









Einführung
DeepSeek R1 hat die KI/ML-Community in den letzten Wochen aus gutem Grund im Sturm erobert und sich sogar darüber hinaus in der breiten Öffentlichkeit verbreitet, mit weitreichenden Folgen für Wirtschaft und Politik. Dies ist vor allem dem Open-Source-Charakter der Modellsuite und den unglaublich niedrigen Trainingskosten zu verdanken. Dadurch hat sich für die breitere Fachwelt gezeigt, dass das Training von hochmodernen KI-Modellen bei Weitem nicht so viel Kapital oder dedizierte Forschung erfordert wie bisher angenommen.
Im ersten Teil dieser Reihe haben wir DeepSeek R1 vorgestellt und gezeigt, wie man das Modell mit Olama ausführt. In diesem Folgebeitrag gehen wir zunächst genauer darauf ein, was R1 so besonders macht. Wir analysieren das einzigartige Reinforcement-Learning-Paradigma (RL) des Modells, um zu sehen, wie die Denkfähigkeit von LLMs allein durch RL gefördert werden kann. Anschließend erläutern wir, wie die Übertragung dieser Techniken auf andere Modelle es uns ermöglicht, diese Fähigkeiten mit bestehenden Versionen zu teilen. Abschließend demonstrieren wir kurz, wie man DeepSeek-R1-Modelle mit GPU Droplets und deren 1-Click-Modell einrichtet und ausführt.
Voraussetzungen
- Deep Learning: Dieser Artikel behandelt Themen für Fortgeschrittene und Experten im Bereich des Trainings neuronaler Netze und des bestärkenden Lernens.
- DigitalOcean-Konto: Für die Tests von R1 werden wir speziell die HuggingFace 1-Click Model GPU Droplets von DigitalOcean verwenden.
DeepSeek R1 – Übersicht
Das Forschungsprojekt DeepSeek R1 hatte zum Ziel, die effektiven Schlussfolgerungsfähigkeiten leistungsstarker Modelle, insbesondere des OpenAI-Modells O1, nachzubilden. Um dieses Ziel zu erreichen, verbesserte das Team seine bestehende Arbeit DeepSeek-v3-Base mithilfe von reinem Reinforcement Learning. Daraus entstand DeepSeek R1 Zero, das zwar hervorragende Ergebnisse bei den Schlussfolgerungsmetriken erzielt, jedoch keine menschliche Interpretationsfähigkeit besitzt und ungewöhnliche Verhaltensweisen wie Sprachvermischung aufweist.
Um diese Probleme zu beheben, schlugen sie DeepSeek R1 vor, das mit einer geringen Menge an Kaltstartdaten und einer mehrstufigen Trainingspipeline arbeitet. R1 erreichte die Lesbarkeit und Anwendbarkeit des aktuellen Stands der Technik im Bereich des linearen Lernmanagements (LLM), indem das DeepSeek-v3-Base-Modell anhand Tausender Kaltstartdaten feinabgestimmt wurde. Anschließend wurde eine weitere Runde Reinforcement Learning durchgeführt, gefolgt von überwachtem Feinabstimmen auf dem Argumentdatensatz und schließlich einer letzten Runde Reinforcement Learning. Diese Technik wurde dann auf andere Modelle übertragen, indem deren Feinabstimmung anhand der von R1 gesammelten Daten überwacht wurde.
Bleiben Sie dran für einen detaillierteren Einblick in diese Entwicklungsphasen und eine Diskussion darüber, wie das Modell iterativ verbessert werden kann, um die Fähigkeiten von DeepSeek R1 zu erreichen.
DeepSeek R1 Zero Tutorial
Um DeepSeek R1 Zero, das Basismodell, aus dem R1 entwickelt wurde, zu erstellen, wandten die Forscher Reinforcement Learning (RL) direkt auf das Basismodell an, ohne SFT-Daten zu verwenden. Das von ihnen gewählte RL-Paradigma heißt Group Relative Policy Optimization (GRPO). Dieses Verfahren ist dem DeepSeekMath-Paper entnommen.
