









TensorFlow
Flujo de tensor Es una biblioteca de aprendizaje automático y aprendizaje profundo publicada por Google, que la ha utilizado en diversas ocasiones para ofrecer una mejor experiencia a sus usuarios. Un ejemplo es cuando inicias una búsqueda y Google completa el texto automáticamente.
Tres grupos de personas utilizan el aprendizaje automático: 1. Investigadores, 2. Científicos de datos y 3. Programadores. Para satisfacer las necesidades de estos grupos, el equipo de Google Brain creó la biblioteca TensorFlow. TensorFlow puede ejecutarse en diferentes CPU y GPU, y utilizarse con diferentes lenguajes como C++, Python o Java. TensorFlow se puede usar en servidores e incluso en teléfonos móviles.
Historia de TensorFlow
A medida que aumentó el volumen de datos, el aprendizaje profundo comenzó a superar a los algoritmos de aprendizaje profundo y Google llegó a la conclusión de que podía mejorar sus servicios con estas redes neuronales profundas y comenzó a construir un marco llamado TensorFlow que podría ayudar a los desarrolladores e investigadores a trabajar juntos en modelos de IA simultáneamente.
Cuando el proyecto estuvo suficientemente desarrollado y escalable, se lanzó públicamente en 2015. Sin embargo, la versión estable no se lanzó hasta 2017.
La característica importante de TensorFlow es que es de código abierto y cuenta con licencia Apache, por lo que puedes usarlo, editarlo y publicar tu propia distribución fácilmente. Incluso puedes generar ingresos sin tener que pagar a Google. .
Arquitectura de TensorFlow
La arquitectura de TensorFlow consta de tres partes: 1. Preprocesamiento de datos 2. Construcción del modelo 3. Entrenamiento y estimación del modelo. El motivo de este nombre es que TensorFlow recibe matrices multidimensionales como entrada, cuyos nombres son tensor Y luego puedes ejecutar una serie de gráficos de operaciones en tus datos, que son diagrama de flujo Sí.
¿Donde se realiza?
El uso de esta biblioteca consta de dos fases:
Fase de desarrollo: Hay un momento en el que entrenas el modelo, y esta fase generalmente se realiza en tu computadora portátil o sistema.
Fase de implementación: Una vez finalizada la capacitación, podrá ejecutar su modelo en cualquier lugar, desde computadoras de escritorio hasta servidores e incluso teléfonos móviles.
De este modo, el entrenamiento y la ejecución del modelo se pueden realizar en diferentes máquinas.
Además de usar CPU, también puedes ejecutar TensorFlow en GPU.
En los cálculos matriciales, debido a que el mismo operador se realiza sobre una gran cantidad de información, este tipo de cálculo es compatible con la estructura de las GPU, como descubrieron investigadores de Stanford a finales de 2010.
Además, esta biblioteca está escrita en C++, por lo que es muy rápida. Por supuesto, se puede usar con otros lenguajes, como Python.
Una característica importante de TensorFlow es TensorBoard, que le permite ver lo que está haciendo TensorFlow.
Componentes de TensorFlow
Tensor
Un tensor es un conjunto de matrices N-dimensionales que pueden representar diversos tipos de información. Cada valor del tensor contiene información de la misma forma.
Los tensores pueden ser la entrada o la salida de un cálculo.
Gráfico
En TensorFlow, todas las operaciones se realizan dentro de un grafo. Cada grafo es un conjunto de cálculos que se ejecutan secuencialmente. Cada cálculo se conoce como nodo de operación y está conectado entre sí.
Ahora bien, ¿por qué el gráfico?
- Puede ejecutarse en diferentes sistemas.
- El gráfico se puede guardar para usarlo más adelante.
- Todos los cálculos en el gráfico se realizan conectando tensores entre sí.
- En resumen, en los gráficos, cada borde es un valor (tensor) y cada nodo es un operador (como la suma).
¿Por qué es famoso TensorFlow?
TensorFlow es el mejor porque está diseñado para que todos lo usen y utiliza API que pueden usarse a diferentes escalas con arquitecturas de aprendizaje profundo como RNN y CNN. Al basarse en computación gráfica, permite visualizar redes neuronales dentro de TensorBoard, lo cual resulta muy útil para la depuración. En general, TensorFlow está diseñado para ofrecer escalabilidad durante la implementación.
