









Introducción
Imagine una base de datos que no solo almacena datos, sino que también los comprende. En los últimos años, las aplicaciones de IA han revolucionado casi todas las industrias y han cambiado el futuro de la informática.
Las bases de datos vectoriales transforman la forma en que gestionamos los datos no estructurados, permitiéndonos almacenar el conocimiento de forma que capture relaciones, similitudes y contexto. A diferencia de las bases de datos tradicionales, que se basan principalmente en datos estructurados almacenados en tablas y se centran en coincidencias exactas, las bases de datos vectoriales nos permiten almacenar datos no estructurados (como imágenes, texto y audio) en un formato que los modelos de aprendizaje automático pueden comprender y comparar.
En lugar de depender de coincidencias exactas, las bases de datos vectoriales pueden encontrar las coincidencias más cercanas y facilitar la recuperación eficiente de elementos alternativos o semánticamente similares. En la era actual, donde la inteligencia artificial lo impulsa todo, las bases de datos vectoriales se han vuelto esenciales para aplicaciones como grandes modelos de lenguaje y modelos de aprendizaje automático que generan y procesan incrustaciones.
¿Qué es la incrustación? Lo explicaremos en breve en este artículo.
Ya sea para sistemas de recomendación o para potenciar la IA conversacional, las bases de datos vectoriales se han convertido en una poderosa solución de almacenamiento de datos que nos permite acceder e interactuar con los datos de formas nuevas y emocionantes.
Ahora veamos qué bases de datos se utilizan con más frecuencia:
- SQL: Almacena datos estructurados y utiliza tablas para almacenar datos con un esquema definido. Los más comunes son MySQL, Oracle Database y PostgreSQL.
- NoSQL: Es una base de datos muy flexible y sin esquema. También es conocida por manejar datos no estructurados o semiestructurados. Ha sido excelente para muchas aplicaciones web en tiempo real y big data. Las más comunes son MongoDB y Cassandra.
- Gráfico: Luego surgió Gráfico, que almacena datos como nodos y aristas y está diseñado para gestionar datos interconectados. Ejemplos: Neo4j, ArangoDB.
- Vector: Bases de datos diseñadas para almacenar y consultar vectores de alta dimensión, lo que permite la búsqueda por similitud y la mejora de las tareas de IA/ML. Las más comunes son Pinecone, Weaviate y Chroma.
Requisitos previos
- Conocimiento de medidas de similitud: comprensión de medidas como la similitud del coseno, la distancia euclidiana o el producto escalar para comparar datos vectoriales.
- Conceptos básicos de ML y IA: conocimiento de modelos y aplicaciones de aprendizaje automático, especialmente aquellos que generan incrustaciones (por ejemplo, PNL, visión artificial).
- Familiaridad con los conceptos de bases de datos: conocimiento general de bases de datos, incluidos los principios de indexación, consulta y almacenamiento de datos.
- Habilidades de programación: Competencia en Python o lenguajes similares comúnmente utilizados en bibliotecas ML y bases de datos vectoriales.
¿Por qué utilizamos bases de datos vectoriales y en qué se diferencian?
Supongamos que almacenamos datos en una base de datos SQL tradicional, donde cada punto de datos se convierte en una incrustación y se almacena. Al crear una consulta, también se convierte en una incrustación, y luego intentamos encontrar las más relevantes comparando esta incrustación de la consulta con las incrustaciones almacenadas mediante la similitud de cosenos.
Sin embargo, este método puede resultar ineficaz por varias razones:
- Alta dimensionalidad: Las incrustaciones suelen ser de alta dimensionalidad. Esto puede provocar tiempos de consulta lentos, ya que cada comparación puede requerir una búsqueda completa de todas las incrustaciones almacenadas.
- Problemas de escalabilidad: El coste computacional de calcular la similitud de cosenos entre millones de incrustaciones resulta prohibitivo con conjuntos de datos grandes. Las bases de datos SQL tradicionales no están optimizadas para esta tarea, lo que dificulta la recuperación en tiempo real.
Por lo tanto, una base de datos tradicional puede tener dificultades para realizar búsquedas eficientes a gran escala. Además, una cantidad significativa de datos generados diariamente no están estructurados y no pueden almacenarse en bases de datos tradicionales.

