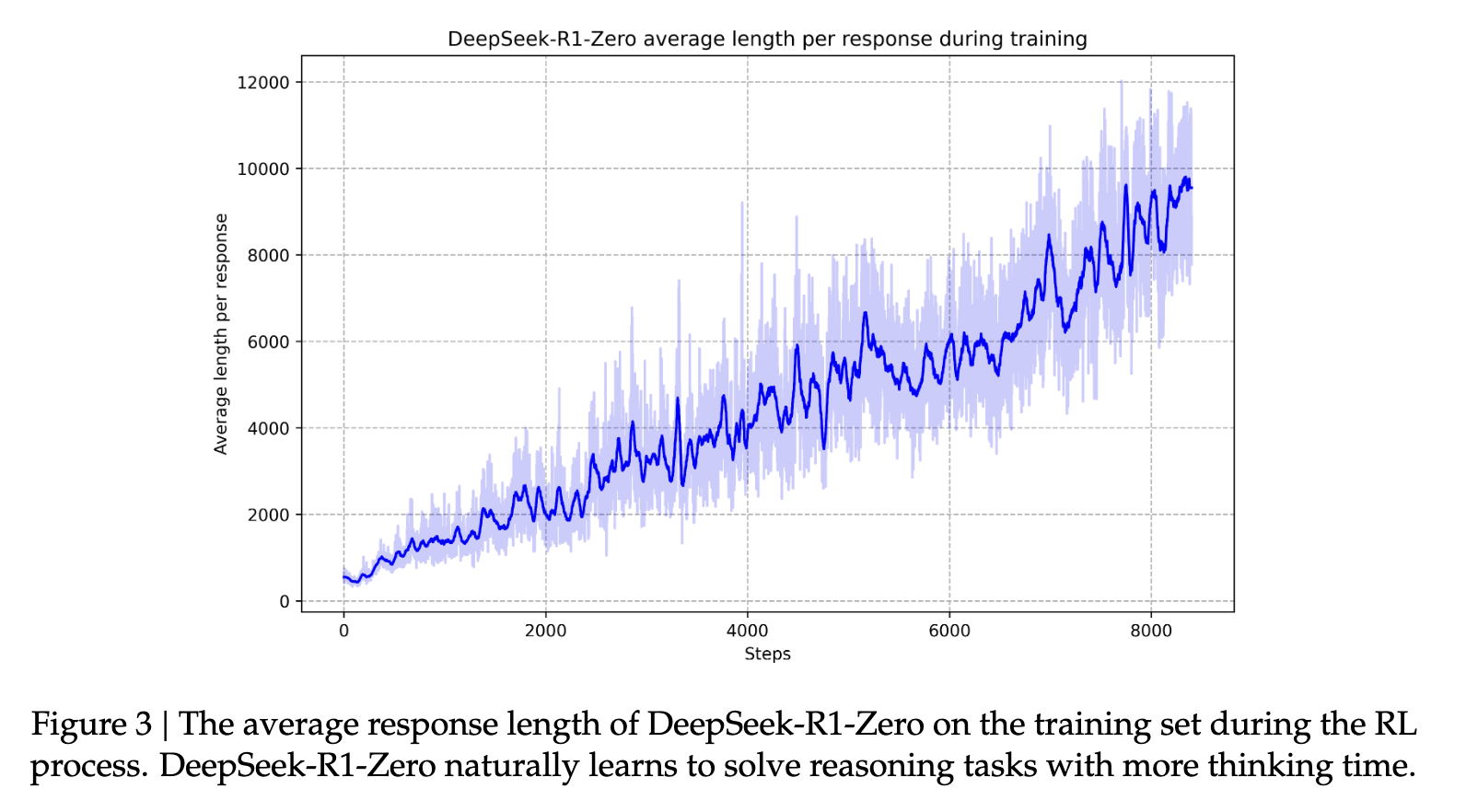
Далее, на втором этапе обучения с подкреплением (RL) повышается “полезность и безопасность модели при одновременном совершенствовании ее способностей к рассуждению” (источник). Дальнейшее обучение модели на различных быстрых распределениях с сигналами вознаграждения позволяет создать модель, которая превосходно справляется с рассуждениями, отдавая приоритет полезности и безопасности. Это помогает моделям стать “человекоподобными” в своей отзывчивости. Это способствует развитию невероятных способностей к рассуждению, которыми модель известна. Со временем этот процесс помогает модели выстраивать длинные цепочки мыслей и рассуждений, которые ее характеризуют.