La buena noticia es que tiene la comunidad más grande entre los diversos marcos de aprendizaje profundo en GitHub.
¿Cuántos algoritmos admite TensorFlow?
- Regresión lineal: tf.estimator.LinearRegressor
- Clasificación: tf.estimator.LinearClassifier
- Clasificación profunda: tf.estimator.DNNClassifier
- Borrado de aprendizaje profundo y profundo: tf.estimator.DNNLinearCombinedClassifier
- Regresión de árbol de refuerzo: tf.estimator.BoostedTreesRegressor
- Clasificación de árboles mejorada: tf.estimator.BoostedTreesClassifier
Algunos ejemplos sencillos
- 12importar numpy como np
- importar tensorflow como tf
En las dos líneas anteriores, importamos las bibliotecas numpy y tensorflow.
En este ejemplo, queremos multiplicar X_1 y X_2. Primero, necesitamos crear el gráfico y luego ejecutar una sesión de TensorFlow para calcular el resultado.
Empecemos.
Paso 1: Definir la variable
El primer paso es crear los nodos de entrada X_1 y X_2. En TensorFlow, debemos especificar el tipo de nodo que vamos a crear; aquí seleccionamos el tipo de marcador de posición.
marcador de posición:
Este tipo asigna un nuevo valor al tensor cada vez que realizamos un cálculo.
- X_1 = tf.placeholder(tf.float32, nombre = “X_1”)
- X_2 = tf.placeholder(tf.float32, nombre = “X_2”)
Como puedes ver, ingresamos el tipo de este nodo como flotante y su nombre como nombre de variable.
Paso 2: Definir el cálculo
- 1multiplicar = tf.multiplicar(X_1, X_2, nombre = “multiplicar”)
Con la línea anterior, estamos creando un vértice que actúa como operador del operador de multiplicación.
¿Cuál es la entrada de los vértices que queremos multiplicar y lo llamamos multiplicar?
Así que ahora hemos creado nuestro primer gráfico.
Paso 3: Ejecutar la operación
Para ejecutar la operación, necesitamos crear una sesión. Esta sesión se crea mediante tf.Session() y se ejecuta al usar run.
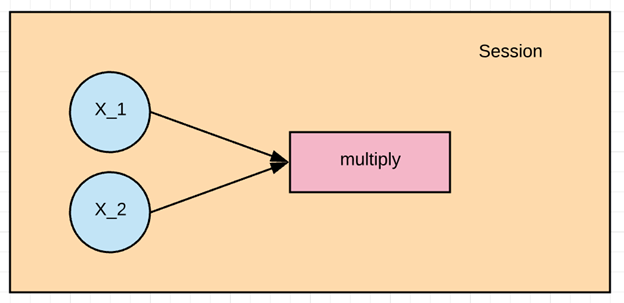
Al ejecutar la multiplicación, necesitamos introducir en la entrada los valores de los tensores x1 y x2. Esto se realiza asignando feed_dict. En este ejemplo, los valores del 1 al 3 se asignan a x1 y del 4 al 6 a x2. Imprimimos el resultado.
- X_1 = tf.placeholder(tf.float32, nombre = “X_1”)
- X_2 = tf.placeholder(tf.float32, nombre = “X_2”)
- 1multiplicar = tf.multiplicar(X_1, X_2, nombre = “multiplicar”)
- con tf.Session() como sesión:
- resultado = sesión.ejecutar(multiplicar, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- imprimir(resultado)
- [ 4. 10. 18.]
Diferentes formas de importar datos a TensorFlow
Bueno, uno de los primeros pasos antes de entrenar el modelo es importar los datos, que tiene dos modos:
- Ingresar datos en la RAM: Hay una forma sencilla de ingresar datos en una matriz de memoria, por ejemplo, escribiendo una línea de código en Python.
- Uso de la canalización de datos de TensorFlow: TensorFlow cuenta con un conjunto de API que permiten procesar datos, realizar operaciones con ellos y luego alimentarlos al algoritmo. Este método es muy eficaz, especialmente cuando los datos son muy grandes. Por ejemplo, las imágenes son enormes y no caben en la RAM. En este caso, la canalización de datos se encarga de la gestión de la RAM.
La pregunta ahora es cuál utilizar.
