









導入
データを保存するだけでなく、それを理解するデータベースを想像してみてください。近年、AIアプリケーションはほぼすべての業界に革命をもたらし、コンピューティングの未来を変えました。.
ベクターデータベースは非構造化データの管理方法を変革し、関係性、類似性、コンテキストを捉えた知識の保存を可能にします。従来のデータベースは主にテーブルに格納された構造化データに依存し、完全一致を重視するのに対し、ベクターデータベースは画像、テキスト、音声などの非構造化データを、機械学習モデルが理解・比較できる形式で保存できます。.
ベクターデータベースは、完全一致に頼るのではなく、「最も近い」一致を見つけ、代替または意味的に類似した項目を効率的に検索できます。人工知能があらゆるものを動かす今日の時代において、ベクターデータベースは、大規模な言語モデルや埋め込みを生成・処理する機械学習モデルなどのアプリケーションにとって不可欠なものとなっています。.
では、埋め込みとは何でしょうか?この記事では簡単に説明します。.
推奨システム用でも、会話型 AI を強化する用でも、ベクター データベースは、新しいエキサイティングな方法でデータにアクセスし、操作することを可能にする強力なデータ ストレージ ソリューションになっています。.
それでは、最も一般的に使用されているデータベースを見てみましょう。
- SQL: 構造化されたデータを保存し、定義されたスキーマを持つテーブルを使用してデータを保存できます。最も一般的なものは、MySQL、Oracle Database、PostgreSQLです。.
- NoSQL:非常に柔軟性が高く、スキーマレスなデータベースです。非構造化データや半構造化データの処理にも優れています。多くのリアルタイムWebアプリケーションやビッグデータで活用されています。代表的なものとしてはMongoDBとCassandraが挙げられます。.
- グラフ: その後、データをノードとエッジとして保存し、相互接続されたデータを管理するために設計されたグラフが登場しました。例: Neo4j、ArangoDB。.
- Vector: 高次元ベクトルを保存およびクエリするために構築されたデータベース。AI/MLタスクの類似性検索と拡張を可能にします。最も一般的なものはPinecone、Weaviate、Chromaです。.
前提条件
- 類似度の尺度に関する知識: ベクトル データを比較するためのコサイン類似度、ユークリッド距離、ドット積などの尺度を理解します。.
- 基本的な ML および AI の概念: 機械学習モデルとアプリケーション、特に埋め込みを生成するもの (NLP、コンピューター ビジョンなど) に関する知識。.
- データベースの概念に関する知識: インデックス作成、クエリ、データ ストレージの原則を含む、データベースに関する一般的な知識。.
- プログラミングスキル: ML ライブラリやベクトル データベースで一般的に使用される Python または同様の言語に精通していること。.
なぜベクター データベースを使用するのでしょうか? また、ベクター データベースとの違いは何でしょうか?
従来のSQLデータベースにデータを保存し、各データポイントを埋め込みに変換して保存するとします。クエリを作成すると、クエリも埋め込みに変換され、コサイン類似度を用いてこのクエリ埋め込みと保存されている埋め込みを比較することで、最も関連性の高いものを見つけようとします。.
ただし、この方法はいくつかの理由で効果がない可能性があります。
- 高次元性:埋め込みは通常、高次元です。そのため、比較のたびに保存されているすべての埋め込みをフルスキャンして検索する必要があるため、クエリ時間が遅くなる可能性があります。.
- スケーラビリティの問題:数百万の埋め込み間のコサイン類似度を計算する計算コストは、大規模なデータセットでは法外な額になります。従来のSQLデータベースはこのタスクに最適化されていないため、リアルタイム検索を実現することは困難です。.
そのため、従来のデータベースでは、効率的で大規模な検索が困難になる可能性があります。さらに、日々生成される大量のデータは非構造化されており、従来のデータベースには保存できません。.

さて、この問題に対処するために、ベクターデータベースを使用します。ベクターデータベースには、高次元データの効率的な類似検索を可能にするインデックスという概念があります。ベクトル埋め込みを整理することで、クエリの高速化に重要な役割を果たし、大規模なデータセットであっても、クエリベクトルに類似するベクトルをデータベースが迅速に取得できるようにします。ベクターインデックスは検索空間を縮小し、数百万、数十億のベクトルへのスケーリングを可能にします。これにより、大規模なデータセットであっても、高速なクエリ応答が可能になります。.
