









TensorFlow
TensorFlow Es handelt sich um eine von Google veröffentlichte Bibliothek für maschinelles Lernen und Deep Learning, die Google an verschiedenen Stellen einsetzt, um seinen Nutzern ein besseres Nutzererlebnis zu bieten. Ein Beispiel dafür ist die automatische Vervollständigung des eingegebenen Textes bei Suchanfragen.
Maschinelles Lernen wird hauptsächlich von drei Gruppen genutzt: 1. Forschern, 2. Datenwissenschaftlern und 3. Programmierern. Um den Bedürfnissen dieser Gruppen gerecht zu werden, hat das Google Brain-Team die TensorFlow-Bibliothek entwickelt. TensorFlow ist auf verschiedenen CPUs und GPUs lauffähig und mit unterschiedlichen Programmiersprachen wie C++, Python oder Java kompatibel. Es kann sowohl auf Servern als auch auf Mobiltelefonen eingesetzt werden.
Geschichte von TensorFlow
Mit zunehmender Datenmenge begannen Deep Learning-Algorithmen immer mehr an Bedeutung zu gewinnen, und Google kam zu dem Schluss, dass es seine Dienste mit diesen tiefen neuronalen Netzen verbessern könnte. Daraufhin begann man mit dem Aufbau eines Frameworks namens TensorFlow, das Entwicklern und Forschern die gleichzeitige Zusammenarbeit an KI-Modellen ermöglichen sollte.
Als das Projekt ausreichend entwickelt und skalierbar war, wurde es 2015 öffentlich freigegeben. Die stabile Version wurde jedoch erst 2017 veröffentlicht.
Das Wichtigste an TensorFlow ist, dass es Open Source ist und unter der Apache-Lizenz steht. Dadurch lässt es sich leicht verwenden, bearbeiten und eigene Versionen veröffentlichen. Man kann damit sogar Geld verdienen, ohne Google dafür bezahlen zu müssen. .
TensorFlow-Architektur
Die TensorFlow-Architektur besteht aus drei Teilen: 1. Datenvorverarbeitung, 2. Modellerstellung und 3. Modelltraining und -schätzung. Der Name TensorFlow leitet sich davon ab, dass es mehrdimensionale Arrays als Eingabe erhält, deren Namen … Tensor Anschließend können Sie eine Reihe von Diagrammen der Operationen auf Ihren Daten ausführen, die Flussdiagramm Ja.
Wo wird es aufgeführt?
Die Nutzung dieser Bibliothek umfasst zwei Phasen:
Entwicklungsphase: Es gibt einen Zeitpunkt, an dem man das Modell trainiert, und diese Phase wird üblicherweise auf dem Laptop oder System durchgeführt.
Implementierungsphase: Sobald das Training abgeschlossen ist, können Sie Ihr Modell überall ausführen, von Desktop-Computern über Server bis hin zu Mobiltelefonen.
Das Training und die Ausführung des Modells können also auf verschiedenen Maschinen erfolgen.
Neben der Verwendung von CPUs kann TensorFlow auch auf GPUs ausgeführt werden.
Bei Matrixberechnungen wird derselbe Operator auf eine große Menge an Informationen angewendet, weshalb diese Art der Berechnung mit der Struktur von GPUs kompatibel ist, wie Forscher der Stanford University Ende 2010 herausfanden.
Ein weiterer Vorteil ist, dass diese Bibliothek in C++ geschrieben ist und daher sehr schnell ist. Selbstverständlich kann sie auch mit anderen Sprachen wie Python verwendet werden.
Ein wichtiges Merkmal von TensorFlow ist TensorBoard, mit dem man sehen kann, was TensorFlow gerade tut.
TensorFlow-Komponenten
Tensor
Ein Tensor ist ein Array von N-dimensionalen Matrizen, die verschiedene Arten von Informationen darstellen können. Jeder Wert im Tensor enthält Informationen derselben Form.
Tensoren können als Eingabe oder Ausgabe einer Berechnung dienen.
Graph
In TensorFlow werden alle Operationen innerhalb eines Graphen ausgeführt. Jeder Graph ist eine Sammlung von Berechnungen, die sequenziell ausgeführt werden. Jede Berechnung wird als Op-Knoten bezeichnet, die mit allen anderen Knoten verbunden sind.
Und warum nun das Diagramm?
- Kann auf verschiedenen Systemen ausgeführt werden.
- Das Diagramm kann zur späteren Verwendung gespeichert werden.