GRPO ähnelt bekannten RL-Systemen, unterscheidet sich aber in einem wichtigen Punkt: Es verwendet kein kritisches Modell. Stattdessen schätzt GRPO die Baseline anhand der Gruppenwerte. Das Belohnungsmodell dieses Systems umfasst zwei Regeln, die jeweils die Genauigkeit und die Übereinstimmung der Vorlage mit einem Muster belohnen. Die Belohnung dient dann als Quelle für Trainingssignale, die anschließend zur Anpassung der RL-Optimierungsrichtung verwendet werden. Dieses regelbasierte System ermöglicht es dem RL-Prozess, das Modell iterativ zu verfeinern und zu verbessern.

Die Trainingsvorlage selbst ist ein einfaches schriftliches Format, das das Basismodell anleitet, den oben genannten Anweisungen zu folgen. Das Modell misst die Reaktionen auf die für jeden Schritt des Reinforcement Learnings (RL) festgelegten «Ankündigungen». “Dies ist ein bedeutender Erfolg, da er die Fähigkeit des Modells unterstreicht, allein durch RL effektiv zu lernen und zu generalisieren” (Quelle).
Diese Selbstentwicklung des Modells führt zur Ausbildung ausgeprägter Denkfähigkeiten, darunter Selbstreflexion und die Berücksichtigung alternativer Lösungsansätze. Verstärkt wird dies durch einen Moment während des Trainings, den das Forschungsteam des Modells als “Aha-Moment” bezeichnet. In dieser Phase lernt DeepSeek-R1-Zero, einem Problem mehr Denkzeit zu widmen, indem es seinen ursprünglichen Ansatz neu bewertet. Dieses Verhalten zeugt nicht nur von den wachsenden Denkfähigkeiten des Modells, sondern ist auch ein faszinierendes Beispiel dafür, wie bestärkendes Lernen zu unerwarteten und komplexen Ergebnissen führen kann. (Quelle).
