









Introducción
Imagina poder conversar con tus datos no estructurados y extraer fácilmente información valiosa. En el panorama actual, basado en datos, extraer información significativa de documentos no estructurados sigue siendo un desafío, lo que dificulta la toma de decisiones y la innovación. En este tutorial, conoceremos las incrustaciones, exploraremos el uso de Amazon Open Search como base de datos vectorial e integraremos el framework Langchain con Modelos de Lenguaje de Gran Tamaño (LLM) para crear un sitio web con un chatbot de PLN integrado. Repasaremos los fundamentos de los LLM para extraer información significativa de un documento no estructurado con la ayuda de un Modelo de Lenguaje de Gran Tamaño de código abierto. Al finalizar este tutorial, comprenderás por completo cómo obtener información significativa de documentos no estructurados y utilizarás las habilidades para explorar e innovar con soluciones similares basadas en IA Full-Stack.
Requisitos previos
- Debe tener una cuenta activa de AWS. Si no la tiene, puede registrarse en el sitio web de AWS.
- Asegúrese de tener instalada la interfaz de línea de comandos (CLI) de AWS en su equipo local y de que esté configurada correctamente con las credenciales requeridas y la región predeterminada. Puede configurarla con el comando aws configure.
- Descargue e instale Docker Engine. Siga las instrucciones de instalación para su sistema operativo.
¿Qué vamos a construir?
En este ejemplo, queremos imitar un problema que enfrentan muchas empresas. Gran parte de los datos actuales no están estructurados, sino que se presentan en forma de transcripciones de audio y video, documentos PDF y Word, manuales, notas escaneadas, transcripciones de redes sociales, etc. Utilizaremos el modelo Flan-T5 XXL como LLM. Este modelo puede generar resúmenes y preguntas y respuestas a partir de textos no estructurados. La imagen a continuación muestra la arquitectura de los diferentes componentes.

Empecemos con lo básico.
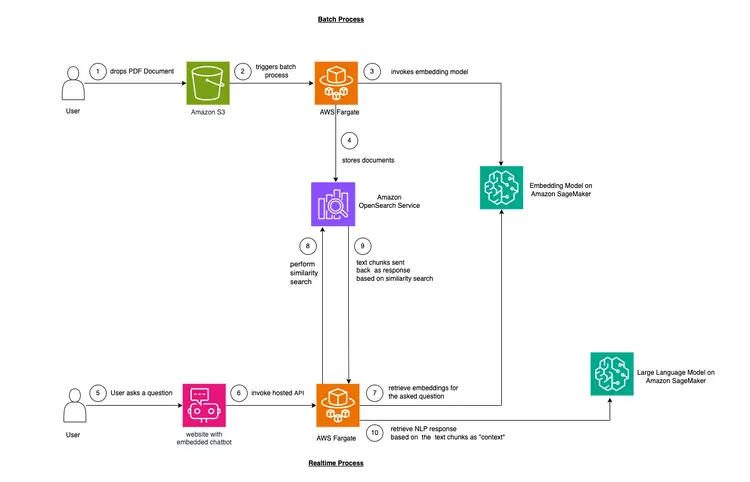
Utilizaremos una técnica llamada aprendizaje en contexto para incorporar un contexto específico de dominio o caso en nuestro LLM. En este caso, tenemos un manual en PDF no estructurado de un automóvil que queremos añadir como contexto para el LLM y queremos que este responda preguntas sobre este manual. ¡Así de simple! Nuestro objetivo es ir un paso más allá creando una API en tiempo real que recibe preguntas, las envía a nuestro backend y es accesible a través de un chatbot de código abierto integrado en el sitio web. Este tutorial nos permitirá crear la experiencia de usuario completa y comprender mejor los diversos conceptos y herramientas a lo largo del proceso.
- El primer paso para proporcionar aprendizaje en texto es ingerir el documento PDF y convertirlo en fragmentos de texto, generar representaciones vectoriales de estos fragmentos de texto llamadas "incrustaciones" y, finalmente, almacenar estas incrustaciones en una base de datos vectorial.
- Las bases de datos vectoriales nos permiten realizar «búsquedas de similitud» en las incrustaciones de texto que almacenan.
