









Introducción
Al diseñar una base de datos, puede que en ocasiones desee restringir los datos permitidos en ciertas columnas. Por ejemplo, si crea una tabla con información sobre rascacielos, podría querer que la columna que contiene la altura de cada edificio no admita valores negativos.
Los sistemas de gestión de bases de datos relacionales (SGBDR) permiten controlar los datos que se añaden a una tabla mediante restricciones. Una restricción es una regla especial que se aplica a una o más columnas (o a toda la tabla) y limita los cambios que se pueden realizar en los datos de la tabla mediante una sentencia. INSERTAR, ACTUALIZAR, o BORRAR Limita.
Este artículo analiza en detalle qué son las restricciones y cómo se utilizan en RDBMS. También analiza cada una de las cinco restricciones definidas en el estándar SQL y explica sus funciones correspondientes.
¿Cuales son las limitaciones?
En SQL, una restricción es cualquier regla aplicada a una columna o tabla que limita los datos que se pueden insertar en ella. Al intentar realizar una operación que modifique los datos almacenados en la tabla, como una instrucción INSERT, UPDATE o DELETE, el RDBMS comprueba si esos datos infringen las restricciones existentes y, de ser así, devuelve un error.
Los administradores de bases de datos suelen usar restricciones para garantizar que la base de datos cumpla con un conjunto definido de reglas de negocio. En el contexto de una base de datos, una regla de negocio es cualquier política o procedimiento que una empresa u otra organización sigue y al que sus datos deben adherirse. Por ejemplo, supongamos que está creando una base de datos que cataloga el inventario de la tienda de un cliente. Si el cliente especifica que cada registro de producto debe tener un número de identificación único, puede crear una columna con la restricción UNIQUE que garantiza que no haya dos entradas iguales en esa columna.
Las restricciones también son útiles para mantener la integridad de los datos. La integridad de los datos es un término amplio que se utiliza a menudo para describir la precisión, consistencia y racionalidad generales de los datos almacenados en una base de datos, según sus casos de uso específicos. Las tablas de una base de datos suelen estar relacionadas, y las columnas de una tabla dependen de los valores de otra. Dado que la entrada de datos suele ser propensa a errores humanos, las restricciones son útiles en casos como este, ya que pueden garantizar que ningún dato introducido erróneamente pueda afectar dichas relaciones y, por lo tanto, comprometer la integridad de la base de datos.
Imagine que está diseñando una base de datos con dos tablas: una para listar los estudiantes actuales de una escuela y otra para listar los miembros del equipo de baloncesto de dicha escuela. Puede aplicar una restricción de clave externa a una columna de la tabla "equipo de baloncesto" que haga referencia a una columna de la tabla "escuela". Esto establece una relación entre ambas tablas al exigir que cada entrada de la tabla "equipo" haga referencia a una entrada de la tabla "estudiantes".
Los usuarios definen restricciones al crear una tabla por primera vez o pueden añadirlas posteriormente con la sentencia ALTER TABLE, siempre que no entren en conflicto con los datos ya existentes en la tabla. Al crear una restricción, el sistema de base de datos le asigna automáticamente un nombre, pero en la mayoría de las implementaciones de SQL se puede añadir un nombre personalizado para cada restricción. Estos nombres se utilizan para referirse a las restricciones en las sentencias ALTER TABLE cuando se modifican o eliminan.
El estándar SQL define formalmente sólo cinco restricciones:
- Clave principal
- Clave externa
- Único
- Revisar
- No está vacío.
Ahora que tiene una comprensión general de cómo se utilizan las restricciones, analicemos con más detalle cada una de estas cinco restricciones.
Clave principal
La restricción CLAVE PRINCIPAL requiere que cada entrada en una columna determinada sea única y no NULA, lo que le permite usar esa columna para identificar cada fila individual en la tabla.
En el modelo relacional, una clave es una columna o conjunto de columnas de una tabla donde se garantiza que cada valor sea único y no contenga ningún valor nulo. Una clave principal es una clave especial cuyos valores se utilizan para identificar filas individuales de una tabla, y la columna o columnas que la componen pueden utilizarse para identificar la tabla en el resto de la base de datos.
