









Introducción
Este tutorial explica cómo instalar Ollama para ejecutar modelos de lenguaje en un servidor con Ubuntu o Debian. También muestra cómo configurar una interfaz de chat con Open WebUI y cómo usar un modelo de lenguaje personalizado.
Requisitos previos
- Un servidor con Ubuntu/Debian
- Necesita acceso de usuario root o un usuario con permisos sudo.
- Antes de comenzar, deberá completar algunas configuraciones iniciales, incluido el firewall.
Paso 1 – Instalar Ollama
Los siguientes pasos explican cómo instalar Ollama manualmente. Para empezar rápidamente, puede usar el script de instalación y continuar con el “Paso 2: Instalación de Ollama WebUI”.
Para instalar Ollama usted mismo, siga estos pasos:
Si su servidor tiene una GPU Nvidia, asegúrese de que los controladores CUDA estén instalados.
nvidia-smi
Si no tiene instalados los controladores CUDA, instálelos ahora. En esta configuración, puede seleccionar su sistema operativo y el tipo de instalador para ver los comandos que necesita ejecutar con su configuración.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
Descargue el binario de Ollama y cree un usuario de Ollama
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaCree un archivo de servicio. De forma predeterminada, puede acceder a la API de Ollama en el puerto 11434 127.0.0.1. Esto significa que la API solo está disponible para el host local.
Si necesita acceso externo a Ollama, puede Ambiente Eliminar y configurar una dirección IP para acceder a la API de Ollama. 0.0.0.0 Permite acceder a la API a través de la IP pública del servidor. Si utiliza Ambiente Si está utilizando , asegúrese de que el firewall de su servidor permita el acceso al puerto que ha configurado aquí. 11434 Si solo tiene un servidor, no necesita cambiar el siguiente comando.
Copie y pegue todo el contenido del siguiente bloque de código. Este nuevo archivo /etc/systemd/system/ollama.servicio Crea e interconecta contenidos EOF Agrega al nuevo archivo.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
Recargue el demonio systemd y habilite el servicio Ollama.
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaUtilice systemctl status olama para comprobar el estado. Si Olama no está en funcionamiento, asegúrese de ejecutar systemctl start olama.
En la terminal, ahora puedes iniciar modelos de lenguaje y hacer preguntas. Por ejemplo:
ollama run llama2
El siguiente paso explica cómo instalar una interfaz web para que puedas hacer tus preguntas en una hermosa interfaz a través de un navegador web.
Paso 2 – Instalar Open WebUI
En la documentación de Olama en GitHub, encontrará una lista de diversas integraciones web y de terminal. Este ejemplo explica cómo instalar Open WebUI.
Puedes instalar Open WebUI en el mismo servidor que Ollama, o instalar Ollama y Open WebUI en servidores separados. Si instalas Open WebUI en un servidor separado, asegúrate de que la API de Ollama esté expuesta en tu red. Para comprobarlo, /etc/systemd/system/olama.servicio Ver el servidor donde está instalado Ollama y el valor OLLAMA_HOST Confirmar.
Los siguientes pasos explican cómo instalar la interfaz:
- A mano
- Con Docker
Instalar Open WebUI manualmente
Instale npm y pip, clone el repositorio WebUI y cree una copia del archivo de entorno de ejemplo:
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .envEn ambiente. La dirección para conectarse a la API de Ollama está configurada por defecto. host local:11434 Si ha instalado la API de Ollama en el mismo servidor que Open WebUI, puede dejar esta configuración como está. Si ha instalado Open WebUI en un servidor distinto al de la API de Ollama, ambiente. Edite y reemplace el valor predeterminado con la dirección del servidor donde está instalado Olama.
Dependencias enumeradas en paquete.json Instale y ejecute el script llamado construir Correr:
npm i && npm run build
Instale los paquetes de Python necesarios:
cd backend
sudo pip install -r requirements.txt -UInterfaz web con olama-webui/backend/start.sh Comenzar.
sh start.shEn inicio.sh, el puerto está configurado en 8080. Esto significa que puede acceder a Open WebUI en http:// :8080 Acceso. Si tiene un firewall activo en su servidor, deberá habilitar el puerto para poder acceder a la interfaz de chat. Para ello, puede ir al "Paso 3: Habilitar puertos para la interfaz web". Si no tiene un firewall, lo cual no se recomienda, puede ir al "Paso 4: Agregar modelos".
Instalar Open WebUI con Docker
Para este paso, necesitas instalar Docker. Si aún no lo has hecho, puedes hacerlo ahora con este tutorial.
Como se mencionó anteriormente, puede optar por instalar Open WebUI en el mismo servidor que Ollama o instalar Ollama y Open WebUI en dos servidores separados.
Instalar Open WebUI en el mismo servidor Ollama
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Instalar Open WebUI en un servidor diferente a Ollama
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
En el comando Docker anterior, el puerto está configurado en 3000. Esto significa que puede acceder a Open WebUI en http:// :3000 Acceso. Si tiene un firewall activo en su servidor, deberá habilitar el puerto para poder acceder a la interfaz de chat. Esto se explica en el siguiente paso.
Paso 3: Permitir el puerto a la interfaz web
Si tiene un firewall, asegúrese de que permita el acceso al puerto Open WebUI. Si lo instaló manualmente, deberá abrir el puerto. 8080 TCP Si lo instalaste con Docker, debes permitir el puerto 3000 TCP Déjame.