- Amazon SageMaker JumpStart ofrece plantillas de soluciones de implementación con un solo clic para configurar la infraestructura para modelos de código abierto preentrenados. Utilizaremos Amazon SageMaker JumpStart para implementar el modelo de incrustación y el modelo de lenguaje grande.
- Amazon OpenSearch es un motor de búsqueda y análisis que puede buscar los vecinos más cercanos de los puntos en un espacio vectorial, lo que lo hace adecuado como base de datos vectorial.
Gráfico: Convertir de PDF para incrustar en una base de datos vectorial
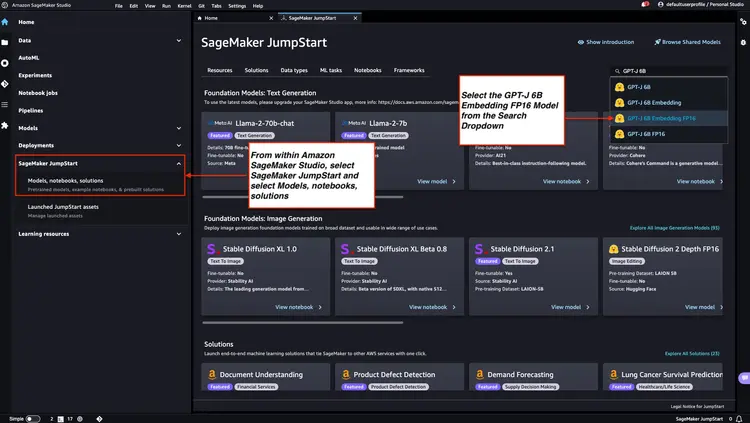
Paso 1: Implementar el modelo de integración GPT-J 6B FP16 con Amazon SageMaker JumpStart
Siga los pasos mencionados en la documentación de Amazon SageMaker: Abra y utilice la sección JumpStart para iniciar un nodo de Amazon SageMaker JumpStart desde el menú principal de Amazon SageMaker Studio. Seleccione Modelos, Notebooks, Soluciones y el modelo de incrustación GPT-J 6B Embedding FP16, como se muestra en la imagen a continuación. A continuación, haga clic en "Implementar" y Amazon SageMaker JumpStart se encargará de configurar la infraestructura para implementar este modelo preentrenado en el entorno de SageMaker.
Paso 2: Implementar Flan T5 XXL LLM con Amazon SageMaker JumpStart
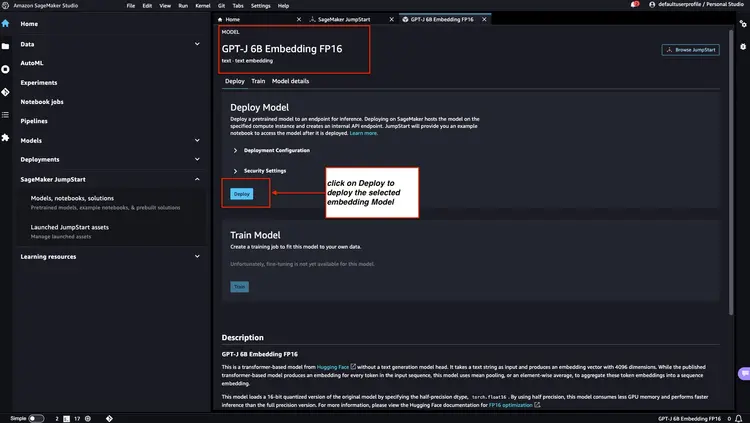
A continuación, en Amazon SageMaker JumpStart, seleccione Flan-T5 XXL LLM y haga clic en "Implementar" para comenzar la configuración automática de la infraestructura e implementar el punto final del modelo en el entorno de Amazon SageMaker.