- Alle Berechnungen im Diagramm werden durch die Verknüpfung von Tensoren durchgeführt.
- Kurz gesagt, in Graphen ist jede Kante ein Wert (Tensor) und jeder Knoten ein Operator (wie zum Beispiel die Addition).
Warum ist TensorFlow so berühmt?
TensorFlow ist die beste Lösung, da es für jedermann geeignet ist und APIs nutzt, die sich für verschiedene Skalierungen mit Deep-Learning-Architekturen wie RNN und CNN eignen. Da es auf Graph-Computing basiert, ermöglicht es die Visualisierung neuronaler Netze in TensorBoard, was beim Debuggen sehr hilfreich ist. Insgesamt ist TensorFlow auf Skalierbarkeit im Einsatz ausgelegt.
Die gute Nachricht ist, dass es die größte Community unter den verschiedenen Deep-Learning-Frameworks auf GitHub hat.
Wie viele Algorithmen werden von TensorFlow unterstützt?
- Lineare Regression: tf.estimator.LinearRegressor
- Klassifizierung: tf.estimator.LinearClassifier
- Deep Classification: tf.estimator.DNNClassifier
- Deep Learning Wipe und Deep: tf.estimator.DNNLinearCombinedClassifier
- Booster-Tree-Regression: tf.estimator.BoostedTreesRegressor
- Boosted Trees Classification: tf.estimator.BoostedTreesClassifier
Ein paar einfache Beispiele
- 12import numpy as np
- import tensorflow as tf
In den beiden obigen Zeilen importieren wir die Bibliotheken numpy und tensorflow.
In diesem Beispiel möchten wir X_1 und X_2 multiplizieren. Zuerst müssen wir den Graphen erstellen und dann eine TensorFlow-Sitzung ausführen, um das Ergebnis zu berechnen.
Los geht's.
Schritt 1: Definiere die Variable
Der erste Schritt besteht darin, die Eingabeknoten X_1 und X_2 zu erstellen. In TensorFlow müssen wir angeben, welchen Knotentyp wir erstellen möchten; hier wählen wir den Platzhaltertyp.
Platzhalter:
Dieser Typ weist dem Tensor bei jeder Berechnung einen neuen Wert zu.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
Wie Sie sehen können, haben wir den Typ dieses Knotens als Gleitkommazahl und seinen Namen als Variablennamen eingegeben.
Schritt 2: Berechnung definieren
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
Mit der obigen Zeile erzeugen wir einen Knotenpunkt, der als Operator des Multiplikationsoperators fungiert.
Das ist die Eingabe der Eckpunkte, die wir multiplizieren wollen, und wir haben sie „multiplizieren“ genannt.
Damit haben wir unser erstes Diagramm erstellt.
Schritt 3: Führen Sie den Vorgang aus
Um die Operation auszuführen, müssen wir eine Sitzung erstellen. Diese Sitzung wird mit tf.Session() erstellt und beim Aufruf von run ausgeführt.
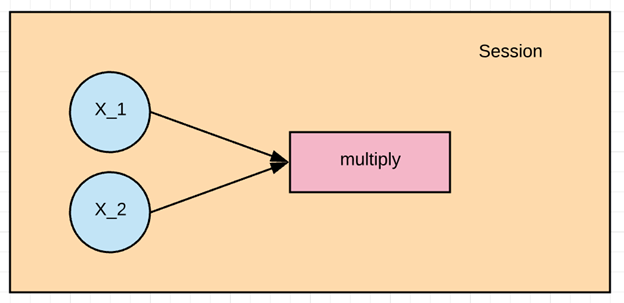
Um die Multiplikation durchzuführen, müssen wir die Werte der Tensoren x1 und x2 als Eingabe übergeben. Dies geschieht durch Zuweisung an feed_dict. In diesem Beispiel werden die Werte 1 bis 3 x1 und die Werte 4 bis 6 x2 zugewiesen. Anschließend geben wir das Ergebnis aus.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
- mit tf.Session() als Sitzung:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(result)
- [ 4. 10. 18.]
Verschiedene Möglichkeiten, Daten in TensorFlow zu importieren
Einer der ersten Schritte vor dem Trainieren des Modells ist der Import der Daten, wofür es zwei Modi gibt:
- Daten in den RAM einlesen: Es gibt eine einfache Möglichkeit, Daten in ein Speicherarray einzulesen, zum Beispiel durch Schreiben einer Codezeile in Python.
