









導入
DeepSeek R1はここ数週間、AI/MLコミュニティを席巻しており、当然のことながら、コミュニティを超えてより広い世界へと広がり、経済と政策に大きな影響を与えています。これは主に、モデルスイートのオープンソース性と、トレーニングの信じられないほど低い価格によるものです。これにより、SOTA AIモデルのトレーニングには、以前考えられていたほど多くの資本や専用の研究は必要ないことが、より広範なコミュニティに示されました。.
このシリーズの第1部では、DeepSeek R1を紹介し、Olamaを使ってモデルを実行する方法を示しました。今回の続編では、R1の真の特徴をより深く掘り下げていきます。まず、R1独自の強化学習(RL)パラダイムを分析し、LLMの推論能力をRLのみでどのように強化できるかを探ります。次に、これらの手法を他のモデルに応用することで、既存のバージョンと機能を共有する方法について説明します。最後に、GPU Dropletsの1クリックモデルを使用して、DeepSeek R1モデルをGPU Dropletsでセットアップし、実行する方法を簡単に説明します。.
前提条件
- ディープラーニング: この記事では、ニューラル ネットワークのトレーニングと強化学習に関連する中級から上級のトピックについて説明します。.
- DigitalOceanアカウント: R1 のテストには、DigitalOcean の HuggingFace 1-Click Model GPU Droplets を具体的に使用します。.
DeepSeek R1の概要
DeepSeek R1研究プロジェクトは、強力な推論モデル、すなわちOpenAIのO1が示す効果的な推論能力を再現することを目指しました。この目標を達成するために、彼らは既存のDeepSeek-v3-Baseを純粋強化学習を用いて改良しようと試みました。その結果、DeepSeek R1 Zeroが誕生しました。このモデルは推論指標において優れた性能を示すものの、人間の解釈能力を欠き、言語混合などの異常な動作を示すという欠点があります。.
これらの問題を改善するため、彼らは少量のコールドスタートデータと多段階の学習パイプラインを備えたDeepSeek R1を提案しました。R1は、数千のコールドスタートデータサンプルを用いてDeepSeek-v3-Baseモデルをファインチューニングし、さらに強化学習を実行した後、引数データセットを用いて教師ありファインチューニングを行い、最後に強化学習を行うことで、SOTA LLMの可読性と適用性を実現しました。そして、R1から収集したデータを用いてファインチューニングを教師ありで実行することで、この手法を他のモデルにも応用しました。.
これらの開発段階の詳細と、DeepSeek R1 の機能を実現するためにモデルを反復的に改善する方法についての説明を引き続きお楽しみください。.
DeepSeek R1 Zero チュートリアル
R1の開発元であるDeepSeek R1 Zeroを作成するために、研究者たちはSFTデータを用いずに強化学習をベースモデルに直接適用しました。彼らが選択した強化学習パラダイムは、グループ相対方策最適化(GRPO)と呼ばれます。このプロセスはDeepSeekMathの論文から改変したものです。.
GRPOは、よく知られている強化学習システムや他のシステムと類似していますが、重要な点が1つあります。それは、批判的モデルを使用しないことです。GRPOは、グループスコアからベースラインを推定します。報酬モデリングには、このシステム用の2つのルールがあり、それぞれがテンプレートの精度とパターンへの適合性に報酬を与えます。この報酬は、強化学習の最適化の方向を変えるために用いられるトレーニング信号のソースとして機能します。このルールベースのシステムにより、強化学習プロセスはモデルを反復的に改良・改善することができます。.

トレーニングテンプレート自体は、ベースモデルが上記のように指定された指示に従うようにガイドするシンプルな記述形式です。モデルは、強化学習の各ステップで設定された「アナウンス」に対する反応を測定します。「これは重要な成果であり、強化学習のみでモデルが効果的に学習および一般化できる能力を浮き彫りにしています」(出典)。.
