









Introducción
Los métodos tradicionales de procesamiento y recepción de datos (como el procesamiento por lotes y el sondeo) son ineficientes en el contexto de los microservicios utilizados en aplicaciones modernas. Estos métodos operan con grandes cantidades de datos, lo que retrasa el resultado final de su procesamiento y obliga a acumular una cantidad significativa de datos antes de su procesamiento. Introducen la complejidad adicional necesaria para sincronizar los trabajadores y potencialmente dejan algunos de ellos infrautilizados a pesar del uso de recursos. Por el contrario, dado que la computación en la nube ofrece una rápida escalabilidad para los recursos locales, los datos entrantes pueden procesarse en tiempo real delegándolos a varios trabajadores en paralelo.
La transmisión de eventos es un enfoque que permite recopilar y delegar de forma flexible los eventos entrantes para su procesamiento, manteniendo al mismo tiempo un flujo continuo de datos entre diferentes sistemas. Programar los datos entrantes para su procesamiento inmediato garantiza la máxima utilización de recursos y una capacidad de respuesta en tiempo real. La transmisión de eventos separa a los productores de los consumidores, lo que permite tener un número desproporcionado de cada uno según la carga actual. Esto permite respuestas instantáneas a las condiciones dinámicas del mundo real.
Esta capacidad de respuesta puede ser especialmente importante en áreas como el comercio financiero, la monitorización de pagos o la supervisión del tráfico. Por ejemplo, Uber utiliza la transmisión de eventos para conectar cientos de microservicios, enviando datos de eventos desde las aplicaciones de pasajero a conductor en tiempo real y archivándolos para su posterior análisis.
Con la difusión de eventos, en lugar de que un trabajador espere un lote de datos a intervalos regulares, el agente de eventos puede notificar al consumidor (normalmente un microservicio) en cuanto ocurre el evento y proporcionarle los datos. El agente de eventos se encarga del enrutamiento, la recepción y la entrega de eventos. También proporciona tolerancia a fallos en caso de que un trabajador falle o se niegue a procesar un evento.
En este documento conceptual, exploraremos el enfoque de transmisión de eventos y sus beneficios. También presentaremos Apache Kafka, un gestor de eventos de código abierto, y examinaremos su papel en este enfoque.
Arquitectura del flujo de eventos
El flujo de eventos es, en esencia, una implementación del patrón arquitectónico pub/sub. En general, este patrón incluye:
- Los temas a los que se dirigen los mensajes (incluido cualquier dato que desee comunicar).
- Editores que producen mensajes
- Suscriptores que reciben mensajes y actúan sobre ellos
- Un agente de mensajes que acepta mensajes de los editores y los entrega a los suscriptores de la manera más eficiente.
Un tema es similar a una categoría a la que se asocia un mensaje. Los temas almacenan de forma persistente la secuencia de mensajes y garantizan que los nuevos mensajes siempre se añadan al final de la secuencia. Una vez que se añade un mensaje a un tema, no se puede modificar posteriormente.
En la retransmisión de eventos, la premisa es similar, aunque más especializada:
- Los eventos y metadatos relacionados se envían como mensajes.
- Los eventos de un tema generalmente se ordenan por hora de llegada.
- Los suscriptores (también llamados consumidores) pueden transmitir eventos desde cualquier punto del hilo hasta el momento actual.
- A diferencia del sistema de publicación/suscripción real, los eventos de un tema se pueden conservar durante un período de tiempo específico o de manera indefinida (como un archivo).
El flujo de eventos no impone restricciones ni hace suposiciones sobre la naturaleza de un evento. Para el agente subyacente, significa que un productor le ha notificado que algo ha sucedido. Lo que realmente sucedió depende de usted para definir y dar significado a su implementación. Por esta razón, desde la perspectiva del agente, los eventos se denominan mensajes o registros indistintamente.
