









導入
Apache Kafka は、様々なセキュリティプロトコルと認証ワークフローをサポートしており、許可されたユーザーとアプリケーションのみがクラスターに接続できるようにします。デフォルト設定では、Kafka は誰でもアクセスを許可しますが、セキュリティチェックは有効化されていません。調査や開発には便利ですが、本番環境でのデプロイメントは、外部に公開する前に適切にセキュリティ保護する必要があります。また、スムーズな運用を確保し、潜在的な障害を防ぐために、環境を監視する必要があります。.
このチュートリアルでは、TLSトラフィック暗号化とSASL認証を設定し、標準的なユーザー名とパスワードによるログインフローを提供することで、Kafkaインストールを強化します。提供されているプロデューサースクリプトとコンシューマースクリプトを設定して、安全なクラスターに接続する方法を学びます。さらに、Kafkaメトリクスをエクスポートし、Grafanaで可視化する方法を学びます。さらに、AKHQが提供する使いやすいWebベースのインターフェースを介して、クラスターノードとトピックにアクセスする方法も学びます。.
前提条件
- 少なくとも4GBのRAMと2つのプロセッサを搭載したドロップレット。Ubuntu Serverの場合は、初期サーバーセットアップの手順に従ってセットアップしてください。.
- Apache Kafka が Droplet にインストールされ、設定されています。セットアップ手順については、「Kafka 入門」チュートリアルをご覧ください。手順 1 と 2 のみ完了してください。.
- Javaが鍵と証明書を管理する方法を理解しましょう。詳細については、「Java Keytool Essentials: Javaキーストアの操作」チュートリアルをご覧ください。.
- Grafanaはサーバーまたはローカルマシンにインストールされています。手順については、UbuntuにGrafanaをインストールしてセキュリティを確保する方法に関するチュートリアルをご覧ください。最初の4つの手順を完了するだけで済みます。.
- 完全に登録されたドメイン名は、ドロップレットを指します。このチュートリアルでは、your_domain を一貫して使用し、Grafana で必要なドメイン名と同じものを指します。ドメイン名は、Namecheap で購入することも、Freenom で無料で取得することも、お好みのドメインレジストラを利用することもできます。.
ステップ1 – Kafkaセキュリティプロトコルを構成する
標準設定では、Kafka はリクエストの送信元を確認することなく誰でも接続できます。つまり、クラスターはデフォルトで誰でもアクセスできる状態です。これはローカルマシンやプライベートインストールのメンテナンス負担を軽減するため、テストには有効ですが、本番環境やパブリックレベルの Kafka インストールでは、不正アクセスを防ぐためのセキュリティ機能を有効にする必要があります。.
このステップでは、Kafkaブローカーとコンシューマー間のトラフィックにTLS暗号化を使用するように設定します。また、クラスターへの接続時の認証フレームワークとしてSASLを設定します。.
TLS証明書の生成と保存
TLSの設定に必要な証明書と鍵を生成するには、Confluent Platform Security Toolsリポジトリにあるスクリプトを使用します。まず、以下のコマンドを実行して、スクリプトをホームディレクトリにクローンします。
git clone https://github.com/confluentinc/confluent-platform-security-tools.git ~/kafka-sslそれにアクセスしてください:
cd ~/kafka-ssl使用するスクリプトはkafka-generate-ssl-automatic.shで、環境変数として国、州、組織、都市を入力する必要があります。これらのパラメータは証明書の生成に使用されますが、その内容は重要ではありません。また、作成されるJavaトラストとキーストアを保護するために、パスワードも入力する必要があります。.
必要な環境変数を設定するには、your_tls_password を希望の値に置き換えて、次のコマンドを実行します。
export COUNTRY=US
export STATE=NY
export ORGANIZATION_UNIT=SE
export CITY=New York
export PASSWORD=your_tls_passwordパスワードは 6 文字以上である必要があることに注意してください。.
次のコマンドを実行して、スクリプトに実行権限を付与します。
chmod +x kafka-generate-ssl-automatic.sh次に、これを実行して必要なファイルを生成します。
./kafka-generate-ssl-automatic.sh大量の出力があります。完了したら、ディレクトリ内のファイルを一覧表示します。
ls -l出力は次のようになります。
Outputrw-rw-r-- 1 kafka kafka 964 May 13 09:33 README.md
-rw-rw-r-- 1 kafka kafka 1063 May 13 09:34 cert-file
-rw-rw-r-- 1 kafka kafka 1159 May 13 09:34 cert-signed
-rwxrw-r-- 1 kafka kafka 6016 May 13 09:33 kafka-generate-ssl-automatic.sh
-rwxrwxr-x 1 kafka kafka 7382 May 13 09:33 kafka-generate-ssl.sh
drwxrwxr-x 2 kafka kafka 4096 May 13 09:34 keystore
-rw-rw-r-- 1 kafka kafka 184929 May 13 09:33 single-trust-store-diagram.pages
-rw-rw-r-- 1 kafka kafka 36980 May 13 09:33 single-trust-store-diagram.pdf
drwxrwxr-x 2 kafka kafka 4096 May 13 09:34 truststore証明書、信頼、およびキーストアが正常に作成されたことがわかります。.