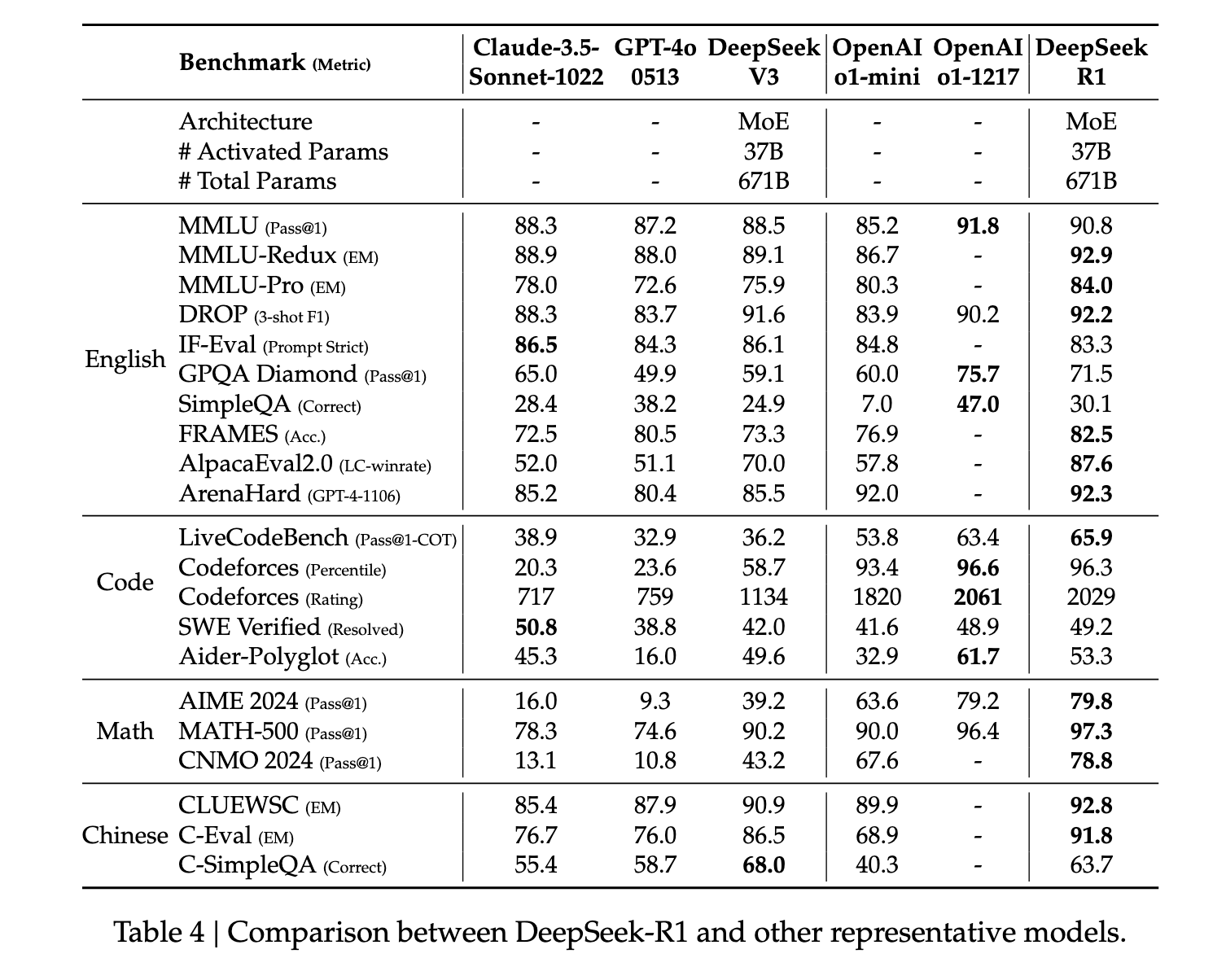
В целом, R1 демонстрирует передовые результаты по показателям логического мышления. В некоторых задачах, таких как математика, он даже превзошел опубликованные эталонные показатели для O1. В целом, также наблюдается очень высокая производительность при решении вопросов, связанных с STEM-дисциплинами, что в основном объясняется крупномасштабным обучением с подкреплением. Помимо STEM-дисциплин, модель демонстрирует высокую эффективность в ответах на вопросы, выполнении образовательных задач и сложных рассуждениях. Авторы утверждают, что эти улучшения и расширенные возможности обусловлены эволюцией моделей обработки цепочек мыслей посредством обучения с подкреплением. Длинные данные о цепочках мыслей используются во время обучения с подкреплением и тонкой настройки, чтобы побудить модель выдавать более длинные, более интроспективные результаты.