Este es uno de los aspectos importantes de las bases de datos relacionales: con una clave principal, los usuarios no necesitan saber que sus datos están almacenados físicamente en una máquina, y su SGBD puede rastrear cada registro y recuperarlos ad hoc. Esto, a su vez, significa que los registros no tienen un orden lógico definido, y los usuarios pueden recuperar sus datos en cualquier orden o mediante cualquier filtro.
Se puede crear una clave principal en SQL con una restricción PRIMARY KEY, que es esencialmente una combinación de las restricciones UNIQUE y NOT NULL. Una vez definida la clave principal, el SGBD crea automáticamente un índice asociado a ella. Un índice es una estructura de base de datos que facilita la recuperación más rápida de datos de una tabla. Al igual que un índice en un libro de texto, las consultas solo tienen que examinar las entradas de la columna indexada para encontrar los valores relacionados. Esto permite que la clave principal actúe como identificador para cada fila de la tabla.
Una tabla solo puede tener una clave principal, pero al igual que las claves normales, una clave principal puede constar de más de una columna. Dicho esto, una característica distintiva de las claves principales es que utilizan únicamente el conjunto mínimo de atributos necesarios para identificar de forma única cada fila de una tabla. Para ilustrar esta idea, imagine una tabla que almacena información sobre los estudiantes de una escuela utilizando las siguientes tres columnas:
identificación de estudiante:Se utiliza para almacenar el número de identificación único de cada estudiante.nombre de pila:Se utiliza para guardar el nombre de cada estudiante.Apellido:Se utiliza para guardar el apellido de cada estudiante.
Es posible que algunos estudiantes de una escuela compartan el mismo nombre, lo que haría que la columna "Nombre" no sea una buena opción como clave principal. Lo mismo ocurre con la columna "Apellido". Una clave principal compuesta por las columnas "Nombre" y "Apellido" podría funcionar, pero aún existe la posibilidad de que dos estudiantes compartan nombre y apellido.
Una clave principal compuesta por el ID del estudiante y las columnas firstName o lastName podría funcionar, pero como el ID de cada estudiante ya es único, incluir cada columna de nombre en la clave principal es redundante. Por lo tanto, en este caso, el conjunto mínimo de atributos que puede identificar cada fila, y por lo tanto una buena opción para la clave principal de la tabla, es solo la columna studentID.
Si una clave consta de datos observables y utilizables (es decir, datos que representan entidades, eventos o propiedades del mundo real), se denomina clave natural. Si la clave se genera internamente y no representa nada externo a la base de datos, se denomina clave sustituta o artificial. Algunos sistemas de bases de datos no recomiendan el uso de claves naturales porque incluso datos aparentemente fijos pueden cambiar de forma impredecible.
Clave externa
La restricción FOREIGN KEY requiere que cada entrada en una columna dada ya debe existir en una columna específica de otra tabla.
Si tiene dos tablas que desea relacionar, una forma de hacerlo es definir una clave externa con una restricción FOREIGN KEY. Una clave externa es una columna de una tabla (la tabla secundaria) cuyos valores provienen de una clave de otra tabla (la tabla principal). Esta es una forma de expresar una relación entre dos tablas: una restricción FOREIGN KEY requiere que los valores de la columna a la que se aplica existan en la columna a la que hace referencia.
