









Einführung
Stellen Sie sich vor, Sie könnten mit Ihren unstrukturierten Daten kommunizieren und dabei mühelos wertvolle Informationen extrahieren. In der heutigen datengetriebenen Welt stellt die Gewinnung aussagekräftiger Erkenntnisse aus unstrukturierten Dokumenten nach wie vor eine Herausforderung dar und behindert Entscheidungsfindung und Innovation. In diesem Tutorial lernen Sie Embeddings kennen, erkunden die Nutzung von Amazon OpenSearch als Vektordatenbank und integrieren das Langchain-Framework mit Large Language Models (LLMs), um eine Website mit einem eingebetteten NLP-Chatbot zu erstellen. Wir behandeln die Grundlagen von LLMs, um mithilfe eines Open-Source-LLMs aussagekräftige Erkenntnisse aus unstrukturierten Dokumenten zu gewinnen. Am Ende dieses Tutorials verfügen Sie über ein umfassendes Verständnis dafür, wie Sie aussagekräftige Erkenntnisse aus unstrukturierten Dokumenten gewinnen und diese Fähigkeiten nutzen können, um ähnliche Full-Stack-KI-basierte Lösungen zu entwickeln und Innovationen voranzutreiben.
Voraussetzungen
- Sie benötigen ein aktives AWS-Konto. Falls Sie noch keines besitzen, können Sie sich auf der AWS-Website registrieren.
- Stellen Sie sicher, dass die AWS-Befehlszeilenschnittstelle (CLI) auf Ihrem lokalen Rechner installiert und mit den erforderlichen Anmeldeinformationen und der Standardregion korrekt konfiguriert ist. Die Konfiguration erfolgt mit dem Befehl `aws configure`.
- Laden Sie Docker Engine herunter und installieren Sie es. Befolgen Sie die Installationsanweisungen für Ihr spezifisches Betriebssystem.
Was werden wir bauen?
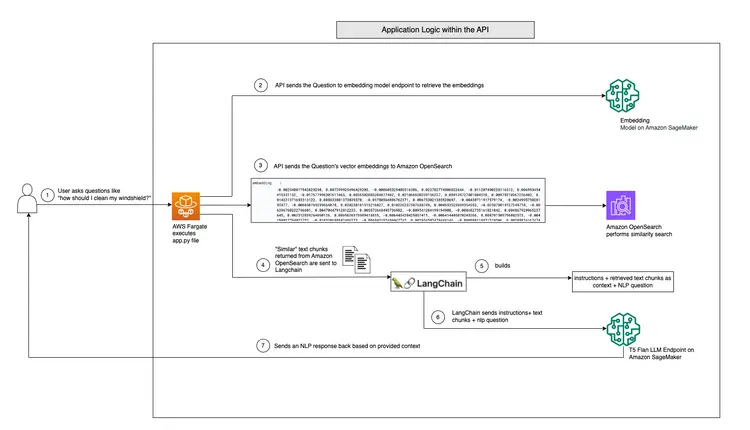
In diesem Beispiel simulieren wir ein Problem, mit dem viele Unternehmen konfrontiert sind. Ein Großteil der heutigen Daten ist unstrukturiert und liegt beispielsweise in Form von Audio- und Videotranskripten, PDF- und Word-Dokumenten, Handbüchern, gescannten Notizen, Social-Media-Transkripten usw. vor. Wir verwenden das Flan-T5 XXL-Modell als LLM (Low-Level-Matrix). Dieses Modell kann Zusammenfassungen und FAQs aus unstrukturierten Texten generieren. Die Abbildung unten zeigt die Architektur der verschiedenen Bausteine.

Fangen wir mit den Grundlagen an.