DeepSeek R1 Zero schnitt in den Benchmarks sehr gut ab, wies aber im Vergleich zu geeigneten, benutzerfreundlichen LLMs deutliche Schwächen hinsichtlich Lesbarkeit und Benutzerfreundlichkeit auf. Daher schlug das Forschungsteam DeepSeek R1 vor, um das Modell für Aufgaben auf menschlichem Niveau zu verbessern.
Von DeepSeek R1 Zero zu DeepSeek R1
Um vom relativ ungezähmten DeepSeek R1 Zero zum wesentlich funktionaleren DeepSeek R1 zu gelangen, führten die Forscher mehrere Trainingsstufen ein.
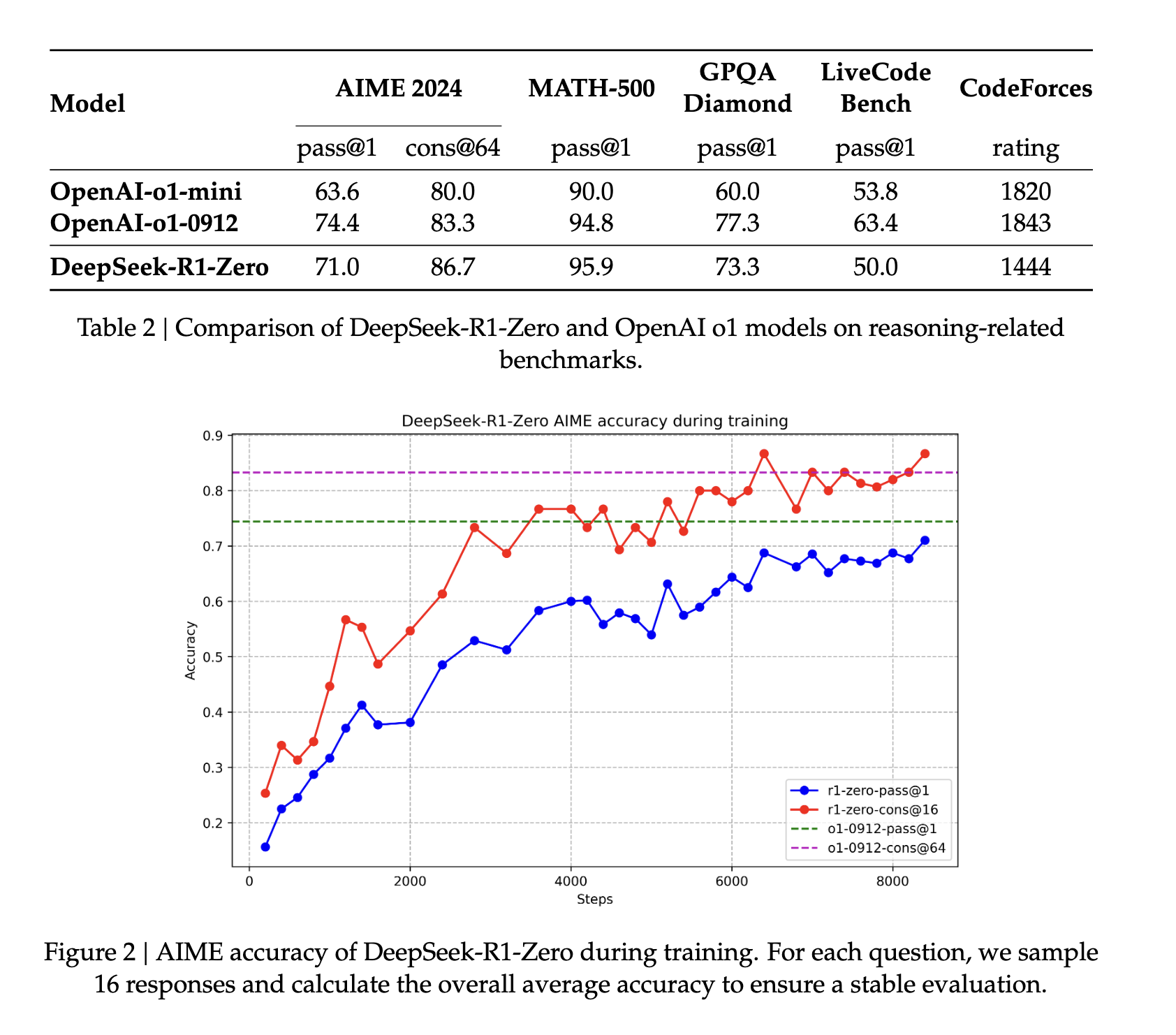
Zunächst wurde DeepSeek-v3-Base anhand Tausender Kaltstartdatensätze feinabgestimmt, bevor dasselbe RL-Paradigma wie für DeepSeek R1 Zero angewendet wurde. Dies bietet den zusätzlichen Vorteil einer konsistenten Sprache in den Ausgaben. In der Praxis verbessert dieser Schritt die Argumentationsfähigkeit des Modells, insbesondere bei Aufgaben wie Programmierung, Mathematik, Naturwissenschaften und logischem Denken, die klar definierte Probleme mit eindeutigen Lösungen beinhalten (Quelle).
Sobald diese RL-Phase abgeschlossen ist, wird das resultierende Modell verwendet, um neue Daten für das überwachte Feinabstimmen zu sammeln. «Im Gegensatz zu den anfänglichen Kaltstartdaten, die sich hauptsächlich auf das logische Denken konzentrieren, kombiniert diese Phase Daten aus anderen Bereichen, um die Fähigkeiten des Modells beim Schreiben, Rollenspielen und anderen allgemeinen Aufgaben zu verbessern» (Quelle).
