









導入
Pythonは今日最も人気のあるプログラミング言語の一つかもしれませんが、最も効率的とは言えません。特に機械学習の世界では、ユーザーはPythonが提供する使いやすさのために効率性を犠牲にしています。.
しかし、だからといって他の方法でスピードアップできないわけではありません。Cythonは、Pythonで簡単に実現できる機能を犠牲にすることなく、Pythonスクリプトの計算時間を短縮する簡単な方法です。.
このチュートリアルでは、Cython を使って Python スクリプトを高速化する方法を紹介します。ここでは、単純ながらも計算コストの高いタスク、つまり 10 億個の数値からなる Python リストを反復処理して合計を計算する for ループの作成に取り組みます。リソースが限られたデバイスでコードを実行する場合、時間は非常に重要です。そこで、Raspberry Pi (RPi) 上の Cython で Python コードを実装する方法を検討することで、この問題を探求します。Cython は、lazy と yozo の違いのように、計算速度に大きな違いをもたらします。.
Cython で Python スクリプトを最適化するための前提条件
- Python の基礎知識: Python の構文、関数、データ型、モジュールに関する知識。.
- 基本的な C/C++ の概念を理解する: ポインター、データ型、制御構造などの基本的な C または C++ の概念に精通していること。.
- Python 開発環境: pip などのパッケージ マネージャーを使用して Python (Python 3.x が望ましい) をインストールします。.
- Cython をインストールします。pip install cython コマンドを使用して Cython をインストールします。.
- ターミナル/コマンド ラインの知識: ターミナルまたはコマンド ラインでコマンドを操作および実行するための基本的な能力。.
これらの前提条件は、Cython を使用して Python コードの最適化を開始する準備に役立ちます。.

PythonとCPython
Pythonのような言語が実際には他の言語で実装されているという事実に気づいていない人は多くいます。例えば、PythonのC言語実装はCPythonとして知られています。これはCythonとは異なることに注意してください。Pythonの様々な実装について詳しくは、こちらの記事をご覧ください。.
Pythonのデフォルト実装であり、最も普及しているのはC-Pythonです。C-Pythonを使うことには重要な利点が一つあります。Cはコンパイル言語であり、そのコードは機械語に変換され、中央処理装置(CPU)によって直接実行されます。では、Cがコンパイル言語であるなら、Pythonも同じなのでしょうか?と疑問に思うかもしれません。
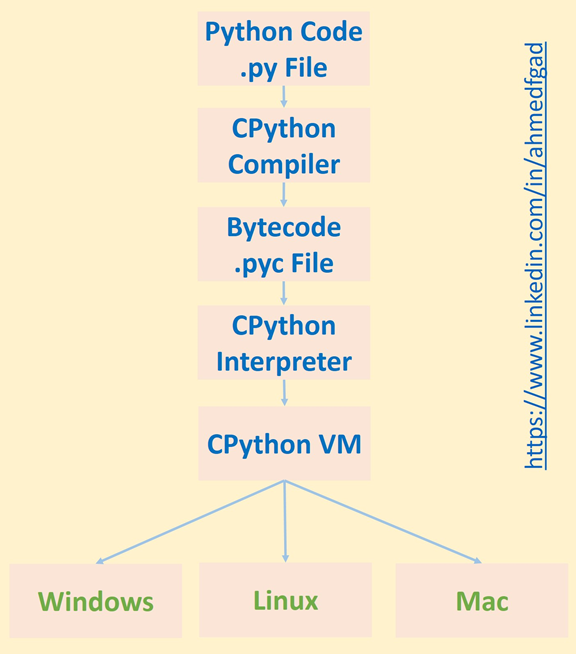
C言語によるPython実装(Cpython)100%はコンパイルも解釈もされません。実際、Pythonスクリプトの実行プロセスでは、コンパイルと解釈の両方が行われます。これを明確化するために、Pythonスクリプトの実行手順を見てみましょう。
- CPythonを使用してソースコードをコンパイルし、バイトコードを生成する
- CPythonインタープリタによるバイトコード解釈
- CPython仮想マシンでCPythonインタープリタの出力を実行する
コンパイルプロセスは、Cpythonがソースコード(.pyファイル)をコンパイルし、Cpythonバイトコード(.pycファイル)を生成するときに発生します。CpythonバイトコードはCpythonインタプリタによって解釈され、出力はCpython仮想マシンで実行されます。上記の手順で示したように、Pythonスクリプトの実行プロセスにはコンパイルと解釈の両方が含まれます。.