Дистиллированные модели DeepSeek R1
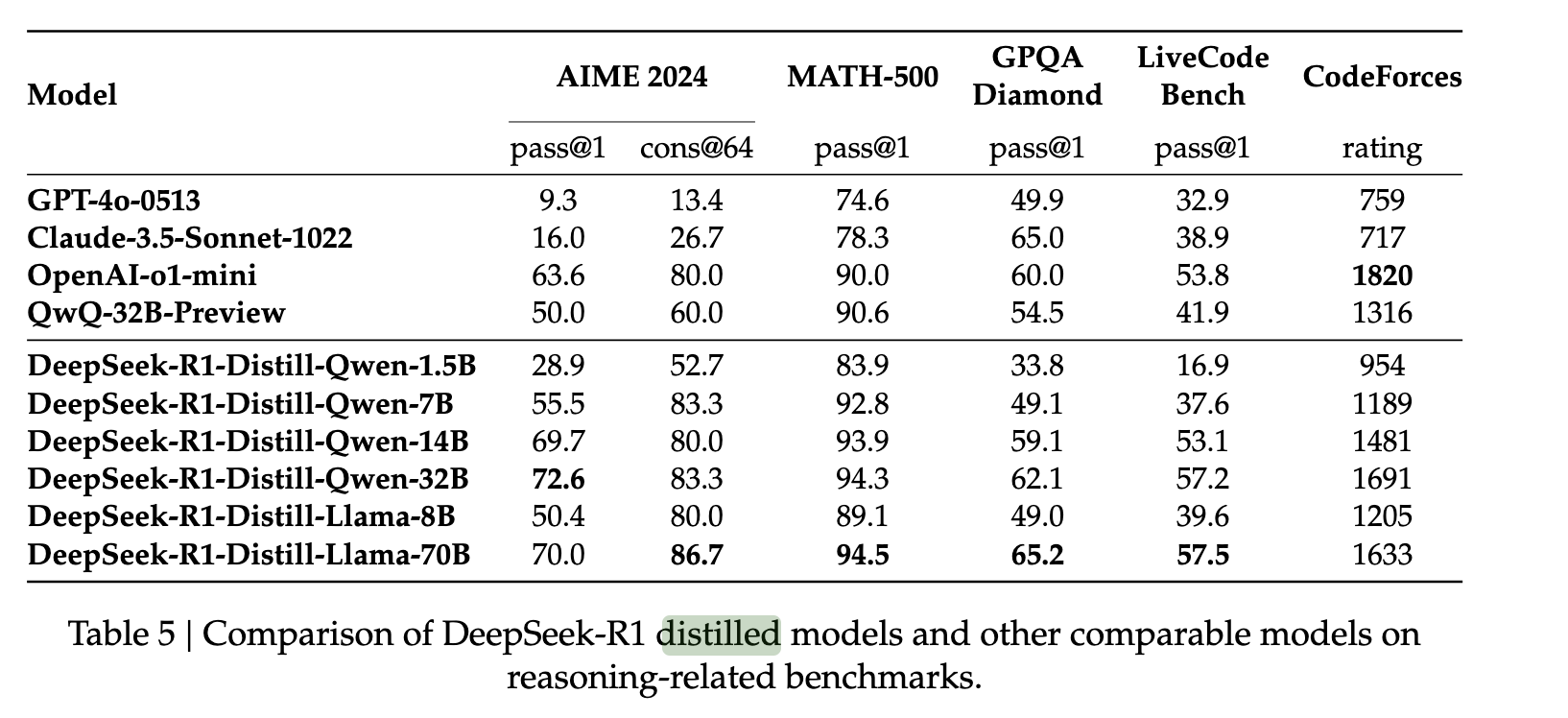 Чтобы расширить возможности DeepSeek R1 для моделей меньшего размера, авторы собрали 800 000 примеров DeepSeek R1 и использовали их для тонкой настройки таких моделей, как QWEN и LLAMA. Они обнаружили, что этот относительно простой метод дистилляции позволил с высокой степенью успеха перенести возможности рассуждений R1 на эти новые модели. Они сделали это без дополнительного обучения с подкреплением, продемонстрировав устойчивость исходных ответов модели к дистилляции.
Чтобы расширить возможности DeepSeek R1 для моделей меньшего размера, авторы собрали 800 000 примеров DeepSeek R1 и использовали их для тонкой настройки таких моделей, как QWEN и LLAMA. Они обнаружили, что этот относительно простой метод дистилляции позволил с высокой степенью успеха перенести возможности рассуждений R1 на эти новые модели. Они сделали это без дополнительного обучения с подкреплением, продемонстрировав устойчивость исходных ответов модели к дистилляции.
Запуск DeepSeek R1 на GPU Droplets
Настройка DeepSeek R1 на GPU Droplets очень проста, если у вас уже есть учетная запись DigitalOcean. Перед продолжением обязательно войдите в свою учетную запись.
