









Introducción
DeepSeek R1 ha revolucionado la comunidad de IA/ML en las últimas semanas, y con razón, e incluso se ha extendido a nivel mundial, con importantes implicaciones para la economía y las políticas. Esto se debe en gran medida al código abierto del conjunto de modelos y al precio increíblemente bajo del entrenamiento, lo que ha demostrado a la comunidad que entrenar modelos de IA SOTA no requiere tanto capital ni tanta investigación como se creía.
En la primera parte de esta serie, presentamos DeepSeek R1 y mostramos cómo ejecutar el modelo con Olama. En esta continuación, comenzaremos profundizando en lo que hace a R1 tan especial. Nos centraremos en analizar el paradigma único de aprendizaje por refuerzo (RL) del modelo para ver cómo se pueden fomentar las capacidades de razonamiento de los LLM únicamente mediante el RL. Posteriormente, explicaremos cómo la incorporación de estas técnicas en otros modelos nos permite compartir estas capacidades con las versiones existentes. Finalizaremos con una breve demostración de cómo configurar y ejecutar modelos de DeepSeek R1 con GPU Droplets utilizando el modelo de un solo clic de GPU Droplets.
Requisitos previos
- Aprendizaje profundo: Este artículo cubre temas intermedios y avanzados relacionados con el entrenamiento de redes neuronales y el aprendizaje de refuerzo.
- Cuenta de DigitalOcean: Utilizaremos específicamente las gotas de GPU del modelo de 1 clic HuggingFace de DigitalOcean para probar R1.
Descripción general de DeepSeek R1
El proyecto de investigación DeepSeek R1 se propuso recrear las capacidades de razonamiento efectivas demostradas por modelos de razonamiento potentes, como el O1 de OpenAI. Para lograrlo, buscaron mejorar su trabajo actual, DeepSeek-v3-Base, mediante aprendizaje por refuerzo puro. Esto condujo al surgimiento de DeepSeek R1 Zero, que muestra un excelente rendimiento en las métricas de razonamiento, pero carece de capacidades de interpretación humana y presenta algunos comportamientos inusuales, como la mezcla de idiomas.
Para solucionar estos problemas, propusieron DeepSeek R1, que implica una pequeña cantidad de datos de arranque en frío y un proceso de entrenamiento multietapa. R1 logró la legibilidad y aplicabilidad de SOTA LLM mediante el ajuste fino del modelo DeepSeek-v3-Base en miles de muestras de datos de arranque en frío, la ejecución de otra ronda de aprendizaje por refuerzo, seguida de un ajuste fino supervisado en el conjunto de datos de argumentos y, finalmente, una ronda final de aprendizaje por refuerzo. Posteriormente, aplicaron esta técnica a otros modelos supervisando su ajuste fino en los datos recopilados por R1.
Manténgase atento para obtener una visión más profunda de estas etapas de desarrollo y una discusión sobre cómo se puede mejorar iterativamente el modelo para alcanzar las capacidades de DeepSeek R1.
Tutorial de DeepSeek R1 Zero
Para crear DeepSeek R1 Zero, el modelo base a partir del cual se desarrolló R1, los investigadores aplicaron RL directamente al modelo base sin datos de SFT. El paradigma de RL elegido se denomina optimización de políticas relativas a grupos (GRPO). Este proceso es una adaptación del artículo de DeepSeekMath.
GRPO es similar a los sistemas de aprendizaje automático conocidos y de otro tipo, pero difiere en un aspecto importante: no utiliza un modelo crítico. En su lugar, GRPO estima la línea base a partir de las puntuaciones del grupo. El modelado de recompensas cuenta con dos reglas para este sistema, cada una de las cuales recompensa la precisión y la adherencia de la plantilla a un patrón. La recompensa sirve entonces como fuente de señales de entrenamiento que se utilizan para cambiar la dirección de la optimización del aprendizaje automático. Este sistema basado en reglas permite que el proceso de aprendizaje automático refine y mejore el modelo iterativamente.

La plantilla de entrenamiento es un formato escrito simple que guía al modelo base para seguir las instrucciones especificadas anteriormente. El modelo mide las respuestas al "anuncio" establecido para cada paso del aprendizaje a distancia. "Este es un logro significativo, ya que destaca la capacidad del modelo para aprender y generalizar eficazmente únicamente mediante el aprendizaje a distancia" (fuente).