Para solucionar este problema, utilizamos una base de datos vectorial. En una base de datos vectorial, existe el concepto de índice, que permite una búsqueda eficiente de similitudes para datos de alta dimensión. Al organizar las incrustaciones vectoriales, este concepto desempeña un papel importante en la aceleración de las consultas y permite que la base de datos recupere rápidamente vectores similares a un vector de consulta, incluso en conjuntos de datos grandes. Los índices vectoriales reducen el espacio de búsqueda y permiten escalar a millones o miles de millones de vectores. Esto permite una respuesta rápida a las consultas incluso en conjuntos de datos grandes.
En las bases de datos tradicionales, buscamos filas que coincidan con nuestra consulta. En las bases de datos vectoriales, utilizamos medidas de similitud para encontrar el vector más similar a nuestra consulta.
Las bases de datos vectoriales utilizan una combinación de algoritmos para la búsqueda por vecino más cercano aproximado (RNA) que optimizan la búsqueda mediante hash, cuantificación o métodos basados en grafos. Estos algoritmos trabajan en conjunto para proporcionar resultados rápidos y precisos. Dado que las bases de datos vectoriales proporcionan coincidencias aproximadas, existe un equilibrio entre precisión y velocidad: una mayor precisión puede ralentizar la consulta.
Fundamentos de las representaciones vectoriales
¿Qué son los vectores?
Los vectores pueden considerarse matrices de números almacenados en una base de datos. Cualquier tipo de dato, como imágenes, texto, archivos PDF y audio, puede convertirse en valores numéricos y almacenarse en una base de datos vectorial como una matriz. Esta representación numérica de los datos permite la búsqueda por similitud.
Antes de comprender los vectores, intentemos comprender la búsqueda semántica y las incrustaciones.
¿Qué es la búsqueda semántica?
La búsqueda semántica es una forma de buscar el significado de las palabras y el contexto en lugar de buscar frases exactas. En lugar de centrarse en la palabra clave, la búsqueda semántica intenta comprender el significado. Por ejemplo, la palabra "python". En una búsqueda tradicional, la palabra "python" podría mostrar resultados tanto para programación en Python como para serpientes en Python, ya que solo reconoce la palabra en sí. Con la búsqueda semántica, el motor busca el contexto. Si las búsquedas recientes se centraran en "lenguajes de programación" o "aprendizaje automático", probablemente mostraría resultados sobre programación en Python. Pero si las búsquedas se centraran en "animales extraños" o "reptiles", asumiría que las pitones eran serpientes y ajustaría los resultados en consecuencia.

Al identificar el contexto, la búsqueda semántica ayuda a revelar la información más relevante en función de la intención real.
¿Qué son las incrustaciones?
Las incrustaciones son una forma de representar palabras como vectores numéricos (por ahora, pensemos en los vectores como listas de números; por ejemplo, la palabra "gato" podría convertirse en [.1,.8,.75,.85]. En un espacio de alta dimensión, las computadoras procesan rápidamente esta representación numérica de una palabra.
Las palabras tienen diferentes significados y relaciones. Por ejemplo, en las incrustaciones de palabras, las palabras “rey” y “reina” tienen vectores similares a los de “rey” y “coche”.
Las incrustaciones pueden capturar el contexto de una palabra según su uso en oraciones. Por ejemplo, "banco" podría significar una institución financiera o la ribera de un río, y las incrustaciones ayudan a reconocer estos significados basándose en las palabras que la rodean. Las incrustaciones son una forma más inteligente para que las computadoras comprendan las palabras, sus significados y sus relaciones.
Una forma de considerar una incrustación es mapear las diferentes características de esa palabra y luego asignarles valores. Esto genera una secuencia de números llamada vector. Existen diversas técnicas para crear estas incrustaciones de palabras. Por lo tanto, una incrustación vectorial es una forma de representar una oración o un documento de palabras con números que pueden representar significado y relaciones. Las incrustaciones vectoriales permiten representar estas palabras como puntos en el espacio donde palabras similares están cerca unas de otras.
Estas incrustaciones vectoriales permiten operaciones matemáticas como la suma y la resta, que pueden utilizarse para capturar relaciones. Por ejemplo, la conocida operación vectorial “rey – hombre + mujer” puede generar un vector cercano a “reina”.
Criterios de similitud en espacios vectoriales
Para medir la similitud de cada vector, se utilizan herramientas matemáticas que cuantifican la similitud o disimilitud. Algunas de ellas se enumeran a continuación:
- Similitud de coseno: el coseno mide el ángulo entre dos vectores, que va de -1 a 1. Donde -1 significa exactamente opuestos, 1 significa vectores idénticos y 0 significa ortogonales o diferentes.
- Distancia euclidiana: Mide la distancia en línea recta entre dos puntos en el espacio vectorial. Los valores más bajos indican mayor similitud.
