









テンソルフロー
テンソルフロー これはGoogleが公開している機械学習およびディープラーニングのライブラリで、Googleはユーザーに優れたユーザーエクスペリエンスを提供するために、このライブラリを様々な場面で活用しています。例えば、検索を開始するとGoogleが入力したテキストを自動補完してくれる機能などが挙げられます。.
機械学習を利用する人々は3つのグループに分けられます。1. 研究者 2. データサイエンティスト 3. プログラマー これらの人々のニーズを満たすために、Google BrainチームはTensorFlowライブラリを開発しました。TensorFlowは、さまざまなCPUやGPUで実行でき、C++、Python、Javaなどのさまざまな言語で使用できます。TensorFlowは、サーバーだけでなく、モバイル端末でも使用できます。.
TensorFlowの歴史
データ量が増加するにつれて、ディープラーニングがディープラーニングアルゴリズムを追い越し始め、Google はこれらのディープ ニューラル ネットワークを使用してサービスを強化できるという結論に達し、開発者と研究者が AI モデルを同時に共同で作業できるようにする TensorFlow と呼ばれるフレームワークの構築を開始しました。.
プロジェクトが十分に開発され、拡張可能になったため、2015 年に一般公開されました。ただし、安定バージョンは 2017 年までリリースされませんでした。.
TensorFlowの重要な特徴は、オープンソースであり、Apacheライセンスに基づいていることです。そのため、簡単に使用、編集、そして独自のディストリビューションを公開できます。Googleに支払うことなく、TensorFlowから収益を得ることさえ可能です。 .
TensorFlowアーキテクチャ
TensorFlowアーキテクチャは3つの部分から構成されています。1. データ前処理 2. モデル構築 3. モデルのトレーニングと推定。TensorFlowという名前は、入力として多次元配列を受け取るため、次のように命名されています。 テンソル そして、データに対する一連の操作のグラフを実行することができます。 フローチャート はい。.
どこで行われますか?
このライブラリの使用には 2 つのフェーズがあります。
開発フェーズ: モデルをトレーニングする時間があり、このフェーズは通常、ラップトップまたはシステムで実行されます。.
実装フェーズ: トレーニングが完了すると、デスクトップからサーバー、さらにはモバイル フォンまで、どこでもモデルを実行できるようになります。.
したがって、モデルのトレーニングと実行は異なるマシンで実行できます。.
CPU を使用するだけでなく、GPU で TensorFlow を実行することもできます。.
行列計算では、大量の情報に対して同じ演算子が実行されることから、このタイプの計算は GPU の構造と互換性があることが、2010 年後半にスタンフォード大学の研究者によって発見されました。.
このライブラリはC++で書かれているので、非常に高速です。もちろん、Pythonなどの他の言語でも使用できます。.
TensorFlow の重要な機能は TensorBoard です。これを使用すると、TensorFlow が何を実行しているかを確認できます。.
TensorFlowコンポーネント
テンソル
テンソルは、様々な種類の情報を表現できるN次元行列の配列です。テンソル内の各値は、同じ形状の情報を保持します。.
テンソルは計算の入力または出力になります。.
グラフ
TensorFlowでは、すべての演算はグラフ内で実行されます。各グラフは、順番に実行される計算の集合です。各計算は演算ノードと呼ばれ、互いに接続されています。.
では、なぜグラフなのでしょうか?
- さまざまなシステムで実行できます。
- グラフは後で使用するために保存できます。
- グラフ内のすべての計算は、テンソルを接続することによって実行されます。.
- つまり、グラフでは、各エッジは値 (テンソル) であり、各ノードは演算子 (加算など) です。.
TensorFlow が有名なのはなぜですか?
TensorFlowは、誰でも使えるように構築されており、RNNやCNNといったディープラーニングアーキテクチャで様々なスケールに対応できるAPIを備えているため、非常に優れています。グラフコンピューティングをベースとしているため、TensorBoard内でニューラルネットワークを可視化することができ、デバッグに非常に便利です。そして全体として、TensorFlowはデプロイメント時のスケーラビリティを重視して構築されています。.
