









Einführung
Dieses Tutorial erklärt die Installation von Ollama zur Ausführung von Sprachmodellen auf einem Server unter Ubuntu oder Debian. Außerdem wird die Einrichtung einer Chat-Oberfläche mit Open WebUI und die Verwendung eines benutzerdefinierten Sprachmodells erläutert.
Voraussetzungen
- Ein Server mit Ubuntu/Debian
- Sie benötigen Root-Benutzerzugriff oder einen Benutzer mit sudo-Berechtigungen.
- Bevor Sie beginnen, müssen Sie einige grundlegende Einstellungen vornehmen, einschließlich der Firewall.
Schritt 1 – Ollama installieren
Die folgenden Schritte erklären die manuelle Installation von Ollama. Für einen schnellen Einstieg können Sie das Installationsskript verwenden und mit “Schritt 2 – Installation der Ollama-Weboberfläche” fortfahren.
Um Ollama selbst zu installieren, befolgen Sie diese Schritte:
Wenn Ihr Server über eine Nvidia-GPU verfügt, stellen Sie sicher, dass die CUDA-Treiber installiert sind.
nvidia-smi
Falls Sie die CUDA-Treiber noch nicht installiert haben, holen Sie dies jetzt nach. In dieser Konfiguration können Sie Ihr Betriebssystem auswählen und den Installationstyp festlegen, um die Befehle anzuzeigen, die Sie mit Ihren Einstellungen ausführen müssen.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
Laden Sie die Ollama-Binärdatei herunter und erstellen Sie einen Ollama-Benutzer.
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaErstellen Sie eine Servicedatei. Standardmäßig können Sie die Ollama-API über Port 11434 127.0.0.1 aufrufen. Das bedeutet, dass die API nur für localhost verfügbar ist.
Falls Sie externen Zugriff auf Ollama benötigen, können Sie dies tun. Umfeld Entfernen Sie die IP-Adresse und legen Sie eine neue fest, um auf die Ollama-API zuzugreifen. 0.0.0.0 Ermöglicht den Zugriff auf die API über die öffentliche IP-Adresse des Servers. Wenn Sie verwenden Umfeld Wenn Sie verwenden, stellen Sie sicher, dass Ihre Server-Firewall den Zugriff auf den hier konfigurierten Port zulässt. 11434 Wenn Sie nur einen Server haben, brauchen Sie den unten stehenden Befehl nicht zu ändern.
Kopieren Sie den gesamten Inhalt des folgenden Codeblocks und fügen Sie ihn ein. Diese neue Datei /etc/systemd/system/ollama.service Erstellt und verknüpft Inhalte EOF Wird der neuen Datei hinzugefügt.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
Laden Sie den systemd-Daemon neu und aktivieren Sie den Ollama-Dienst.
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaVerwenden Sie `systemctl status olama`, um den Status zu überprüfen. Falls Olama nicht ausgeführt wird, führen Sie `systemctl start olama` aus.
Im Terminal können Sie nun Sprachmodelle starten und Fragen stellen. Zum Beispiel:
ollama run llama2
Im nächsten Schritt wird erklärt, wie Sie eine Weboberfläche installieren, damit Sie Ihre Fragen über eine ansprechende Benutzeroberfläche in einem Webbrowser stellen können.
Schritt 2 – Open WebUI installieren
In der Olama-Dokumentation auf GitHub finden Sie eine Liste verschiedener Web- und Terminalintegrationen. Dieses Beispiel erklärt die Installation von Open WebUI.
Sie können Open WebUI auf demselben Server wie Ollama installieren oder Ollama und Open WebUI auf zwei separaten Servern. Wenn Sie Open WebUI auf einem separaten Server installieren, stellen Sie sicher, dass die Ollama-API in Ihrem Netzwerk verfügbar ist. Zur Sicherheit sollten Sie Folgendes überprüfen: /etc/systemd/system/olama.service Zeigen Sie den Server an, auf dem Ollama installiert ist, und den Wert OLLAMA_HOST Bestätigen.
Die folgenden Schritte erklären die Installation der Schnittstelle:
- Manuell
- Mit Docker
Open WebUI manuell installieren
Installieren Sie npm und pip, klonen Sie das WebUI-Repository und erstellen Sie eine Kopie der Beispielumgebungsdatei:
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .envIn Umfeld. Die Adresse für die Verbindung zur Ollama-API ist auf den Standardwert eingestellt. localhost:11434 ist festgelegt. Wenn Sie die Ollama API auf demselben Server wie Ihre Open WebUI installiert haben, können Sie diese Einstellungen unverändert lassen. Wenn Sie die Open WebUI auf einem separaten Server als die Ollama API installiert haben, Umfeld. Bearbeiten Sie den Standardwert und ersetzen Sie ihn durch die Serveradresse, auf der Olama installiert ist.