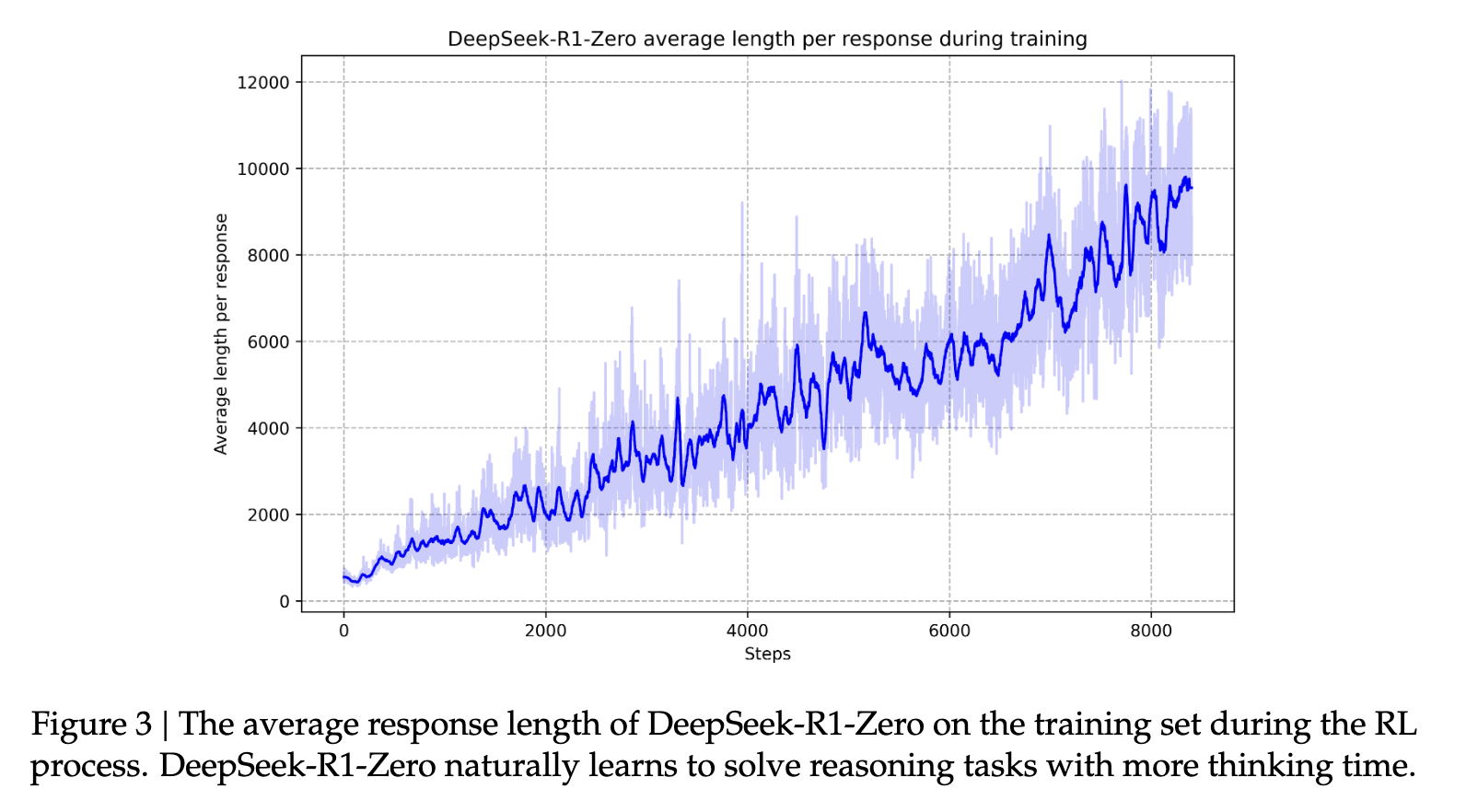
Im nächsten Schritt wird die zweite Phase des Reinforcement Learnings (RL) implementiert, um “die Nützlichkeit und Unschädlichkeit des Modells zu verbessern und gleichzeitig seine Denkfähigkeit zu verfeinern” (Quelle). Durch weiteres Training des Modells mit verschiedenen schnellen Verteilungen und Belohnungssignalen kann ein Modell entwickelt werden, das sich durch hervorragende Denkfähigkeit auszeichnet und dabei Nützlichkeit und Unschädlichkeit priorisiert. Dies trägt dazu bei, dass die Modelle in ihrer Reaktionsfähigkeit “menschenähnlich” werden. Dadurch entwickelt das Modell die bemerkenswerten Denkfähigkeiten, für die es bekannt ist. Im Laufe der Zeit hilft dieser Prozess dem Modell, lange Gedankenketten und Schlussfolgerungen zu entwickeln, die es charakterisieren.