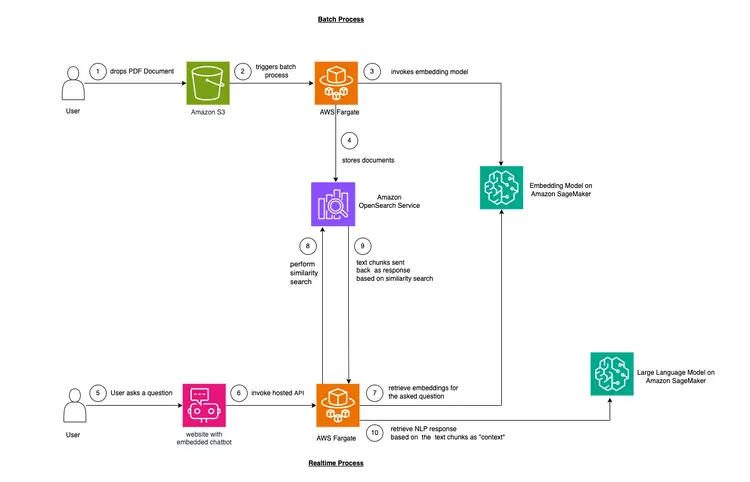
Wir verwenden eine Technik namens kontextbezogenes Lernen, um domänen- oder fallbezogenen “Kontext” in unser Lernmodell (LLM) einzubinden. Konkret handelt es sich um ein unstrukturiertes PDF-Handbuch für ein Auto, das wir als «Kontext» für das LLM hinzufügen möchten. Das LLM soll dann Fragen zu diesem Handbuch beantworten. So einfach ist das! Unser Ziel ist es, einen Schritt weiterzugehen und eine Echtzeit-API zu entwickeln, die Fragen empfängt, an unser Backend weiterleitet und über einen in die Website eingebetteten Open-Source-Chatbot zugänglich ist. Dieses Tutorial ermöglicht es uns, die gesamte Benutzererfahrung zu gestalten und Einblicke in die verschiedenen Konzepte und Werkzeuge des Prozesses zu gewinnen.
- Der erste Schritt zur Bereitstellung von In-Text-Lernen besteht darin, das PDF-Dokument einzulesen und in Textabschnitte zu zerlegen, Vektordarstellungen dieser Textabschnitte, sogenannte “Embeddings”, zu generieren und diese Embeddings schließlich in einer Vektordatenbank zu speichern.
- Vektordatenbanken ermöglichen es uns, «Ähnlichkeitssuchen» anhand der darin gespeicherten Text-Embeddings durchzuführen.
- Amazon SageMaker JumpStart bietet Vorlagen für die Bereitstellung mit nur einem Klick, um die Infrastruktur für Open-Source-Modelle mit vortrainierten Daten einzurichten. Wir werden Amazon SageMaker JumpStart verwenden, um das Embedding-Modell und das Large Language-Modell bereitzustellen.
- Amazon OpenSearch ist eine Such- und Analyse-Engine, die die nächsten Nachbarn von Punkten in einem Vektorraum finden kann und sich daher als Vektordatenbank eignet.