- Distancia Manhattan (Norma L1): Mide la distancia entre dos puntos sumando la diferencia absoluta de sus componentes correspondientes.
- Distancia de Minkowski: una generalización de las distancias euclidiana y de Manhattan.
Estas son las métricas de distancia o similitud más comunes utilizadas en los algoritmos de aprendizaje automático.
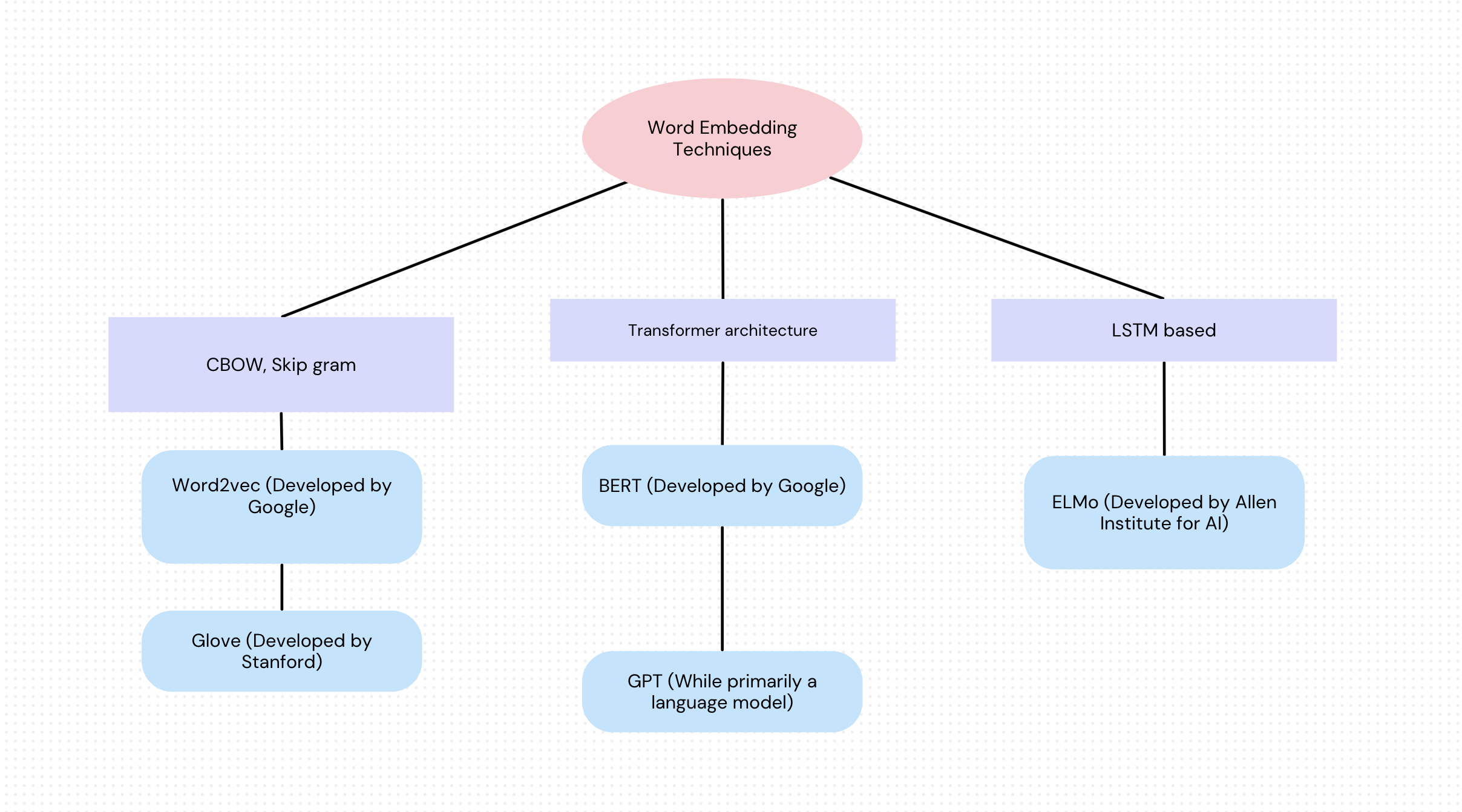
Bases de datos de vectores populares
A continuación se muestran algunas de las bases de datos vectoriales más populares que se utilizan ampliamente en la actualidad:
- Pinecone: Una base de datos vectorial completamente administrada, conocida por su facilidad de uso, escalabilidad y rápida búsqueda de vecinos más cercanos (RNA). Pinecone es conocida por su integración con flujos de trabajo de aprendizaje automático, especialmente con la búsqueda semántica y los sistemas de recomendación.