従来のデータベースでは、クエリに一致する行を検索します。ベクターデータベースでは、類似度指標を使用して、クエリに最も類似するベクターを見つけます。.
ベクターデータベースは、ハッシュ、量子化、グラフベースの手法を用いて検索を最適化する近似最近傍探索(ANN)アルゴリズムを組み合わせて使用します。これらのアルゴリズムはパイプライン内で連携し、高速かつ正確な結果を提供します。ベクターデータベースは近似マッチングを提供するため、精度と速度の間にはトレードオフがあり、精度を高くするとクエリの速度が低下する可能性があります。.
ベクトル表現の基礎
ベクトルとは何ですか?
ベクトルは、データベースに格納された数値の配列と考えることができます。画像、テキスト、PDFファイル、音声など、あらゆる種類のデータを数値に変換し、ベクトルデータベースに配列として格納できます。このデータの数値表現により、類似検索と呼ばれる機能が可能になります。.
ベクトルを理解する前に、セマンティック検索と埋め込みを理解してみましょう。.
セマンティック検索とは何ですか?
セマンティック検索は、正確なフレーズ一致ではなく、単語の意味と文脈を検索する方法です。セマンティック検索はキーワードに焦点を当てるのではなく、意味を理解しようとします。例えば、「python」という単語の場合、従来の検索では「python」という単語は単語そのものしか認識しないため、「Pythonプログラミング」と「Pythonヘビ」の両方の検索結果を返す可能性があります。セマンティック検索では、エンジンは文脈を探します。最近の検索が「コーディング言語」や「機械学習」に関するものであれば、おそらくPythonプログラミングに関する結果が表示されるでしょう。しかし、「奇妙な動物」や「爬虫類」に関する検索であれば、pythonはヘビであると想定し、それに応じて結果を調整します。.

セマンティック検索はコンテキストを識別することで、実際の意図に基づいて最も関連性の高い情報を表示するのに役立ちます。.
埋め込みとは何ですか?
埋め込みは、単語を数値ベクトルとして表現する方法です (ここでは、ベクトルを数値のリストとして考えます。たとえば、「cat」という単語は [.1,.8,.75,.85] になる可能性があります)。高次元空間では、コンピューターは単語のこの数値表現をすばやく処理します。.