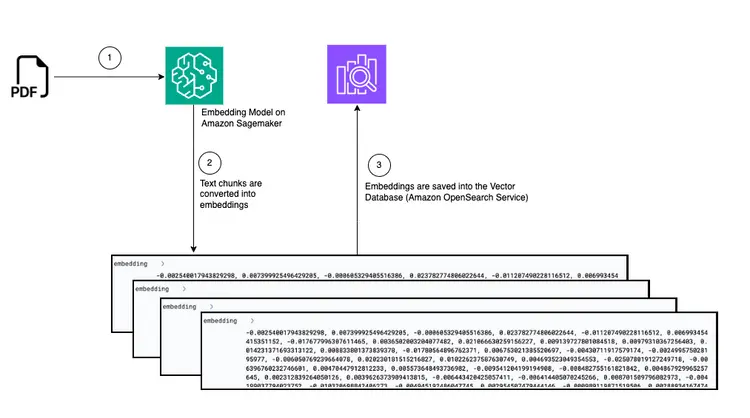
Diagramm: Konvertierung von PDF zu Einbettung in Vektordatenbank
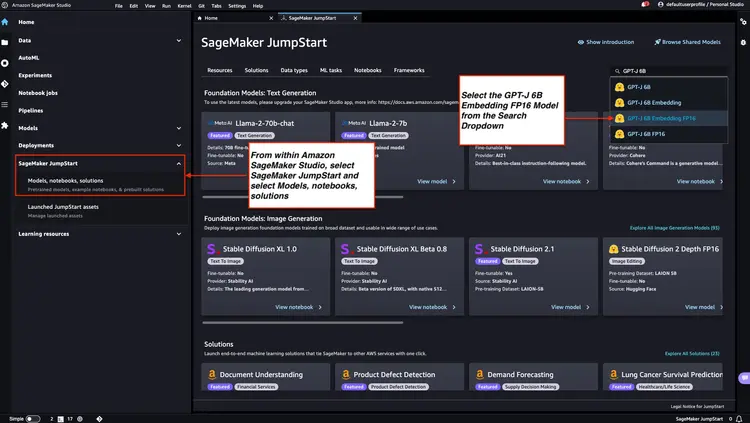
Schritt 1 – Bereitstellung des GPT-J 6B FP16-Einbettungsmodells mit Amazon SageMaker JumpStart
Folgen Sie den Schritten in der Amazon SageMaker-Dokumentation: Öffnen Sie den JumpStart-Bereich im Hauptmenü von Amazon SageMaker Studio, um einen Amazon SageMaker JumpStart-Knoten zu starten. Wählen Sie ‘Modelle, Notebooks, Lösungen’ und anschließend das GPT-J 6B Embedding FP16-Einbettungsmodell (siehe Abbildung unten). Klicken Sie dann auf „Bereitstellen“. Amazon SageMaker JumpStart richtet die Infrastruktur für die Bereitstellung dieses vortrainierten Modells in der SageMaker-Umgebung ein.
Schritt 2 – Flan T5 XXL LLM mit Amazon SageMaker JumpStart bereitstellen
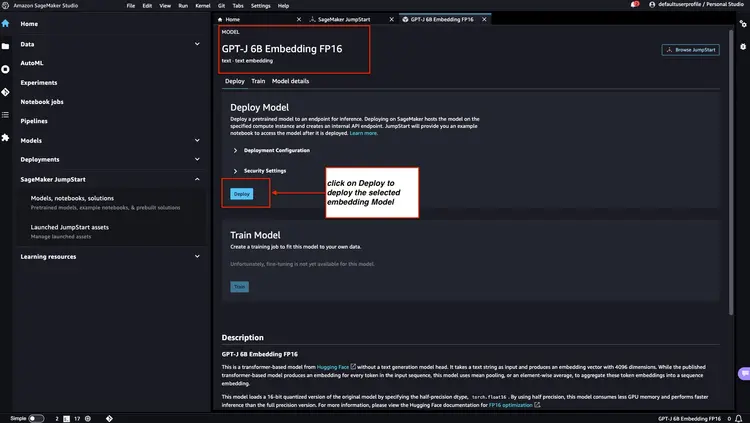
Wählen Sie anschließend in Amazon SageMaker JumpStart Flan-T5 XXL LLM aus und klicken Sie dann auf ‘Bereitstellen’, um die automatische Infrastruktureinrichtung zu starten und den Modellendpunkt in der Amazon SageMaker-Umgebung bereitzustellen.
