









導入
非構造化データと会話し、貴重な情報を簡単に抽出できると想像してみてください。今日のデータ駆動型の環境において、非構造化ドキュメントから有意義な洞察を抽出することは依然として課題であり、意思決定やイノベーションの妨げとなっています。このチュートリアルでは、埋め込みについて理解し、Amazon Open Search をベクターデータベースとして使用する方法を探り、Langchain フレームワークを大規模言語モデル (LLM) と統合して、NLP チャットボットが埋め込まれたウェブサイトを構築します。オープンソースの大規模言語モデルを活用し、非構造化ドキュメントから有意義な洞察を抽出するための LLM の基礎について説明します。このチュートリアルを完了すると、非構造化ドキュメントから有意義な洞察を得る方法を包括的に理解し、そのスキルを使用して同様のフルスタック AI ベースのソリューションを探索およびイノベーションできるようになります。.
前提条件
- 有効なAWSアカウントが必要です。お持ちでない場合は、AWSウェブサイトでサインアップできます。.
- ローカルマシンにAWSコマンドラインインターフェース(CLI)がインストールされ、必要な認証情報とデフォルトのリージョンが適切に設定されていることを確認してください。aws configureコマンドを使用して設定できます。.
- Docker Engineをダウンロードしてインストールします。お使いのオペレーティングシステムのインストール手順に従ってください。.
何を構築するのでしょうか?
この例では、多くの企業が直面している問題を模倣します。今日のデータの多くは非構造化データですが、音声や動画のトランスクリプト、PDFやWord文書、マニュアル、スキャンしたメモ、ソーシャルメディアのトランスクリプトなど、非構造化データであることがほとんどです。LLM(学習モデル)として、Flan-T5 XXLモデルを使用します。このモデルは、非構造化テキストから要約やQ&Aを生成できます。下の図は、各構成要素のアーキテクチャを示しています。.

まずは基本から始めましょう。
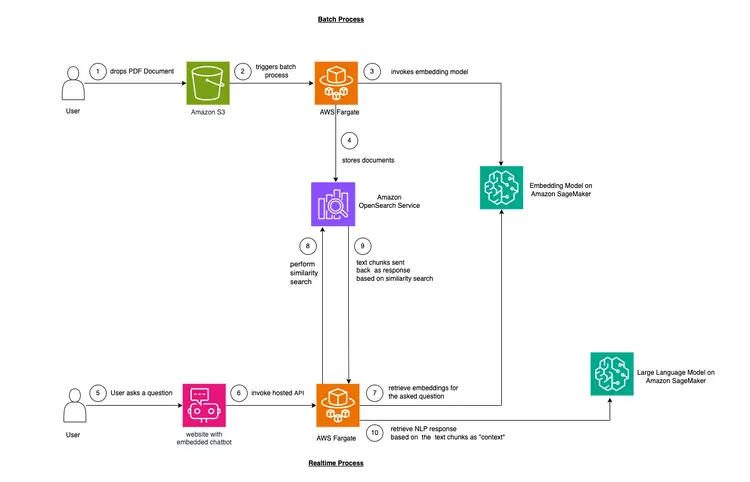
インコンテキスト学習と呼ばれる手法を用いて、ドメインまたはケース固有の「コンテキスト」をLLMに注入します。今回のケースでは、構造化されていない自動車のPDFマニュアルをLLMの「コンテキスト」として追加し、LLMがこのマニュアルに関する質問に答えられるようにします。実にシンプルです!目標は、これをさらに一歩進め、質問を受信してバックエンドに送信し、ウェブサイトに埋め込まれたオープンソースのチャットボットからアクセスできるリアルタイムAPIを作成することです。このチュートリアルでは、ユーザーエクスペリエンス全体を構築し、プロセス全体を通して様々な概念やツールについての洞察を得ることができます。.
- テキスト内学習を提供するための最初のステップは、PDF ドキュメントを取り込んでそれをテキスト チャンクに変換し、「埋め込み」と呼ばれるこれらのテキスト チャンクのベクトル表現を生成し、最後にこれらの埋め込みをベクトル データベースに保存することです。.
- ベクター データベースを使用すると、そこに保存されているテキスト埋め込みに対して「類似性検索」を実行できます。.