単語にはそれぞれ異なる意味と関係性があります。例えば、単語埋め込みにおいて、「king」と「queen」は、「king」と「car」と同様のベクトルを持ちます。.
埋め込みは、文中での単語の使用に基づいて文脈を捉えることができます。例えば、「bank」は金融機関を意味する場合もあれば、川岸を意味する場合もありますが、埋め込みは周囲の単語に基づいてこれらの意味を認識するのに役立ちます。埋め込みは、コンピューターが単語、意味、そして関係性を理解するためのよりスマートな方法です。.
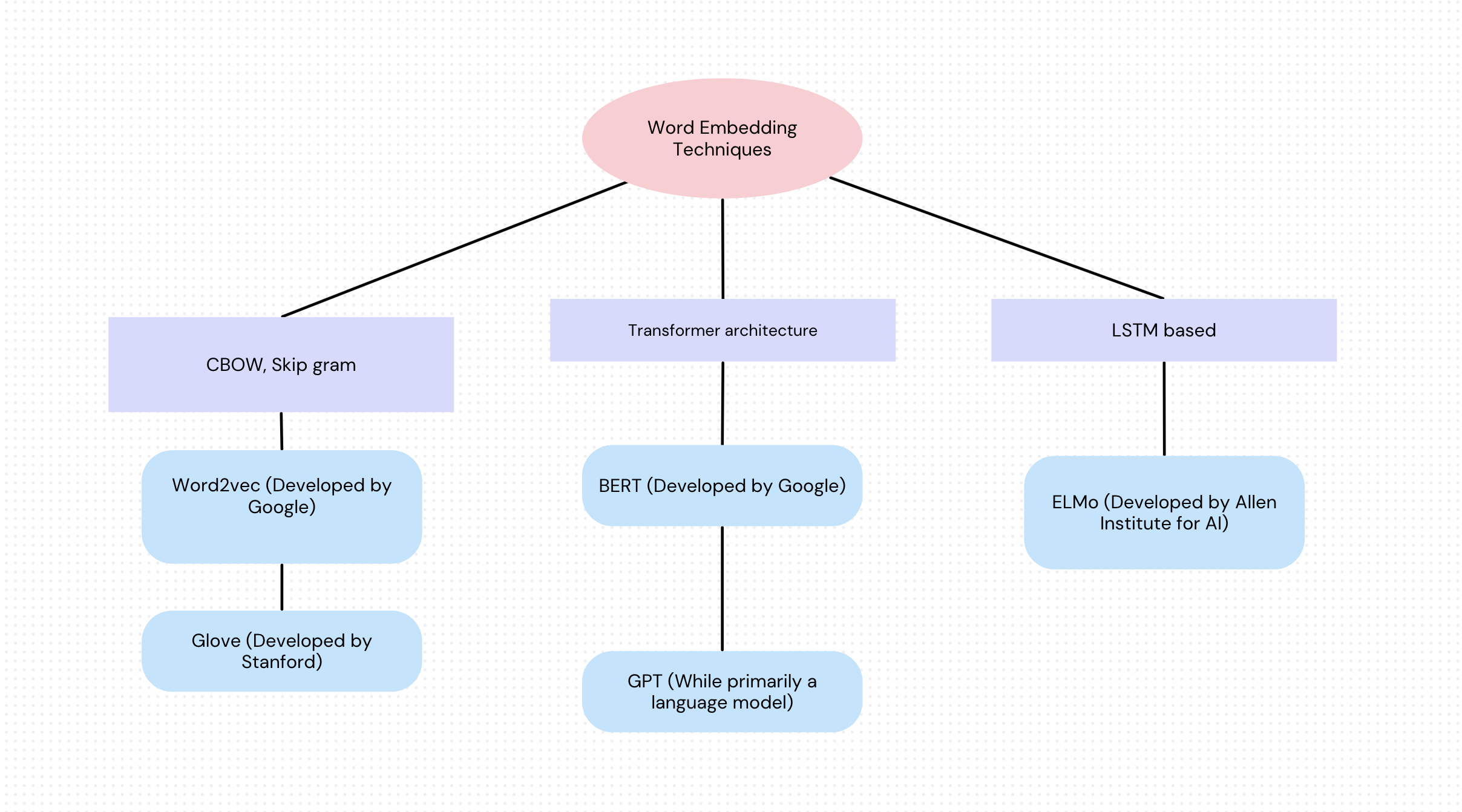
埋め込みを考える一つの方法は、単語の様々な特徴や特性をマッピングし、それぞれの特徴に値を割り当てることです。これにより数値の列が得られ、これはベクトルと呼ばれます。このような単語埋め込みを作成するには、様々な手法が使用できます。したがって、ベクトル埋め込みとは、単語からなる文や文書を数値で表し、意味や関係性を表す方法です。ベクトル埋め込みにより、これらの単語は、類似した単語が互いに近接する空間上の点として表すことができます。.
これらのベクトル埋め込みにより、加算や減算といった数学演算が可能になり、関係性を捉えることができます。例えば、「王 - 男 + 女」というよく知られたベクトル演算は、「女王」に近いベクトルを生成することができます。.
ベクトル空間における類似性基準
さて、各ベクトルの類似度を測定するために、類似度または非類似度を定量化する数学的ツールが用いられます。以下にその一部を挙げます。
- コサイン類似度: コサインは、2 つのベクトル間の角度を -1 から 1 までの範囲で測定します。-1 は正反対、1 は同一のベクトル、0 は直交または非類似を意味します。.
- ユークリッド距離:ベクトル空間における2点間の直線距離を測定します。値が小さいほど類似度が高いことを示します。.
- マンハッタン距離 (L1 標準): 対応するコンポーネントの絶対差を合計して 2 点間の距離を測定します。.
- ミンコフスキー距離: ユークリッド距離とマンハッタン距離の一般化。.
これらは、機械学習アルゴリズムで使用される最も一般的な距離または類似性のメトリックです。.