TLS および SASL 用の Kafka の設定
TLS 暗号化を有効にするために必要なファイルが揃ったので、Kafka がそれらを使用するように構成し、SASL を使用してユーザーを認証します。.
インストールディレクトリのconfig/kraftセクションにあるserver.propertiesファイルを修正します。このファイルは、前提条件としてKafkaのホームディレクトリにインストールされています。以下のコマンドを実行してファイルにアクセスします。
cd ~/kafkaメイン構成ファイルを編集用に開きます。
nano config/kraft/server.properties
次の行を見つけます。
...
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:9092次のように変更し、PLAINTEXT を BROKER に置き換えます。
...
listeners=BROKER://:9092,CONTROLLER://:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=BROKER
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=BROKER://localhost:9092次に、listener.security.protocol.map の行を見つけます。
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL次の値を持つ定義を埋め込んで、BROKER を SASL_SSL にマップします。
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSLここでは、リスナーで使用した BROKER エイリアス定義を追加し、それを SASL_SSL にマッピングしました。これは、SSL (TLS の旧称) と SASL の両方を使用する必要があることを示しています。.
次に、ファイルの末尾に移動して、次の行を追加します。
ssl.truststore.location=/home/kafka/kafka-ssl/truststore/kafka.truststore.jks
ssl.truststore.password=your_tls_password
ssl.keystore.location=/home/kafka/kafka-ssl/keystore/kafka.keystore.jks
ssl.keystore.password=your_tls_password
ssl.key.password=your_tls_password
ssl.client.auth=required
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.controller.protocol=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
authorizer.class.name=org.apache.kafka.metadata.authorizer.StandardAuthorizer
allow.everyone.if.no.acl.found=false
super.users=User:adminまず、作成したトラストストアとキーストアの場所とパスワードを定義します。ssl.client.auth パラメータを required に設定し、Kafka が有効な TLS 証明書を提示しない接続を拒否するように指示します。次に、SASL メカニズムを PLAIN に設定して有効化します。PLAIN は PLAINTEXT とは異なり、暗号化された接続を使用する必要があり、どちらもユーザー名とパスワードの組み合わせを使用します。.
最後に、StandardAuthorizer を認可クラスとして設定します。このクラスは、後ほど作成する構成ファイルと照合して資格情報を確認します。次に、allow.everyone.if.no.acl.found パラメータを false に設定し、不適切な資格情報を持つ接続のアクセスを制限します。また、クラスターで管理タスクを実行するには少なくとも 1 人の admin ユーザーが必要なため、admin ユーザーをスーパーユーザーとして選択します。.
your_tls_password を前のセクションでスクリプトに入力したパスワードに置き換え、ファイルを保存して閉じることを忘れないでください。.
Kafka の設定が完了したら、接続に必要な資格情報を定義するファイルを作成する必要があります。Kafka は、認証ワークフローを実装するためのフレームワークである Java 認証・承認サービス (JAAS) をサポートしており、JAAS 形式の資格情報定義を受け入れます。.
これらはconfig/kraftにあるkafka-server-jaas.confというファイルに保存します。以下のコマンドを実行してファイルを作成し、編集用に開きます。
nano config/kraft/kafka-server-jaas.conf次の行を追加します。
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin"
user_admin="admin";
};ユーザー名とパスワードは、クラスター内の複数のノードが存在する場合にブローカー間の通信に使用される主要な認証情報を指定します。user_admin 行は、ユーザー名が admin、パスワードが admin のユーザーを定義し、このユーザーは外部からブローカーに接続できます。完了したら、ファイルを保存して閉じます。.
Kafka は kafka-server-jaas.conf ファイルを認識している必要があります。このファイルはメインの設定を完了するからです。kafka systemd サービスの設定を変更し、その参照を渡す必要があります。以下のコマンドを実行して、サービスを編集用に開きます。
sudo systemctl edit --full kafka–full を渡すと、サービスの全コンテンツにアクセスできます。ExecStart 行を見つけてください。
...
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/kraft/server.properties > /home/kafka/kafka/kafka.log 2>&1'
...その上に次の行を追加すると、次のようになります。
...
User=kafka
Environment="KAFKA_OPTS=-Djava.security.auth.login.config=/home/kafka/kafka/config/kraft/kafka-server-jaas.conf"
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/kraft/server.properties > /home/kafka/kafka/kafka.log 2>&1'
...これにより、設定ファイルのjava.security.auth.login.configパラメータがJAAS設定ファイルのパスに設定され、メインのKafka設定ファイルから分離されます。完了したら、ファイルを保存して閉じます。以下のコマンドを実行して、サービス定義をリロードします。
sudo systemctl daemon-reload次に、Kafka を再起動します。
sudo systemctl restart kafkaこれで、Kafka インストールの TLS 暗号化と SASL 認証が構成されました。次に、提供されているコンソール スクリプトを使用して接続する方法を学習します。.