Si sus datos son inferiores a 10 GB, puede usar fácilmente el primer método; por ejemplo, una biblioteca conocida para esto es Pandas. De lo contrario, por ejemplo, si tiene 30 GB de datos y 12 GB de RAM, no podrá usar este método y deberá recurrir a la API de pipeline. La pipeline procesa los datos por lotes, y cada lote se introduce en la pipeline y se utiliza para aprender el modelo. Usar la pipeline permite el procesamiento en paralelo. Esto significa que TensorFlow puede entrenar el modelo en varias CPU simultáneamente.
En resumen, si sus datos son pequeños, cárguelos completamente en la RAM, por ejemplo, con Pandas. De lo contrario, o si desea usar varias CPU, utilice la canalización de TensorFlow.
Creación de una canalización en TensorFlow
Paso 1) Crear datos
Generamos dos números aleatorios con la biblioteca numpy.
- 123importar numpy como np
- x_entrada = np.aleatorio.muestra((1,2))
- imprimir(x_entrada)
- 1[[0.8835775 0.23766977]]
Paso 2) Crear un marcador de posición
En este paso, creamos un marcador de posición llamado X como una matriz con dos miembros de tipo flotante.
- usando un marcador de posición #
- x = tf.placeholder(tf.float32, forma=[1,2], nombre = 'X')
Paso 3: Crear el conjunto de datos
En este punto, necesitamos definir el conjunto de datos en el que colocaremos el valor de marcador de posición x.
- 1tf.data.Conjunto de datos.de_cortes_tensoriales
- 1conjunto de datos = tf.data.Conjunto de datos.de_tensor_slices(x)
Paso 4: Construir la tubería
En este paso, necesitamos inicializar la canalización. El primer paso es crear un iterador que iterará sobre los datos. Con el método get_next obtenemos el siguiente valor. En este ejemplo, hay un lote con solo dos valores.
- 12iterador = conjunto de datos.make_initializable_iterator()
- obtener_siguiente = iterador.obtener_siguiente()
Paso 5: Ejecutar el cálculo
En el paso final, ejecutamos una sesión cuya entrada es un iterador y valores de entrada creados por numpy, y para cada uno, imprimimos su valor.
- con tf.Session() como sesión:
- # alimenta el marcador de posición con datos
- sess.run(iterador.inicializador, feed_dict={ x: x_input })
- imprimir(sess.run(get_next))
- 1[0.8835775 0.23766978]
Resumen
TensorFlow es la biblioteca de aprendizaje profundo más famosa, que permite crear cualquier framework de aprendizaje profundo. Google Brain desarrolló este proyecto para conectar a los equipos de investigación con los de desarrollo, y Google lo utiliza en casi todos sus proyectos. Una de las principales razones para usar TensorFlow es su fácil escalabilidad durante la implementación. TensorFlow se puede utilizar desde servidores potentes hasta teléfonos Android e iOS.
TensorFlow funciona en una sesión, donde cada sesión está definida por un gráfico con diferentes cálculos.
Como ejemplo simple en TensorFlow, la multiplicación es la siguiente:
1. Definición de variable
- X_1 = tf.placeholder(tf.float32, nombre = “X_1”)
- X_2 = tf.placeholder(tf.float32, nombre = “X_2”)
2. Definición de cálculo
- 1multiplicar = tf.multiplicar(X_1, X_2, nombre = “multiplicar”)
3. Ejecución de operaciones
- con tf.Session() como sesión:
- resultado = sesión.ejecutar(multiplicar, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- imprimir(resultado)
Una práctica común en TensorFlow es crear una tubería para cargar datos en la RAM, lo que se realiza con los siguientes pasos:
1. Creación de datos
- importar numpy como np
- x_entrada = np.aleatorio.muestra((1,2))
- imprimir(x_entrada)
2. Crea un marcador de posición
- 1x = tf.placeholder(tf.float32, forma=[1,2], nombre = 'X')
3. Definición del método del conjunto de datos
- 1conjunto de datos = tf.data.Conjunto de datos.de_tensor_slices(x)
4. Construcción de tuberías
- 1iterador = conjunto de datos.make_initializable_iterator() obtener_siguiente = iteraror.get_next()
5. Ejecución del programa
- con tf.Session() como sesión:
- sess.run(iterador.inicializador, feed_dict={ x: x_input })
- imprimir(sess.run(get_next))