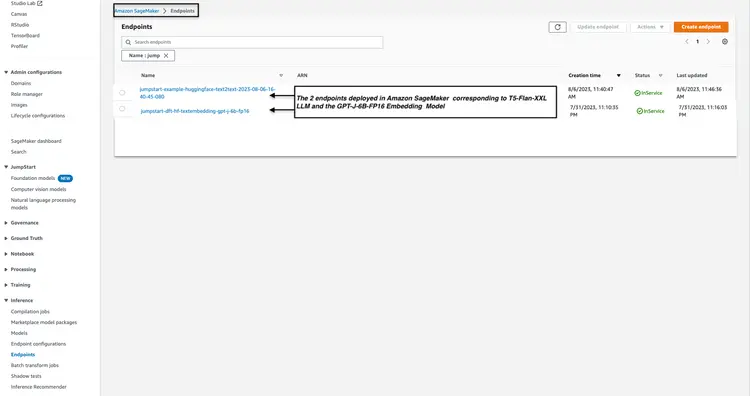
Paso 3: Verificar el estado de los puntos finales del modelo implementado
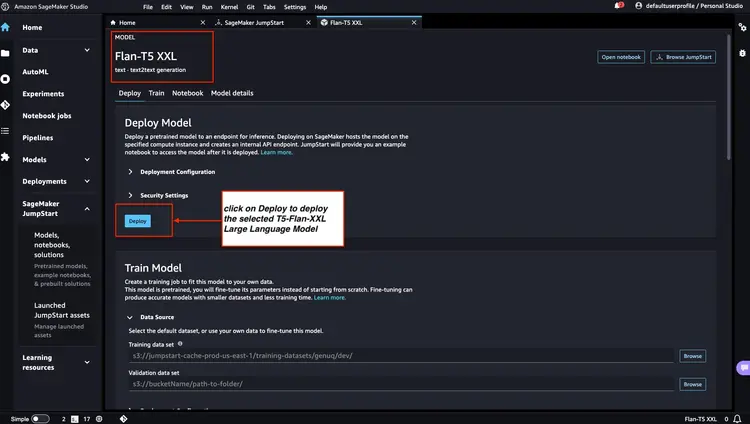
Comprobamos el estado de los puntos de conexión del modelo implementados en los pasos 1 y 2 en la consola de Amazon SageMaker y anotamos sus nombres, ya que los usaremos en nuestro código. Así se ve mi consola después de implementar los puntos de conexión del modelo.
Paso 4: Crear un clúster de Amazon Open Search
Amazon OpenSearch es un servicio de búsqueda y análisis compatible con el algoritmo k-Nearest Neighbors (kNN). Esta función es fundamental para las búsquedas basadas en similitud y permite utilizar OpenSearch eficazmente como base de datos vectorial. Para más información sobre las versiones de Elasticsearch/OpenSearch compatibles con el plugin kNN, consulte el siguiente enlace: Documentación del plugin k-NN.
Usamos la AWS CLI para implementar el archivo de plantilla de AWS CloudFormation desde la ubicación de GitHub. Infraestructura/opensearch-vectordb.yaml Utilizaremos el comando aws. pila de creación de Cloudformation Ejecute el siguiente comando para crear un clúster de Amazon Open Search. Debe reemplazar los valores por los suyos antes de ejecutar el comando. nombre de usuario y contraseña Vamos a hacerlo.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> Paso 5: Crear el flujo de trabajo de captura e incrustación de documentos
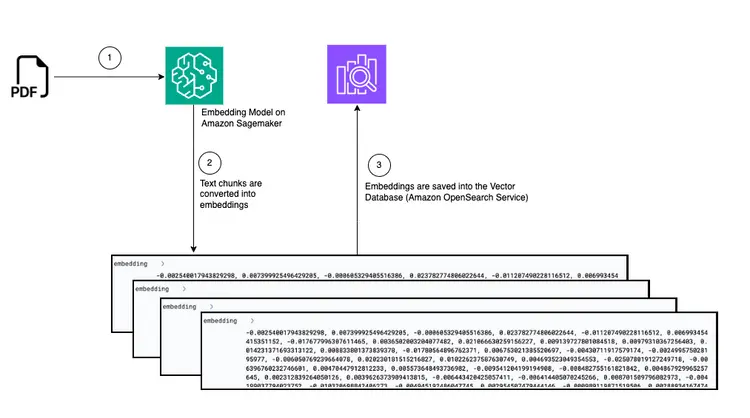
En este paso, crearemos una canalización de ingesta y procesamiento diseñada para leer un documento PDF cuando se almacena en un bucket de Amazon Simple Storage Service (S3). Esta canalización realizará las siguientes tareas:
- Extraer texto del documento PDF.