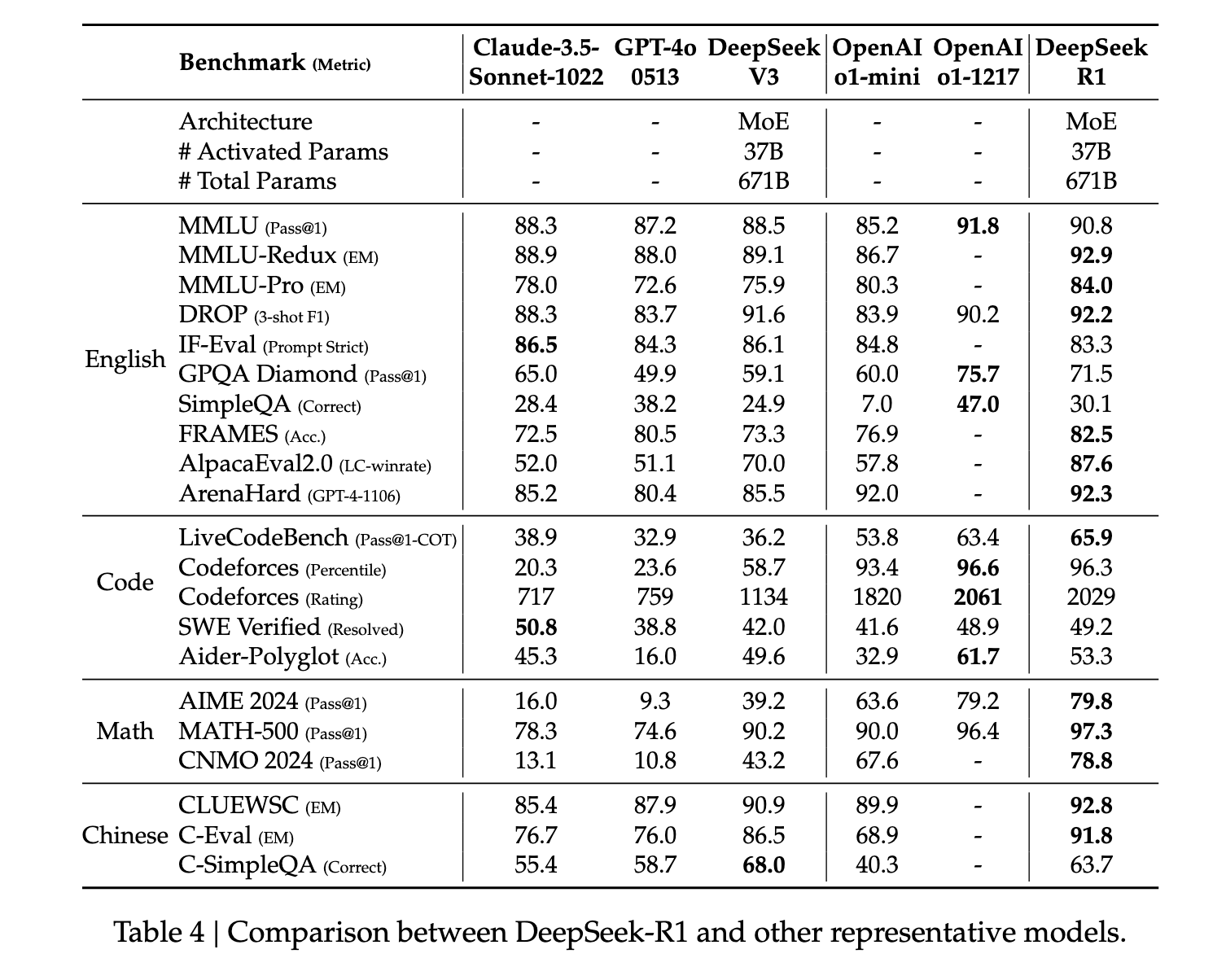
R1 erzielt durchweg Bestleistungen bei der Messung des logischen Denkens. In einigen Aufgaben, wie beispielsweise Mathematik, übertrifft es sogar veröffentlichte Benchmarks für O1. Insgesamt zeigt es auch bei MINT-bezogenen Fragen eine sehr starke Leistung, die primär auf groß angelegtes Reinforcement Learning zurückzuführen ist. Neben MINT-Fächern ist das Modell auch bei der Beantwortung von Fragen, der Bearbeitung von Lernaufgaben und komplexen Denkprozessen äußerst kompetent. Die Autoren argumentieren, dass diese Verbesserungen und erweiterten Fähigkeiten auf die Weiterentwicklung von Modellen zur Verarbeitung von Gedankenketten durch Reinforcement Learning zurückzuführen sind. Lange Datenketten werden während des Reinforcement Learnings und der Feinabstimmung verwendet, um das Modell zu längeren und introspektiveren Ausgaben anzuregen.