このモデルの自己進化により、自己反省や代替アプローチの検討など、強力な推論能力が発達します。これは、モデルの研究チームが「アハ体験」と呼ぶ、トレーニング中の瞬間によって強化されます。この段階で、DeepSeek-R1-Zeroは初期のアプローチを再評価することで、問題により多くの思考時間を費やすことを学習します。この行動は、モデルの推論能力の成長を証明するだけでなく、強化学習が予期せぬ複雑な結果をもたらす可能性があることを示す魅力的な例でもあります。(出典).
DeepSeek R1 Zeroはベンチマーク全体で非常に優れたパフォーマンスを発揮しましたが、人間に優しい本格的なLLMと比較すると、可読性と使いやすさの面で大きく劣っていました。そこで研究チームは、人間レベルのタスク向けにモデルをさらに改良するために、DeepSeek R1を提案しました。.
DeepSeek R1 ZeroからDeepSeek R1へ
比較的扱いにくい DeepSeek R1 Zero から、はるかに機能的な DeepSeek R1 に移行するために、研究者は複数のトレーニング段階を導入しました。.
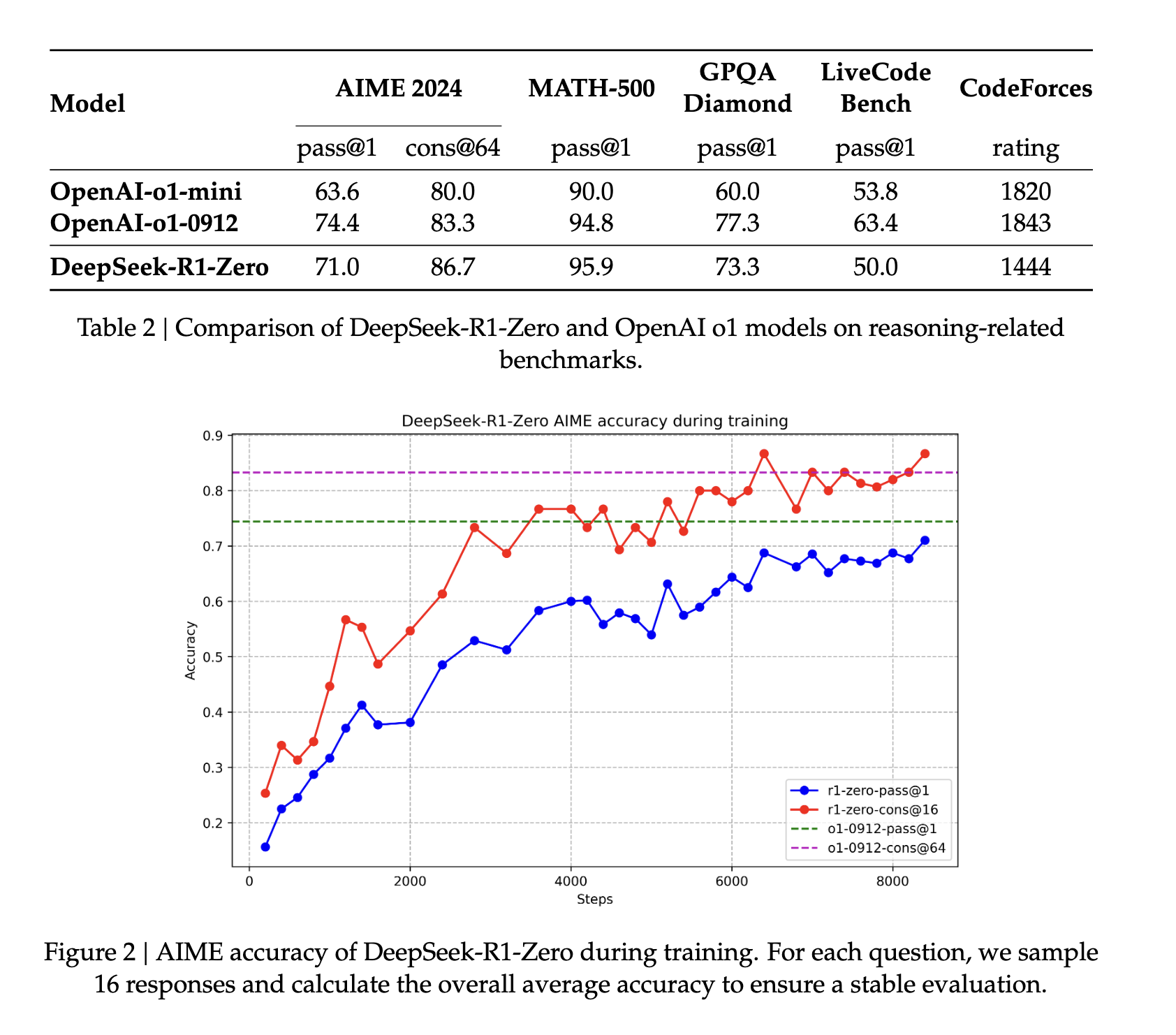
まず、DeepSeek-v3-Baseは数千のコールドスタートデータで微調整された後、DeepSeek R1 Zeroで使用されたのと同じ強化学習パラダイムを実行し、出力に一貫性のある言語が付加されました。実際には、このステップはモデルの推論能力を向上させる効果があり、特にコーディング、数学、科学、論理的推論といった、明確に定義された問題と明確な解決策を伴う推論タスクにおいて効果を発揮します(出典)。.