Cpythonコンパイラはバイトコードを一度だけ生成しますが、コードが実行されるたびにインタープリタが呼び出されます。バイトコードの解釈には通常、長い時間がかかります。インタープリタを使用すると実行速度が低下するのであれば、そもそもインタープリタを使用する意味はありません。主な理由は、インタープリタを使用することでPythonを異なるオペレーティングシステムで使用できるようになるからです。バイトコードはCPU上で実行されるCpython仮想マシン内でマシンとは独立して実行されるため、変更を加えることなく異なるマシンで実行できます。.
インタプリタを使用しない場合、CpythonコンパイラはCPU上で直接実行されるマシンコードを生成します。プラットフォームによって命令が異なるため、コードは異なるプラットフォームでは実行できません。.
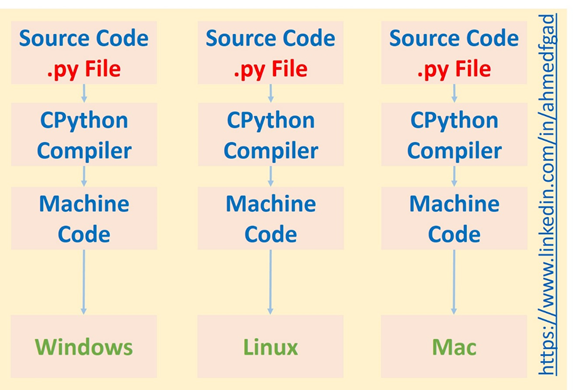
簡単に言うと、コンパイラを使うと処理は速くなりますが、インタープリタを使うとコードはクロスプラットフォームになります。つまり、PythonがC言語よりも遅い理由の一つは、インタープリタの使用にあります。コンパイラは一度しか実行されませんが、インタープリタはコードが実行されるたびに実行されることを覚えておいてください。.
PythonはC言語よりもはるかに遅いですが、多くのプログラマーは使いやすさからPythonを好んで使用しています。Pythonは多くの詳細をプログラマーから隠蔽するため、面倒なデバッグ作業を軽減できます。例えば、Pythonは動的型付け言語であるため、コード内のすべての変数の型を指定する必要はありません。Pythonが自動的に型を推測します。一方、静的型付け言語(C、C++、Javaなど)では、以下に示すように、変数の型を指定する必要があります。.
int x = 10
string s = "Hello"Python での次の実装と比較してください。
動的型付けはコーディングを容易にしますが、適切なデータ型を見つけるためにマシンに負担をかけます。これにより、実行プロセスが遅くなります。.
x = 10
s = "Hello"一般的に、Pythonのような「高水準」言語は開発者にとって理解しやすいものです。しかし、コードを実行する際には、低水準命令に変換する必要があります。この変換には時間がかかり、使いやすさを優先するためにその時間が犠牲になっています。.
時間が問題になる場合は、低レベルコマンドを使用することをお勧めします。つまり、フロントエンドであるPythonでコードを書く代わりに、CPython(裏ではPythonをC言語で実装したプログラム)を使ってコードを記述できます。ただし、これを行うと、PythonではなくC言語でプログラミングしているような感覚になります。.
CPythonははるかに複雑です。CPythonではすべてがCで実装されているため、コーディング時にCの複雑さから逃れる方法はありません。そのため、多くの開発者は代わりにCythonを使用しています。しかし、CythonはCPythonとどう違うのでしょうか?
Cython との違いは何ですか?
上で定義したように、Cythonはスピードと使いやすさという両方の長所を兼ね備えた言語です。Pythonで通常のコードを書くこともできますが、実行時間を短縮するために、CythonではPythonコードの一部をC言語に置き換えることができます。つまり、両方の言語を1つのファイルに統合することになります。PythonのすべてがCythonでも有効であると考えるのは当然ですが、いくつかの制限があることに注意してください。.