Schritt 3 – Überprüfen Sie den Status der bereitgestellten Modellendpunkte
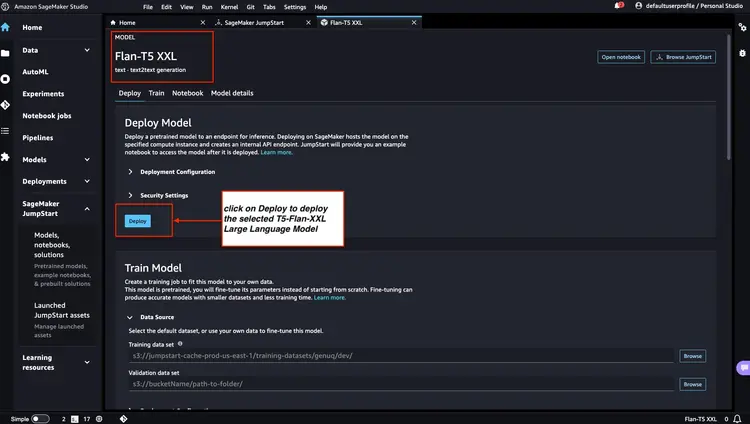
Wir überprüfen den Status der in Schritt 1 und Schritt 2 bereitgestellten Modellendpunkte in der Amazon SageMaker-Konsole und notieren uns deren Namen, da wir sie in unserem Code verwenden werden. So sieht meine Konsole nach der Bereitstellung der Modellendpunkte aus.
Schritt 4 – Amazon Open Search Cluster erstellen
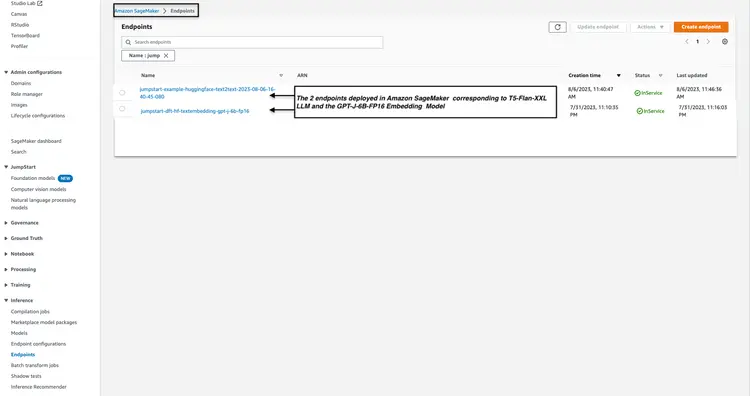
Amazon OpenSearch ist ein Such- und Analysedienst, der den k-Nearest-Neighbors-Algorithmus (kNN) unterstützt. Diese Funktion ist für ähnlichkeitbasierte Suchen von unschätzbarem Wert und ermöglicht die effektive Nutzung von OpenSearch als Vektordatenbank. Weitere Informationen zu den Elasticsearch/OpenSearch-Versionen, die das kNN-Plugin unterstützen, finden Sie unter folgendem Link: k-NN-Plugin-Dokumentation.
Wir verwenden die AWS CLI, um die AWS CloudFormation-Vorlagendatei vom GitHub-Speicherort bereitzustellen. Infrastructure/opensearch-vectordb.yaml Wir werden den AWS-Befehl verwenden. cloudformation create-stack Führen Sie die folgenden Schritte aus, um einen Amazon Open Search-Cluster zu erstellen. Ersetzen Sie die Werte vor der Ausführung des Befehls durch Ihre eigenen. Benutzername Und Passwort Lass es uns tun.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> Schritt 5 – Erstellen Sie den Workflow zur Dokumentenerfassung und -einbettung.
In diesem Schritt erstellen wir eine Pipeline zur Erfassung und Verarbeitung von PDF-Dokumenten, die in einem Amazon Simple Storage Service (S3)-Bucket abgelegt werden. Diese Pipeline führt folgende Aufgaben aus:
- Text aus einem PDF-Dokument extrahieren.
- Konvertiere Textfragmente in Einbettungen (Vektordarstellungen).
- Speichern Sie eingebettete Inhalte in Amazon Open Search.
Das Hochladen einer PDF-Datei in einen S3-Bucket löst einen ereignisgesteuerten Workflow aus, der einen AWS Fargate-Job beinhaltet. Dieser Job ist für die Umwandlung des Textes in eingebettete Elemente und deren Einbettung in Amazon OpenSearch zuständig.