DeepSeek R1 Destillierte Modelle
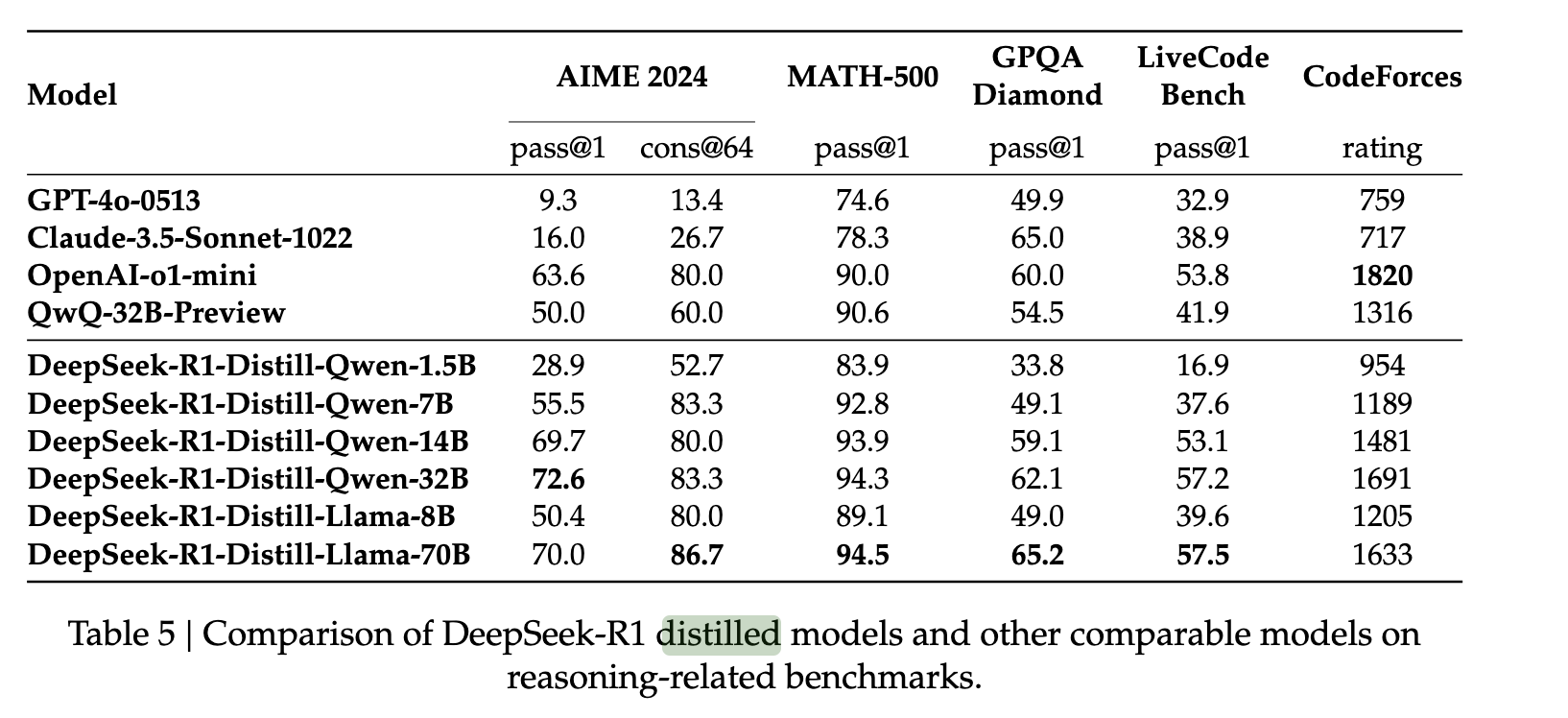 Um die Fähigkeiten von DeepSeek R1 auf kleinere Modelle auszuweiten, sammelten die Autoren 800.000 DeepSeek-R1-Beispiele und nutzten diese zur Feinabstimmung von Modellen wie QWEN und LLAMA. Sie stellten fest, dass diese relativ einfache Destillationsmethode die Übertragung der Schlussfolgerungsfähigkeiten von R1 auf diese neuen Modelle mit hohem Erfolg ermöglichte. Dies gelang ihnen ohne zusätzliches Reinforcement Learning (RL), wodurch die Robustheit der ursprünglichen Modellantworten gegenüber der Modelldestillation demonstriert wurde.
Um die Fähigkeiten von DeepSeek R1 auf kleinere Modelle auszuweiten, sammelten die Autoren 800.000 DeepSeek-R1-Beispiele und nutzten diese zur Feinabstimmung von Modellen wie QWEN und LLAMA. Sie stellten fest, dass diese relativ einfache Destillationsmethode die Übertragung der Schlussfolgerungsfähigkeiten von R1 auf diese neuen Modelle mit hohem Erfolg ermöglichte. Dies gelang ihnen ohne zusätzliches Reinforcement Learning (RL), wodurch die Robustheit der ursprünglichen Modellantworten gegenüber der Modelldestillation demonstriert wurde.
DeepSeek R1 wird auf GPU-Droplets gestartet
Die Einrichtung von DeepSeek R1 auf GPU-Droplets ist sehr einfach, wenn Sie bereits ein DigitalOcean-Konto besitzen. Melden Sie sich unbedingt an, bevor Sie fortfahren.