- Convertir fragmentos de texto en incrustaciones (representaciones vectoriales).
- Guardar incrustaciones en Amazon Open Search.
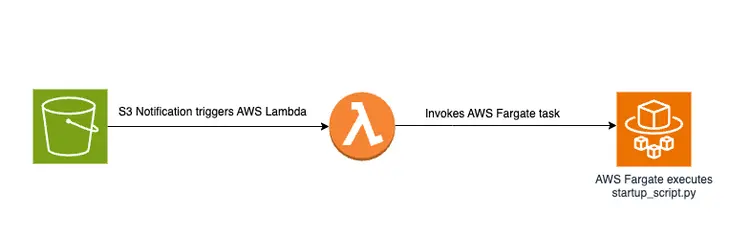
Al colocar un archivo PDF en un bucket de S3, se activará un flujo de trabajo basado en eventos que incluye un trabajo de AWS Fargate. Este trabajo se encargará de convertir el texto en incrustaciones e insertarlas en Amazon Open Search.
Descripción esquemática
A continuación se muestra un diagrama que muestra el proceso de transferencia de documentos para almacenar fragmentos de texto incrustados en la base de datos de vectores de Amazon OpenSearch:
Script de inicio y estructura de archivos
La lógica principal del archivo crear-incrustaciones-guardar-en-vectordb\startup_script.py Este script de Python se encuentra en script de inicio.pyRealiza diversas tareas relacionadas con el procesamiento de documentos, la incrustación de texto y la inserción en un clúster de Amazon Open Search. El script descarga un documento PDF de un bucket de Amazon S3 y lo divide en fragmentos de texto más pequeños. Para cada fragmento, el contenido de texto se envía al punto de enlace del modelo de incrustación GPT-J 6B FP16 implementado en Amazon SageMaker (obtenido de la variable de entorno TEXT_EMBEDDING_MODEL_ENDPOINT_NAME) para crear incrustaciones de texto. Las incrustaciones creadas se colocan en el índice de Amazon Open Search junto con otra información. El script recupera los parámetros de configuración y validación de las variables de entorno y los mantiene consistentes en todos los entornos. El script está diseñado para ejecutarse de forma uniforme en un contenedor Docker.
Construir y publicar la imagen de Docker
Después de comprender el código en script de inicio.py, construimos el Dockerfile desde la carpeta crear-incrustaciones-guardar-en-vectordb Continuaremos y subiremos la imagen a Amazon Elastic Container Registry (Amazon ECR). Amazon Elastic Container Registry (Amazon ECR) es un registro de contenedores completamente administrado que ofrece alojamiento de alto rendimiento, lo que nos permite implementar imágenes y artefactos de aplicaciones de forma fiable en cualquier lugar. Usaremos la CLI de AWS y la CLI de Docker para crear y subir la imagen de Docker a Amazon ECR. En todos los comandos siguientes, Reemplace con el número de cuenta de AWS correcto.
Recupere un token de autenticación y autentique el cliente Docker en el registro en la AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com Construya su imagen de Docker usando el siguiente comando.
docker build -t save-embedding-vectordb .
Una vez que se complete la compilación, etiquete la imagen para que podamos enviarla a este repositorio:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Ejecute el siguiente comando para enviar esta imagen al nuevo repositorio de Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Una vez que la imagen de Docker se carga en el repositorio de Amazon ECR, debería verse como la siguiente imagen:
Construir una infraestructura para un flujo de trabajo de incrustación de PDF basado en eventos
Podemos usar la interfaz de línea de comandos de AWS (AWS CLI) para crear una pila de CloudFormation para un flujo de trabajo basado en eventos con los parámetros proporcionados. La plantilla de CloudFormation está disponible en el repositorio de GitHub en Infraestructura/fargate-embeddings-vectordb-save.yaml Necesitamos ignorar los parámetros para que coincidan con el entorno de AWS.
Aquí están los parámetros clave para actualizar en el comando pila de creación de AWS CloudFormation Se afirma:
- BucketName: este parámetro representa el bucket de Amazon S3 donde colocaremos los documentos PDF.