この強化学習フェーズが完了すると、得られたモデルは教師あり学習のための微調整のための新しいデータ収集に使用されます。「主に推論に焦点を当てた初期のコールドスタートデータとは異なり、このフェーズでは他のドメインのデータも組み合わせて、ライティング、ロールプレイング、その他の汎用タスクにおけるモデルの能力を強化します」(出典)。.
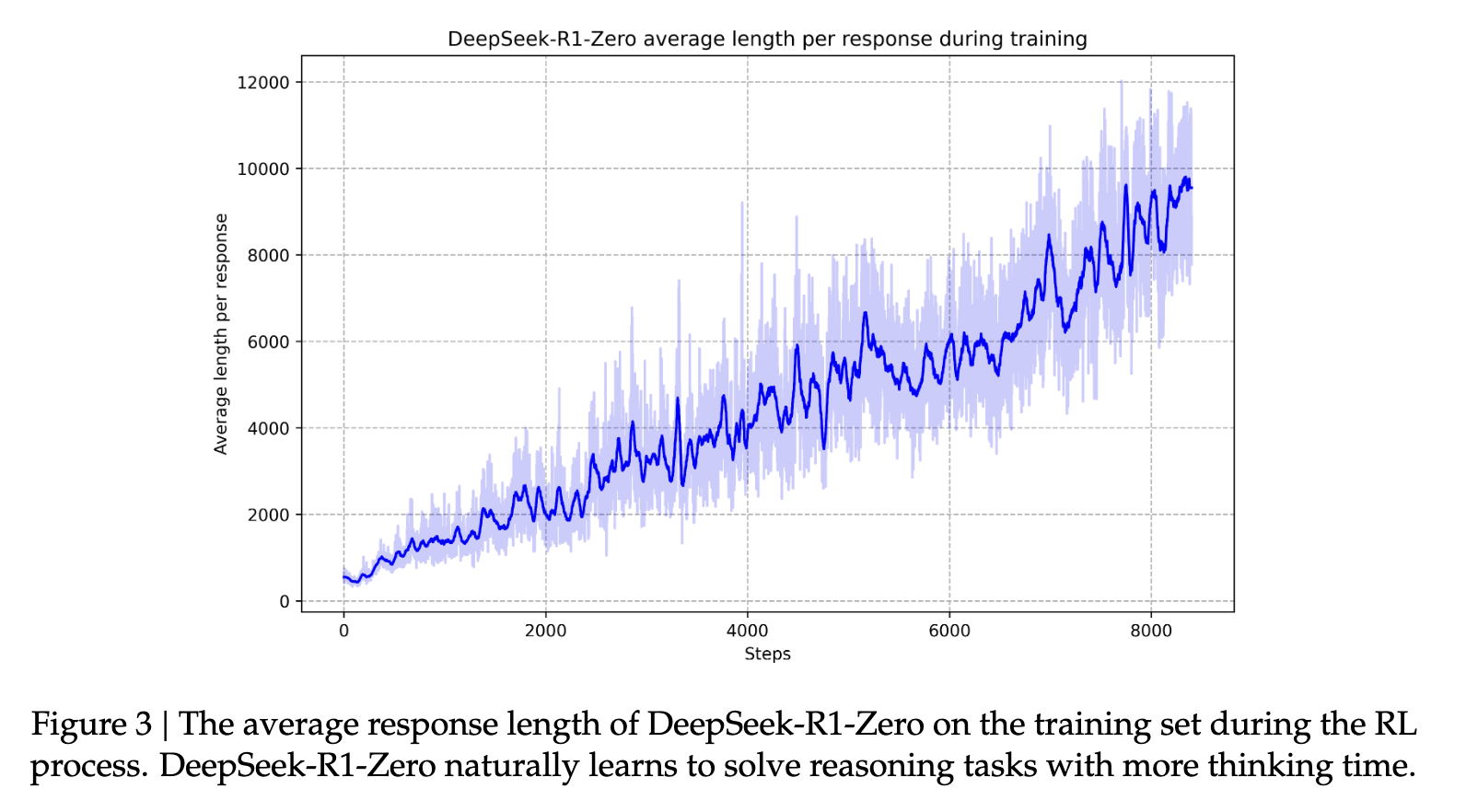
次に、強化学習の第2段階が実装され、「モデルの有用性と無害性を向上させると同時に、推論能力を洗練させる」ことを目指します(出典)。報酬信号を用いて様々な高速分布でモデルをさらに訓練することで、有用性と無害性を優先しながら推論能力に優れたモデルを訓練できます。これにより、モデルの応答性は「人間のような」ものになります。