- Amazon SageMaker JumpStart は、オープンソースの事前トレーニング済みモデル用のインフラストラクチャを構築するためのワンクリックデプロイソリューションテンプレートを提供します。Amazon SageMaker JumpStart を使用して、埋め込みモデルと大規模言語モデルをデプロイします。.
- Amazon OpenSearch は、ベクトル空間内の点の最近傍を検索できる検索および分析エンジンであり、ベクトルデータベースとして適しています。.
チャート: PDF からベクター データベースに埋め込むための変換
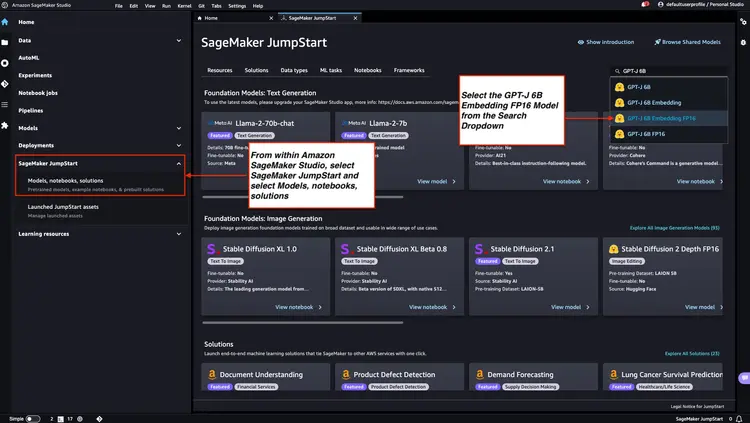
ステップ 1 - Amazon SageMaker JumpStart を使用して GPT-J 6B FP16 埋め込みモデルをデプロイする
Amazon SageMaker ドキュメントに記載されている手順に従ってください。Amazon SageMaker Studio のメインメニューから「JumpStart」セクションを開き、Amazon SageMaker JumpStart ノードを起動します。「モデル、ノートブック、ソリューション」を選択し、下の画像に示すように「GPT-J 6B Embedding FP16」埋め込みモデルを選択します。「デプロイ」をクリックすると、Amazon SageMaker JumpStart が、この事前トレーニング済みモデルを SageMaker 環境にデプロイするためのインフラストラクチャのセットアップを行います。.
ステップ 2 - Amazon SageMaker JumpStart を使用して Flan T5 XXL LLM をデプロイする
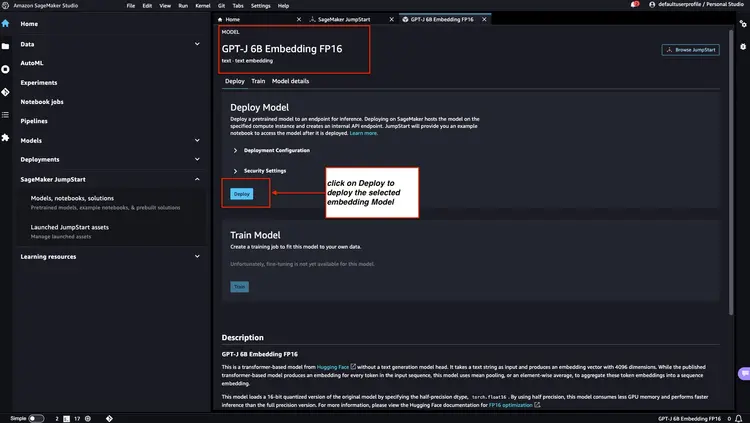
次に、Amazon SageMaker JumpStart で Flan-T5 XXL LLM を選択し、「デプロイ」をクリックして自動インフラストラクチャのセットアップを開始し、モデルエンドポイントを Amazon SageMaker 環境にデプロイします。.
