









導入
このチュートリアルでは、UbuntuまたはDebianサーバー上で言語モデルを実行するためにOllamaをインストールする方法について説明します。また、Open WebUIでチャットインターフェースを設定する方法と、カスタム言語モデルを使用する方法についても説明します。.
前提条件
- Ubuntu/Debian を搭載したサーバー
- ルート ユーザー アクセスまたは sudo 権限を持つユーザーが必要です。.
- 始める前に、ファイアウォールを含むいくつかの初期設定を完了する必要があります。.
ステップ1 – Ollamaをインストールする
以下の手順では、Ollamaを手動でインストールする方法を説明します。すぐに始めるには、インストールスクリプトを使用して「ステップ2 - Ollama WebUIのインストール」に進んでください。.
Ollama を自分でインストールするには、次の手順に従います。
サーバーに Nvidia GPU が搭載されている場合は、CUDA ドライバーがインストールされていることを確認してください。
nvidia-smi
CUDAドライバがインストールされていない場合は、今すぐインストールしてください。この設定では、オペレーティングシステムとインストーラの種類を選択すると、設定に応じて実行する必要があるコマンドが表示されます。.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
Ollamaバイナリをダウンロードし、Ollamaユーザーを作成します。
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaサービスファイルを作成します。デフォルトでは、Ollama APIはポート11434 127.0.0.1でアクセスできます。つまり、APIはlocalhostでのみ利用可能です。.
Ollamaへの外部アクセスが必要な場合は、 環境 Ollama API にアクセスするための IP アドレスを削除して設定します。. 0.0.0.0 サーバーのパブリックIP経由でAPIにアクセスできるようになります。 環境 を使用している場合は、サーバーのファイアウォールがここで設定したポートへのアクセスを許可していることを確認してください。 11434 サーバーが 1 台しかない場合は、以下のコマンドを変更する必要はありません。.
次のコードブロックの内容全体をコピーして貼り付けます。この新しいファイルは /etc/systemd/system/ollama.service コンテンツの作成と相互コンテンツ 終了 新しいファイルに追加します。.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
systemd デーモンをリロードし、Ollama サービスを有効にします。
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaステータスを確認するには、systemctl status olama を使用してください。Olama が起動していない場合は、systemctl start olama を実行してください。.
ターミナルで言語モデルを起動し、質問することができます。例えば:
ollama run llama2
次の手順では、Web ブラウザーを介して美しいインターフェースで質問できるように、Web インターフェースをインストールする方法について説明します。.
ステップ2 – Open WebUIをインストールする
GitHubのOlamaドキュメントには、様々なWebおよびターミナル統合のリストが掲載されています。この例では、Open WebUIのインストール方法を説明します。.
Open WebUIはOllamaと同じサーバーにインストールすることも、OllamaとOpen WebUIを別のサーバーにインストールすることもできます。Open WebUIを別のサーバーにインストールする場合は、Ollama APIがネットワーク上で公開されていることを確認してください。念のため、 /etc/systemd/system/olama.service Ollamaがインストールされているサーバーとその値を表示します OLLAMA_HOST 確認する。.
次の手順では、インターフェースのインストール方法について説明します。
- 手動で
- Dockerを使う
Open WebUIを手動でインストールする
npm と pip をインストールし、WebUI リポジトリのクローンを作成し、サンプル環境ファイルのコピーを作成します。
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .envで 環境。. Ollama APIに接続するためのアドレスはデフォルトに設定されています。 ローカルホスト:11434 設定されています。Ollama APIをOpen WebUIと同じサーバーにインストールしている場合は、これらの設定をそのままにしておくことができます。Open WebUIをOllama APIとは別のサーバーにインストールしている場合は、 環境。. デフォルト値を編集して、Olama がインストールされているサーバー アドレスに置き換えます。.
依存関係のリスト パッケージ.json というスクリプトをインストールして実行します 建てる 走る:
npm i && npm run build
必要な Python パッケージをインストールします。
cd backend
sudo pip install -r requirements.txt -Uウェブインターフェース olama-webui/backend/start.sh 始める。.
sh start.shで スタート.sh、ポートは8080に設定されています。つまり、Open WebUIにアクセスできます。 http:// :8080 アクセス。サーバー上でファイアウォールが有効になっている場合は、チャットUIにアクセスする前にポートを許可する必要があります。許可するには、「ステップ3 – Web UIへのポートの許可」に進んでください。ファイアウォールがない場合は(推奨されません)、そのまま「ステップ4 – モデルの追加」に進んでください。.
DockerでOpen WebUIをインストールする
このステップでは、Docker をインストールする必要があります。まだ Docker をインストールしていない場合は、このチュートリアルを使って今すぐインストールできます。.
前述のように、Open WebUI を Ollama と同じサーバーにインストールするか、Ollama と Open WebUI を 2 つの別々のサーバーにインストールするかを選択できます。.
同じOllamaサーバーにOpen WebUIをインストールする
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Ollamaとは別のサーバーにOpen WebUIをインストールする
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
上記のDockerコマンドでは、ポートは3000に設定されています。これは、Open WebUIにアクセスできることを意味します。 http:// :3000 アクセス。サーバー上でファイアウォールが有効になっている場合は、チャットインターフェースにアクセスする前にポートを許可する必要があります。これは次の手順で説明します。.
ステップ3 – Web UIへのポートを許可する
ファイアウォールをご利用の場合は、Open WebUIのポートへのアクセスが許可されていることを確認してください。手動でインストールした場合は、ポートを開く必要があります。 8080 TCP Dockerでインストールした場合は、ポートを許可する必要があります 3000 TCP 私にさせて。.