これは、モデルが誇る驚異的な推論能力を進化させるのに役立ちます。このプロセスは、時間の経過とともに、モデルが自身の特徴である思考と推論の長い連鎖を発達させるのに役立ちます。.
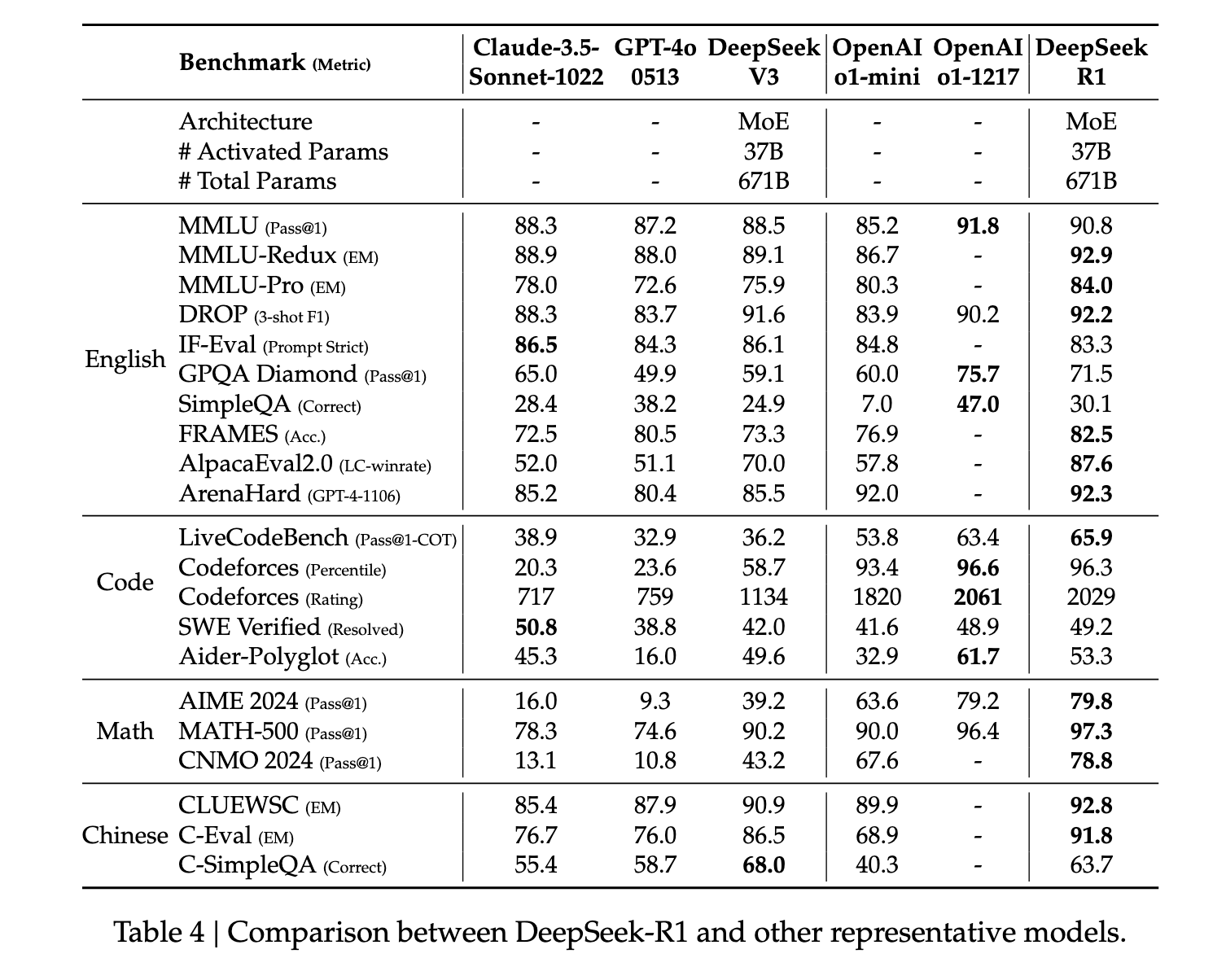
R1は推論能力において全般的に最先端のパフォーマンスを示しています。数学などの一部のタスクでは、O1の公開ベンチマークを上回るパフォーマンスを示すことさえ示されています。また、STEM関連の質問においても非常に優れたパフォーマンスを示しており、これは主に大規模な強化学習によるものです。STEM科目に加えて、このモデルは質問への回答、教育課題、複雑な推論においても高いスキルを発揮します。