- VpcId y SubnetId: estos parámetros especifican dónde se ejecutará la tarea de Fargate.
- ImageName: este es el nombre de la imagen de Docker en Amazon Elastic Container Registry (ECR) para save-embedding-vectordb.
- TextEmbeddingModelEndpointName: utilice este parámetro para proporcionar el nombre del modelo de incrustación implementado en Amazon SageMaker en el paso 1.
- VectorDatabaseEndpoint: especifique la dirección del punto final del dominio de Amazon OpenSearch.
- VectorDatabaseUsername y VectorDatabasePassword: estos parámetros son para las credenciales necesarias para acceder al clúster de Amazon Open Search creado en el paso 4.
- VectorDatabaseIndex: establece el nombre del índice en Amazon Open Search donde se almacenan las incrustaciones de documentos PDF.
Para ejecutar la creación de la pila de CloudFormation, después de actualizar los valores de los parámetros, utilizamos el siguiente comando de AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualAl crear la pila de CloudFormation mencionada anteriormente, configuramos un bucket S3 y creamos notificaciones S3 que lanzan una función Lambda. Esta función Lambda, a su vez, inicia una tarea Fargate. Esta tarea Fargate crea un contenedor Docker con el archivo. script de inicio.py Implementa que se encarga de crear incrustaciones en Amazon OpenSearch bajo un nuevo índice de OpenSearch llamado manual del coche Es.
Prueba con una muestra en PDF
Una vez que la pila de CloudFormation esté en ejecución, inserte un PDF con el manual de la máquina en su bucket de S3. Descargué un manual de la máquina disponible aquí. Una vez finalizada la ejecución de la canalización de transporte basada en eventos, el clúster de Amazon Open Search debería contener el siguiente perfil: manual del coche Con las incrustaciones que se muestran a continuación.
Paso 6: Implementar la API de preguntas y respuestas en tiempo real con soporte de texto Llm
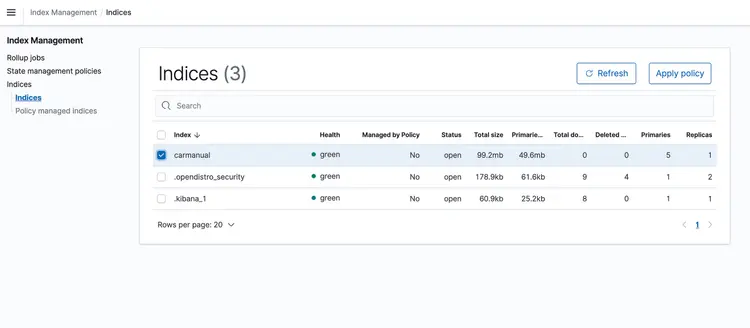
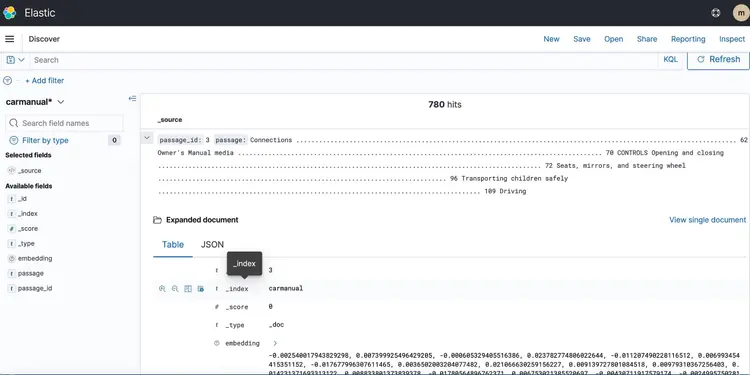
Ahora que tenemos nuestras incrustaciones de texto en una base de datos vectorial impulsada por Amazon Open Search, pasemos al siguiente paso. Aquí, usaremos las funciones del T5 Flan XXL LLM para obtener respuestas en tiempo real sobre el manual de nuestro coche.