Diagrammatischer Überblick
Nachfolgend ein Diagramm, das die Dokumentenübertragungspipeline zum Speichern eingebetteter Textausschnitte in der Amazon OpenSearch-Vektordatenbank zeigt:
Startskript und Dateistruktur
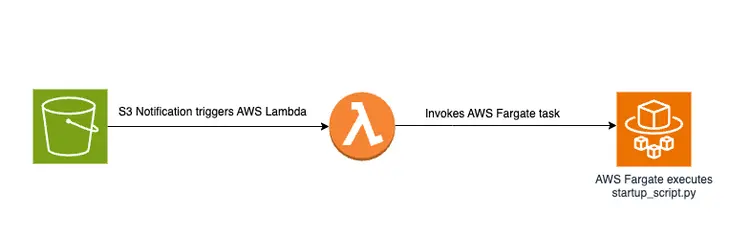
Die Hauptlogik in der Datei create-embeddings-save-in-vectordb\startup_script.py Dieses Python-Skript befindet sich unter startup_script.pyDas Skript führt verschiedene Aufgaben im Zusammenhang mit der Dokumentenverarbeitung, dem Einbetten von Text und dem Einfügen in einen Amazon Open Search-Cluster aus. Es lädt ein PDF-Dokument aus einem Amazon S3-Bucket herunter und zerlegt es in kleinere Textabschnitte. Der Textinhalt jedes Abschnitts wird an den in Amazon SageMaker bereitgestellten Endpunkt des GPT-J 6B FP16-Einbettungsmodells (abgerufen über die Umgebungsvariable TEXT_EMBEDDING_MODEL_ENDPOINT_NAME) gesendet, um Texteinbettungen zu erstellen. Diese Einbettungen werden zusammen mit anderen Informationen im Amazon Open Search-Index abgelegt. Das Skript ruft Konfigurations- und Validierungsparameter aus Umgebungsvariablen ab und sorgt so für Konsistenz in verschiedenen Umgebungen. Es ist für die einheitliche Ausführung in einem Docker-Container vorgesehen.
Docker-Image erstellen und veröffentlichen
Nachdem ich den Code verstanden hatte startup_script.pyWir werden die Dockerfile aus dem Ordner erstellen. create-embeddings-save-in-vectordb Wir laden das Image nun in die Amazon Elastic Container Registry (Amazon ECR) hoch. Amazon ECR ist eine vollständig verwaltete Container-Registry, die leistungsstarkes Hosting bietet, sodass wir Anwendungs-Images und Artefakte zuverlässig überall bereitstellen können. Wir verwenden die AWS CLI und die Docker CLI, um das Docker-Image zu erstellen und in Amazon ECR hochzuladen. In allen folgenden Befehlen Ersetzen Sie dies durch die korrekte AWS-Kontonummer.
Rufen Sie ein Authentifizierungstoken ab und authentifizieren Sie den Docker-Client bei der Registry über die AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com Erstellen Sie Ihr Docker-Image mit dem folgenden Befehl.
docker build -t save-embedding-vectordb .
Sobald der Build abgeschlossen ist, taggen Sie das Image, damit wir es in dieses Repository hochladen können:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Führen Sie den folgenden Befehl aus, um dieses Image in das neue Amazon ECR-Repository zu übertragen:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
Sobald das Docker-Image in das Amazon ECR-Repository hochgeladen wurde, sollte es wie folgt aussehen:
Aufbau einer Infrastruktur für einen ereignisbasierten PDF-Einbettungs-Workflow
Wir können die AWS-Befehlszeilenschnittstelle (AWS CLI) verwenden, um einen CloudFormation-Stack für einen ereignisgesteuerten Workflow mit den angegebenen Parametern zu erstellen. Die CloudFormation-Vorlage ist im GitHub-Repository unter [Link einfügen] verfügbar. Infrastructure/fargate-embeddings-vectordb-save.yaml Wir müssen die Parameter ignorieren, um die AWS-Umgebung nachzubilden.