通常の Python ファイルの拡張子は .py ですが、Cython ファイルの拡張子は .pyx です。.pyx ファイル内にも同じ Python コードを記述できますが、これらのファイルでは Cython コードも使用できます。Python コードを .pyx ファイルに格納すると、Python コードを直接実行するよりも処理速度が速くなる場合がありますが、変数の型を宣言するほど高速ではありません。そのため、このチュートリアルでは、.pyx ファイル内に Python コードを記述するだけでなく、実行速度を向上させるための変更を加えることに重点を置いています。これによりプログラミングが少し複雑になりますが、多くの時間を節約できます。C プログラミングの経験があれば、この手順はより簡単に理解できるでしょう。.
シンプルなPythonコードのCitron化
Python コードを Cython に変換するには、まず拡張子 . .pyx 拡張ではなく作成 .py. このファイル内で、通常の Python コードの記述を開始できます (Cython が受け入れるコードにはいくつかの制限があり、これについては Cython のドキュメントで説明されていることに注意してください)。.
先に進む前に、Cythonがインストールされていることを確認してください。次のコマンドで確認できます。.
pip install cython
.pyd/.so ファイルを生成するには、まず Cython ファイルをビルドする必要があります。.pyd/.so ファイルは、後でインポートするモジュールを表します。Cython ファイルのビルドには setup.py ファイルを使用します。このファイルを作成し、以下のコードを記述します。distutils.core.setup() 関数を使用して Cython.Build.cythonize() 関数を呼び出し、.pyx ファイルをシアン化します。この関数は、シアン化したいファイルへのパスを受け取ります。ここでは、setup.py ファイルが test_cython.pyx ファイルと同じ場所にあると仮定しています。.
import distutils.core
import Cython.Build
distutils.core.setup(
ext_modules = Cython.Build.cythonize("test_cython.pyx"))Cythonファイルをビルドするには、コマンドラインで以下のコマンドを入力します。コマンドラインのカレントディレクトリは、setup.pyファイルと同じディレクトリである必要があります。.
python setup.py build_ext --inplace
このコマンドが完了すると、.pyxファイルの横に2つのファイルが作成されます。1つ目のファイルの拡張子は.c、もう1つのファイルの拡張子は.pyd(または使用しているオペレーティングシステムに応じて類似の拡張子)になります。生成されたファイルを使用するには、test_cythonモジュールをインポートするだけで、「Hello Cython」というメッセージが直接表示されます(以下を参照)。.
![]()
これでPythonコードのCyton化が完了しました。次のセクションでは、ループが作成された.pyxファイルのCyton化について説明します。.
「for」ループのサイトニック化“
さて、先ほどのタスク、つまり100万個の数値をループして合計するforループを最適化してみましょう。まずはループ自体の効率性を調べてみましょう。timeモジュールは、実行にかかる時間を推定するために役立ちます。.
import time
t1 = time.time()
for k in range(1000000):
pass
t2 = time.time()
t = t2-t1
print("%.20f" % t).pyxファイルでは、3回の実行にかかる平均時間は0.0281秒です。このコードは、Core i7-6500U(2.5GHz)プロセッサと16GBのDDR3 RAMを搭載したマシンで実行されています。.
これを、典型的なPythonファイルの実行時間(平均0.0411秒)と比較してみましょう。つまり、forループをC言語の速度で実行するように変更しなくても、Cythonは反復処理においてPythonのわずか1.46倍しか速くないということです。.
では、加算してみましょう。これを行うには、range() 関数を使用します。.
import time
t1 = time.time()
total = 0
for k in range(1000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.100f" % t)どちらのスクリプトも同じ値、つまり499999500000を返すことに注意してください。Pythonでは、この実行には平均0.1183秒かかります(3つのテスト)。Cythonでは1.35倍高速で、平均0.0875秒かかります。.