Utilizamos las incrustaciones almacenadas en la base de datos vectorial para contextualizar LLM. Este contexto permite a LLM comprender y responder eficazmente a preguntas sobre el manual de nuestro vehículo. Para ello, utilizaremos un framework llamado LangChain, que simplifica la coordinación de los diversos componentes necesarios para nuestro sistema de preguntas y respuestas en tiempo real y con reconocimiento de texto, diseñado por LLM.
Las incrustaciones almacenadas en una base de datos vectorial representan el significado y las relaciones de las palabras y permiten realizar cálculos basados en similitudes semánticas. Mientras que las incrustaciones crean representaciones vectoriales de fragmentos de texto para capturar significados y relaciones, T5 Flan LLM se especializa en crear respuestas contextuales basadas en el contexto introducido en solicitudes y consultas. El objetivo es vincular las preguntas del usuario con fragmentos de texto mediante la creación de incrustaciones para las preguntas y la medición de su similitud con otras incrustaciones almacenadas en la base de datos vectorial.
Al representar fragmentos de texto y consultas de usuario como vectores, podemos realizar cálculos matemáticos para realizar búsquedas de similitud contextuales. Para medir la similitud entre dos puntos de datos, utilizamos métricas de distancia en un espacio multidimensional.
El siguiente diagrama muestra el flujo de trabajo de preguntas y respuestas en tiempo real proporcionado por LangChain y nuestro T5 Flan LLM.
Descripción gráfica del soporte de preguntas y respuestas en tiempo real de T5-Flan-XXL LLM
Construir la API
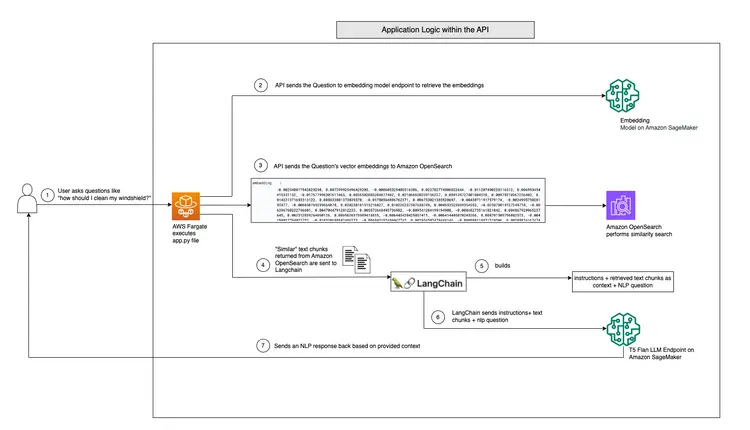
Ahora que hemos revisado nuestro flujo de trabajo LLM de LangChain y T5 Flask, analicemos a fondo el código de nuestra API, que acepta preguntas de los usuarios y proporciona respuestas contextuales. Esta API de preguntas y respuestas en tiempo real se encuentra en la carpeta RAG-langchain-questionanswer-t5-llm de nuestro repositorio de GitHub, y su lógica principal se encuentra en el archivo app.py. Esta aplicación basada en Flask define una ruta /qa para responder preguntas.
Cuando un usuario envía una consulta a la API, esta utiliza la variable de entorno TEXT_EMBEDDING_MODEL_ENDPOINT_NAME y apunta a un endpoint de Amazon SageMaker para convertir la consulta en representaciones vectoriales numéricas llamadas incrustaciones. Estas incrustaciones capturan el significado semántico del texto.
La API también aprovecha Amazon OpenSearch para realizar búsquedas de similitud contextuales, lo que le permite extraer fragmentos de texto relevantes de la guía de trabajo del directorio de OpenSearch basándose en las incrustaciones obtenidas de las consultas de los usuarios. Tras este paso, la API llama al punto de enlace T5 Flan LLM, identificado por la variable de entorno T5FLAN_XXL_ENDPOINT_NAME, que también se implementa en Amazon SageMaker. El punto de enlace utiliza los fragmentos de texto obtenidos de Amazon OpenSearch como contexto para generar respuestas. Estos fragmentos de texto obtenidos de Amazon OpenSearch actúan como contexto valioso para el punto de enlace T5 Flan LLM, lo que le permite proporcionar respuestas significativas a las consultas de los usuarios. El código de la API utiliza LangChain para orquestar todas estas interacciones.