Esta autoevolución del modelo lo lleva a desarrollar potentes capacidades de razonamiento, incluyendo la autorreflexión y la consideración de enfoques alternativos. Esto se ve reforzado por un momento durante el entrenamiento que el equipo de investigación del modelo denomina "momento revelador". Durante esta fase, DeepSeek-R1-Zero aprende a dedicar más tiempo a pensar en un problema reevaluando su enfoque inicial. Este comportamiento no solo demuestra el desarrollo de las capacidades de razonamiento del modelo, sino también un ejemplo fascinante de cómo el aprendizaje por refuerzo puede generar resultados inesperados y complejos. (Fuente).
DeepSeek R1 Zero tuvo un excelente rendimiento en las pruebas de referencia, pero tuvo deficiencias importantes en legibilidad y usabilidad en comparación con los LLM adecuados y fáciles de usar. Por ello, el equipo de investigación propuso DeepSeek R1 para optimizar el modelo para tareas de nivel humano.
De DeepSeek R1 Zero a DeepSeek R1
Para pasar del relativamente indómito DeepSeek R1 Zero al mucho más funcional DeepSeek R1, los investigadores introdujeron varias etapas de entrenamiento.
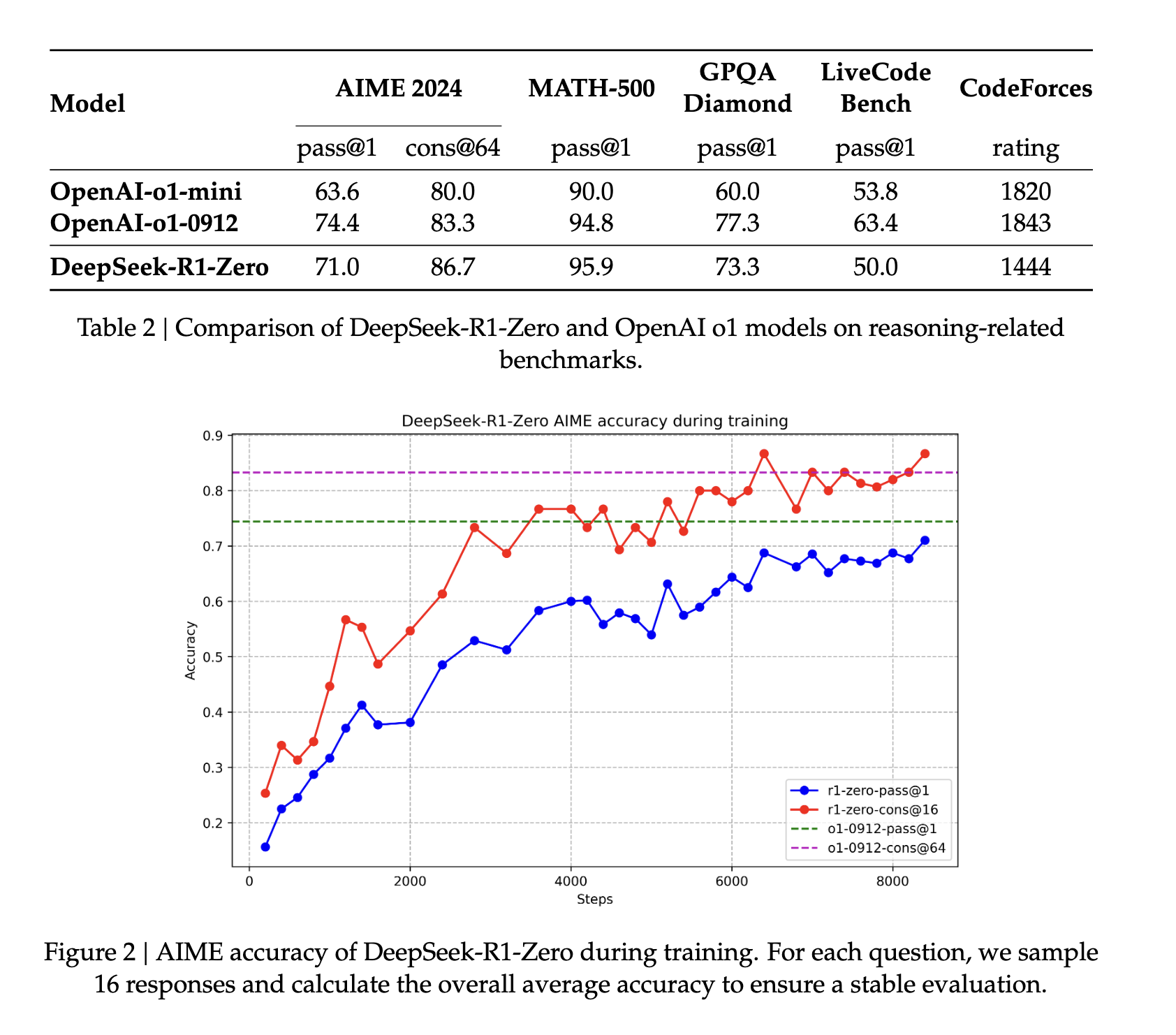
Para empezar, DeepSeek-v3-Base se afinó con miles de datos de arranque en frío antes de ejecutar el mismo paradigma de aprendizaje automático (RL) utilizado para DeepSeek R1 Zero, con la ventaja adicional de un lenguaje consistente en los resultados. En la práctica, este paso mejora la capacidad de razonamiento del modelo, especialmente en tareas de razonamiento como programación, matemáticas, ciencias y razonamiento lógico, que implican problemas bien definidos con soluciones claras (fuente).
Una vez finalizada esta fase de aprendizaje por repetición (RL), el modelo resultante se utiliza para recopilar nuevos datos para un ajuste fino supervisado. «A diferencia de los datos iniciales de arranque en frío, que se centran principalmente en el razonamiento, esta fase combina datos de otros dominios para mejorar las capacidades del modelo en la escritura, la representación de roles y otras tareas generales» (fuente).