Para ilustrarlo, aquí hay un diagrama detallado de la arquitectura del flujo de eventos de Kafka de la documentación de Confluent:
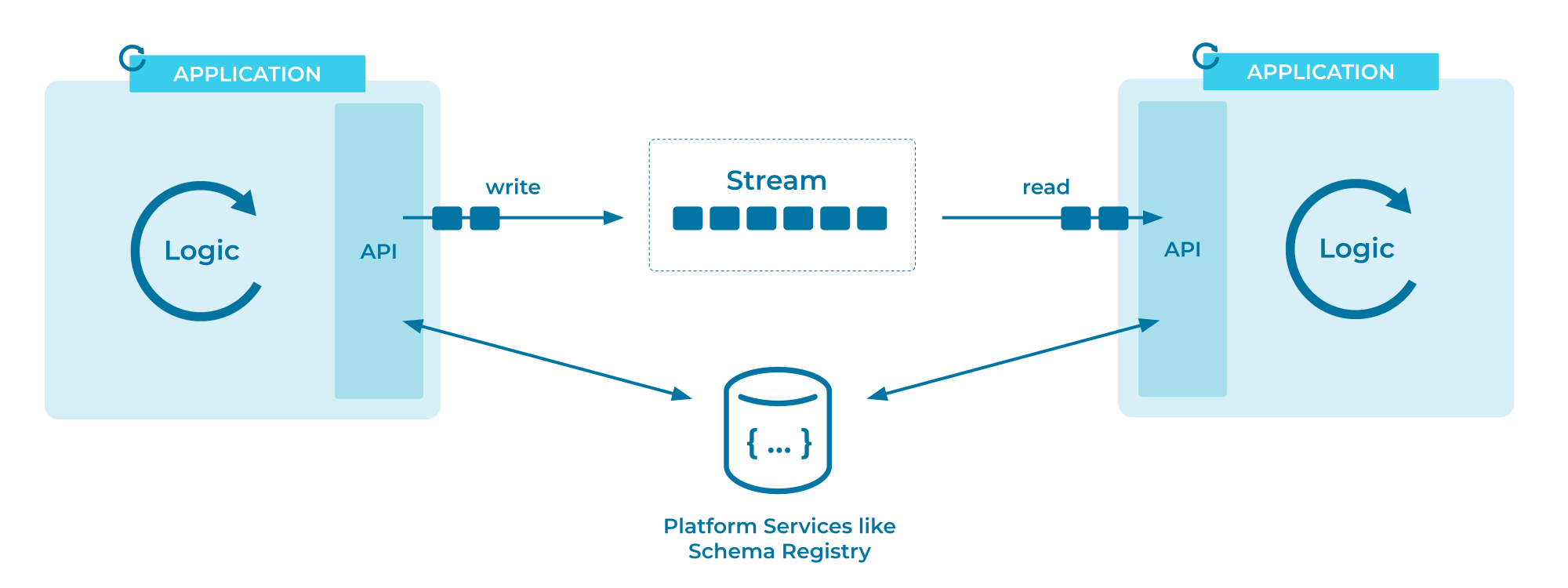
Existen dos modelos para que los consumidores recuperen datos de un intermediario: push y pull. Push se refiere a que el intermediario de eventos inicia el proceso de envío de datos a un consumidor inicialmente disponible, mientras que pull significa que el consumidor solicita al intermediario los registros disponibles posteriores. Esta distinción parece inofensiva, pero en la práctica se prefiere pull.
Una de las principales razones por las que el envío no se usa ampliamente es que el bróker no puede garantizar que el consumidor pueda actuar sobre el evento. Por lo tanto, podría terminar enviando el evento varias veces innecesariamente, aunque aún necesite almacenarlo en el tema. El bróker también debería considerar la agrupación de eventos para un mayor rendimiento, lo cual es lo opuesto a la idea de transmitirlos lo más rápido posible.
Permitir que el consumidor extraiga los datos cuando estén listos para procesarlos reduce el tráfico innecesario de red y permite una mayor confiabilidad. Esto garantiza que solo reciba datos cuando estén listos para procesarlos. El tiempo de procesamiento depende de la lógica de negocio y afecta la programación del número de trabajadores. En ambos casos, el intermediario debe recordar qué eventos ha reconocido el consumidor.
Ahora que sabe qué es la transmisión de eventos y en qué arquitectura se basa, aprenderá sobre los beneficios de este enfoque dinámico.
Beneficios de la transmisión de eventos
Los principales beneficios de la retransmisión de eventos son:
- Coherencia: el agente de eventos garantiza que los eventos se envíen correctamente a todos los consumidores interesados.
- Tolerancia a fallos: si un consumidor no acepta un evento, se lo puede redirigir a otro lugar para garantizar que ningún evento quede sin procesar.
- Reutilización: Los eventos almacenados en un hilo son inmutables. Pueden reproducirse en su totalidad o desde un punto específico, lo que permite reprocesarlos si la lógica de negocio cambia.