ステップ2 – 安全なクラスターに接続する
このステップでは、提供されているコンソール スクリプトを使用して JAAS 構成ファイルを使用して安全な Kafka クラスターに接続する方法を学習します。.
メッセージの生成と消費のトピックを操作するために提供されるスクリプトも内部で Java を使用するため、信頼ストアとキー ストアの場所と SASL 認証を記述する JAAS 構成を受け入れます。.
この設定は、ホームディレクトリのclient-jaas.confというファイルに保存します。ファイルを作成し、編集用に開きます。
nano ~/client-jaas.conf次の行を追加します。
security.protocol=SASL_SSL ssl.truststore.location=/home/kafka/kafka-ssl/truststore/kafka.truststore.jks ssl.truststore.password=your_tls_password ssl.keystore.location=/home/kafka/kafka-ssl/keystore/kafka.keystore.jks ssl.keystore.password=your_tls_password sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin"; ssl.endpoint.identification.algorithm=
前回と同様に、プロトコルをSASL_SSLに設定し、作成したキーストアとトラストストアのパスとパスワードを指定します。次に、SASLメカニズムをPLAINに設定し、ユーザーadminの資格情報を入力します。接続の問題を回避するため、ssl.endpoint.identification.algorithmパラメータを明示的にクリアします。これは、初期スクリプトが証明書エンドポイントとして実行マシンのホスト名を設定するためです。このホスト名が正しくない可能性があります。.
your_tls_password を適切な値に置き換え、ファイルを保存して閉じます。.
このファイルをスクリプトに渡すには、--command-config パラメータを使用します。以下のコマンドでクラスター内に新しいトピックを作成します。
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic new_topic --command-config ~/client-jaas.confコマンドは正常に実行されるはずです:
Output...
Created topic new_topic.作成されたことを確認するには、次のコマンドを実行してクラスター内のすべてのスレッドを一覧表示します。
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list --command-config ~/client-jaas.conf出力には new_topic が存在することが示されます。
Output__consumer_offsets
new_topic
...このセクションでは、トラフィックにTLS暗号化を使用し、ユーザー名とパスワードの組み合わせによる認証にSASLを使用するようにKafkaインストールを設定しました。次に、Prometheusを使用してJMX経由でさまざまなKafkaメトリックをエクスポートする方法を学びます。.
ステップ3 – Prometheusを使用してKafka JMXメトリクスを監視する
このセクションでは、Prometheusを使用してKafkaのメトリクスを収集し、Grafanaでクエリできるようにします。そのためには、Kafka用のJMXエクスポーターを設定し、Prometheusに接続する必要があります。.
Java Management Extensions (JMX) は、Java アプリケーション向けのフレームワークです。開発者は、アプリケーション実行時のパフォーマンスに関する汎用メトリクスとカスタムメトリクスを標準形式で収集できます。Kafka は Java で記述されているため、JMX プロトコルをサポートし、トピックやブローカーのステータスなどのカスタムメトリクスを JMX プロトコル経由で公開します。.KafkaとPrometheusの設定
続行する前に、Prometheusをインストールする必要があります。Ubuntuマシンではaptを使用できます。リポジトリは以下を実行してインストールできます。
sudo apt update次に、Prometheus をインストールします。
sudo apt install prometheus -yその他のプラットフォームの場合は、公式ウェブサイトのインストール手順に従ってください。.
インストールが完了したら、Prometheus用のJMXエクスポーターライブラリをKafkaインストールに追加する必要があります。バージョンページに移動し、名前にjavaagentが含まれる最新バージョンを選択してください。執筆時点での最新バージョンは0.20.0です。以下のコマンドを使用して、Kafkaがインストールされているlibs/ディレクトリにダウンロードしてください。
curl https://repo.maven.apache.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.20.0/jmx_prometheus_javaagent-0.20.0.jar -o ~/kafka/libs/jmx_prometheus_javaagent.jarJMX エクスポート ライブラリが Kafka によって選択されるようになりました。.
エクスポーターを有効にする前に、Prometheusにレポートするメトリクスを指定する必要があります。この設定は、Kafkaインストールのconfig/ディレクトリにあるjmx-exporter.ymlというファイルに保存します。JMXエクスポータープロジェクトは適切なデフォルト設定を提供しているので、以下のコマンドを実行して、Kafkaインストールのconfig/ディレクトリにjmx-exporter.ymlというファイルとして保存します。
curl https://raw.githubusercontent.com/prometheus/jmx_exporter/main/example_configs/kafka-2_0_0.yml -o ~/kafka/config/jmx-exporter.yml次に、Kafka systemd サービスを変更してエクスポーターを有効にする必要があります。エクスポーターとその設定を含めるには、KAFKA_OPTS 環境変数を変更する必要があります。以下のコマンドを実行してサービスを編集します。
sudo systemctl edit --full kafka環境行を次のように変更します。
Environment="KAFKA_OPTS=-Djava.security.auth.login.config=/home/kafka/kafka/config/kraft/kafka-server-jaas.conf -javaagent:/home/kafka/kafka/libs/jmx_prometheus_javaagent.jar=7075:/home/kafka/kafka/config/jmx-exporter.yml"
ここでは、-javaagent 引数を使用して、JMX エクスポーターをその構成で初期化します。.