Aufgeführte Abhängigkeiten in package.json Installieren und führen Sie das Skript mit dem Namen aus bauen Laufen:
npm i && npm run build
Installieren Sie die benötigten Python-Pakete:
cd backend
sudo pip install -r requirements.txt -UWeb-Oberfläche mit olama-webui/backend/start.sh Start.
sh start.shIn start.shDer Port ist auf 8080 eingestellt. Das bedeutet, dass Sie auf Open WebUI zugreifen können in http:// :8080 Zugriff. Wenn auf Ihrem Server eine Firewall aktiv ist, müssen Sie den Port freigeben, bevor Sie auf die Chat-Oberfläche zugreifen können. Fahren Sie dazu mit «Schritt 3 – Ports für die Web-Oberfläche freigeben» fort. Falls Sie keine Firewall verwenden (was nicht empfohlen wird), fahren Sie mit «Schritt 4 – Modelle hinzufügen» fort.
Open WebUI mit Docker installieren
Für diesen Schritt müssen Sie Docker installieren. Falls Sie Docker noch nicht installiert haben, können Sie dies jetzt mithilfe dieser Anleitung tun.
Wie bereits erwähnt, können Sie Open WebUI entweder auf demselben Server wie Ollama installieren oder Ollama und Open WebUI auf zwei separaten Servern installieren.
Installieren Sie Open WebUI auf demselben Ollama-Server.
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Installieren Sie Open WebUI auf einem anderen Server als Ollama.
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Im obigen Docker-Befehl ist der Port auf 3000 eingestellt. Das bedeutet, dass Sie auf Open WebUI zugreifen können unter http:// :3000 Zugriff. Falls auf Ihrem Server eine Firewall aktiv ist, müssen Sie den Port freigeben, bevor Sie auf die Chat-Oberfläche zugreifen können. Dies wird im nächsten Schritt erläutert.
Schritt 3 – Port zur Web-Benutzeroberfläche zulassen
Wenn Sie eine Firewall verwenden, stellen Sie sicher, dass diese den Zugriff auf den Open WebUI-Port zulässt. Falls Sie die Anwendung manuell installiert haben, müssen Sie den Port manuell öffnen. 8080 TCP Wenn Sie es mit Docker installiert haben, müssen Sie den Port freigeben. 3000 TCP Lass mich.
Um dies erneut zu überprüfen, können Sie Folgendes verwenden: netstat Probieren Sie es aus und sehen Sie, welche Ports belegt sind.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTENEs gibt verschiedene Firewall-Tools. Dieses Tutorial konfiguriert das Standard-Firewall-Tool für Ubuntu. ufw Wenn Sie eine andere Firewall verwenden, stellen Sie sicher, dass diese eingehenden Datenverkehr zu den TCP-Ports 8080 oder 3000 zulässt.
Firewall-Regeln verwalten ufw:
- Aktuelle Firewall-Einstellungen anzeigen
Um zu überprüfen, ob die Firewall ufw Wenn Sie aktiv sind und bereits Regeln haben, können Sie die folgenden verwenden:
sudo ufw status
- TCP-Port 8080 oder 3000 zulassen
Wenn die Firewall aktiviert ist, führen Sie diesen Befehl aus, um eingehenden Datenverkehr an den TCP-Port 8080 oder 3000 zuzulassen:
sudo ufw allow proto tcp to any port 8080
- Neue Firewall-Einstellungen anzeigen
Neue Regeln sollten nun hinzugefügt werden. Zur Überprüfung gehen Sie zu:
sudo ufw status
Schritt 4 – Modelle hinzufügen
Nachdem Sie die Weboberfläche aufgerufen haben, müssen Sie Ihr erstes Konto erstellen. Dieser Benutzer verfügt über Administratorrechte. Um Ihren ersten Chat zu starten, wählen Sie ein Modell aus. Sie können eine Liste der Modelle auf der offiziellen Llama-Website durchsuchen. In diesem Beispiel fügen wir “llama2” hinzu.
Wählen Sie in der oberen rechten Ecke das Symbol für die Einstellungen aus.
Gehen Sie zu “Modelle”, geben Sie ein Modell ein und wählen Sie die Schaltfläche „Herunterladen“.