ここで、ループが 0 から始まり、10 億の数字を処理する別の例を見てみましょう。.
import time
t1 = time.time()
total = 0
for k in range(1000000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.20f" % t)Cythonスクリプトは約85秒(1.4分)で完了しましたが、Pythonスクリプトは約115秒(1.9分)で完了しました。どちらの場合も、かなり時間がかかります。このような単純なタスクに1分以上かかるのであれば、Cythonを使う意味があるのでしょうか?これはCythonのせいではなく、私たちのせいであることに注意してください。.
前述の通り、Cythonスクリプト(.pyx)内にPythonコードを記述することは確かに改善されますが、実行時のパフォーマンスには大きな違いはありません。Cythonスクリプト内のPythonコードにいくつか変更を加える必要があります。まず最初に、使用する変数のデータ型を明示的に宣言する必要があります。.
Cデータ型を変数に割り当てる
前のコードでは、total、k、t1、t2、tの5つの変数が使用されています。これらの変数のデータ型はすべてコードによって暗黙的に推論されるため、時間がかかります。データ型の推論にかかる時間を節約するために、C言語からデータ型を割り当てましょう。.
変数totalの型はunsigned long long intです。すべての数値の合計が整数になるため整数型となり、その合計が常に正になるためunsigned型となります。しかし、なぜlong long型なのでしょうか?それは、すべての数値の合計が非常に大きいため、変数を可能な限り大きくするためにlong long型が使われているからです。.
変数 k に割り当てられたデータ型は int であり、残りの 3 つの変数 t1、t2、t にはデータ型 float が割り当てられます。.
import time
cdef unsigned long long int total
cdef int k
cdef float t1, t2, t
t1 = time.time()
for k in range(1000000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.100f" % t)最後のprint文で定義されている精度が100に設定されており、これらの数値はすべて0になっていることに注目してください(次の画像を参照)。これはCythonを使用することで期待できる結果です。Pythonでは1.9分以上かかるのに対し、Cythonでは全く時間がかかりません。Pythonの1000倍や100000倍速いとは言いませんが、出力時間の精度を変えて試してみましたが、それでも数値は表示されませんでした。.
![]()
range() 関数に渡される値を格納する整数変数を作成することもできます。これにより、パフォーマンスがさらに向上します。新しいコードは以下の通りです。値は整数変数 maxval に格納されています。.
import time
cdef unsigned long long int maxval
cdef unsigned long long int total
cdef int k
cdef float t1, t2, t
maxval=1000000000
t1=time.time()
for k in range(maxval):
total = total + k
print "Total =", total
t2=time.time()
t = t2-t1
print("%.100f" % t)Cython を使用して Python スクリプトのパフォーマンスを向上させる方法を確認したので、これを Raspberry Pi (RPi) に適用してみましょう。.
パソコンからRaspberry Piにアクセス可能
Raspberry Piを初めてお使いになる場合は、PCとRPiの両方をネットワークに接続する必要があります。DHCP(Dynamic Host Configuration Protocol)が有効になっているスイッチに両方のデバイスを接続することで、IPアドレスを自動割り当てできます。ネットワークが正常に構築されると、割り当てられたIPv4アドレスに基づいてRPiにアクセスできるようになります。RPiに割り当てられているIPv4アドレスを確認するにはどうすればよいでしょうか?ご安心ください。IPスキャナーツールを使えば簡単です。このチュートリアルでは、「Advanced IP Scanner」という無料アプリを使用します。.
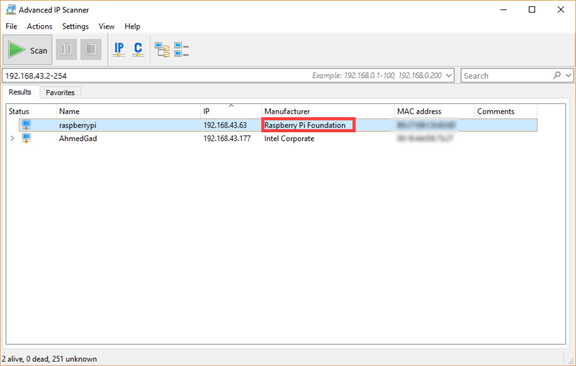
このアプリケーションのユーザーインターフェースは次のとおりです。このアプリケーションは、検索するIPv4アドレスの範囲を受け付け、アクティブなデバイスに関する情報を返します。.