完了したら、ファイルを保存して閉じ、次のコマンドを実行して Kafka を起動します。
sudo systemctl restart kafka1 分後、ポート 7075 が使用中かどうかを照会して、JMX エクスポーターが実行されていることを確認します。
sudo ss -tunelp | grep 7075出力は次のようになります。
Outputtcp LISTEN 0 3 *:7075 *:* users:(("java",pid=6311,fd=137)) uid:1000 ino:48151 sk:8 cgroup:/system.slice/kafka.service v6only:0 <->この行は、JMX エクスポーターを指す Kafka サービスによって開始された Java プロセスによってポート 7075 が使用されていることを示します。.
次に、エクスポートされたJMXメトリックを監視するようにPrometheusを設定します。メインの設定ファイルは/etc/prometheus/prometheus.ymlにあるので、開いて編集します。
sudo nano /etc/prometheus/prometheus.yml次の行を見つけます。
...
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
scrape_timeout: 5s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: node
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: ['localhost:9100']Prometheus が監視するエンドポイントを指定する scrape_configs セクションで、Kafka メトリックをスクレイピングするための新しいセクションを追加します。
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
scrape_timeout: 5s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: node
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: ['localhost:9100']
- job_name: 'kafka'
static_configs:
- targets: ['your_domain:7075']Kafka ジョブには、JMX エクスポート エンドポイントを指すターゲットがあります。.
your_domain をドメイン名に置き換え、ファイルを保存して閉じてください。その後、以下のコマンドを実行してPrometheusを起動してください。
sudo systemctl restart prometheusブラウザでドメインのポート9090にアクセスします。Prometheusインターフェースにアクセスします。ステータスセクションで「ターゲット」をクリックすると、ジョブの一覧が表示されます。
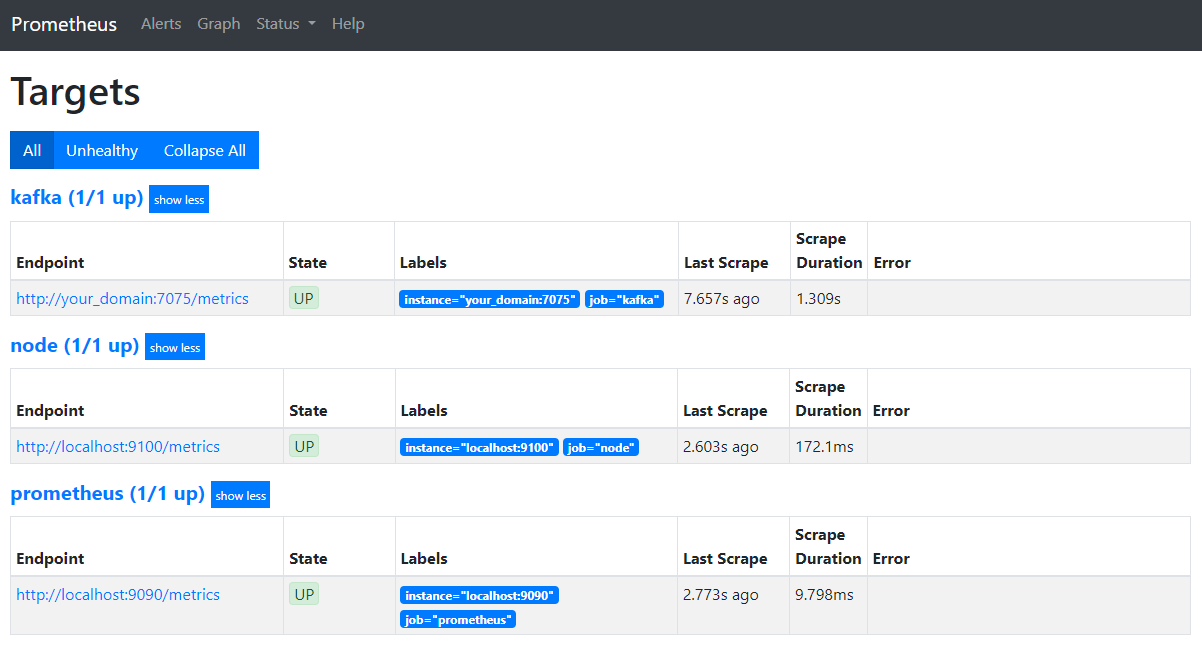
PrometheusがKafkaジョブを引き継ぎ、メトリクスのスクレイピングを開始していることに注意してください。次に、Grafanaでメトリクスにアクセスする方法を学びます。.
Grafanaでメトリクスをクエリする
前提条件として、DropletにGrafanaをインストールし、your_domainに配置している必要があります。ブラウザでGrafanaにアクセスし、サイドバーの「接続」セクションで「新しい接続を追加」をクリックし、検索フィールドに「Prometheus」と入力してください。.