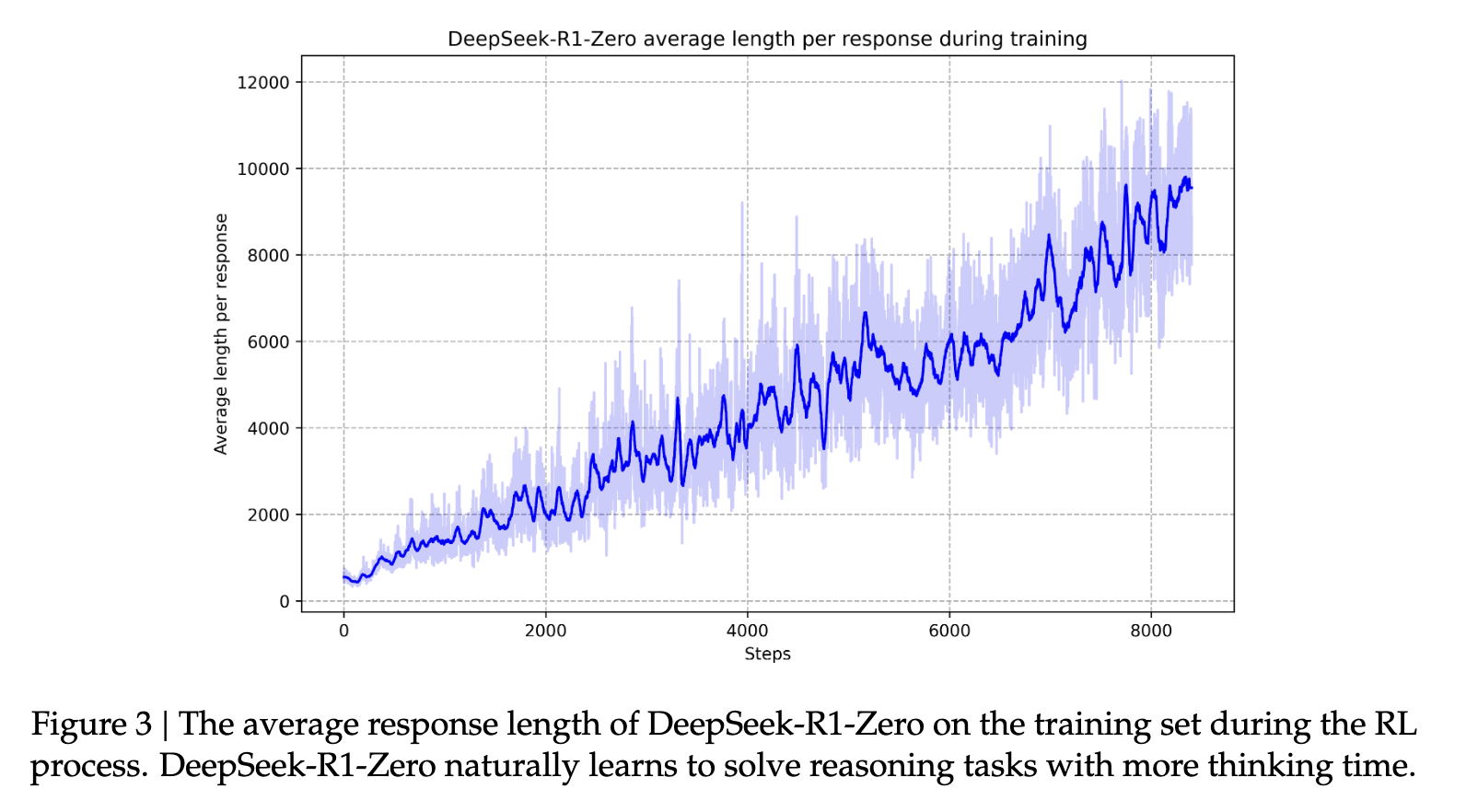
A continuación, se implementa la segunda etapa del aprendizaje por refuerzo (RL) para mejorar la utilidad e inocuidad del modelo, a la vez que se refinan sus capacidades de razonamiento (fuente). Al entrenar el modelo en diversas distribuciones rápidas con señales de recompensa, se puede entrenar un modelo que destaca en el razonamiento, priorizando la utilidad y la inocuidad. Esto ayuda a los modelos a adquirir una capacidad de respuesta similar a la humana, lo que ayuda al modelo a desarrollar las increíbles capacidades de razonamiento que lo caracterizan. Con el tiempo, este proceso ayuda al modelo a desarrollar largas cadenas de pensamiento y razonamiento que lo caracterizan.
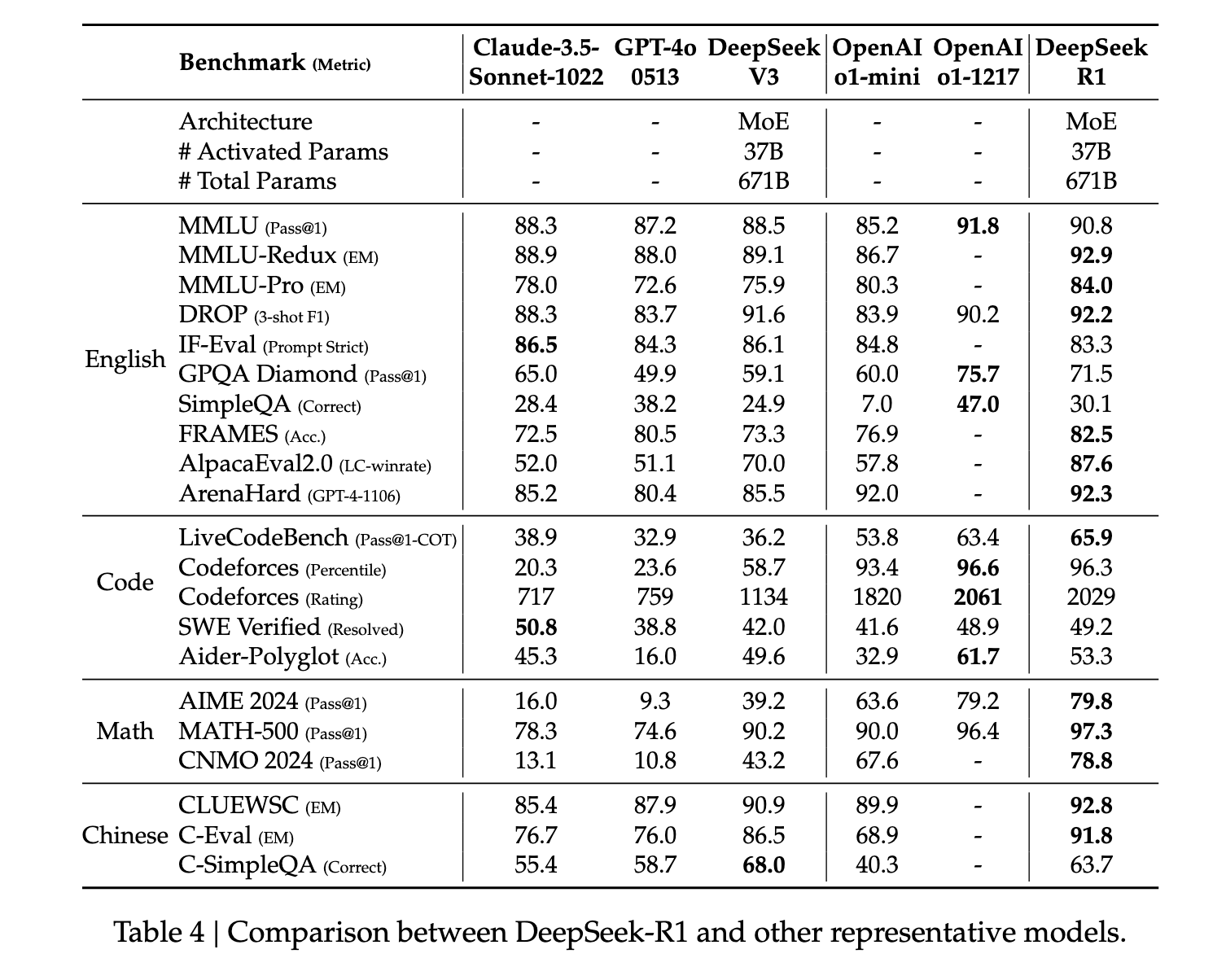