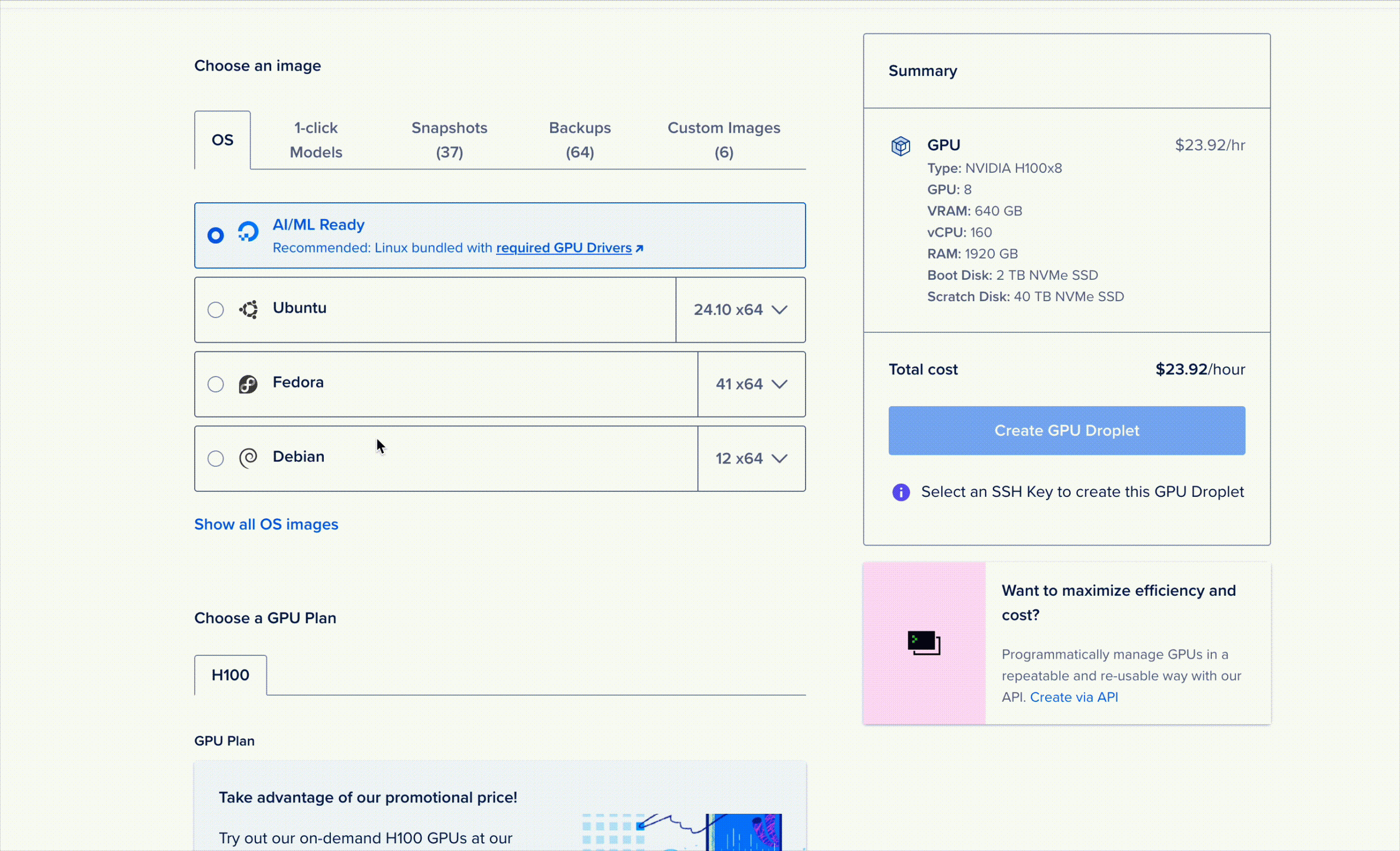
Мы предоставляем доступ к R1 в виде GPU Droplet-приложения, запускаемого в один клик. Для запуска просто откройте консоль GPU Droplet, перейдите на вкладку «Модели, запускаемые в один клик» в окне выбора модели и запустите устройство!
После этого модель станет доступна для взаимодействия с помощью методов HuggingFace или OpenAI. Используйте приведенный ниже скрипт для взаимодействия с вашей моделью с помощью кода Python.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)В качестве альтернативы мы создали собственный персональный помощник, работающий в той же системе. Мы рекомендуем использовать персонального помощника для этих задач, поскольку он абстрагирует большую часть сложности прямого взаимодействия с моделью, размещая все в удобном графическом окне. Для получения дополнительной информации об использовании скрипта персонального помощника, пожалуйста, ознакомьтесь с этим руководством.
Результат
В заключение, R1 — это шаг вперед для сообщества разработчиков LLM. Их подход обещает сэкономить миллионы долларов на затратах на обучение, обеспечивая при этом производительность, сопоставимую или даже превосходящую производительность передовых моделей с закрытым исходным кодом. Мы будем внимательно следить за DeepSeek, чтобы увидеть, как они будут развиваться по мере того, как их модель будет получать международное признание.