









Introduction
Imagine a database that not only stores data but also understands it. In recent years, AI applications have revolutionized almost every industry and changed the future of computing.
Vector databases change the way we manage unstructured data, allowing us to store knowledge in a way that captures relationships, similarities, and context. Unlike traditional databases, which rely primarily on structured data stored in tables and focus on exact matches, vector databases allow us to store unstructured data—such as images, text, and audio—in a format that machine learning models can understand and compare.
Rather than relying on exact matches, vector databases can find “closest” matches and facilitate efficient retrieval of alternate or semantically similar items. In today’s era, where artificial intelligence powers everything, vector databases have become essential for applications including large language models and machine learning models that generate and process embeddings.
So, what is embedding? We will cover it shortly in this article.
Whether for recommendation systems or to power conversational AI, vector databases have become a powerful data storage solution that enables us to access and interact with data in new and exciting ways.
Now let's take a look at what databases are most commonly used:
- SQL: Stores structured data and uses tables to store data with a defined schema. The most common ones are MySQL, Oracle Database, and PostgreSQL.
- NoSQL: It is very flexible and a schema-less database. It is also known for handling unstructured or semi-structured data. It has been great for many real-time web applications and big data. The most common ones are MongoDB and Cassandra.
- Graph: Then came Graph which stores data as nodes and edges and is designed to manage interconnected data. Example: Neo4j, ArangoDB.
- Vector: Databases built to store and query high-dimensional vectors, enabling similarity searching and augmentation for AI/ML tasks. The most common are Pinecone, Weaviate, and Chroma.
Prerequisites
- Knowledge of similarity measures: Understanding measures such as cosine similarity, Euclidean distance, or dot product for comparing vector data.
- Basic ML and AI concepts: Knowledge of machine learning models and applications, especially those that generate embeddings (e.g. NLP, computer vision).
- Familiarity with database concepts: General knowledge of databases including the principles of indexing, querying, and data storage.
- Programming skills: Proficiency in Python or similar languages commonly used in ML libraries and vector databases.
Why do we use vector databases and how are they different?
Suppose we store data in a traditional SQL database, where each data point is converted into an embedding and stored. When a query is built, it is also converted into an embedding, and then we try to find the most relevant ones by comparing this query embedding to the stored embeddings using cosine similarity.
However, this method can become ineffective for several reasons:
- High dimensionality: Embeddings are usually high dimensional. This can lead to slow query times, as each comparison may require a full scan search across all stored embeddings.
- Scalability issues: The computational cost of computing cosine similarity between millions of embeddings becomes prohibitive with large datasets. Traditional SQL databases are not optimized for this task, making it challenging to achieve real-time retrieval.
Therefore, a traditional database may struggle with efficient, large-scale searches. Furthermore, a significant amount of data generated daily is unstructured and cannot be stored in traditional databases.

Well, to deal with this problem, we use a vector database. In a vector database, there is the concept of Index which enables efficient similarity search for high dimensional data. By organizing vector embeddings, it plays a significant role in speeding up queries and allows the database to quickly retrieve vectors similar to a query vector even in large datasets. Vector indexes reduce the search space and enable scaling to millions or billions of vectors. This enables fast query response even in large datasets.
In traditional databases, we search for rows that match our query. We use similarity measures in vector databases to find the vector that is most similar to our query.
Vector databases use a combination of algorithms for approximate nearest neighbor (ANN) search that optimize the search through hashing, quantization, or graph-based methods. These algorithms work together in a pipeline to provide fast and accurate results. Since vector databases provide approximate matching, there is a trade-off between accuracy and speed – higher accuracy may slow down the query.
Fundamentals of vector representations
What are vectors?
Vectors can be thought of as arrays of numbers stored in a database. Any type of data, such as images, text, PDF files, and audio, can be converted to numerical values and stored in a vector database as an array. This numerical representation of data allows for something called similarity searching.
Before understanding vectors, let's try to understand semantic search and embeddings.
What is semantic search?
Semantic search is a way to look for the meaning of words and context rather than matching exact phrases. Instead of focusing on the keyword, semantic search tries to understand the meaning. For example, the word “python.” In a traditional search, the word “python” might return results for both Python programming and Python snakes, because it only recognizes the word itself. With semantic search, the engine looks for context. If recent searches were about «coding languages» or «machine learning,» it would likely show results about Python programming. But if searches were about «weird animals» or «reptiles,» it would assume pythons were snakes and adjust the results accordingly.