ステップ3 - デプロイされたモデルエンドポイントのステータスを確認する
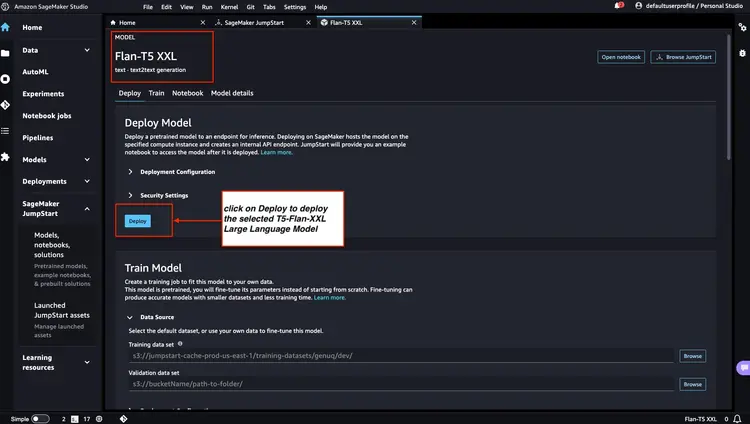
Amazon SageMaker コンソールで、ステップ 1 とステップ 2 でデプロイしたモデルエンドポイントのステータスを確認し、エンドポイント名を書き留めておきます。これらのエンドポイント名はコード内で使用します。モデルエンドポイントをデプロイした後のコンソールの表示は以下のとおりです。.
ステップ4 – Amazon Open Search Clusterを作成する
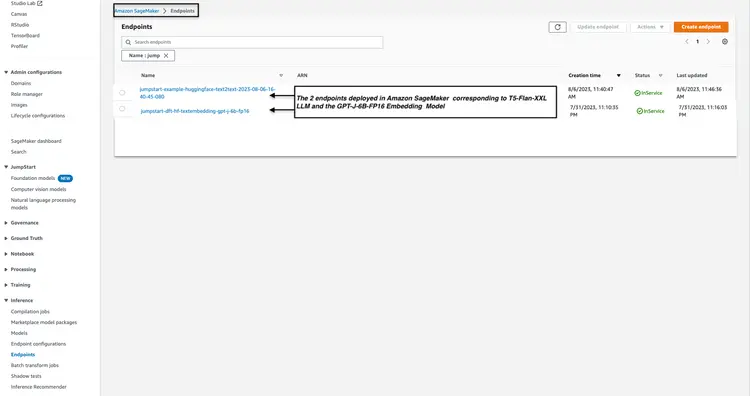
Amazon OpenSearch は、k近傍法(kNN)アルゴリズムをサポートする検索・分析サービスです。この機能は類似性ベースの検索に非常に役立ち、OpenSearch をベクターデータベースとして効果的に活用できます。kNN プラグインをサポートする Elasticsearch/OpenSearch のバージョンについて詳しくは、k-NN プラグインのドキュメントをご覧ください。.
AWS CLI を使用して、GitHub の場所から AWS CloudFormation テンプレートファイルをデプロイします。 インフラストラクチャ/opensearch-vectordb.yaml aws コマンドを使用します。 cloudformation スタック作成 Amazon Open Search クラスターを作成するには、次のコマンドを実行します。コマンドを実行する前に、値を置き換える必要があります。 ユーザー名 そして パスワード やりましょう。.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> ステップ5 – ドキュメントキャプチャと埋め込みワークフローを構築する
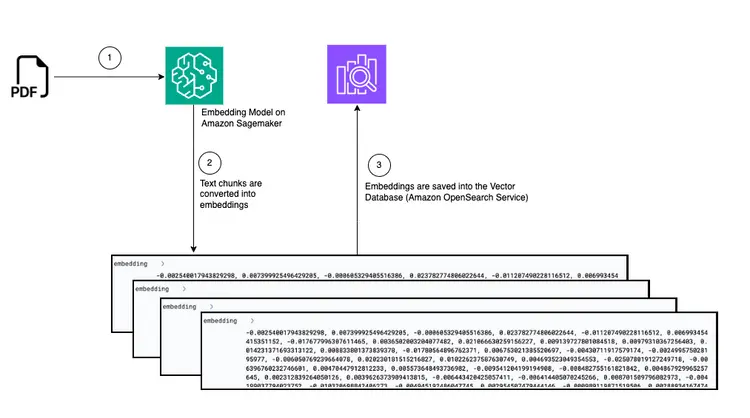
このステップでは、Amazon Simple Storage Service (S3) バケットに格納された PDF ドキュメントを読み取るための取り込みおよび処理パイプラインを作成します。このパイプラインは以下のタスクを実行します。
- PDF ドキュメントからテキストを抽出します。.
- テキストフラグメントを埋め込み(ベクトル表現)に変換します。.
- Amazon Open Search に埋め込みを保存します。.