- Escalabilidad: los productores y los consumidores son entidades separadas y no tienen que esperarse unos a otros, lo que significa que pueden escalar dinámicamente hacia arriba o hacia abajo según la demanda.
- Facilidad de uso: el agente de eventos maneja el enrutamiento y el almacenamiento de eventos, abstrayendo la lógica compleja y permitiéndole concentrarse en los datos en sí.
Cada evento debe contener únicamente los detalles necesarios sobre la ocurrencia. Los gestores de eventos suelen ser muy eficientes y, aunque se recomienda que los eventos no caduquen una vez registrados en un tema, no deben tratarse como una base de datos tradicional.
Por ejemplo, sería útil mostrar que el número de visualizaciones de un artículo ha cambiado, pero no es necesario almacenar el artículo completo y sus metadatos junto con este dato. En su lugar, el evento podría contener una referencia al ID del artículo en una base de datos externa. De esta forma, se puede seguir rastreando el historial sin incluir información innecesaria ni contaminar el hilo.
Ahora aprenderá sobre Apache Kafka y otros agentes de eventos populares, cómo se comparan y cómo encajan en el ecosistema de transmisión de eventos.
El papel de Apache Kafka
Apache Kafka es un agente de eventos de código abierto escrito en Java y mantenido por la Apache Software Foundation. Consiste en servidores y clientes distribuidos que se comunican mediante un protocolo de red TCP personalizado para obtener el máximo rendimiento. Kafka es altamente confiable y escalable, y puede ejecutarse en máquinas virtuales, hardware físico, contenedores y otros entornos de nube.
Para garantizar la confiabilidad, Kafka se implementa como un clúster compuesto por uno o más servidores. Este clúster puede abarcar múltiples regiones de la nube y centros de datos. Los clústeres de Kafka son tolerantes a fallos, lo que significa que, en caso de fallo o desconexión del servidor, los remanentes se reagrupan para garantizar una alta disponibilidad de las operaciones sin impacto externo ni pérdida de datos.
Para lograr la máxima eficiencia, no todos los servidores de Kafka cumplen la misma función. Algunos servidores se agrupan y actúan como intermediarios, formando una capa de almacenamiento para almacenar datos. Otros pueden integrarse con sus sistemas existentes e ingerir datos como flujos de eventos mediante Kafka Connect, una herramienta para la transmisión fiable de datos desde sistemas existentes (como bases de datos relacionales) a Kafka.
Kafka considera a productores y consumidores como sus clientes. Como se explicó anteriormente, los productores escriben eventos en un bróker de Kafka, que los envía a los consumidores interesados. En la configuración predeterminada, Kafka garantiza que cada evento sea procesado una sola vez por uno de los consumidores.
En Kafka, los temas están particionados. Esto significa que un tema se distribuye en partes entre diferentes intermediarios de Kafka, lo que garantiza la escalabilidad. Kafka también garantiza que los eventos almacenados en una combinación específica de temas y sus particiones siempre se puedan leer en el mismo orden en que se escribieron.
Tenga en cuenta que la simple partición de un tema no garantiza la redundancia, que solo se puede lograr mediante la replicación entre regiones y centros de datos. Es común tener al menos tres copias de un clúster en un entorno de producción, lo que significa que siempre hay tres combinaciones de tema y partición disponibles.
Integración de Kafka
Como se mencionó, los datos de sistemas existentes se pueden importar y exportar con Kafka Connect. Es ideal para importar bases de datos completas, informes o métricas desde sus servidores en subprocesos de baja latencia. Kafka Connect proporciona conectores para diferentes sistemas de datos que permiten gestionar los datos de forma estándar. Otra ventaja de usar conectores en lugar de soluciones propias es que Connect es escalable por defecto (se pueden agrupar varios trabajadores) y monitoriza automáticamente el progreso.
Hay una gran cantidad de clientes disponibles para comunicarse con Kafka a través de sus aplicaciones. Se admiten numerosos lenguajes de programación, como Java, Scala, Python, .NET, C++, Go, etc. También está disponible una biblioteca cliente de alto nivel llamada Kafka Streams para Java y Scala. Esta biblioteca abstrae los componentes internos y permite conectarse fácilmente a un servidor Kafka y comenzar a recibir eventos de difusión.
Resultado
Este artículo aborda los paradigmas del enfoque moderno de flujo de eventos para el procesamiento de datos y eventos, así como sus ventajas sobre los procesos tradicionales de categorización de datos. También aprendió sobre Apache Kafka como agente de eventos y su ecosistema de clientes.