El siguiente diagrama muestra dicha relación entre dos tablas: una utilizada para registrar información sobre los empleados de una empresa y la otra para el seguimiento de las ventas. En este ejemplo, la clave principal de la tabla EMPLOYEES está referenciada por la clave externa de la tabla SALES:
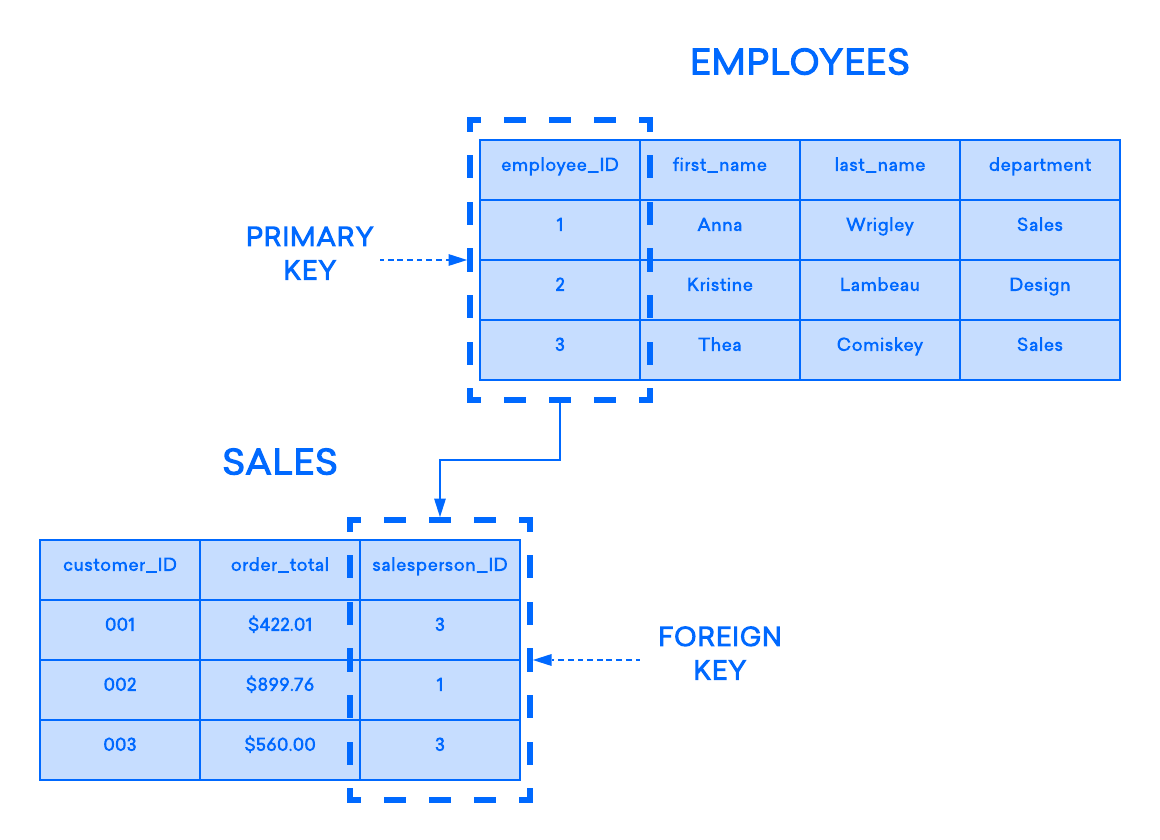
Si intenta insertar un registro en una tabla secundaria y el valor introducido en la columna de clave externa no existe en la clave principal de la tabla principal, la instrucción de inserción no será válida. Esto ayuda a mantener la integridad de la relación, ya que las filas de ambas tablas siempre están correctamente relacionadas.
Generalmente, la clave externa de una tabla es la clave principal de la tabla principal, pero no siempre es así. En la mayoría de los RDBMS, cualquier columna de la tabla principal con una restricción UNIQUE o PRIMARY KEY puede ser referenciada por la clave externa de la tabla secundaria.
Único
La restricción UNIQUE evita que se agreguen valores duplicados a la columna dada.
Como su nombre indica, una restricción UNIQUE requiere que cada entrada de una columna sea un valor único. Cualquier intento de agregar un valor que ya figura en la columna generará un error.
Las restricciones UNIQUE son útiles para imponer relaciones uno a uno entre tablas. Como se mencionó anteriormente, se puede establecer una relación entre dos tablas mediante una clave externa, pero existen varios tipos de relaciones entre tablas:
یک به یکUno a muchosEn una relación de muchos a cualquiera, una fila de la tabla principal puede relacionarse con varias filas de la tabla secundaria, pero cada fila de la tabla secundaria puede relacionarse solo con una fila de la tabla principal.¿Cuántos?:Si las filas de la tabla principal se pueden relacionar con varias filas de la tabla secundaria y viceversa, se dice que las dos tienen una relación de muchos a muchos.