再度確認するには、 ネットスタット 使用中のポートを確認します。.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTENファイアウォールツールには様々な種類があります。このチュートリアルでは、Ubuntuのデフォルトのファイアウォールツールを設定します。 ufw 別のファイアウォールを使用している場合は、TCP ポート 8080 または 3000 への受信トラフィックが許可されていることを確認してください。.
ファイアウォールルールを管理する ufw:
- 現在のファイアウォール設定を表示する
ファイアウォールを確認するには ufw がアクティブで、すでにルールがある場合は、以下を使用できます。
sudo ufw status
- TCPポート8080または3000を許可する
ファイアウォールが有効になっている場合は、次のコマンドを実行して、TCP ポート 8080 または 3000 への着信トラフィックを許可します。
sudo ufw allow proto tcp to any port 8080
- 新しいファイアウォール設定を表示する
新しいルールが追加されました。確認するには、次のページにアクセスしてください。
sudo ufw status
ステップ4 – モデルの追加
ウェブインターフェースにアクセスしたら、最初のアカウントを作成する必要があります。このユーザーには管理者権限が付与されます。最初のチャットを開始するには、モデルを選択する必要があります。llamaの公式サイトでモデルのリストを参照できます。この例では、「llama2」を追加します。.
右上隅にある設定アイコンを選択します。
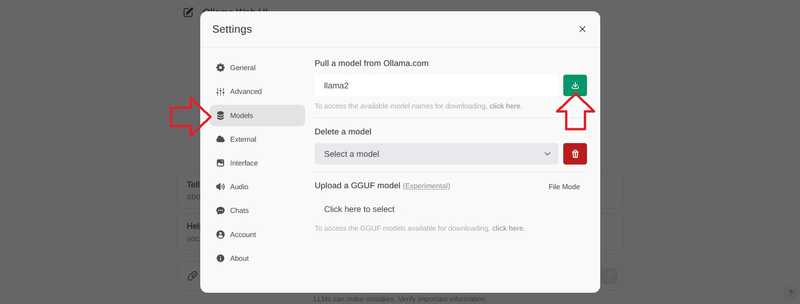
「モデル」に移動し、モデルを入力してダウンロードボタンを選択します。.
次のメッセージが表示されるまで待ちます。
Model 'llama2' has been successfully downloaded.
設定を閉じてチャットに戻ります。.
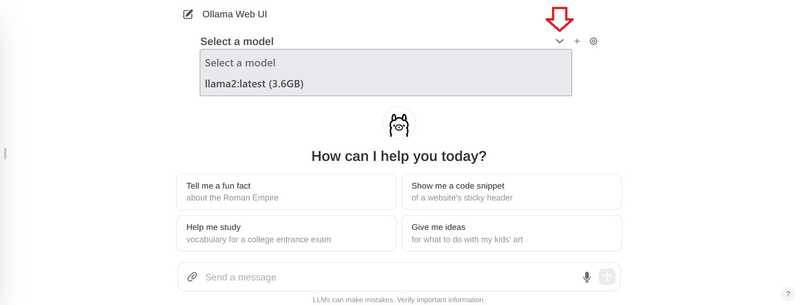
チャットで、上部の「モデルを選択」をクリックしてモデルを追加します。.
複数のモデルを追加する場合は、上部の + 記号を使用できます。.
使用したいモデルを追加したら、質問を開始できます。複数のモデルを追加した場合は、回答を切り替えることができます。.

ステップ5 – モデルを追加する
インターフェースから新しいモデルを追加したい場合は、 http:// :8080/モデルファイル/作成/ やってください。必要なら。 8080 と 3000 交換する。.
以下では、ターミナル経由で新しいモデルを追加する方法に焦点を当てます。まず、olamaがインストールされているサーバーに接続する必要があります。リストから 世界 現在利用可能なモデルを一覧表示するために使用します。.
- モデルファイルを作成する
モデルファイルの要件は、GitHubのOlamaドキュメントに記載されています。モデルファイルの最初の行にFROM使用するモデルを指定できます。この例では、既存のllama2モデルを変更します。全く新しいモデルを追加する場合は、モデルファイルへのパスを指定する必要があります(例:FROM ./my-model.gguf)。.
nano new-model
このコンテンツを保存する:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
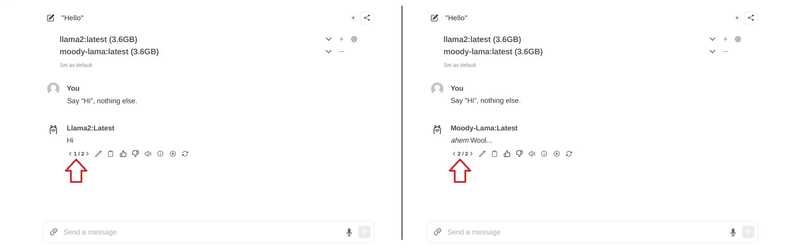
SYSTEM You are a moody lama that only talks about its own fluffy wool.モデルファイルからモデルを作成する
ollama create moody-lama -f ./new-model
- 新しいモデルが利用可能かどうかを確認します。
olama コマンドを使用してすべてのモデルを一覧表示します。Moody-lama も一覧表示されるはずです。.
ollama list
- WebUIでモデルを使用する
ウェブインターフェースに戻ると、モデルがモデル選択リストに表示されるはずです。まだ表示されていない場合は、更新する必要があるかもしれません。.
結果
このチュートリアルでは、独自のサーバーで AI チャットをホストする方法と、独自のモデルを追加する方法を学習しました。.