Hier sind die wichtigsten Parameter, die im Befehl aktualisiert werden müssen. aws cloudformation create-stack Es heißt:
- BucketName: Dieser Parameter repräsentiert den Amazon S3-Bucket, in dem die PDF-Dokumente abgelegt werden.
- VpcId und SubnetId: Diese Parameter legen fest, wo die Fargate-Aufgabe ausgeführt wird.
- ImageName: Dies ist der Name des Docker-Images in der Amazon Elastic Container Registry (ECR) für save-embedding-vectordb.
- TextEmbeddingModelEndpointName: Verwenden Sie diesen Parameter, um den Namen des in Schritt 1 in Amazon SageMaker bereitgestellten Einbettungsmodells anzugeben.
- VectorDatabaseEndpoint: Geben Sie die Endpunktadresse der Amazon OpenSearch-Domäne an.
- VectorDatabaseUsername und VectorDatabasePassword: Diese Parameter sind die Anmeldeinformationen, die für den Zugriff auf den in Schritt 4 erstellten Amazon Open Search-Cluster benötigt werden.
- VectorDatabaseIndex: Legt den Namen des Index in Amazon Open Search fest, in dem eingebettete PDF-Dokumente gespeichert werden.
Um die Erstellung des CloudFormation-Stacks nach der Aktualisierung der Parameterwerte durchzuführen, verwenden wir den folgenden AWS CLI-Befehl:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualDurch die Erstellung des oben beschriebenen CloudFormation-Stacks richten wir einen S3-Bucket ein und erstellen S3-Benachrichtigungen, die eine Lambda-Funktion starten. Diese Lambda-Funktion wiederum startet einen Fargate-Task. Der Fargate-Task erstellt einen Docker-Container mit der Datei startup-script.py Implementiert die Funktion, die für die Erstellung von Einbettungen in Amazon OpenSearch unter einem neuen OpenSearch-Index namens „…“ verantwortlich ist. Autohandbuch Es ist.
Testen Sie es mit einem PDF-Beispiel.
Sobald der CloudFormation-Stack ausgeführt wird, legen Sie eine PDF-Datei mit dem Maschinenhandbuch in Ihren S3-Bucket hoch. Ich habe ein Maschinenhandbuch heruntergeladen, das hier verfügbar ist. Nachdem die ereignisbasierte Transportpipeline abgeschlossen ist, sollte der Amazon OpenSearch-Cluster das folgende Profil enthalten: Autohandbuch Mit den unten gezeigten Einbettungen.
Schritt 6 – Implementierung der Echtzeit-Fragen-und-Antworten-API mit Llm-Textunterstützung
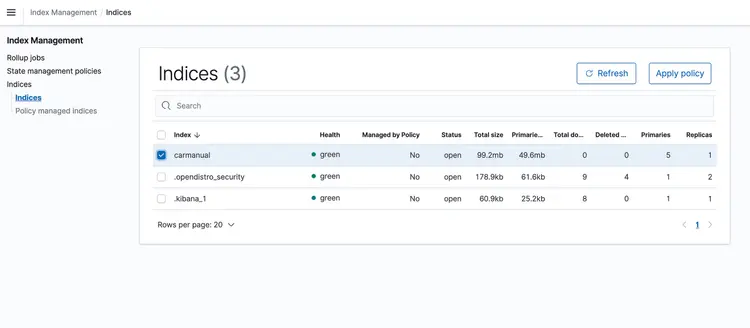
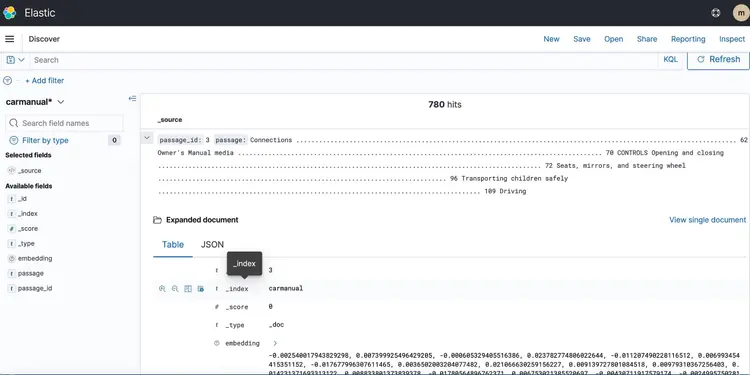
Nachdem wir unsere Texteinbettungen in einer von Amazon Open Search unterstützten Vektordatenbank gespeichert haben, fahren wir mit dem nächsten Schritt fort. Hier nutzen wir die Funktionen des T5 Flan XXL LLM, um in Echtzeit Antworten zu unserer Fahrzeugbedienungsanleitung zu erhalten.