Wir bieten Zugriff auf R1 als 1-Klick-Modell-GPU-Droplet. Um es zu starten, öffnen Sie einfach die GPU-Droplet-Konsole, gehen Sie im Modellauswahlfenster auf die Registerkarte «1-Klick-Modelle» und starten Sie das Gerät!
Anschließend kann das Modell über die Methoden von HuggingFace oder OpenAI angesprochen werden. Verwenden Sie das untenstehende Skript, um mit Ihrem Modell mithilfe von Python-Code zu interagieren.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)Alternativ haben wir einen benutzerdefinierten persönlichen Assistenten entwickelt, der auf demselben System läuft. Wir empfehlen die Verwendung dieses Assistenten für diese Aufgaben, da er die direkte Interaktion mit dem Modell erheblich vereinfacht, indem er alles in einer übersichtlichen GUI-Oberfläche darstellt. Weitere Informationen zur Verwendung des Skripts für den persönlichen Assistenten finden Sie in diesem Tutorial.
Ergebnis
Zusammenfassend lässt sich sagen, dass R1 einen Fortschritt für die LLM-Entwicklungsgemeinschaft darstellt. Ihr Verfahren verspricht Einsparungen in Millionenhöhe bei den Trainingskosten und liefert gleichzeitig eine Leistung, die mit fortschrittlichen proprietären Modellen vergleichbar oder sogar besser ist. Wir werden DeepSeek aufmerksam beobachten, um zu sehen, wie das Unternehmen weiter wächst, während sein Modell internationale Anerkennung erlangt.