By identifying context, semantic search helps to surface the most relevant information based on the actual intent.
What are embeddings?
Embeddings are a way to represent words as numeric vectors (for now, let's think of vectors as lists of numbers; for example, the word "cat" might become [.1,.8,.75,.85]. In a high-dimensional space, computers quickly process this numeric representation of a word.
Words have different meanings and relationships. For example, in word embeddings, the words “king” and “queen” have similar vectors as “king” and “car.”.
Embeddings can capture the context of a word based on its use in sentences. For example, “bank” could mean a financial institution or a riverbank, and embeddings help to recognize these meanings based on surrounding words. Embeddings are a smarter way for computers to understand words, meanings, and relationships.
One way to think about an embedding is to map the different features or characteristics of that word and then assign values to each of these features. This gives a sequence of numbers and is called a vector. There are various techniques that can be used to create these word embeddings. Hence, a vector embedding is a way to represent a sentence or document of words in numbers that can depict meaning and relationships. Vector embeddings allow these words to be represented as points in space where similar words are close to each other.
These vector embeddings allow for mathematical operations such as addition and subtraction, which can be used to capture relationships. For example, the well-known vector operation “king – man + woman” can yield a vector close to “queen.”.
Similarity criteria in vector spaces
Now, to measure the similarity of each vector, mathematical tools are used to quantify the similarity or dissimilarity. Some of them are listed below:
- Cosine Similarity: Cosine measures the angle between two vectors, ranging from -1 to 1. Where -1 means exactly opposite, 1 means identical vectors, 0 means orthogonal or dissimilar.
- Euclidean distance: Measures the straight line distance between two points in vector space. Smaller values indicate greater similarity.
- Manhattan Distance (L1 Norm): Measures the distance between two points by summing the absolute difference of their corresponding components.
- Minkowski distance: A generalization of Euclidean and Manhattan distances.
These are the most common distance or similarity metrics used in machine learning algorithms.
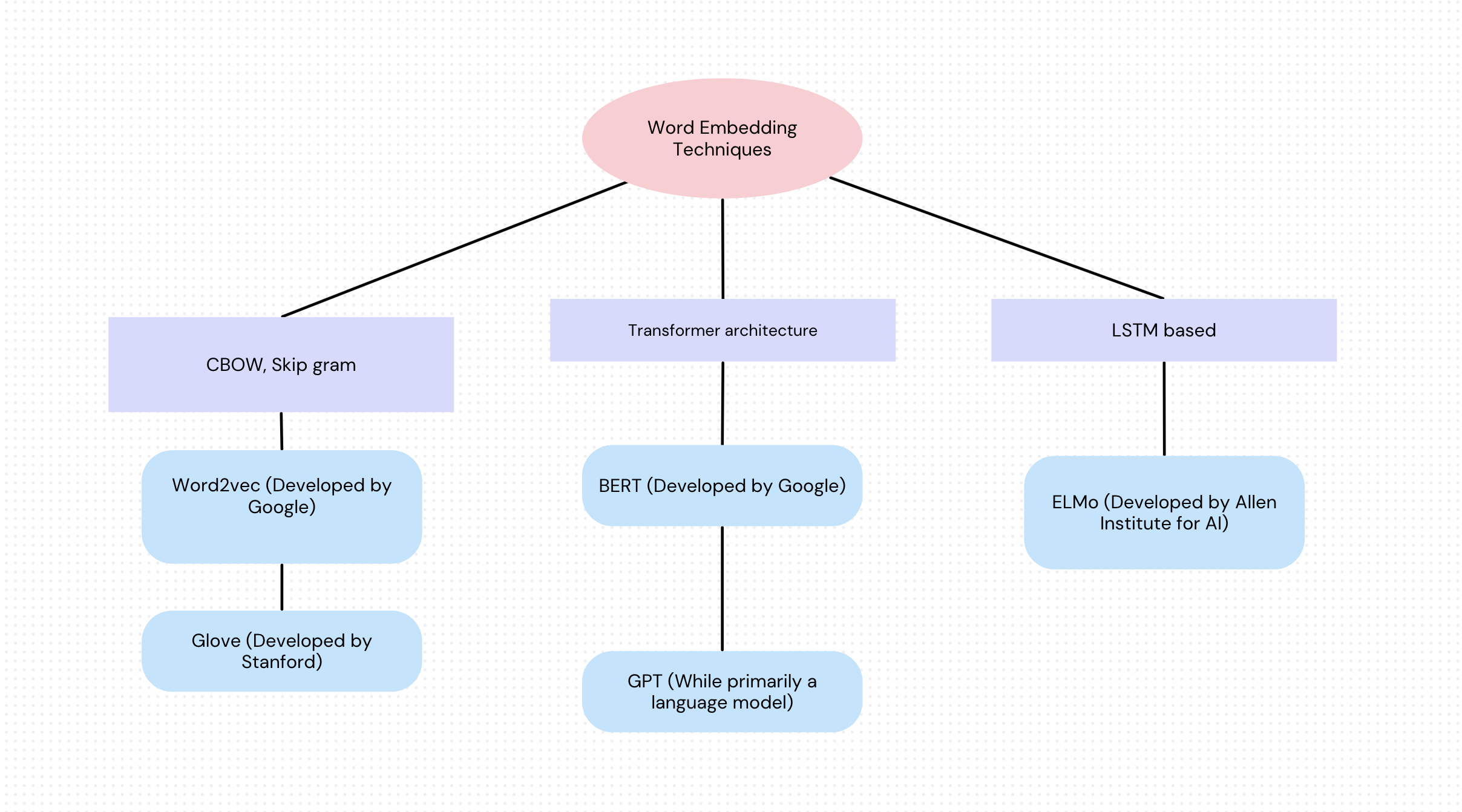
Popular vector databases
Here are some of the most popular vector databases that are widely used today:
- Pinecone: A fully managed vector database known for its ease of use, scalability, and fast approximate nearest neighbor (ANN) search. Pinecone is known for its integration with machine learning workflows, especially semantic search and recommendation systems.
- FAISS (Facebook AI Similarity Search): Developed by Meta (formerly Facebook), FAISS is a highly optimized library for similarity search and clustering of dense vectors. It is open source, efficient, and commonly used in academic and industrial research, especially for large-scale similarity searches.