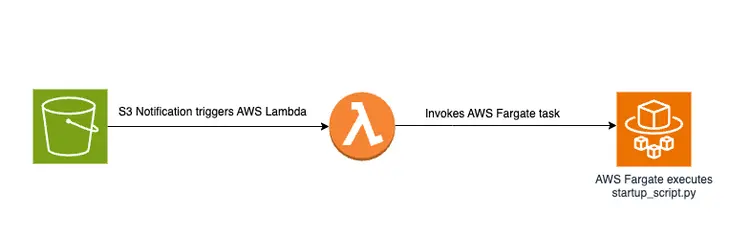
PDFファイルをS3バケットにドロップすると、AWS Fargateジョブを含むイベントドリブンワークフローがトリガーされます。このジョブは、テキストを埋め込みデータに変換し、Amazon Open Searchに挿入する役割を担います。.
図による概要
以下は、Amazon OpenSearch ベクターデータベースに埋め込まれたテキストスニペットを保存するためのドキュメント転送パイプラインを示す図です。
起動スクリプトとファイル構造
ファイル内のメインロジック 埋め込みを作成して VectorDB に保存\スタートアップ スクリプト.py このPythonスクリプトは次の場所にあります。 スタートアップスクリプト.pyは、ドキュメント処理、テキストの埋め込み、Amazon Open Search クラスターへの挿入に関連するいくつかのタスクを実行します。スクリプトは、Amazon S3 バケットから PDF ドキュメントをダウンロードし、ダウンロードしたドキュメントを小さなテキストチャンクに分割します。各チャンクのテキストコンテンツは、Amazon SageMaker にデプロイされた GPT-J 6B FP16 埋め込みモデルエンドポイント (TEXT_EMBEDDING_MODEL_ENDPOINT_NAME 環境変数から取得) に送信され、テキスト埋め込みが作成されます。作成された埋め込みは、他の情報とともに Amazon Open Search インデックスに配置されます。スクリプトは、環境変数から設定と検証パラメータを取得し、環境間で一貫性を保ちます。このスクリプトは、Docker コンテナ内で均一に実行されるように設計されています。.
Dockerイメージをビルドして公開する
コードを理解した後 スタートアップスクリプト.pyフォルダからDockerfileを構築します 埋め込みを作成して VectorDB に保存する イメージをAmazon Elastic Container Registry (Amazon ECR) にプッシュします。Amazon Elastic Container Registry (Amazon ECR) は、高性能ホスティングを提供するフルマネージドのコンテナレジストリで、アプリケーションイメージとアーティファクトをどこにでも確実にデプロイできます。AWS CLIとDocker CLIを使用してDockerイメージをビルドし、Amazon ECRにプッシュします。以下のコマンドはすべて、正しい AWS アカウント番号に置き換えてください。.
認証トークンを取得し、AWS CLI でレジストリに対して Docker クライアントを認証します。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com 次のコマンドを使用して Docker イメージをビルドします。.
docker build -t save-embedding-vectordb .
ビルドが完了したら、イメージにタグを付け、このリポジトリにイメージをプッシュできるようにします。
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
次のコマンドを実行して、このイメージを新しい Amazon ECR リポジトリにプッシュします。
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Docker イメージが Amazon ECR リポジトリにアップロードされると、次のイメージのようになります。
イベントベースのPDF埋め込みワークフローのインフラストラクチャを構築する
AWS コマンドラインインターフェース (AWS CLI) を使って、指定されたパラメータでイベント駆動型ワークフロー用の CloudFormation スタックを作成できます。CloudFormation テンプレートは、GitHub リポジトリから入手できます。 インフラストラクチャ/fargate-embeddings-vectordb-save.yaml AWS 環境に合わせてパラメータを無視する必要があります。.
コマンドで更新する主なパラメータは次のとおりです aws cloudformation スタック作成 次のように述べられています。
- BucketName: このパラメータは、PDF ドキュメントをドロップする Amazon S3 バケットを表します。.
- VpcId と SubnetId: これらのパラメータは、Fargate タスクが実行される場所を指定します。.
- ImageName: これは、save-embedding-vectordb の Amazon Elastic Container Registry (ECR) 内の Docker イメージの名前です。.
- TextEmbeddingModelEndpointName: このパラメータを使用して、手順 1 で Amazon SageMaker にデプロイされた埋め込みモデルの名前を指定します。.