Construya y publique la imagen de Docker para la API
Tras comprender el código en app.py, procedemos a compilar el Dockerfile desde la carpeta RAG-langchain-questionanswer-t5-llm y a enviar la imagen a Amazon ECR. Usaremos AWS CLI y Docker CLI para compilar y enviar la imagen de Docker a Amazon ECR. En todos los comandos siguientes: Reemplace con el número de cuenta de AWS correcto.
Recupere un token de autenticación y autentique el cliente Docker en el registro en la AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Construya la imagen de Docker usando el siguiente comando.
docker build -t qa-container .
Una vez que se complete la compilación, etiquete la imagen para que podamos enviarla a este repositorio:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Ejecute el siguiente comando para enviar esta imagen al nuevo repositorio de Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Una vez que la imagen de Docker se carga en el repositorio de Amazon ECR, debería verse como la siguiente imagen:
Cree una pila de CloudFormation para alojar el punto final de la API
Utilizaremos la interfaz de línea de comandos (CLI) de AWS para crear una pila de CloudFormation para un clúster de Amazon ECS que aloja una tarea de Fargate para exponer la API. La plantilla de CloudFormation se encuentra en el repositorio de GitHub en Infrastructure/fargate-api-rag-llm-langchain.yaml. Necesitamos sobrescribir los parámetros para que coincidan con el entorno de AWS. Estos son los parámetros clave que se deben actualizar en el comando aws cloudformation create-stack:
- DemoVPC: este parámetro especifica la nube privada virtual (VPC) en la que se ejecutará su servicio.
- PublicSubnetIds: este parámetro requiere una lista de ID de subredes públicas donde se ubicarán su balanceador de carga y sus tareas.
- NOMBREDELAIMAGEN: proporcione el nombre de la imagen de Docker en Amazon Elastic Container Registry (ECR) para el contenedor qa.
- TextEmbeddingModelEndpointName: especifique el nombre del punto final del modelo Embeddings implementado en Amazon SageMaker en el paso 1.
- T5FlanXXLEndpointName: establece el nombre del punto final T5-FLAN implementado en Amazon SageMaker en el paso 2.
- VectorDatabaseEndpoint: especifique la dirección del punto final del dominio de Amazon OpenSearch.
- VectorDatabaseUsername y VectorDatabasePassword: estos parámetros son para las credenciales necesarias para acceder al clúster OpenSearch creado en el paso 4.
- VectorDatabaseIndex: Establezca el nombre del índice en Amazon OpenSearch donde se almacenarán los datos de su servicio. El nombre del índice que usamos en este ejemplo es carmanual.
Para ejecutar la creación de la pila de CloudFormation, después de actualizar los valores de los parámetros, utilizamos el siguiente comando de AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualTras ejecutar correctamente la pila de CloudFormation mencionada anteriormente, acceda a la consola de AWS y a la pestaña "Salidas de CloudFormation" de la pila ecs-questionanswer-llm. En esta pestaña, encontrará la información necesaria, incluido el punto de conexión de la API. A continuación, se muestra un ejemplo de cómo se vería la salida:
Probar la API
Podemos probar el punto final de la API a través del comando curl de la siguiente manera:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
Veremos una respuesta como la siguiente.
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
Paso 7: Crear e implementar un sitio web con un chatbot integrado
Luego, pasamos al paso final de nuestra canalización completa, que integra la API con el chatbot integrado en un sitio web HTML. Para este sitio web y el chatbot integrado, nuestro código fuente es una aplicación Node.js que consta de un archivo index.html integrado con el archivo botkit.js de código abierto como chatbot. Para simplificar las cosas, he creado un Dockerfile y lo he incluido junto con el código en la carpeta homegrown_website_and_bot. Usaremos AWS CLI y Docker CLI para compilar y enviar la imagen de Docker a Amazon ECR para el sitio web frontend. En todos los comandos siguientes: Reemplace con el número de cuenta de AWS correcto.
Recupere un token de autenticación y autentique el cliente Docker en el registro en la AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Construya la imagen de Docker usando el siguiente comando:
docker build -t web-chat-frontend .