Wir nutzen die in der Vektordatenbank gespeicherten Einbettungen, um LLM Kontextinformationen bereitzustellen. Dieser Kontext ermöglicht es LLM, Fragen zu unserer Fahrzeugbedienungsanleitung effektiv zu verstehen und zu beantworten. Dazu verwenden wir das Framework LangChain, welches die Koordination der verschiedenen Komponenten unseres von LLM entwickelten, textbasierten Echtzeit-Frage-Antwort-Systems vereinfacht.
In einer Vektordatenbank gespeicherte Embeddings stellen die Bedeutungen und Beziehungen von Wörtern dar und ermöglichen Berechnungen auf Basis semantischer Ähnlichkeiten. Während Embeddings Vektordarstellungen von Textausschnitten erstellen, um Bedeutungen und Beziehungen zu erfassen, ist T5 Flan LLM darauf spezialisiert, kontextrelevante Antworten auf Basis des in Anfragen und Abfragen eingefügten Kontexts zu generieren. Ziel ist es, Benutzerfragen mit Textausschnitten abzugleichen, indem Embeddings für die Fragen erstellt und anschließend deren Ähnlichkeit zu anderen in der Vektordatenbank gespeicherten Embeddings gemessen wird.
Indem wir Textausschnitte und Nutzeranfragen als Vektoren darstellen, können wir mathematische Berechnungen durchführen, um kontextbezogene Ähnlichkeitssuchen durchzuführen. Um die Ähnlichkeit zwischen zwei Datenpunkten zu messen, verwenden wir Distanzmetriken in einem mehrdimensionalen Raum.
Das untenstehende Diagramm zeigt den Echtzeit-Frage-und-Antwort-Workflow, der von LangChain und unserem T5 Flan LLM bereitgestellt wird.
Grafische Übersicht der Echtzeit-Frage-und-Antwort-Unterstützung von T5-Flan-XXL LLM
Erstellen Sie die API
Nachdem wir unseren LangChain- und T5 Flask LLM-Workflow besprochen haben, schauen wir uns nun den API-Code an, der Benutzerfragen entgegennimmt und kontextbezogene Antworten liefert. Diese Echtzeit-Frage-und-Antwort-API befindet sich im Ordner „RAG-langchain-questionanswer-t5-llm“ unseres GitHub-Repositorys, und ihre Kernlogik ist in der Datei „app.py“ implementiert. Diese Flask-basierte Anwendung definiert eine Route „/qa“ zum Beantworten von Fragen.
Wenn ein Benutzer eine Anfrage an die API sendet, verwendet diese die Umgebungsvariable TEXT_EMBEDDING_MODEL_ENDPOINT_NAME und verweist auf einen Amazon SageMaker-Endpunkt, um die Anfrage in numerische Vektordarstellungen, sogenannte Embeddings, umzuwandeln. Diese Embeddings erfassen die semantische Bedeutung des Textes.