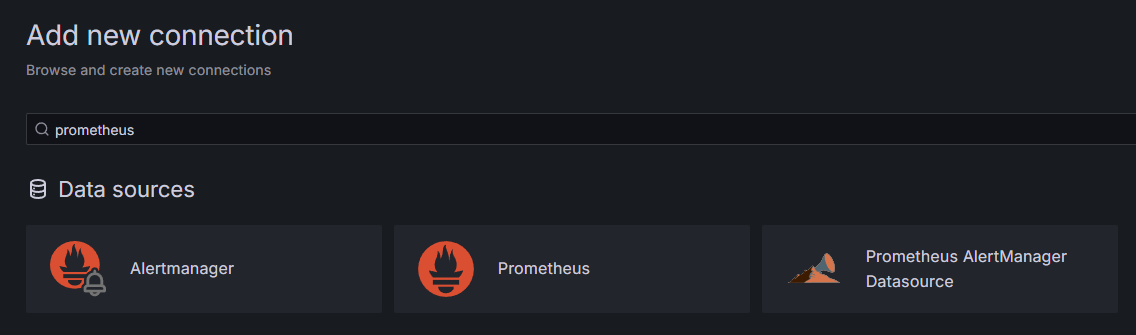
Prometheusをクリックし、右上の「新しいデータソースを追加」ボタンをクリックします。Prometheusインスタンスのアドレスを入力するよう求められます。
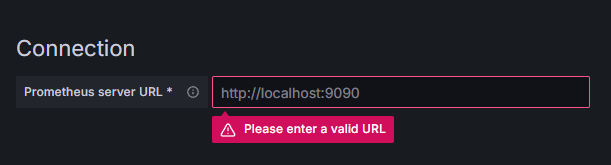
http://your_domain_name:9090 と入力し、実際のドメイン名を置き換えて下にスクロールし、「保存してテスト」を押します。成功メッセージが表示されます。

Prometheus接続がGrafanaに追加されました。サイドバーの「Explore」をクリックすると、メトリックを選択するように求められます。「kafka_」と入力すると、クラスターに関連するすべてのメトリックが一覧表示されます。
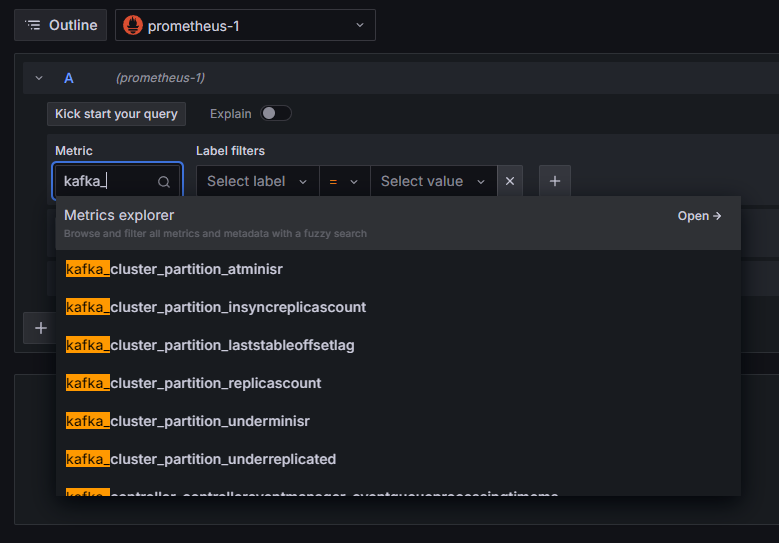
例えば、各パーティションの内部ディスクログのサイズを示す kafka_log_log_size メトリックを選択し、右上の「クエリを実行」をクリックします。利用可能なトピックごとに、時間の経過に伴うサイズの変化が表示されます。
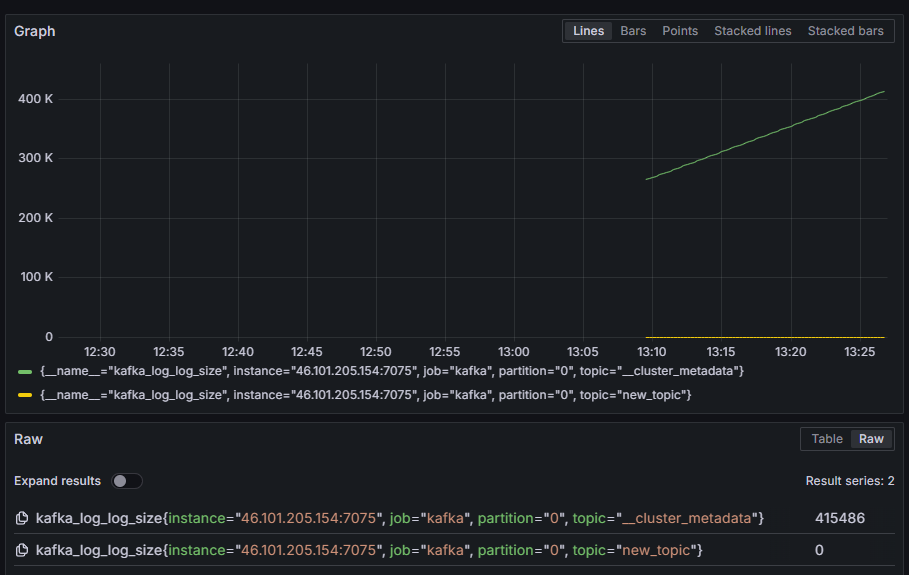
ここまでで、Kafkaが提供するJMXエクスポーターメトリクスを設定し、それらをスクレイピングするようにPrometheusを設定しました。その後、GrafanaからPrometheusに接続し、Kafkaメトリクスに対してクエリを実行しました。次は、Webインターフェースを使用してKafkaクラスターを管理する方法を学びます。.