En general, R1 muestra un rendimiento de vanguardia en las medidas de razonamiento. En algunas tareas, como matemáticas, incluso ha demostrado superar los parámetros publicados para O1. En general, también presenta un rendimiento muy sólido en preguntas relacionadas con STEM, lo cual se atribuye principalmente al aprendizaje por refuerzo a gran escala. Además de las materias STEM, el modelo es altamente competente para responder preguntas, tareas educativas y razonamiento complejo. Los autores argumentan que estas mejoras y mayores capacidades se deben a la evolución de los modelos de procesamiento de cadenas de pensamiento mediante el aprendizaje por refuerzo. Los datos de cadenas de pensamiento largas se utilizan durante el aprendizaje por refuerzo y el ajuste para estimular al modelo a producir resultados más largos e introspectivos.
Modelos destilados de DeepSeek R1
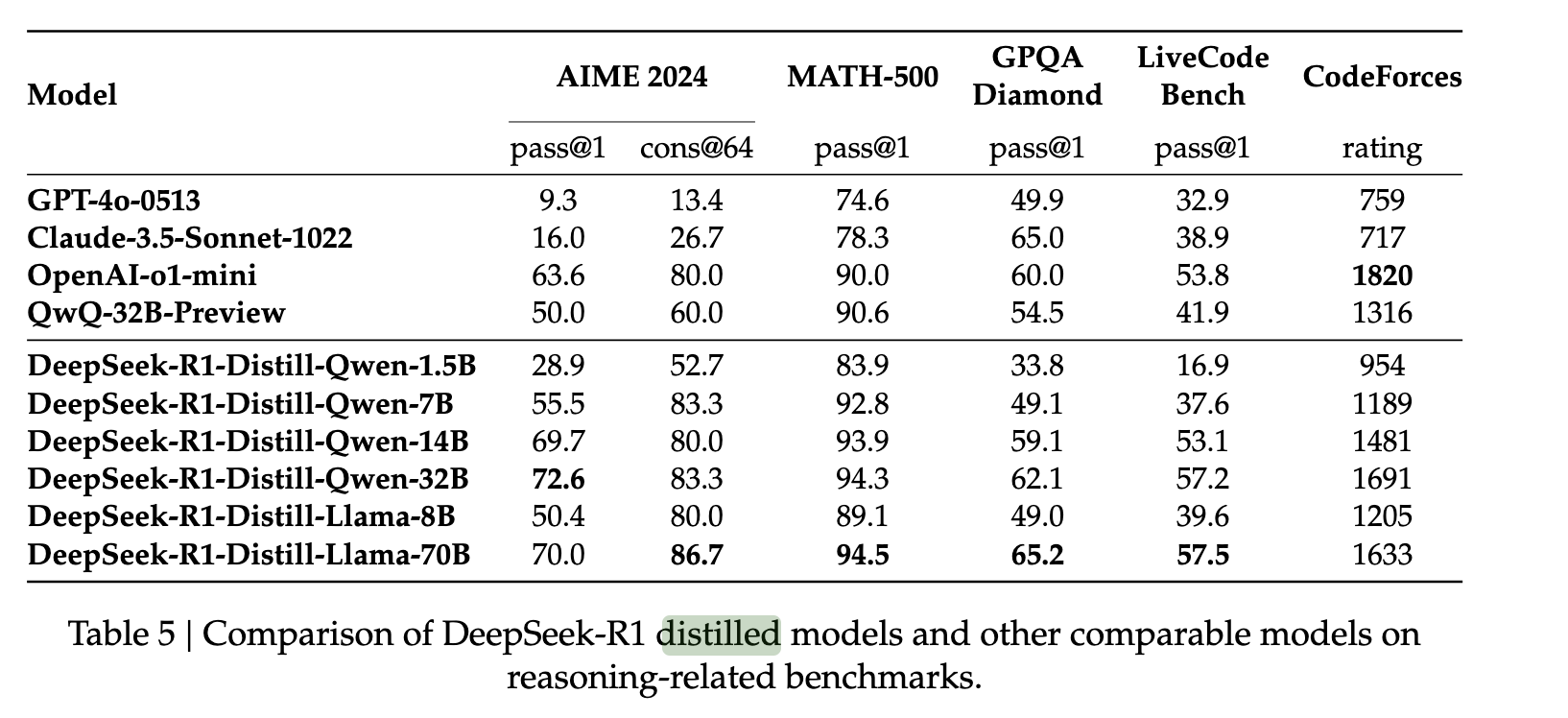 Para ampliar las capacidades de DeepSeek R1 a modelos más pequeños, los autores recopilaron 800.000 ejemplos de DeepSeek R1 y los utilizaron para perfeccionar modelos como QWEN y LLAMA. Descubrieron que este método de destilación relativamente sencillo permitió transferir las capacidades de razonamiento de R1 a estos nuevos modelos con un alto grado de éxito. Lo lograron sin necesidad de RL adicional, lo que demuestra la robustez de las respuestas del modelo original a la destilación.
Para ampliar las capacidades de DeepSeek R1 a modelos más pequeños, los autores recopilaron 800.000 ejemplos de DeepSeek R1 y los utilizaron para perfeccionar modelos como QWEN y LLAMA. Descubrieron que este método de destilación relativamente sencillo permitió transferir las capacidades de razonamiento de R1 a estos nuevos modelos con un alto grado de éxito. Lo lograron sin necesidad de RL adicional, lo que demuestra la robustez de las respuestas del modelo original a la destilación.
Lanzamiento de DeepSeek R1 en Droplets de GPU
Configurar DeepSeek R1 en Droplets de GPU es muy sencillo si ya tienes una cuenta de DigitalOcean. Asegúrate de iniciar sesión antes de continuar.