- Verwendung der TensorFlow-Datenpipeline: TensorFlow bietet eine Reihe von APIs, mit denen Sie Daten einlesen, verschiedene Operationen darauf ausführen und sie anschließend Ihrem Algorithmus zuführen können. Diese Methode ist besonders effektiv bei großen Datenmengen. Beispielsweise sind Bilder sehr groß und passen nicht in den Arbeitsspeicher. In diesem Fall übernimmt die Datenpipeline die Speicherverwaltung.
Die Frage ist nun, welches System man verwenden soll.
Bei Datenmengen unter 10 GB können Sie problemlos die erste Methode verwenden. Eine bekannte Bibliothek hierfür ist beispielsweise Pandas. Bei beispielsweise 30 GB Daten und 12 GB RAM ist diese Methode hingegen nicht anwendbar. In diesem Fall sollten Sie die Pipeline-API nutzen. Die Pipeline zerlegt die Daten in Batches, die jeweils in die Pipeline eingespeist und zum Trainieren des Modells verwendet werden. Durch die Verwendung der Pipeline ist parallele Verarbeitung möglich. Das bedeutet, dass TensorFlow das Modell gleichzeitig auf mehreren CPUs trainieren kann.
Kurz gesagt: Bei kleinen Datenmengen empfiehlt es sich, diese vollständig in den Arbeitsspeicher zu laden, beispielsweise mit pandas. Andernfalls, oder wenn mehrere CPUs genutzt werden sollen, sollte die TensorFlow-Pipeline verwendet werden.
Erstellen einer Pipeline in TensorFlow
Schritt 1) Daten erstellen
Wir generieren zwei Zufallszahlen mit der NumPy-Bibliothek.
- 123import numpy as np
- x_input = np.random.sample((1,2))
- print(x_input)
- 1[[0.8835775 0.23766977]]
Schritt 2) Einen Platzhalter erstellen
In diesem Schritt erstellen wir einen Platzhalter namens X als Array mit zwei Elementen vom Typ float.
- Verwendung eines Platzhalters #
- x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
Schritt 3: Datensatz erstellen
An dieser Stelle müssen wir den Datensatz definieren, in den wir den Platzhalterwert x einfügen werden.
- 1tf.data.Dataset.from_tensor_slices
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
Schritt 4: Die Pipeline erstellen
In diesem Schritt initialisieren wir die Pipeline. Zuerst erstellen wir einen Iterator, der die Daten durchläuft. Mit der Methode `get_next` erhalten wir den nächsten Wert. In diesem Beispiel enthält ein Batch nur zwei Werte.
- 12iterator = dataset.make_initializable_iterator()
- get_next = iterator.get_next()
Schritt 5: Führen Sie die Berechnung durch.
Im letzten Schritt führen wir eine Sitzung aus, deren Eingabe ein Iterator und von NumPy erzeugte Eingabewerte sind, und geben für jeden Wert diesen aus.
- mit tf.Session() als Sitzung:
- # speisen Sie den Platzhalter mit Daten.
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))
- 1[0.8835775 0.23766978]
Zusammenfassung
TensorFlow ist die bekannteste Deep-Learning-Bibliothek und eignet sich für die Entwicklung beliebiger Deep-Learning-Frameworks. Google Brain entwickelte dieses Projekt, um die Zusammenarbeit zwischen Forschungs- und Entwicklungsteams zu verbessern, und Google setzt es in nahezu allen seinen Projekten ein. Ein Hauptgrund für die Verwendung von TensorFlow ist die einfache Skalierbarkeit beim Deployment. TensorFlow lässt sich von leistungsstarken Servern bis hin zu Android- und iOS-Smartphones nutzen.
TensorFlow arbeitet in einer Sitzung, wobei jede Sitzung durch einen Graphen mit unterschiedlichen Berechnungen definiert wird.
Ein einfaches Beispiel in TensorFlow: Die Multiplikation funktioniert wie folgt:
1. Variablendefinition
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
2. Definition der Berechnung
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
3. Durchführung der Operationen
- mit tf.Session() als Sitzung:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(result)
Eine gängige Praxis in TensorFlow ist das Erstellen einer Pipeline zum Laden von Daten in den RAM. Dies geschieht in folgenden Schritten:
1. Datenerstellung
- import numpy as np
- x_input = np.random.sample((1,2))
- print(x_input)
2. Einen Platzhalter erstellen
- 1x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
3. Definition der Datensatzmethode
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
4. Pipelinebau
- 1iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
5. Programmausführung
- mit tf.Session() als Sitzung:
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))