ステップ4 – AKHQを使用したKafkaクラスターの管理
このステップでは、Kafkaクラスターを管理するためのWebアプリケーションであるAKHQの設定と使用方法を学習します。AKHQを使用すると、トピック、パーティション、コンシューマーグループ、設定パラメータの一覧表示と操作、そしてトピックからのメッセージの送受信を単一の場所から行うことができます。.
実行ファイルとその設定ファイルはakhqというディレクトリに保存します。以下のコマンドを実行して、ホームディレクトリに作成してください。
mkdir ~/akhqそれにアクセスしてください:
cd ~/akhqブラウザで公式リリースページにアクセスし、最新のJARファイルへのリンクをコピーしてください。執筆時点での最新バージョンは0.24.0です。以下のコマンドを実行して、ホームディレクトリにダウンロードしてください。
curl -L https://github.com/tchiotludo/akhq/releases/download/0.24.0/akhq-0.24.0-all.jar -o ~/akhq/akhq.jarAKHQのダウンロードが完了し、クラスターに接続するための設定を定義する準備が整いました。設定はakhq-config.ymlというファイルに保存します。以下のコマンドを実行してファイルを作成し、編集用に開きます。
nano ~/akhq/akhq-config.yml次の行を追加します。
akhq:
connections:
localhost-sasl:
properties:
bootstrap.servers: "localhost:9092"
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin";
ssl.truststore.location: /home/kafka/kafka-ssl/truststore/kafka.truststore.jks
ssl.truststore.password: secret
ssl.keystore.location: /home/kafka/kafka-ssl/keystore/kafka.keystore.jks
ssl.keystore.password: secret
ssl.key.password: secret
ssl.endpoint.identification.algorithm: ""これは、SASLおよびTLSパラメータを指定してlocalhost:9092のクラスターを指定する基本的なAKHQ設定です。必要な数の接続を定義できるため、複数のクラスターを同時にサポートすることもできます。これにより、AKHQはKafka管理において汎用性を高めます。完了したら、ファイルを保存して閉じてください。.
次に、AKHQをバックグラウンドで実行するためのsystemdサービスを定義する必要があります。systemdサービスは継続的に起動、停止、再起動できます。.
サービス設定は、systemdがサービスを保存する/lib/systemd/systemディレクトリ内のcode-server.serviceというファイルに保存します。テキストエディタを使ってファイルを作成してください。
sudo nano /etc/systemd/system/akhq.service次の行を追加します。
[Unit]
Description=akhq
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c 'java -Dmicronaut.config.files=/home/kafka/akhq/akhq-config.yml -jar /home/kafka/akhq/akhq.jar'
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetまず、サービスの説明を指定します。次に、[Service] フィールドでサービスの種類(「simple」はコマンドを単純に実行することを意味します)を定義し、実行するコマンドを指定します。また、実行ユーザーとして kafka を指定し、サービスが終了した場合に自動的に再起動するように指定します。.
[Install] セクションでは、サーバーにログインできるときにこのサービスを開始するようにシステムに指示します。完了したら、ファイルを保存して閉じます。.