Una vez que se complete la compilación, etiquete la imagen para que podamos enviarla a este repositorio:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Ejecute el siguiente comando para enviar esta imagen al nuevo repositorio de Amazon ECR:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Tras subir la imagen de Docker del sitio web al repositorio de ECR, creamos la pila de CloudFormation para el frontend ejecutando el archivo Infrastructure\fargate-website-chatbot.yaml. Necesitamos sobrescribir los parámetros para que coincidan con el entorno de AWS. Estos son los parámetros clave que se deben actualizar en el comando aws cloudformation create-stack:
- DemoVPC: este parámetro especifica la nube privada virtual (VPC) donde se implementará su sitio web.
- PublicSubnetIds: este parámetro requiere una lista de ID de subredes públicas donde se colocarán las tareas y el balanceador de carga de su sitio web.
- NOMBREDELAIMAGEN: Ingrese el nombre de la imagen de Docker en Amazon Elastic Container Registry (ECR) para su sitio web.
- QUESTURL: Especifique la URL del punto final de la API implementado en el paso 6. Su formato es http:// Es /qa.
Para ejecutar la creación de la pila de CloudFormation, después de actualizar los valores de los parámetros, utilizamos el siguiente comando de AWS CLI:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaPaso 8: Consulta el Asistente de IA de Car Savvy
Tras crear correctamente la pila de CloudFormation mencionada anteriormente, acceda a la consola de AWS y a la pestaña "Salidas de CloudFormation" de la pila ecs-website-chatbot. En esta pestaña, encontrará el nombre DNS del balanceador de carga de aplicaciones (ALB) asociado al frontend. A continuación, se muestra un ejemplo de cómo se vería la salida:
Llama a la URL del punto final en el navegador para ver el aspecto del sitio web. Haz preguntas en lenguaje natural al chatbot integrado. Algunas preguntas que podemos hacer son: "¿Cómo limpio mi parabrisas?", "¿Dónde puedo encontrar el VIN?", "¿Cómo reporto un defecto de seguridad?".“
¿Qué sigue?

Esperamos que lo anterior te muestre cómo puedes crear tus propios pipelines listos para producción para LLM e integrarlos con tus chatbots frontend y NLP integrado. ¡Cuéntame qué más te gustaría leer sobre el uso de tecnologías de código abierto, analítica, aprendizaje automático y AWS!
A medida que continúe su aprendizaje, le animo a profundizar en Embeddings, Bases de Datos Vectoriales, LangChain y otros LLM. Están disponibles en Amazon SageMaker JumpStart, así como en las herramientas de AWS que usamos en este tutorial, como Amazon OpenSearch, Docker Containers y Fargate. Estos son algunos pasos a seguir para ayudarle a dominar estas tecnologías:
- Amazon SageMaker: a medida que avance con SageMaker, familiarícese con los otros algoritmos que ofrece.
- BÚSQUEDA ABIERTA DE AMAZON: Conozca el algoritmo K-NN y otros algoritmos de distancia
- Langchain: LangChain es un marco diseñado para simplificar la creación de aplicaciones utilizando LLM.
- Incrustaciones: una incrustación es una representación numérica de una pieza de información, por ejemplo, texto, documentos, imágenes, audio, etc.
- Amazon SageMaker JumpStart: SageMaker JumpStart ofrece modelos de código abierto previamente entrenados para una amplia gama de tipos de problemas para ayudarlo a comenzar con el aprendizaje automático.
Borrar
- Inicie sesión en la AWS CLI. Asegúrese de que esté configurada correctamente con los permisos necesarios para realizar estas acciones.
- Elimine el archivo PDF de su bucket de Amazon S3 ejecutando el siguiente comando. Reemplace el nombre de su bucket con el nombre real de su bucket de Amazon S3 y ajuste la ruta del archivo PDF si es necesario.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
Elimina las pilas de CloudFormation. Reemplaza los nombres de las pilas con los nombres reales de tus pilas de CloudFormation.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2Resultado
En este tutorial, creamos un chatbot de preguntas y respuestas integral con tecnologías de AWS y herramientas de código abierto. Integramos Amazon OpenSearch como base de datos vectorial, un modelo de incrustación GPT-J 6B FP16 y usamos Langchain con un LLM. El chatbot extrae información de documentos no estructurados.