良いニュースとしては、GitHub 上のさまざまなディープラーニング フレームワークの中で最大のコミュニティがあることです。.
TensorFlow ではいくつのアルゴリズムがサポートされていますか?
- 線形回帰: tf.estimator.LinearRegressor
- 分類: tf.estimator.LinearClassifier
- 深層分類: tf.estimator.DNNClassifier
- ディープラーニングワイプとディープ:tf.estimator.DNNLinearCombinedClassifier
- ブースターツリー回帰: tf.estimator.BoostedTreesRegressor
- ブーストツリー分類: tf.estimator.BoostedTreesClassifier
いくつかの簡単な例
- 12numpyをnpとしてインポートする
- TensorflowをTFとしてインポートする
上記の 2 行では、numpy ライブラリと tensorflow ライブラリをインポートしています。.
この例では、X_1とX_2を乗算します。まずグラフを作成し、TensorFlowセッションを実行して結果を計算する必要があります。.
さあ、始めましょう。
ステップ1: 変数を定義する
最初のステップは、入力ノード X_1、X_2 を作成することです。TensorFlow では、作成するノードの種類を指定する必要があります。ここではプレースホルダー型を選択します。.
プレースホルダー:
この型は、計算を実行するたびにテンソルに新しい値を割り当てます。.
- X_1 = tf.placeholder(tf.float32, 名前 = “X_1”)
- X_2 = tf.placeholder(tf.float32, 名前 = “X_2”)
ご覧のとおり、このノードのタイプを float として入力し、名前を変数名として入力しました。.
ステップ2: 計算を定義する
- 1乗算 = tf.multiply(X_1, X_2, 名前 = “乗算”)
上記の行では、乗算演算子の演算子として機能する頂点を作成しています。
これは乗算する頂点の入力であり、multiply という名前を付けました。
これで最初のグラフが作成されました。.
ステップ3: 操作を実行する
操作を実行するには、セッションを作成する必要があります。このセッションはtf.Session()を使用して作成され、runコマンドの実行時に実行されます。.
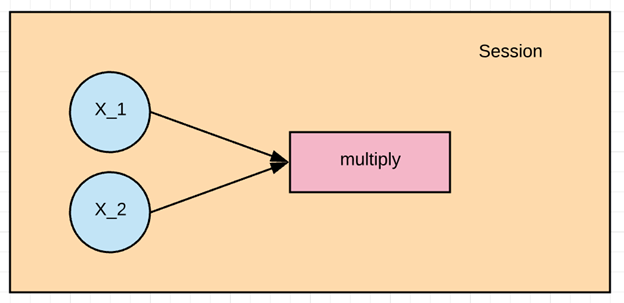
乗算を実行する際には、テンソルx1とx2の値を入力として与える必要があります。これはfeed_dictを代入することで行われます。この例では、1から3までの値がx1に、4から6までの値がx2に代入されています。そして、結果を出力します。.
- X_1 = tf.placeholder(tf.float32, 名前 = “X_1”)
- X_2 = tf.placeholder(tf.float32, 名前 = “X_2”)
- 1乗算 = tf.multiply(X_1, X_2, 名前 = “乗算”)
- tf.Session() をセッションとして使用します:
- 結果 = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(結果)
- [ 4. 10. 18.]
TensorFlowにデータをインポートするさまざまな方法
モデルをトレーニングする前の最初のステップの 1 つは、データをインポートすることです。これには 2 つのモードがあります。
- RAM へのデータの入力: たとえば、Python で 1 行のコードを記述するなどして、メモリ配列にデータを入力する簡単な方法があります。.
- TensorFlowデータパイプラインの使用:TensorFlowには、データを取得し、一連の操作を実行してアルゴリズムに渡すためのAPIセットが用意されています。この方法は、特にデータが非常に大きい場合に非常に効果的です。例えば、画像は巨大でRAMに収まりきらない場合などです。このような場合、データパイプラインがRAM管理を担います。.