- VectorDatabaseEndpoint: Amazon OpenSearch ドメインのエンドポイントアドレスを指定します。.
- VectorDatabaseUsername および VectorDatabasePassword: これらのパラメータは、手順 4 で作成した Amazon Open Search クラスターにアクセスするために必要な認証情報です。.
- VectorDatabaseIndex: PDF ドキュメントの埋め込みが保存される Amazon Open Search のインデックスの名前を設定します。.
CloudFormation スタックの作成を実行するには、パラメータ値を更新した後、次の AWS CLI コマンドを使用します。
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanual上記のCloudFormationスタックを作成することで、S3バケットを設定し、Lambda関数を起動するS3通知を作成します。このLambda関数はFargateタスクを開始します。Fargateタスクは、以下のファイルを含むDockerコンテナを作成します。 起動スクリプト.py Amazon OpenSearchに新しいOpenSearchインデックスの下に埋め込みを作成する役割を担う実装です。 車のマニュアル そうです。.
PDFサンプルでテストする
CloudFormationスタックが起動したら、マシンマニュアルのPDFファイルをS3バケットにドロップします。私はこちらからマシンマニュアルをダウンロードしました。イベントベースのトランスポートパイプラインの実行が完了すると、Amazon Open Searchクラスターには以下のプロファイルが含まれるはずです。 車のマニュアル 埋め込みは以下のとおりです。.
ステップ6 – Llmテキストサポートを備えたリアルタイムQ&A APIの実装
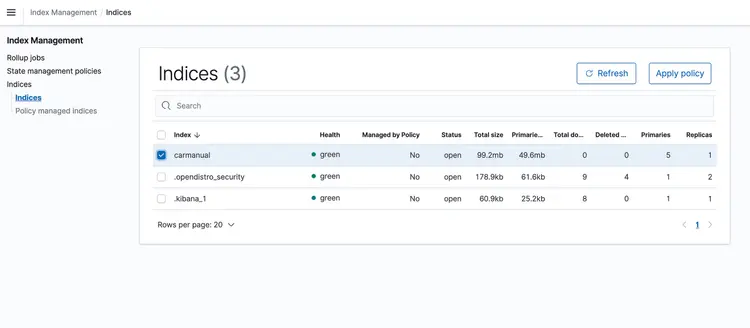
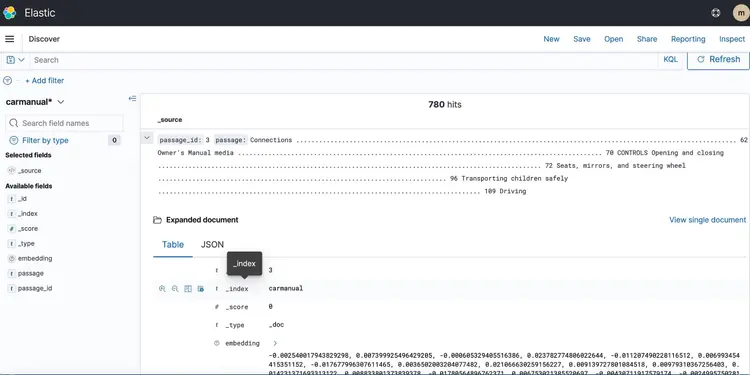
Amazon Open Search を利用したベクターデータベースにテキストを埋め込んだので、次のステップに進みましょう。ここでは、T5 Flan XXL LLM の機能を活用して、車のマニュアルに関するリアルタイムの回答を提供します。.
ベクトルデータベースに保存された埋め込み情報を用いて、LLMにコンテキストを提供します。このコンテキストにより、LLMは自動車マニュアルに関する質問を効果的に理解し、回答できるようになります。これを実現するために、LangChainと呼ばれるフレームワークを使用します。このフレームワークは、LLMが設計したリアルタイムのテキスト認識型質疑応答システムに必要な様々なコンポーネントの連携を簡素化します。.
ベクターデータベースに保存された埋め込みは、単語の意味と関係性を表し、意味的類似性に基づく計算を可能にします。埋め込みはテキストスニペットのベクトル表現を作成して意味と関係性を捉えますが、T5 Flan LLMは、リクエストやクエリに挿入されたコンテキストに基づいて、コンテキストに関連する回答を作成することに特化しています。目標は、ユーザーの質問に対応する埋め込みを作成し、ベクターデータベースに保存されている他の埋め込みとの類似性を測定することで、ユーザーの質問とテキストスニペットを一致させることです。.