著者らは、これらの改善と能力向上は、強化学習による思考連鎖処理モデルの進化によるものだと主張しています。強化学習とファインチューニングにおいては、長い思考連鎖データを使用することで、モデルがより長く、より内省的な出力を生成するように促します。.
DeepSeek R1 蒸留モデル
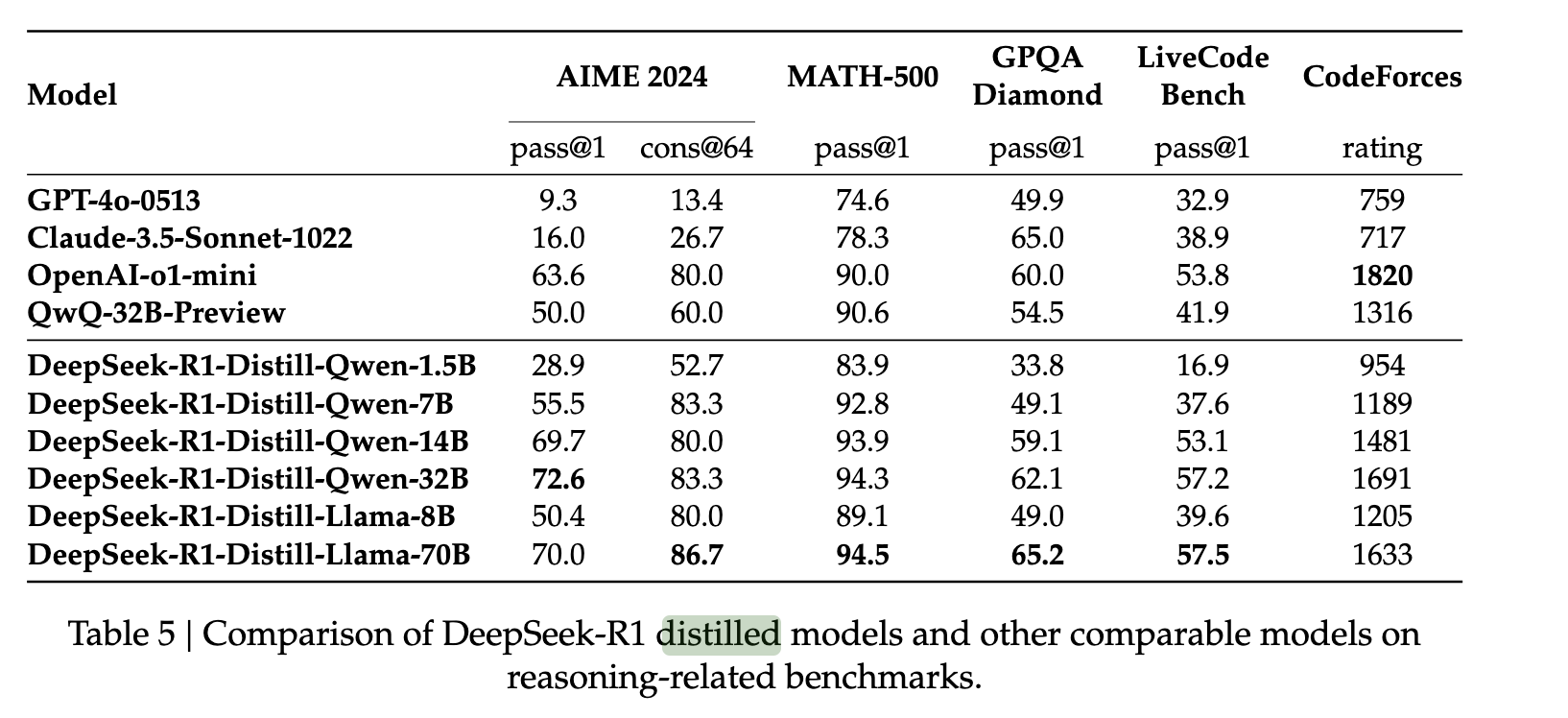 DeepSeek R1の機能をより小規模なモデルに拡張するため、著者らは80万件のDeepSeek R1のサンプルを収集し、それらを用いてQWENやLLAMAなどのモデルを微調整しました。この比較的単純な蒸留手法を用いることで、R1の推論機能をこれらの新しいモデルに高い確率で移植できることが分かりました。著者らは追加の強化学習を一切行わずにこれを実現し、元のモデルがモデル蒸留に対して堅牢に応答することを実証しました。.
DeepSeek R1の機能をより小規模なモデルに拡張するため、著者らは80万件のDeepSeek R1のサンプルを収集し、それらを用いてQWENやLLAMAなどのモデルを微調整しました。この比較的単純な蒸留手法を用いることで、R1の推論機能をこれらの新しいモデルに高い確率で移植できることが分かりました。著者らは追加の強化学習を一切行わずにこれを実現し、元のモデルがモデル蒸留に対して堅牢に応答することを実証しました。.
GPU DropletsでDeepSeek R1を起動
DigitalOceanアカウントをお持ちの場合、GPU DropletsでのDeepSeek R1の設定は非常に簡単です。続行する前に必ずログインしてください。.
