









導入
従来のデータ処理・受信方法(バッチ処理やポーリングなど)は、現代のアプリケーションで使用されるマイクロサービスにおいては非効率的です。これらの方法は膨大なデータチャンクを処理するため、処理の最終結果が遅れ、処理前に膨大な量のデータが蓄積されることになります。ワーカーの同期に必要な複雑さが増し、リソースを最大限に活用しているにもかかわらず、一部のワーカーが十分に活用されない可能性があります。一方、クラウドコンピューティングはオンプレミスのリソースを迅速に拡張できるため、受信データを複数のワーカーに並列に委任することで、リアルタイムに処理できます。.
イベントストリーミングは、異なるシステム間でのデータフローを維持しながら、受信イベントを柔軟に収集し、処理を委任するアプローチです。受信データを即時処理するようにスケジュール設定することで、リソースを最大限に活用し、リアルタイムの応答性を確保します。イベントストリーミングはプロデューサーとコンシューマーを分離し、現在の負荷に応じてそれぞれの数を均等に配分できます。これにより、動的な現実世界の状況に即座に対応できます。.
このような応答性は、金融取引、決済監視、交通監視といった分野で特に重要になります。例えば、Uberはイベントストリーミングを使用して数百のマイクロサービスを接続し、乗客とドライバー間のアプリケーションからイベントデータをリアルタイムで送信し、後で分析できるようにアーカイブしています。.
イベントブロードキャストでは、従来ワーカーが一定間隔でデータのバッチを待機する代わりに、イベントブローカーがイベント発生と同時にコンシューマー(通常はマイクロサービス)に通知し、イベントデータを提供します。イベントブローカーはイベントのルーティング、受信、配信を処理します。また、ワーカーがイベント処理に失敗したり、イベント処理を拒否したりした場合でも、フォールトトレランスを提供します。.
このコンセプトペーパーでは、イベントストリーミングのアプローチとその利点について考察します。また、オープンソースのイベントブローカーであるApache Kafkaを紹介し、このアプローチにおけるその役割を検証します。.
イベントフローアーキテクチャ
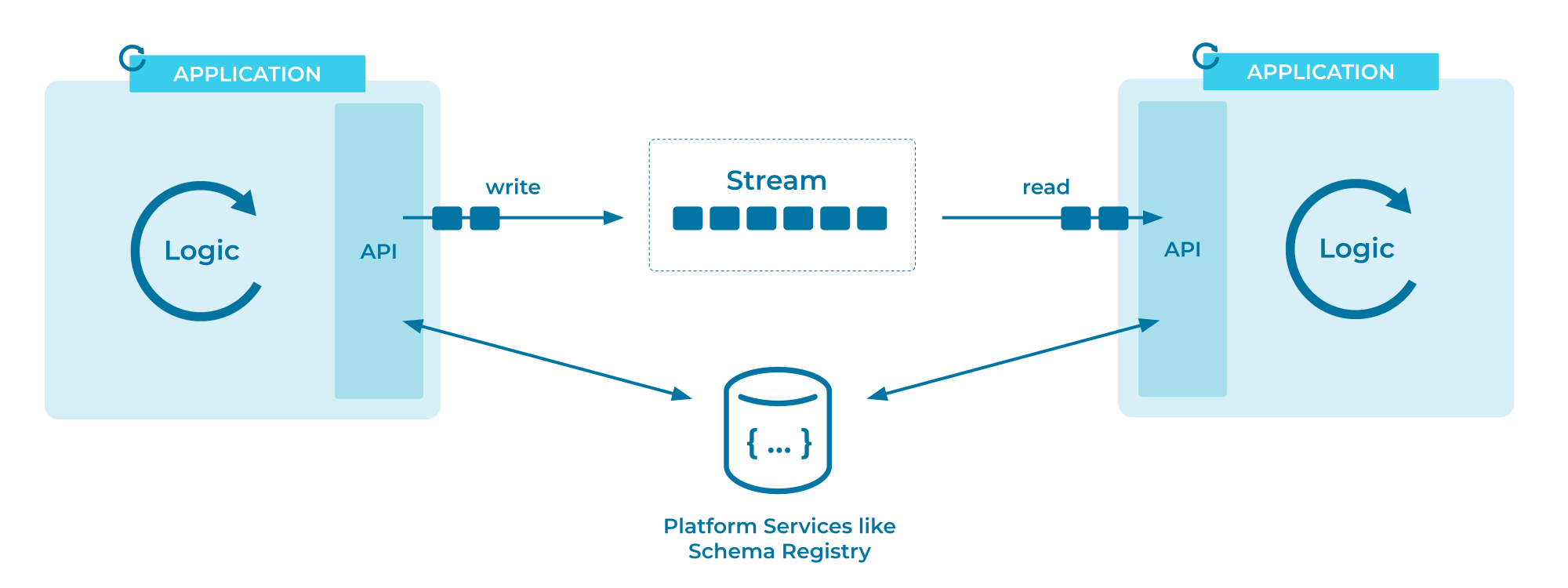
イベントフローは、本質的にはpub/subアーキテクチャパターンの実装です。一般的に、pub/subパターンには以下の要素が含まれます。
- メッセージ (通信するデータを含む) の対象となるトピック。.