テキストスニペットとユーザークエリをベクトルとして表現することで、数学的な計算を実行し、コンテキストを考慮した類似検索を実行できます。2つのデータポイント間の類似度を測定するために、多次元空間における距離指標を使用します。.
下の図は、LangChain と当社の T5 Flan LLM が提供するリアルタイム Q&A ワークフローを示しています。.
T5-Flan-XXL LLM によるリアルタイム Q&A サポートのグラフィカルな概要
APIを構築する
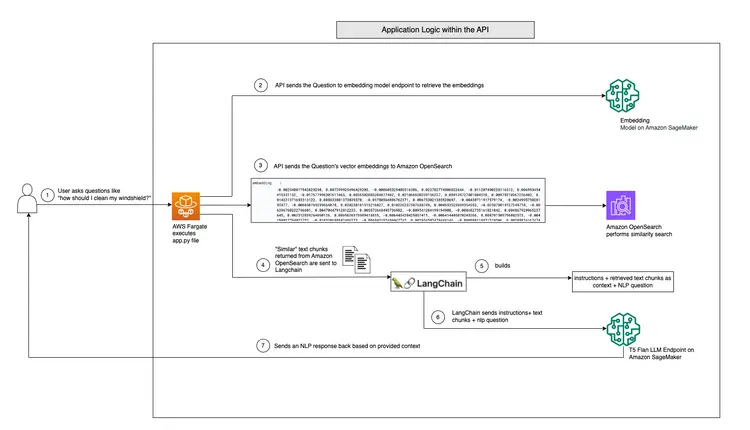
LangChainとT5 Flask LLMのワークフローを確認したところで、ユーザーの質問を受け付け、状況に応じた回答を提供するAPIコードを見てみましょう。このリアルタイムQ&A APIは、GitHubリポジトリのRAG-langchain-questionanswer-t5-llmフォルダに配置されており、コアロジックはapp.pyファイルにあります。このFlaskベースのアプリケーションは、質問に回答するための/qaルートを定義しています。.
ユーザーがAPIにクエリを送信すると、APIはTEXT_EMBEDDING_MODEL_ENDPOINT_NAME環境変数を使用してAmazon SageMakerエンドポイントを指定し、クエリを埋め込みと呼ばれる数値ベクトル表現に変換します。これらの埋め込みは、テキストの意味を捉えます。.
さらに、API は Amazon OpenSearch を活用してコンテキスト認識型の類似検索を実行し、ユーザークエリから取得した埋め込みに基づいて、OpenSearch ディレクトリワークガイドから関連するテキストスニペットを取得します。このステップの後、API は T5 Flan LLM エンドポイントを呼び出します。このエンドポイントは、T5FLAN_XXL_ENDPOINT_NAME 環境変数で識別され、Amazon SageMaker にもデプロイされています。エンドポイントは、Amazon OpenSearch から取得したテキストスニペットをコンテキストとして使用して応答を生成します。Amazon OpenSearch から取得したこれらのテキストスニペットは、T5 Flan LLM エンドポイントにとって貴重なコンテキストとして機能し、ユーザークエリに対して意味のある応答を提供できるようにします。API コードは、LangChain を使用してこれらすべてのやり取りを調整します。.
API用のDockerイメージをビルドして公開する
app.py のコードを理解したら、RAG-langchain-questionanswer-t5-llm フォルダから Dockerfile をビルドし、イメージを Amazon ECR にプッシュします。AWS CLI と Docker CLI を使用して Docker イメージをビルドし、Amazon ECR にプッシュします。以下のコマンドはすべて、正しい AWS アカウント番号に置き換えてください。.
認証トークンを取得し、AWS CLI でレジストリに対して Docker クライアントを認証します。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
次のコマンドを使用して Docker イメージをビルドします。.
docker build -t qa-container .