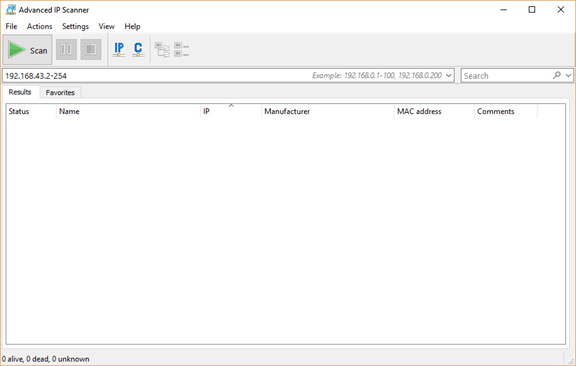
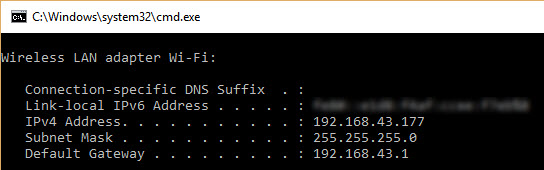
ローカルネットワークのIPv4アドレス範囲を入力する必要があります。範囲がわからない場合は、Windowsではipconfigコマンド(Linuxではifconfigコマンド)を実行して、コンピューターのIPv4アドレスを確認してください(下図参照)。私の場合、コンピューターのWi-Fiアダプターに割り当てられたIPv4アドレスは192.168.43.177、サブネットマスクは255.255.255.0です。つまり、ネットワーク上のIPv4アドレス範囲は192.168.43.1から192.168.43.255までです。図に示すように、IPv4アドレス192.168.43.1はゲートウェイに割り当てられています。この範囲の最後のIPv4アドレスである192.168.43.255は、ブロードキャストメッセージ用に予約されていることに注意してください。したがって、検索する範囲は 192.168.43.2 から始まり、192.168.43.254 で終わります。.
次の図に示すスキャン結果によると、RPiに割り当てられたIPv4アドレスは192.168.43.63です。このIPv4アドレスは、セキュアシェル(SSH)セッションを確立するために使用できます。.
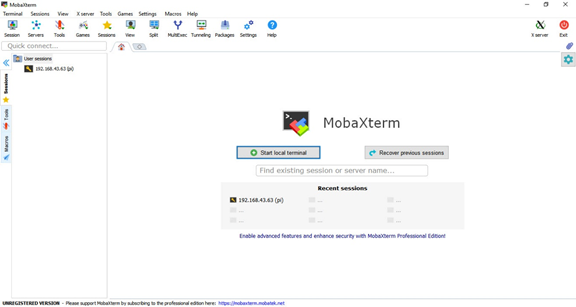
SSHセッションを確立するために、MobaXtermという無料ソフトウェアを使用します。このプログラムのユーザーインターフェースは次のとおりです。.
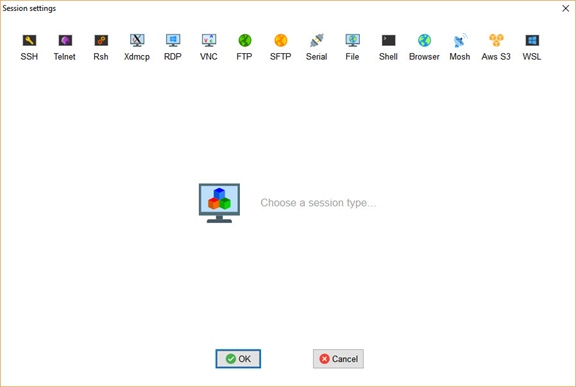
SSHセッションを作成するには、左上隅の「セッション」ボタンをクリックします。下図のような新しいウィンドウが表示されます。.