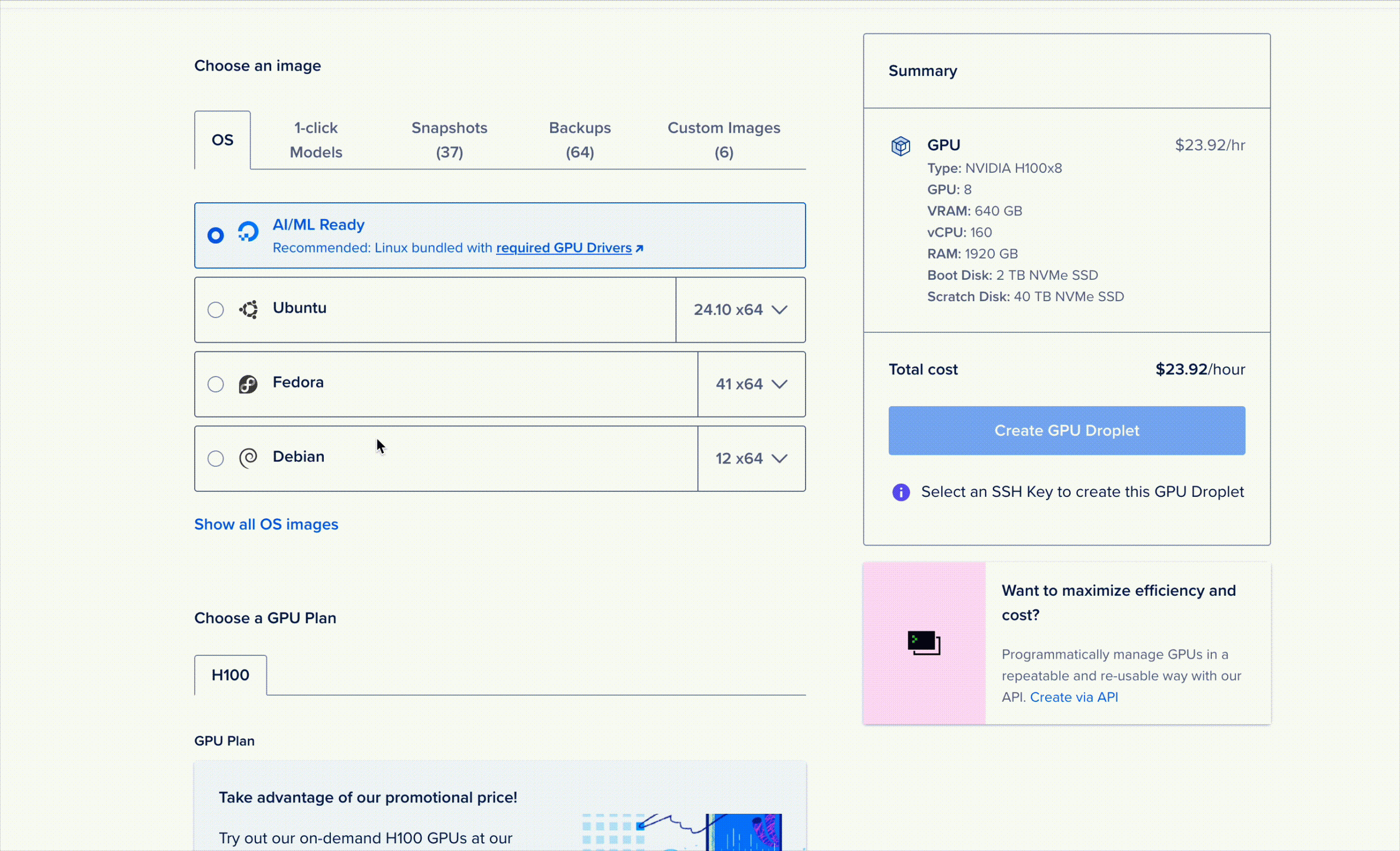
Ofrecemos acceso a R1 como una Droplet de GPU de Modelos de un Clic. Para iniciarla, simplemente abra la consola de Droplets de GPU, vaya a la pestaña "Modelos de un Clic" en la ventana de selección de modelos e inicie el dispositivo.
Desde allí, se podrá acceder al modelo mediante los métodos HuggingFace u OpenAI para comunicarse con él. Utilice el siguiente script para interactuar con su modelo mediante código Python.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)Como alternativa, hemos creado un asistente personal personalizado que se ejecuta en el mismo sistema. Recomendamos usar el asistente personal para estas tareas, ya que simplifica en gran medida la interacción directa con el modelo al mostrar todo en una ventana gráfica intuitiva. Para obtener más información sobre el uso del script del asistente personal, consulte este tutorial.
Resultado
En conclusión, R1 representa un avance para la comunidad de desarrollo LLM. Su proceso promete ahorrar millones de dólares en costos de capacitación, a la vez que ofrece un rendimiento comparable o incluso superior al de los modelos avanzados de código cerrado. Seguiremos de cerca el desarrollo de DeepSeek a medida que su modelo gana reconocimiento internacional.