ビルドが完了したら、イメージにタグを付け、このリポジトリにイメージをプッシュできるようにします。
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
次のコマンドを実行して、このイメージを新しい Amazon ECR リポジトリにプッシュします。
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Docker イメージが Amazon ECR リポジトリにアップロードされると、次のイメージのようになります。
APIエンドポイントをホストするためのCloudFormationスタックを構築する
AWS コマンドラインインターフェース (CLI) を使用して、API を公開するための Fargate タスクをホストする Amazon ECS クラスター用の CloudFormation スタックを作成します。CloudFormation テンプレートは、GitHub リポジトリの Infrastructure/fargate-api-rag-llm-langchain.yaml にあります。AWS 環境に合わせてパラメータをオーバーライドする必要があります。aws cloudformation create-stack コマンドで更新する主要なパラメータは次のとおりです。
- DemoVPC: このパラメータは、サービスが実行される仮想プライベート クラウド (VPC) を指定します。.
- PublicSubnetIds: このパラメータには、ロードバランサとタスクが配置されるパブリックサブネット ID のリストが必要です。.
- IMAGENAME: qa コンテナの Amazon Elastic Container Registry (ECR) 内の Docker イメージ名を指定します。.
- TextEmbeddingModelEndpointName: ステップ 1 で Amazon SageMaker にデプロイされた Embeddings モデルのエンドポイント名を指定します。.
- T5FlanXXLEndpointName: ステップ 2 で Amazon SageMaker にデプロイした T5-FLAN エンドポイント名を設定します。.
- VectorDatabaseEndpoint: Amazon OpenSearch ドメインのエンドポイントアドレスを指定します。.
- VectorDatabaseUsername および VectorDatabasePassword: これらのパラメーターは、手順 4 で作成した OpenSearch クラスターにアクセスするために必要な資格情報です。.
- VectorDatabaseIndex: サービスデータを保存するAmazon OpenSearchのインデックス名を設定します。この例では「carmanual」というインデックス名を使用しています。.
CloudFormation スタックの作成を実行するには、パラメータ値を更新した後、次の AWS CLI コマンドを使用します。
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanual上記のCloudFormationスタックの実行に成功したら、AWSコンソールにアクセスし、ecs-questionanswer-llmスタックの「CloudFormation Outputs」タブにアクセスしてください。このタブには、APIエンドポイントなどの必要な情報が表示されます。出力例を以下に示します。
APIをテストする
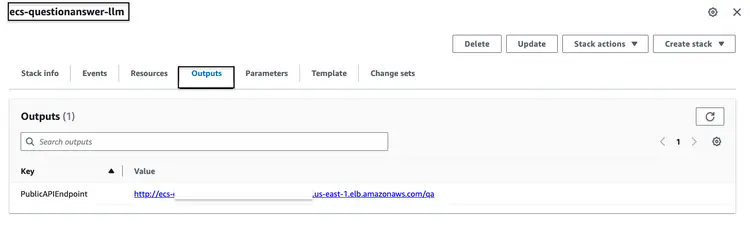
次のように curl コマンドを使用して API エンドポイントをテストできます。
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
以下のような応答が表示されます。
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
ステップ7 – チャットボットを統合したウェブサイトを作成して展開する
次に、フルスタックパイプラインの最終ステップに進み、HTMLウェブサイトに埋め込まれたチャットボットとAPIを統合します。このウェブサイトと埋め込みチャットボットのソースコードは、チャットボットとしてオープンソースのbotkit.jsを統合したindex.htmlで構成されるNodejsアプリケーションです。作業を簡素化するために、Dockerfileを作成し、homegrown_website_and_botフォルダにコードと一緒に配置しました。AWS CLIとDocker CLIを使用して、フロントエンドウェブサイト用のDockerイメージをビルドし、Amazon ECRにプッシュします。以下のすべてのコマンドで、正しい AWS アカウント番号に置き換えてください。.
認証トークンを取得し、AWS CLI でレジストリに対して Docker クライアントを認証します。.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
次のコマンドを使用して Docker イメージをビルドします。
docker build -t web-chat-frontend .
ビルドが完了したら、イメージにタグを付け、このリポジトリにイメージをプッシュできるようにします。
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
次のコマンドを実行して、このイメージを新しい Amazon ECR リポジトリにプッシュします。
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
ウェブサイトのDockerイメージをECRリポジトリにプッシュした後、Infrastructure\fargate-website-chatbot.yamlファイルを実行して、フロントエンド用のCloudFormationスタックを作成します。AWS環境に合わせてパラメータを上書きする必要があります。aws cloudformation create-stackコマンドで更新する主要なパラメータは次のとおりです。
- DemoVPC: このパラメータは、Web サイトがデプロイされる仮想プライベート クラウド (VPC) を指定します。.