Para comprobarlo de nuevo, puedes utilizar netstat Utilice y vea qué puertos se están utilizando.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTENExisten varias herramientas de firewall. Este tutorial configurará la herramienta de firewall predeterminada para Ubuntu. ufw Si está utilizando otro firewall, asegúrese de que permita el tráfico entrante al puerto TCP 8080 o 3000.
Administrar reglas de firewall ufw:
- Ver la configuración actual del firewall
Para comprobar si el firewall ufw está activo y ya tienes alguna regla, puedes utilizar lo siguiente:
sudo ufw status
- Permitir el puerto TCP 8080 o 3000
Si el firewall está habilitado, ejecute este comando para permitir el tráfico entrante al puerto TCP 8080 o 3000:
sudo ufw allow proto tcp to any port 8080
- Ver la nueva configuración del firewall
Se deberían añadir nuevas reglas. Para comprobarlo, vaya a:
sudo ufw status
Paso 4 – Agregar modelos
Tras acceder a la interfaz web, deberá crear su primera cuenta. Este usuario tendrá derechos de administrador. Para iniciar su primer chat, deberá elegir un modelo. Puede consultar la lista de modelos en el sitio web oficial de Llama. En este ejemplo, añadiremos "llama2".
En la esquina superior derecha, seleccione el icono de configuración.
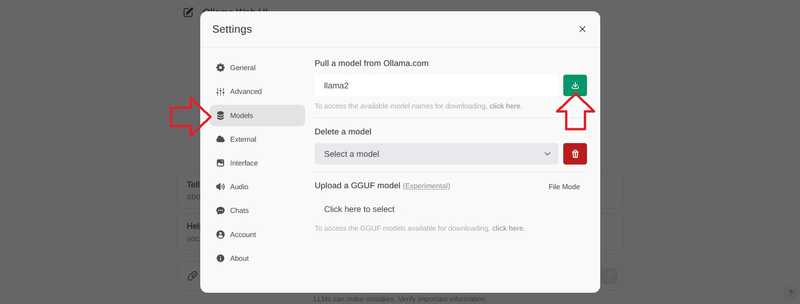
Vaya a “Modelos”, ingrese un modelo y seleccione el botón de descarga.
Espere a que aparezca este mensaje:
Model 'llama2' has been successfully downloaded.
Cierra la configuración para volver al chat.
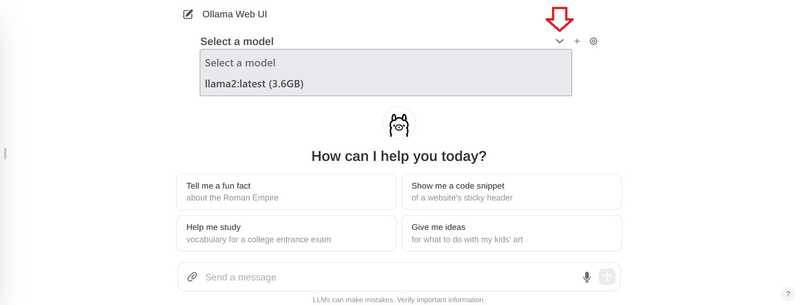
En el chat, haga clic en “Seleccionar modelo” en la parte superior y agregue su modelo.
Si desea agregar varios modelos, puede utilizar el signo + en la parte superior.
Una vez que hayas añadido los modelos que quieres usar, puedes empezar a hacer preguntas. Si has añadido varios modelos, puedes alternar entre las respuestas.

Paso 5 – Agrega tu modelo
Si desea agregar nuevos modelos a través de la interfaz, puede hacerlo a través de http:// :8080/archivosmodelo/crear/ Hazlo. Si es necesario. 8080 con 3000 Reemplazar.
A continuación, nos centraremos en añadir un nuevo modelo mediante la terminal. Primero, debe conectarse al servidor que tiene instalado Olama. En la lista... mundo Úselo para enumerar los modelos que están disponibles hasta el momento.
- Crear un archivo de modelo
Puedes encontrar los requisitos para un archivo de modelo en la documentación de Olama en GitHub. En la primera línea del archivo de modelo FROM Puedes especificar el modelo que quieres usar. En este ejemplo, modificaremos el modelo llama2 existente. Si quieres añadir un modelo completamente nuevo, debes especificar la ruta al archivo del modelo (por ejemplo, FROM ./my-model.gguf).
nano new-model
Guardar este contenido:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
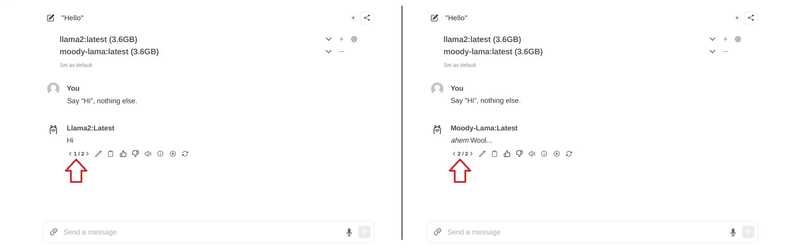
SYSTEM You are a moody lama that only talks about its own fluffy wool.Crear un modelo a partir del archivo del modelo
ollama create moody-lama -f ./new-model
- Comprueba si el nuevo modelo está disponible.
Use el comando olama para listar todos los modelos. Moody-lama también debería estar en la lista.
ollama list
- Utilice su modelo en WebUI
Al regresar a la interfaz web, el modelo debería aparecer en la lista de selección. Si aún no aparece, puede que necesite actualizar la página rápidamente.
Resultado
En este tutorial, aprendió cómo alojar un chat de IA en su propio servidor y cómo agregar sus propios modelos.