人気のベクターデータベース
以下は、現在広く使用されている最も人気のあるベクター データベースの一部です。
- Pinecone: 使いやすさ、スケーラビリティ、高速な近似最近傍探索(ANN)で知られる、フルマネージドベクターデータベースです。Pineconeは、機械学習ワークフロー、特にセマンティック検索やレコメンデーションシステムとの統合性で知られています。.
- FAISS(Facebook AI 類似度検索):Meta(旧Facebook)によって開発されたFAISSは、密ベクトルの類似度検索とクラスタリングのために高度に最適化されたライブラリです。オープンソースで効率的であり、学術研究や産業界の研究、特に大規模な類似度検索で広く利用されています。.
- Weaviate: ベクター検索とハイブリッド検索機能をサポートするオープンソースのクラウドネイティブベクターデータベースです。Weaviateは、Hugging Face、OpenAI、Cohereなどのモデルとの統合で知られており、セマンティック検索やNLPアプリケーションにとって強力な選択肢となっています。.
- Milvus: 大規模AIアプリケーション向けに最適化された、オープンソースで拡張性に優れたベクターデータベースです。Milvusは様々なインデックス作成方法をサポートし、幅広い統合エコシステムを備えているため、リアルタイムレコメンデーションシステムやコンピュータービジョンタスクで広く利用されています。.
- Qdrant:ユーザーフレンドリーさを重視した高性能ベクターデータベースであるQdrantは、リアルタイムインデックス作成や分散サポートなどの機能を備えています。高次元データを処理できるように設計されており、レコメンデーションエンジン、パーソナライゼーション、NLPタスクに適しています。.
- Chroma: オープンソースでLLMアプリケーション向けに特別に設計されたChromaは、LLM用の埋め込みストアを提供し、類似検索をサポートします。会話型AIやその他のLLMベースのアプリケーションでは、LangChainと組み合わせて使用されることがよくあります。.
使用すべきもの
それでは、ベクター データベースの使用例をいくつか見てみましょう。.
- ベクターデータベースは、長期記憶を必要とする会話エージェントに利用できます。Langchainを使えば簡単に実装でき、会話エージェントはベクターデータベースに会話履歴を照会・保存できます。ユーザーとのやり取りに応じて、ボットは過去の会話から文脈的に関連性の高いスニペットを抽出し、ユーザーエクスペリエンスを向上させます。.
- ベクターデータベースは、意味的に類似した文書やテキストを検索することで、セマンティック検索や情報検索に使用できます。キーワードの正確な一致ではなく、クエリにテキスト的に関連するコンテンツを検索します。.
- eコマース、音楽ストリーミング、ソーシャルメディアなどのプラットフォームは、ベクターデータベースを用いてレコメンデーションを生成します。ユーザーのアイテムや好みをベクターとして表現することで、システムはユーザーの過去の興味に類似した商品、曲、コンテンツを見つけることができるのです。.
- 画像およびビデオ プラットフォームは、ベクター データベースを使用して視覚的に類似したコンテンツを見つけます。.
ベクターデータベースの課題
- スケーラビリティとパフォーマンス:データ量が増加し続けるにつれ、ベクターデータベースの精度を維持しながら、高速性とスケーラビリティを維持することが課題となる可能性があります。また、正確な検索結果を生成する際にも、速度と精度のバランスを取ることが課題となる可能性があります。.
- コストとリソースの集約性: 高次元ベクトル演算はリソースを大量に消費する可能性があり、強力なハードウェアと効率的なインデックス作成が必要になるため、ストレージと計算のコストが増加する可能性があります。.
- 精度と近似のトレードオフ: ベクター データベースは最近傍法 (ANN) 技術を使用してより高速な検索を実現しますが、正確な一致ではなく近似一致になる可能性があります。.
- 従来のシステムとの統合: ベクター データベースを既存の従来のデータベースと統合することは、異なるデータ構造と取得方法を使用するため、困難な場合があります。.
結果
ベクターデータベースは、高次元空間における類似性に基づく検索を可能にすることで、画像、音声、テキスト、レコメンデーションといった複雑なデータの保存と検索方法を変革します。完全一致を必要とする従来のデータベースとは異なり、ベクターデータベースは埋め込みと類似性スコアを用いて「十分に近い」結果を見つけるため、パーソナライズされたレコメンデーション、セマンティック検索、異常検出といったアプリケーションに最適です。.