次のコマンドを実行してサービス設定を読み込みます。
sudo systemctl daemon-reload次のコマンドを実行して AKHQ サービスを開始します。
sudo systemctl start akhq次に、ステータスを表示して、正しく起動したことを確認します。
sudo systemctl status akhq出力は次のようになります。
Output● akhq.service - akhq
Loaded: loaded (/etc/systemd/system/akhq.service; disabled; vendor preset: enabled)
Active: active (running) since Wed 2024-05-15 07:37:10 UTC; 3s ago
Main PID: 3241 (sh)
Tasks: 21 (limit: 4647)
Memory: 123.3M
CPU: 4.474s
CGroup: /system.slice/akhq.service
├─3241 /bin/sh -c "java -Dmicronaut.config.files=/home/kafka/akhq/akhq-config.yml -jar /home/kafka/akhq/akhq.jar"
└─3242 java -Dmicronaut.config.files=/home/kafka/akhq/akhq-config.yml -jar /home/kafka/akhq/akhq.jarAKHQは現在バックグラウンドで実行されています。デフォルトではポート8080で表示されます。ブラウザでそのポートのドメインにアクセスしてアクセスしてください。トピックのリストが表示されたデフォルトのビューが表示されます。
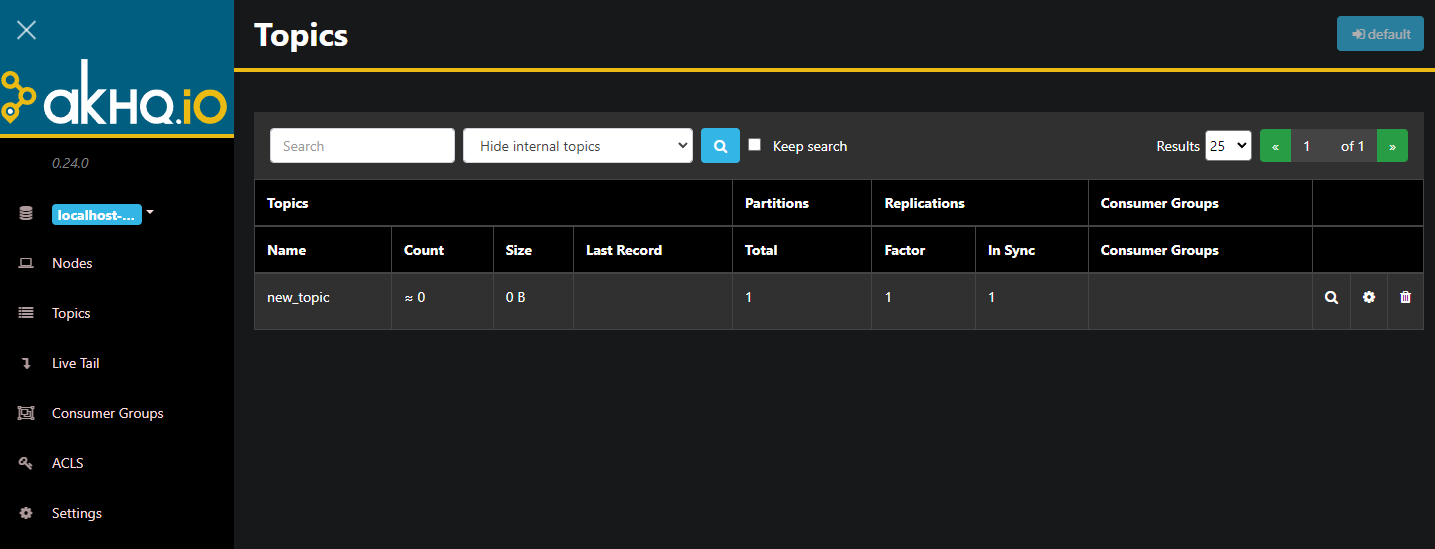
表内のトピックの行をダブルクリックすると、詳細ビューにアクセスできます。
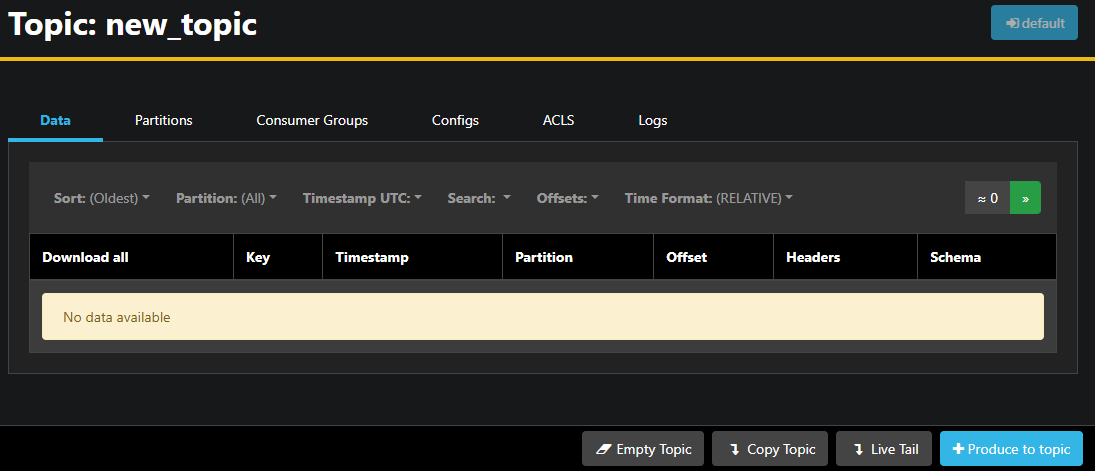
AKHQでは、トピック内のメッセージ、パーティション、コンシューマーグループ、およびそれらの設定を表示できます。また、右下のボタンを使用してトピックを空にしたり、コピーしたりすることもできます。.