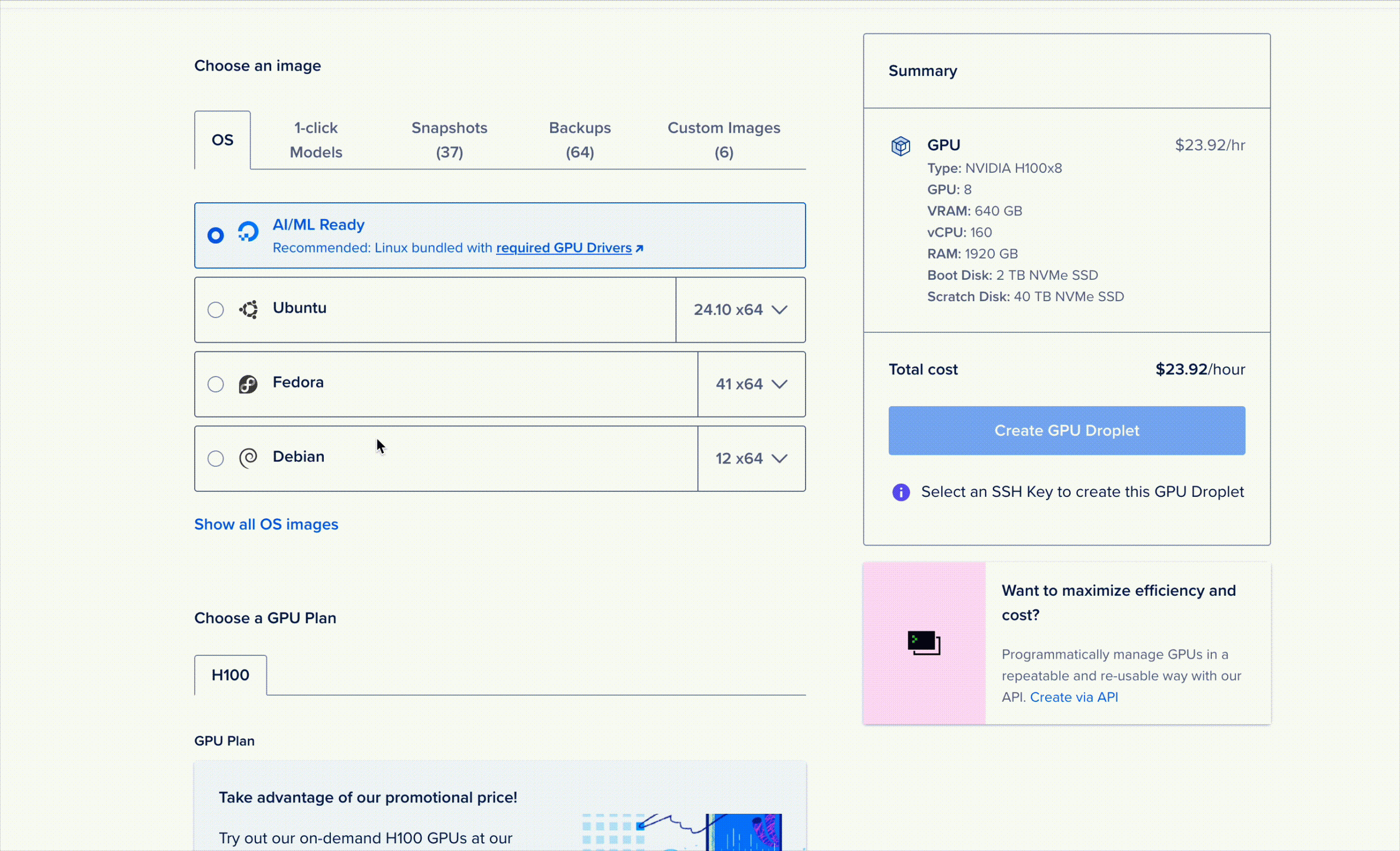
R1へのアクセスは、1-Click Model GPU Dropletとして提供されています。起動するには、GPU Dropletコンソールを開き、モデル選択ウィンドウの「1-Click Models」タブに移動してデバイスを起動するだけです。
そこから、HuggingFaceまたはOpenAIのメソッドに従ってモデルと通信することで、モデルにアクセスできるようになります。以下のスクリプトを使用して、Pythonコードでモデルを操作してください。.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)あるいは、同じシステム上で動作するカスタムパーソナルアシスタントも作成しました。これらのタスクにはパーソナルアシスタントの使用をお勧めします。パーソナルアシスタントは、すべての操作を分かりやすいGUIウィンドウにまとめることで、モデルとの直接的なインタラクションに伴う多くの複雑さを抽象化します。パーソナルアシスタントスクリプトの使い方の詳細については、こちらのチュートリアルをご覧ください。.
結果
結論として、R1はLLM開発コミュニティにとって大きな前進です。このプロセスは、高度なクローズドソースモデルと同等、あるいはそれ以上の性能を実現しながら、数百万ドルのトレーニングコストを削減することを約束しています。DeepSeekのモデルが国際的な認知度を高めるにつれ、彼らがどのように成長していくのか、今後も注目していきたいと思います。.