- PublicSubnetIds: このパラメータには、Web サイトのロードバランサーとタスクが配置されるパブリックサブネット ID のリストが必要です。.
- IMAGENAME: ウェブサイトの Amazon Elastic Container Registry (ECR) にある Docker イメージの名前を入力します。.
- QUESTURL: ステップ6でデプロイしたAPIエンドポイントのURLを指定します。形式はhttp://です。 /qaです。.
CloudFormation スタックの作成を実行するには、パラメータ値を更新した後、次の AWS CLI コマンドを使用します。
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaステップ8 – Car Savvy AIアシスタントをチェックする
上記のCloudFormationスタックの構築に成功したら、AWSコンソールにアクセスし、ecs-website-chatbotスタックのCloudFormation出力タブにアクセスします。このタブには、フロントエンドに関連付けられたアプリケーションロードバランサー(ALB)のDNS名が表示されます。出力例を以下に示します。
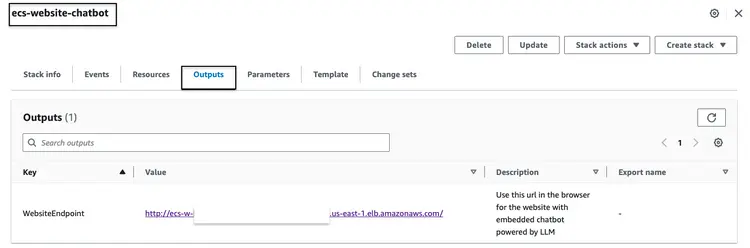
ブラウザでエンドポイントURLを呼び出して、ウェブサイトの表示を確認してください。埋め込まれたチャットボットに自然言語で質問してみましょう。例えば、「フロントガラスの掃除方法は?」「車台番号はどこで確認できますか?」「安全上の欠陥を報告するにはどうすればいいですか?」といった質問が考えられます。“
次は何?

以上で、LLM向けの本番環境対応パイプラインを構築し、フロントエンドのチャットボットや組み込みNLPと統合する方法をご紹介できたかと思います。オープンソーステクノロジー、アナリティクス、機械学習、AWSの活用に関する他に読みたい記事があれば、ぜひ教えてください。
学習を続ける中で、埋め込み、ベクターデータベース、LangChain、その他いくつかのLLMについて深く掘り下げてみることをお勧めします。これらはAmazon SageMaker JumpStartだけでなく、このチュートリアルで使用したAmazon OpenSearch、Dockerコンテナ、FargateなどのAWSツールでも利用可能です。これらのテクノロジーを習得するための次のステップをいくつかご紹介します。
- Amazon SageMaker: SageMaker を使いながら、SageMaker が提供する他のアルゴリズムにも慣れてください。.
- AMAZON-OPEN SEARCH: K-NNアルゴリズムとその他の距離アルゴリズムについて学ぶ
- Langchain: LangChain は、LLM を使用してアプリケーションの作成を簡素化するように設計されたフレームワークです。.
- 埋め込み: 埋め込みとは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。.
- Amazon SageMaker JumpStart: SageMaker JumpStart は、機械学習を始めるのに役立つ、さまざまな問題タイプに対応する事前トレーニング済みのオープンソースモデルを提供します。.
消去
- AWS CLI にログインします。AWS CLI がこれらのアクションを実行するために必要な権限で適切に設定されていることを確認してください。.
- 次のコマンドを実行して、Amazon S3 バケットから PDF ファイルを削除します。バケット名を実際の Amazon S3 バケット名に置き換え、必要に応じて PDF ファイルへのパスを調整してください。.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
CloudFormation スタックを削除します。スタック名を実際の CloudFormation スタックの名前に置き換えます。.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2結果
このチュートリアルでは、AWSテクノロジーとオープンソースツールを使用して、フルスタックのQ&Aチャットボットを構築しました。Amazon OpenSearchをベクターデータベースとして統合し、GPT-J 6B FP16埋め込みモデルとLangchainをLLMと連携させました。このチャットボットは、非構造化ドキュメントから洞察を抽出します。.









