









Introduction
Traditional methods of processing and receiving data (such as batch processing and polling) are inefficient in the context of microservices used in modern applications. These methods operate on massive chunks of data, which delays the final result of their processing and forces a significant amount of data to be accumulated before it can be processed. They introduce additional complexity required to synchronize workers and potentially leave some of them underutilized despite their resource utilization. In contrast, since cloud computing offers rapid scalability for on-premises resources, incoming data can be processed in real time by delegating it to multiple workers in parallel.
Event streaming is an approach to flexibly collect and delegate incoming events for processing while maintaining a continuous flow of data between different systems. Scheduling incoming data for immediate processing ensures maximum resource utilization and real-time responsiveness. Event streaming separates producers from consumers, allowing you to have a disproportionate number of each depending on the current load. This enables instant reactions to dynamic real-world conditions.
Such responsiveness can be especially important in areas such as financial trading, payment monitoring, or traffic monitoring. For example, Uber uses event streaming to connect hundreds of microservices, sending event data from rider-to-driver applications in real time and archiving it for later analysis.
With event broadcasting, instead of a worker traditionally waiting for a batch of data at a regular interval, the event broker can notify the consumer (typically a microservice) as soon as the event occurs and provide it with the event data. The event broker takes care of routing, receiving, and delivering events. It also provides fault tolerance in the event that a worker fails or refuses to process an event.
In this concept paper, we will explore the event streaming approach and its benefits. We will also introduce Apache Kafka, an open source event broker, and examine its role in this approach.
Event flow architecture
Event flow, at its core, is an implementation of the pub/sub architectural pattern. In general, the pub/sub pattern includes:
- The topics to which messages (including any data you want to communicate) are addressed.
- Publishers who produce messages
- Subscribers who receive and act on messages
- A message broker that accepts messages from publishers and delivers them to subscribers in the most efficient way.
A topic is similar to a category to which a message is associated. Topics persistently store the sequence of messages and ensure that new messages are always added to the end of the sequence. Once a message is added to a topic, it cannot be changed later.
With event broadcasting, the premise is similar, though more specialized:
- Events and related metadata are sent as messages.
- Events in a topic are usually sorted by arrival time.
- Subscribers (also called consumers) can broadcast events from any point in the thread up to the current moment.
- Unlike the actual pub/sub, events for a topic can be kept for a specific period of time or kept indefinitely (as an archive).
Event flow does not impose any constraints or make any assumptions about the nature of an event. As far as the underlying broker is concerned, it means that a producer has notified it that something has happened. What actually happened is up to you to define and give meaning to your implementation. For this reason, from the broker's perspective, events are called messages or records interchangeably.
To illustrate, here is a detailed diagram of the Kafka event stream architecture from the Confluent documentation:
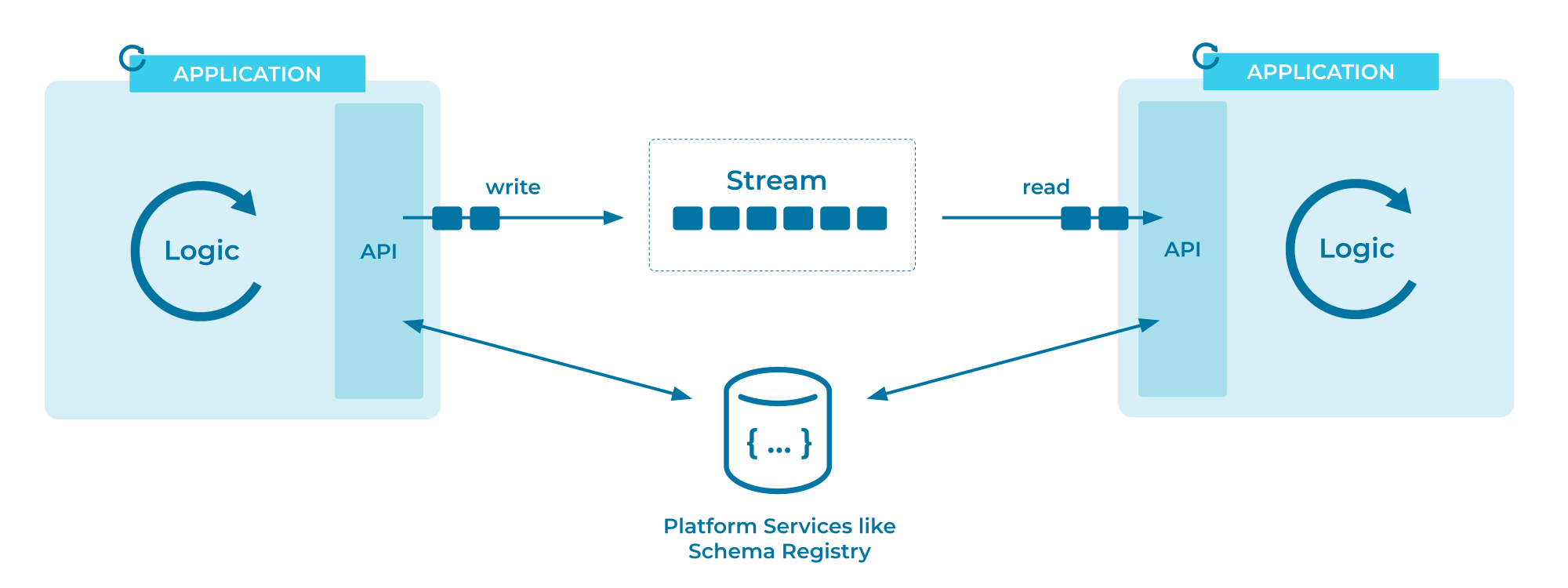
There are two models for how consumers can retrieve data from a broker: pushing and pulling. Pushing refers to the event broker initiating the process of sending data to an initially available consumer, while pulling means that the consumer requests subsequent available records from the broker. This distinction seems harmless, but pulling is preferred in practice.