new_topic トピックは空なので、[トピックに生成] ボタンを押します。これにより、新しいメッセージのパラメータを選択するためのインターフェイスが開きます。
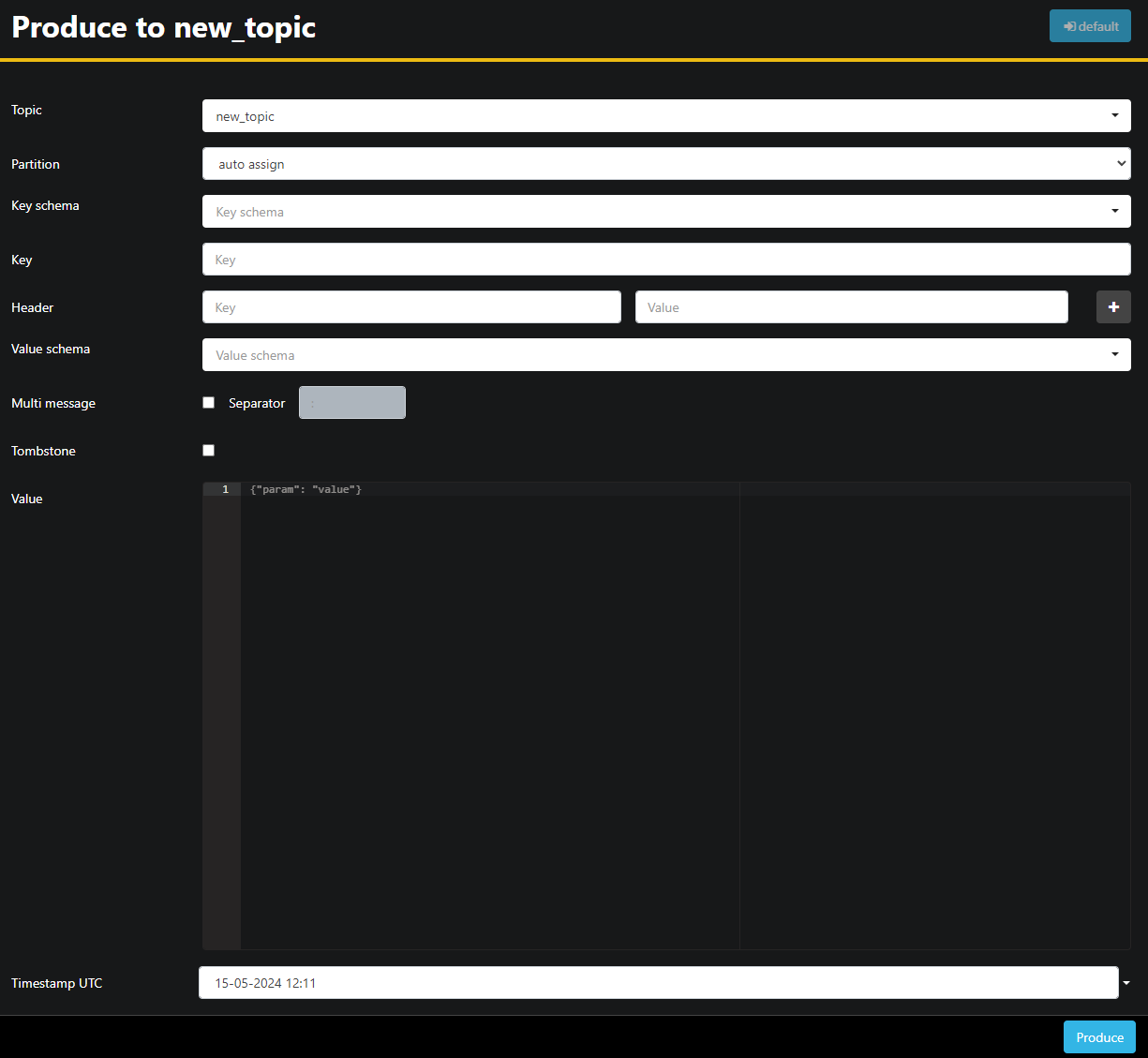
AKHQが自動的にトピック名を入力します。「値」フィールドに「Hello World!」と入力し、「出力」を押します。メッセージがKafkaに送信され、「データ」タブに表示されます。
メッセージの内容が非常に長い場合があるため、AKHQ では最初の行のみが表示されます。メッセージ全体を表示するには、行の後の暗い領域をクリックして表示してください。.
左側のサイドバーで「ノード」をクリックすると、クラスター内のブローカーの一覧が表示されます。現在、クラスターは1つのノードのみで構成されています。

ノードをダブルクリックするとその構成が開き、リモートで設定を変更できるようになります。
変更が完了したら、右下にある「設定を更新」ボタンを押して適用できます。同様に、各テーマにアクセスして「設定」タブに移動すると、各テーマの設定を確認・変更できます。.
このセクションでは、Kafka ノードとトピックをリモートで管理および表示するための使いやすいインターフェースを提供する Web アプリケーション AKHQ をセットアップしました。AKHQ を使用すると、トピック内のメッセージの生成と消費、およびトピックとノードの両方の設定パラメータのリアルタイム更新が可能になります。.
結果
このチュートリアルでは、暗号化にTLS、ユーザー認証にSASLを設定し、Kafka環境のセキュリティを確保しました。また、Prometheusを使用してメトリックのエクスポートを設定し、Grafanaで可視化しました。さらに、Kafkaクラスターを管理するためのWebアプリケーションであるAKHQの使い方を学びました。.