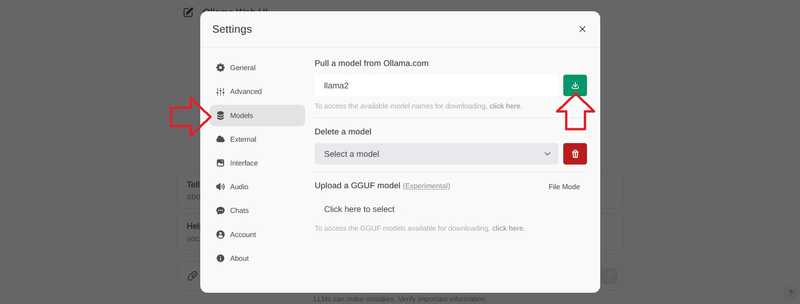
Warten Sie, bis diese Meldung erscheint:
Model 'llama2' has been successfully downloaded.
Schließe die Einstellungen, um zum Chat zurückzukehren.
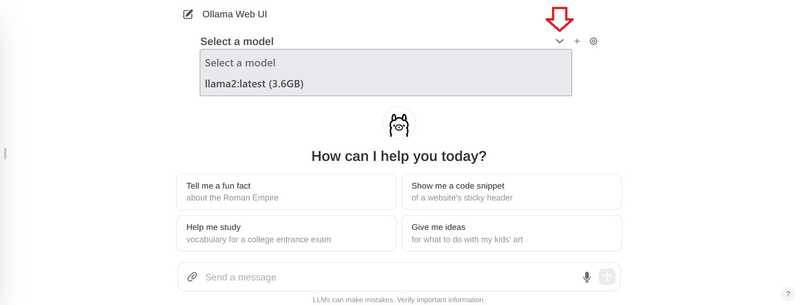
Klicken Sie im Chat oben auf “Modell auswählen” und fügen Sie Ihr Modell hinzu.
Wenn Sie mehrere Modelle hinzufügen möchten, können Sie das Pluszeichen (+) oben verwenden.
Sobald Sie die gewünschten Modelle hinzugefügt haben, können Sie Ihre Fragen stellen. Wenn Sie mehrere Modelle hinzugefügt haben, können Sie zwischen den Antworten wechseln.

Schritt 5 – Fügen Sie Ihr Modell hinzu
Wenn Sie über die Benutzeroberfläche neue Modelle hinzufügen möchten, können Sie dies über folgende Schritte tun: http:// :8080/modelfiles/create/ Tu es. Falls nötig. 8080 mit 3000 Ersetzen.
Im Folgenden wird die Hinzufügung eines neuen Modells über das Terminal beschrieben. Zuerst müssen Sie sich mit dem Server verbinden, auf dem Olama installiert ist. Aus der Liste Welt Dient dazu, die bisher verfügbaren Modelle aufzulisten.
- Erstellen Sie eine Modelldatei
Die Anforderungen an eine Modelldatei finden Sie in der Olama-Dokumentation auf GitHub. In der ersten Zeile der Modelldatei: FROM Sie können das gewünschte Modell auswählen. In diesem Beispiel modifizieren wir das bestehende llama2-Modell. Wenn Sie ein komplett neues Modell hinzufügen möchten, müssen Sie den Pfad zur Modelldatei angeben (z. B. FROM ./my-model.gguf).
nano new-model
Diesen Inhalt speichern:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
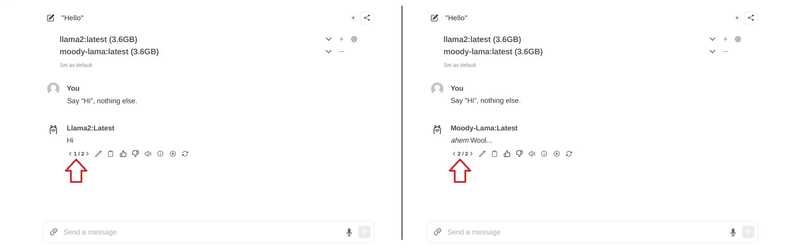
SYSTEM You are a moody lama that only talks about its own fluffy wool.Erstellen Sie ein Modell aus der Modelldatei
ollama create moody-lama -f ./new-model
- Prüfen Sie, ob das neue Modell verfügbar ist.
Verwenden Sie den Befehl olama, um alle Modelle aufzulisten. Moody-lama sollte ebenfalls aufgeführt werden.
ollama list
- Verwenden Sie Ihr Modell in der WebUI.
Wenn Sie zur Weboberfläche zurückkehren, sollte das Modell nun in der Modellauswahlliste angezeigt werden. Falls es noch nicht angezeigt wird, aktualisieren Sie die Seite bitte kurz.
Ergebnis
In diesem Tutorial haben Sie gelernt, wie Sie einen KI-Chat auf Ihrem eigenen Server hosten und wie Sie Ihre eigenen Modelle hinzufügen.