ここで問題となるのは、どちらを使用するかということです。
データサイズが10GB未満であれば、最初の方法を簡単に使用できます。例えば、このための有名なライブラリとしてpandasがあります。それ以外の場合、例えばデータが30GBでRAMが12GBの場合、当然この方法は使えず、パイプラインAPIを使用する必要があります。パイプラインはデータをバッチ処理し、各バッチはパイプラインに入力され、モデルの学習に使用されます。パイプラインを使用すると並列処理が可能になります。つまり、TensorFlowは複数の異なるCPUで同時にモデルを学習できます。.
つまり、データが小さい場合は、pandasなどを使ってRAMに完全にロードします。そうでない場合、または複数のCPUを使用する場合は、TensorFlowパイプラインを使用します。.
TensorFlowでパイプラインを作成する
ステップ1) データを作成する
numpy ライブラリを使用して 2 つの乱数を生成します。
- 123numpyをnpとしてインポートする
- x_input = np.random.sample((1,2))
- 印刷(x_input)
- 1[[0.8835775 0.23766977]]
ステップ2) プレースホルダーを作成する
この手順では、float 型の 2 つのメンバーを持つ配列として、X という名前のプレースホルダーを作成します。
- プレースホルダー#を使用する
- x = tf.placeholder(tf.float32, 形状=[1,2], 名前 = 'X')
ステップ3: データセットを作成する
この時点で、プレースホルダー値 x を配置するデータセットを定義する必要があります。.
- 1tf.data.Dataset.from_tensor_slices
- 1データセット = tf.data.Dataset.from_tensor_slices(x)
ステップ4: パイプラインを構築する
このステップでは、パイプラインを初期化する必要があります。最初のステップは、データを反復処理するイテレータを作成することです。get_next メソッドを使用して次の値を取得します。この例では、2つの値のみを持つバッチがあります。.
- 12イテレータ = dataset.make_initializable_iterator()
- get_next = イテレータ.get_next()
ステップ5: 計算を実行する
最後のステップでは、反復子と numpy によって作成された入力値を入力とするセッションを実行し、それぞれの値を出力します。.
- tf.Session() をセッションとして使用します:
- # プレースホルダーにデータを入力する
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))
- 1[0.8835775 0.23766978]
まとめ
TensorFlowは、あらゆるディープラーニングフレームワークの構築に使用できる最も有名なディープラーニングライブラリです。Google Brainは、研究チームと開発チーム間のギャップを埋めるためにこのプロジェクトを開発し、Googleはほぼすべてのプロジェクトでこれを使用しています。TensorFlowを使用する主な理由の一つは、デプロイメント時のスケーラビリティの容易さです。TensorFlowは、強力なサーバーからAndroidやiOSスマートフォンまで幅広く利用できます。.
TensorFlow はセッション内で動作し、各セッションは異なる計算を行うグラフによって定義されます。.
TensorFlow での簡単な例として、乗算は次のようになります。
1. 変数の定義
- X_1 = tf.placeholder(tf.float32, 名前 = “X_1”)
- X_2 = tf.placeholder(tf.float32, 名前 = “X_2”)
2. 計算の定義
- 1乗算 = tf.multiply(X_1, X_2, 名前 = “乗算”)
3. 業務の遂行
- tf.Session() をセッションとして使用します:
- 結果 = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(結果)
TensorFlow では、データを RAM にロードするためのパイプラインを作成するのが一般的です。これは次の手順で実行されます。
1. データ作成
- numpyをnpとしてインポートする
- x_input = np.random.sample((1,2))
- 印刷(x_input)
2. プレースホルダーを作成する
- 1x = tf.placeholder(tf.float32, 形状=[1,2], 名前 = 'X')
3. データセット法の定義
- 1データセット = tf.data.Dataset.from_tensor_slices(x)
4. パイプライン建設
- 1イテレータ = dataset.make_initializable_iterator() get_next = iteraror.get_next()
5. プログラム実行
- tf.Session() をセッションとして使用します:
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))