One of the main reasons pushing is not widely used is that the broker cannot be sure that the consumer can actually act on the event. Therefore, it may end up sending the event multiple times unnecessarily while still needing to store it in the topic. The broker should also consider batching events for higher throughput, which is the opposite of the idea of broadcasting them as quickly as possible.
Having the consumer pull data when it is ready to process reduces unnecessary network traffic and allows for greater reliability. This ensures that it only receives data when it is ready to process. The processing time depends on the business logic and affects the scheduling of the number of workers. In both cases, the broker must remember which events the consumer has acknowledged.
Now that you know what event streaming is and what architecture it is based on, you will learn about the benefits of this dynamic approach.
Benefits of event streaming
The main benefits of event broadcasting are:
- Consistency: The event broker ensures that events are correctly sent to all interested consumers.
- Fault tolerance: If a consumer fails to accept an event, it can be redirected elsewhere to ensure that no event is left unprocessed.
- Reusability: Events stored in a thread are immutable. They can be replayed in their entirety or from a specific point in time, allowing you to reprocess events if your business logic changes.
- Scalability: Producers and consumers are separate entities and do not have to wait for each other, meaning they can be dynamically scaled up or down depending on demand.
- Ease of use: The event broker handles event routing and storage, abstracting away complex logic and allowing you to focus on the data itself.
Each event should contain only the necessary details about the occurrence. Event brokers are generally very efficient, and although it is recommended that events not expire once they are logged into a topic, they should not be treated as a traditional database.
For example, it would be nice to show that the number of views on an article has changed, but there is no need to store the entire article and its metadata along with this fact. Instead, the event could contain a reference to the article ID in an external database. This way, the history can still be tracked without including unnecessary information and polluting the thread.
Now you will learn about Apache Kafka and other popular event brokers, how they compare, and how they fit into the event streaming ecosystem.
The role of Apache Kafka
Apache Kafka is an open source event broker written in Java and maintained by the Apache Software Foundation. It consists of distributed servers and clients that communicate using a custom TCP network protocol for maximum performance. Kafka is highly reliable and scalable and can run on virtual machines, bare metal hardware, containers, and other cloud environments.
For reliability, Kafka is deployed as a cluster of one or more servers. This cluster can span multiple cloud regions and data centers. Kafka clusters are fault-tolerant, meaning that in the event of a server failure or disconnection, the remnants are regrouped to ensure high availability of operations without external impact and data loss.
For maximum efficiency, not all Kafka servers play the same role. Some servers are grouped together and act as intermediaries, forming a storage layer for holding data. Others can be integrated with your existing systems and ingest data as event streams using Kafka Connect, a tool for reliably streaming data from existing systems (such as relational databases) to Kafka.
Kafka considers producers and consumers as its clients. As explained earlier, producers write events to a Kafka broker, which sends them to interested consumers. In the default configuration, Kafka guarantees that an event is ultimately processed only once by one of the consumers.
In Kafka, topics are partitioned. This means that a topic is distributed in parts across different Kafka brokers, which ensures scalability. Kafka also guarantees that events stored in a specific combination of topics and their partitions can always be read in the same order in which they were written.
Note that simply partitioning a topic does not guarantee redundancy, which can only be achieved through replication across regions and data centers. It is common to have at least 3 copies of a cluster in a production environment, meaning that three topic-partition combinations are always available.
Kafka integration
As mentioned, data from existing systems can be imported and exported using Kafka Connect. It is suitable for importing entire databases, reports or metrics from your servers in low-latency threads. Kafka Connect provides connectors for different data systems that allow you to manage data in a standard way. Another advantage of using connectors instead of using your own solutions is that Connect is scalable by default (multiple workers can be grouped together) and automatically tracks progress.
There are a large number of clients available to communicate with Kafka through your applications. Many programming languages are supported, such as Java, Scala, Python, .NET, C++, Go, etc. A high-level client library called Kafka Streams is also available for Java and Scala. This library abstracts the internals and allows you to easily connect to a Kafka server and start receiving broadcast events.
Result
This article covers the paradigms of the modern event stream approach to data and event processing and its advantages over traditional data categorization processes. You also learned about Apache Kafka as an event broker and its client ecosystem.