Al agregar una restricción UNIQUE a una columna que tiene una restricción FOREIGN KEY aplicada, puede garantizar que cada entrada en la tabla principal aparezca solo una vez en la secundaria, estableciendo así una relación uno a uno entre las dos tablas.
Tenga en cuenta que puede definir restricciones UNIQUE tanto a nivel de tabla como de columna. Al definirse a nivel de tabla, una restricción UNIQUE puede aplicarse a más de una columna. En este caso, cada columna de la restricción puede tener valores duplicados, pero cada fila debe tener una combinación única de valores en las columnas restringidas.
Revisar
Una restricción CHECK define una condición para una columna, conocida como predicado, que cualquier valor ingresado en ella debe satisfacer.
Los predicados de la restricción CHECK se escriben como una expresión que puede evaluarse como VERDADERO, FALSO o posiblemente desconocido. Si se intenta introducir un valor en una restricción CHECK y este hace que la instrucción se evalúe como VERDADERO o desconocido (lo que ocurre con valores NULL), la operación se realizará correctamente. Sin embargo, si la expresión se evalúa como FALSO, fallará.
Los predicados CHECK suelen basarse en un operador de comparación matemático (como <, >, <=, OR >=) para restringir el rango de datos permitidos en una columna. Por ejemplo, un uso común de las restricciones CHECK es evitar que se contengan valores negativos en algunas columnas cuando un valor negativo no tendría sentido, como en el ejemplo siguiente.
Esta sentencia CREATE TABLE crea una tabla llamada productInfo con columnas para el nombre, el número de identificación y el precio de cada producto. Dado que no tiene sentido que un producto tenga un precio negativo, esta sentencia aplica una restricción CHECK a la columna de precio para garantizar que solo contenga valores positivos:
CREATE TABLE productInfo (
productID int,
name varchar(30),
price decimal(4,2)
CHECK (price > 0)
);Ningún predicado CHECK debe usar un operador de comparación matemático. Normalmente, se puede usar cualquier operador SQL que pueda evaluarse como verdadero, falso o desconocido en un predicado de verificación, incluyendo LIKE, BETWEEN, IS NOT NULL, etc. Algunas implementaciones de SQL, aunque no todas, permiten incluir una subconsulta en un predicado CHECK. Sin embargo, tenga en cuenta que la mayoría de las implementaciones no permiten referenciar a otra tabla en una sentencia.
No está vacío.
La restricción NOT NULL evita que se agreguen valores NULL a la columna dada.
En la mayoría de las implementaciones de SQL, si se inserta una fila de datos pero no se especifica un valor para una columna específica, el sistema de base de datos representará los datos faltantes como NULL de forma predeterminada. En SQL, NULL es una palabra clave especial que se utiliza para representar un valor desconocido, faltante o no especificado. Sin embargo, NULL no es un valor en sí mismo, sino el estado de un valor desconocido.
Para ilustrar esta diferencia, imagine una tabla utilizada para el seguimiento de clientes en una agencia de talentos que tiene columnas para el nombre y apellido de cada cliente. Si un cliente usa un solo nombre, como "Cher", "Usher" o "Beyoncé", el administrador de la base de datos podría introducir solo un nombre en la columna de nombre, lo que provocaría que el SGBD insertara NULL en la columna de apellido. La base de datos no considera que el apellido de un cliente sea literalmente "nulo". Simplemente significa que se desconoce el valor de la columna de apellido de esa fila o que el campo no corresponde a ese registro en particular.
Como su nombre indica, la restricción NOT NULL impide que cualquier valor en la columna dada sea nulo. Esto significa que, para cualquier columna con una restricción NOT NULL, debe especificar un valor al insertar una nueva fila. De lo contrario, la operación INSERT fallará.
Resultado
Las restricciones son una herramienta esencial para cualquiera que busque diseñar una base de datos con un alto nivel de integridad y seguridad. Al restringir los datos que se introducen en una columna, se garantiza que las relaciones entre tablas se mantengan correctamente y que la base de datos cumpla con las reglas de negocio que definen su propósito.