- Weaviate: An open source, cloud-native vector database that supports vector and hybrid search capabilities. Weaviate is known for its integration with models from Hugging Face, OpenAI, and Cohere, making it a strong option for semantic search and NLP applications.
- Milvus: An open-source, highly scalable vector database optimized for large-scale AI applications. Milvus supports various indexing methods and has a broad ecosystem of integrations, making it popular for real-time recommendation systems and computer vision tasks.
- Qdrant: A high-performance vector database that focuses on user-friendliness, Qdrant offers features like real-time indexing and distributed support. It is designed to handle high-dimensional data, making it suitable for recommendation engines, personalization, and NLP tasks.
- Chroma: Open source and designed explicitly for LLM applications, Chroma provides an embedding store for LLMs and supports similar searches. It is often used with LangChain for conversational AI and other LLM-based applications.
Things you should use
Now, let's review some of the use cases of vector databases.
- Vector databases can be used for conversational agents that require long-term memory storage. This can be easily implemented with Langchain and enables the conversational agent to query and store conversation history in a vector database. As users interact, the bot pulls contextually relevant snippets from past conversations, enhancing the user experience.
- Vector databases can be used for semantic search and information retrieval by retrieving semantically similar documents or texts. They find content that is textually related to the query, rather than exact keyword matching.
- Platforms such as e-commerce, music streaming, or social media use vector databases to generate recommendations. By representing the user's items and preferences as vectors, the system can find products, songs, or content similar to the user's past interests.
- Image and video platforms use vector databases to find visually similar content.
Challenges for vector databases
- Scalability and performance: As data volumes continue to grow, keeping vector databases fast and scalable while maintaining accuracy can become a challenge. Balancing speed and accuracy can also be a potential challenge when generating accurate search results.
- Cost and resource intensity: High-dimensional vector operations can be resource intensive, requiring powerful hardware and efficient indexing, which can increase storage and computational costs.
- Precision vs. Approximation Tradeoff: Vector databases use nearest neighbor (ANN) techniques to achieve faster searches, but may result in approximate rather than exact matches.
- Integration with traditional systems: Integrating vector databases with existing traditional databases can be challenging, as they use different data structures and retrieval methods.
Result
Vector databases change the way we store and search for complex data such as images, audio, text, and recommendations by allowing similarity-based searches in high-dimensional spaces. Unlike traditional databases that require exact matches, vector databases use embeddings and similarity scores to find «close enough» results, making them great for applications such as personalized recommendations, semantic search, and anomaly detection.