- メッセージを発信する出版社
- メッセージを受信して対応する購読者
- パブリッシャーからのメッセージを受け取り、最も効率的な方法でサブスクライバーに配信するメッセージ ブローカー。
トピックは、メッセージが関連付けられるカテゴリのようなものです。トピックはメッセージのシーケンスを永続的に保存し、新しいメッセージが常にシーケンスの末尾に追加されることを保証します。メッセージがトピックに追加されると、後で変更することはできません。.
イベントブロードキャストの場合も、前提は同様ですが、より特殊です。
- イベントと関連メタデータはメッセージとして送信されます。
- トピック内のイベントは通常、到着時間順に並べられます。
- サブスクライバー (コンシューマーとも呼ばれます) は、スレッド内の任意の時点から現在の瞬間までのイベントをブロードキャストできます。.
- 実際の pub/sub とは異なり、トピックのイベントは、特定の期間保持することも、無期限に (アーカイブとして) 保持することもできます。.
イベントフローは、イベントの性質についていかなる制約も仮定もしません。基盤となるブローカーにとって、イベントフローとはプロデューサーから何かが起こったことが通知されたことを意味します。実際に何が起こったかは、実装者が定義し、意味づける責任があります。そのため、ブローカーの観点からは、イベントはメッセージまたはレコードと同義に呼ばれます。.
説明のために、Confluent ドキュメントの Kafka イベント ストリーム アーキテクチャの詳細な図を以下に示します。
コンシューマがブローカーからデータを取得する方法には、プッシュとプルの2つのモデルがあります。プッシュとは、イベントブローカーが最初に利用可能なコンシューマにデータを送信するプロセスを開始することを指し、プルとは、コンシューマがブローカーに後続の利用可能なレコードを要求することを意味します。この区別は一見無害に思えますが、実際にはプルの方が好まれます。.
プッシュが広く利用されていない主な理由の一つは、ブローカーがコンシューマーが実際にイベントに基づいてアクションを実行できるかどうか確信できないことです。そのため、イベントをトピックに保存する必要があるにもかかわらず、不必要に複数回送信してしまう可能性があります。ブローカーは、スループットを向上させるためにイベントをバッチ処理することも検討する必要があります。これは、イベントをできるだけ早くブロードキャストするという考え方とは逆のことです。.
コンシューマーが処理準備が整った時点でデータを取得するようにすることで、不要なネットワークトラフィックを削減し、信頼性を向上させることができます。これにより、処理準備が整った時点でのみデータを受信するようになります。処理時間はビジネスロジックに依存し、ワーカー数のスケジューリングに影響します。どちらの場合も、ブローカーはコンシューマーがどのイベントを承認したかを記憶しておく必要があります。.
イベント ストリーミングとは何か、またそれがどのようなアーキテクチャに基づいているかがわかったので、次はこの動的なアプローチの利点について学習します。.
イベントストリーミングのメリット
イベントブロードキャストの主な利点は次のとおりです。
- 一貫性: イベント ブローカーは、イベントが関係するすべてのコンシューマーに正しく送信されることを保証します。.
- フォールト トレランス: コンシューマーがイベントを受け入れられない場合、イベントが処理されないまま残らないように、イベントを別の場所にリダイレクトできます。.
- 再利用性:スレッドに保存されたイベントは不変です。イベント全体または特定の時点から再生できるため、ビジネスロジックが変更された場合でもイベントを再処理できます。.
- スケーラビリティ: プロデューサーとコンシューマーは別々のエンティティであり、お互いを待つ必要がないため、需要に応じて動的にスケールアップまたはスケールダウンできます。.