- FAISS (Búsqueda de similitudes con IA de Facebook): Desarrollada por Meta (anteriormente Facebook), FAISS es una biblioteca altamente optimizada para la búsqueda de similitudes y la agrupación de vectores densos. Es de código abierto, eficiente y se utiliza comúnmente en la investigación académica e industrial, especialmente para búsquedas de similitudes a gran escala.
- Weaviate: Una base de datos vectorial de código abierto, nativa de la nube, que admite funciones de búsqueda vectorial e híbrida. Weaviate es conocido por su integración con modelos de Hugging Face, OpenAI y Cohere, lo que lo convierte en una opción sólida para aplicaciones de búsqueda semántica y PLN.
- Milvus: Una base de datos vectorial de código abierto y altamente escalable, optimizada para aplicaciones de IA a gran escala. Milvus admite diversos métodos de indexación y cuenta con un amplio ecosistema de integraciones, lo que la hace popular para sistemas de recomendación en tiempo real y tareas de visión artificial.
- Qdrant: Una base de datos vectorial de alto rendimiento centrada en la facilidad de uso. Qdrant ofrece funciones como indexación en tiempo real y soporte distribuido. Está diseñada para gestionar datos de alta dimensión, lo que la hace ideal para motores de recomendación, personalización y tareas de PLN.
- Chroma: De código abierto y diseñado específicamente para aplicaciones LLM, Chroma proporciona un almacén de integración para LLM y admite búsquedas similares. Se utiliza a menudo con LangChain para IA conversacional y otras aplicaciones basadas en LLM.
Cosas que deberías usar
Ahora, revisemos algunos de los casos de uso de las bases de datos vectoriales.
- Las bases de datos vectoriales se pueden usar para agentes conversacionales que requieren almacenamiento en memoria a largo plazo. Esto se implementa fácilmente con Langchain y permite al agente conversacional consultar y almacenar el historial de conversaciones en una base de datos vectorial. A medida que los usuarios interactúan, el bot extrae fragmentos contextualmente relevantes de conversaciones anteriores, lo que mejora la experiencia del usuario.
- Las bases de datos vectoriales pueden utilizarse para la búsqueda semántica y la recuperación de información mediante la recuperación de documentos o textos semánticamente similares. Encuentran contenido textualmente relacionado con la consulta, en lugar de buscar coincidencias exactas con palabras clave.
- Plataformas como el comercio electrónico, la música en streaming o las redes sociales utilizan bases de datos vectoriales para generar recomendaciones. Al representar los artículos y preferencias del usuario como vectores, el sistema puede encontrar productos, canciones o contenido similar a sus intereses previos.
- Las plataformas de imágenes y vídeos utilizan bases de datos vectoriales para encontrar contenido visualmente similar.
Desafíos para las bases de datos vectoriales
- Escalabilidad y rendimiento: A medida que el volumen de datos sigue creciendo, mantener bases de datos vectoriales rápidas y escalables, a la vez que se mantiene la precisión, puede convertirse en un desafío. Equilibrar la velocidad y la precisión también puede ser un desafío potencial al generar resultados de búsqueda precisos.
- Intensidad de costos y recursos: las operaciones vectoriales de alta dimensión pueden consumir muchos recursos, lo que requiere hardware potente e indexación eficiente, lo que puede aumentar los costos de almacenamiento y computacionales.
- Disyuntiva entre precisión y aproximación: las bases de datos vectoriales utilizan técnicas de vecino más cercano (ANN) para lograr búsquedas más rápidas, pero pueden dar como resultado coincidencias aproximadas en lugar de exactas.
- Integración con sistemas tradicionales: la integración de bases de datos vectoriales con bases de datos tradicionales existentes puede ser un desafío, ya que utilizan diferentes estructuras de datos y métodos de recuperación.
Resultado
Las bases de datos vectoriales transforman la forma en que almacenamos y buscamos datos complejos, como imágenes, audio, texto y recomendaciones, al permitir búsquedas basadas en similitudes en espacios de alta dimensión. A diferencia de las bases de datos tradicionales, que requieren coincidencias exactas, las bases de datos vectoriales utilizan incrustaciones y puntuaciones de similitud para encontrar resultados lo suficientemente cercanos, lo que las hace ideales para aplicaciones como recomendaciones personalizadas, búsqueda semántica y detección de anomalías.