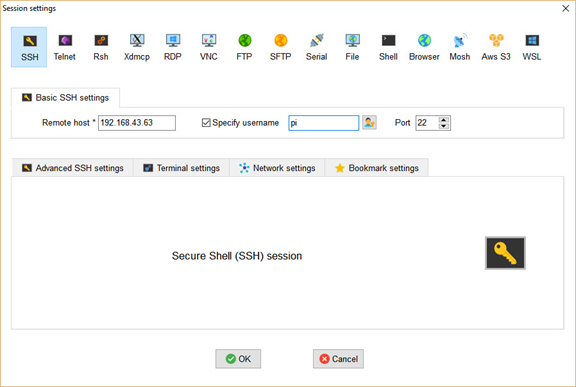
このウィンドウで、左上隅のSSHボタンをクリックすると、以下のウィンドウが開きます。Raspberry PiのIPv4アドレスとユーザー名(デフォルトではpi)を入力し、「OK」をクリックしてセッションを開始します。.
「OK」ボタンをクリックすると、パスワードの入力を求める新しいウィンドウが表示されます。デフォルトのパスワードはraspberrypiです。ログインすると、次のウィンドウが表示されます。左側のペインでは、Raspberry Piのディレクトリ間を簡単に移動できます。コマンドを入力するためのコマンドラインもあります。.
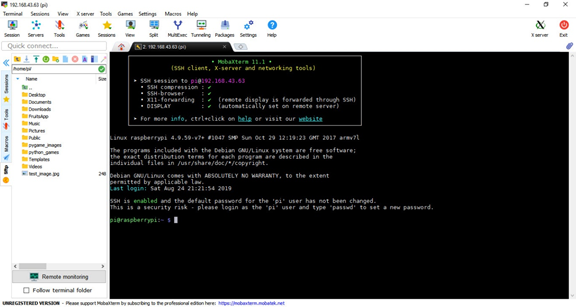
Raspberry PiでCythonを使用する
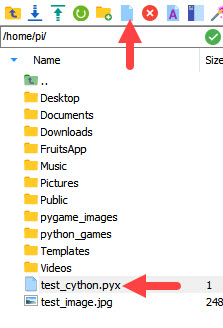
先ほどの例のコードを記述するために、新しいファイルを作成し、拡張子を.pyxに変更します。左側のパネルバーには、新しいファイルとディレクトリを作成するためのオプションがあります。下の画像に示すように、新規ファイルアイコンを使用すると、作業が簡単になります。Raspberry Piのルートディレクトリにtest_cython.pyxというファイルを作成しました。.
ファイルをダブルクリックして開き、コードを貼り付けて保存します。次に、先ほど説明した通りのsetup.pyファイルを作成します。その後、以下のコマンドを実行してCythonスクリプトをビルドします。.
python3 setup.py build_ext --inplace
このコマンドが正常に完了すると、次の図に示すように、左側のパネルに出力ファイルが表示されます。Windowsを使用していないため、インポートするモジュールの拡張子が.soになっていることに注意してください。.
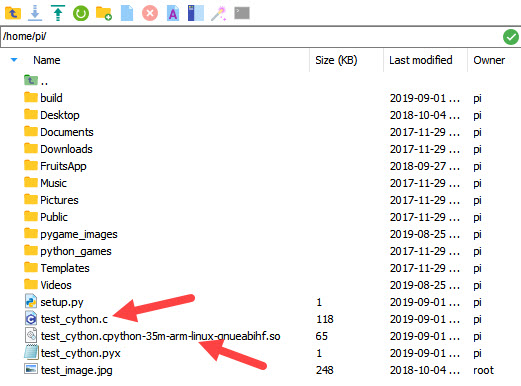
それでは、Pythonを起動してモジュールをインポートしてみましょう(以下を参照)。PCと同じ結果が得られ、実行時間は実質的にゼロです。.

結果
このチュートリアルでは、Cythonを使ってPythonスクリプトの実行時間を短縮する方法を説明しました。ループの使用例を紹介します。 のために 10億個の数値からなるPythonリストの全要素を加算する処理について、変数宣言の有無で実行時間を比較しました。純粋なPythonではこの処理に約2分かかりますが、Cythonを使用し、静的変数を宣言することで、ほぼ瞬時に処理が完了します。.