- 使いやすさ: イベント ブローカーはイベントのルーティングとストレージを処理し、複雑なロジックを抽象化して、データ自体に集中できるようにします。.
各イベントには、発生に関する必要な詳細情報のみを含める必要があります。イベントブローカーは一般的に非常に効率的であり、イベントはトピックに記録された後は期限切れにならないようにすることが推奨されますが、従来のデータベースのように扱うべきではありません。.
例えば、記事の閲覧数の変化を示すことは可能ですが、その事実とともに記事全体とそのメタデータを保存する必要はありません。代わりに、イベントに外部データベース内の記事IDへの参照を含めることができます。これにより、不要な情報を含めることなく、スレッドを汚染することなく、履歴を追跡できます。.
ここでは、Apache Kafka とその他の一般的なイベント ブローカーについて、それらの比較、イベント ストリーミング エコシステムへの適合方法について学習します。.
Apache Kafkaの役割
Apache Kafka は、Java で記述され、Apache Software Foundation によってメンテナンスされているオープンソースのイベントブローカーです。分散サーバーとクライアントで構成され、カスタム TCP ネットワークプロトコルを使用して通信することで、最大限のパフォーマンスを実現します。Kafka は信頼性と拡張性に優れており、仮想マシン、ベアメタルハードウェア、コンテナ、その他のクラウド環境で実行できます。.
信頼性を確保するため、Kafka は 1 台以上のサーバーからなるクラスターとしてデプロイされます。このクラスターは複数のクラウドリージョンとデータセンターにまたがって構成できます。Kafka クラスターはフォールトトレラントであり、サーバー障害や切断が発生した場合でも、残りのサーバーが再編成され、外部への影響やデータ損失のない高可用性オペレーションを実現します。.
効率を最大限に高めるため、すべてのKafkaサーバーが同じ役割を果たすわけではありません。一部のサーバーはグループ化され、仲介役として機能し、データを保持するためのストレージ層を形成します。他のサーバーは既存のシステムに統合され、Kafka Connectを使用してイベントストリームとしてデータを取り込むことができます。Kafka Connectは、既存のシステム(リレーショナルデータベースなど)からKafkaにデータを確実にストリーミングするためのツールです。.
Kafka はプロデューサーとコンシューマーをクライアントとみなします。前述のように、プロデューサーは Kafka ブローカーにイベントを書き込み、ブローカーはそれを関心のあるコンシューマーに送信します。デフォルトの設定では、Kafka はイベントが最終的にいずれかのコンシューマーによって一度だけ処理されることを保証します。.
Kafka では、トピックはパーティション化されています。つまり、トピックは複数の Kafka ブローカーに分割され、スケーラビリティが確保されます。また、Kafka は、特定のトピックとそのパーティションの組み合わせに保存されたイベントが、常に書き込まれた順序で読み取られることを保証します。.
トピックを単純にパーティション分割するだけでは冗長性が保証されないことに注意してください。冗長性は、リージョンやデータセンターをまたがるレプリケーションによってのみ実現できます。本番環境では、クラスターのコピーを少なくとも3つ持つのが一般的です。つまり、常に3つのトピックとパーティションの組み合わせが利用可能であるということです。.
Kafka統合
前述の通り、Kafka Connect を使用すれば、既存システムからのデータのインポートとエクスポートが可能です。Kafka Connect は、サーバーからデータベース全体、レポート、メトリックなどを低レイテンシのスレッドでインポートするのに適しています。Kafka Connect は、様々なデータシステムに対応するコネクタを提供しており、標準的な方法でデータを管理できます。独自のソリューションではなくコネクタを使用するもう一つのメリットは、Connect がデフォルトでスケーラブル(複数のワーカーをグループ化可能)であり、進捗状況を自動的に追跡できることです。.
アプリケーションを通じてKafkaと通信するためのクライアントは多数用意されています。Java、Scala、Python、.NET、C++、Goなど、多くのプログラミング言語がサポートされています。JavaとScala向けの高水準クライアントライブラリ「Kafka Streams」も利用可能です。このライブラリは内部処理を抽象化しており、Kafkaサーバーに簡単に接続してブロードキャストイベントの受信を開始できます。.
結果
この記事では、データとイベント処理における最新のイベントストリームアプローチのパラダイムと、従来のデータ分類プロセスに対するその利点について解説しました。また、イベントブローカーとしてのApache Kafkaとそのクライアントエコシステムについても解説しました。.