Die API nutzt Amazon OpenSearch für kontextbezogene Ähnlichkeitssuchen und ruft relevante Textausschnitte aus dem OpenSearch-Verzeichnishandbuch basierend auf den Einbettungen der Nutzeranfragen ab. Anschließend ruft die API den T5 Flan LLM-Endpunkt auf, der durch die Umgebungsvariable T5FLAN_XXL_ENDPOINT_NAME identifiziert und ebenfalls in Amazon SageMaker bereitgestellt wird. Der Endpunkt verwendet die von Amazon OpenSearch abgerufenen Textausschnitte als Kontext für die Generierung von Antworten. Diese Textausschnitte liefern dem T5 Flan LLM-Endpunkt wertvollen Kontext und ermöglichen so die Bereitstellung aussagekräftiger Antworten auf Nutzeranfragen. Der API-Code verwendet LangChain zur Orchestrierung all dieser Interaktionen.
Erstellen und veröffentlichen Sie das Docker-Image für die API.
Nachdem wir den Code in app.py verstanden haben, erstellen wir das Dockerfile aus dem Ordner RAG-langchain-questionanswer-t5-llm und laden das Image in Amazon ECR hoch. Wir verwenden die AWS CLI und die Docker CLI, um das Docker-Image zu erstellen und in Amazon ECR hochzuladen. In allen folgenden Befehlen Ersetzen Sie dies durch die korrekte AWS-Kontonummer.
Rufen Sie ein Authentifizierungstoken ab und authentifizieren Sie den Docker-Client bei der Registry über die AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Erstellen Sie das Docker-Image mit dem folgenden Befehl.
docker build -t qa-container .
Sobald der Build abgeschlossen ist, taggen Sie das Image, damit wir es in dieses Repository hochladen können:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Führen Sie den folgenden Befehl aus, um dieses Image in das neue Amazon ECR-Repository zu übertragen:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
Sobald das Docker-Image in das Amazon ECR-Repository hochgeladen wurde, sollte es wie folgt aussehen:
Erstellen Sie einen CloudFormation-Stack zum Hosten des API-Endpunkts.
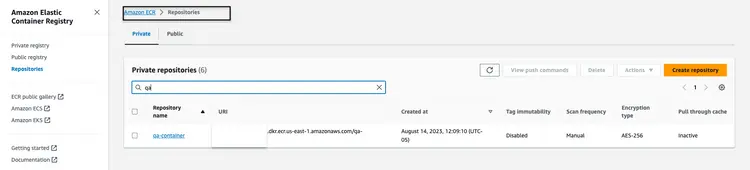
Wir verwenden die AWS-Befehlszeilenschnittstelle (CLI), um einen CloudFormation-Stack für einen Amazon ECS-Cluster zu erstellen, der eine Fargate-Aufgabe zur Bereitstellung der API hostet. Die CloudFormation-Vorlage befindet sich im GitHub-Repository unter Infrastructure/fargate-api-rag-llm-langchain.yaml. Wir müssen die Parameter an die AWS-Umgebung anpassen. Hier sind die wichtigsten Parameter, die im Befehl `aws cloudformation create-stack` aktualisiert werden müssen:
- DemoVPC: Dieser Parameter gibt die virtuelle private Cloud (VPC) an, in der Ihr Dienst ausgeführt wird.
- PublicSubnetIds: Dieser Parameter erfordert eine Liste öffentlicher Subnetz-IDs, in denen sich Ihr Load Balancer und Ihre Aufgaben befinden werden.
- IMAGENAME: Geben Sie den Namen des Docker-Images in der Amazon Elastic Container Registry (ECR) für den qa-Container an.
- TextEmbeddingModelEndpointName: Geben Sie den Endpunktnamen des in Schritt 1 in Amazon SageMaker bereitgestellten Embeddings-Modells an.
- T5FlanXXLEndpointName: Legen Sie den T5-FLAN-Endpunktnamen fest, der in Schritt 2 auf Amazon SageMaker bereitgestellt wurde.
- VectorDatabaseEndpoint: Geben Sie die Endpunktadresse der Amazon OpenSearch-Domäne an.
- VectorDatabaseUsername und VectorDatabasePassword: Diese Parameter sind die Anmeldeinformationen, die für den Zugriff auf den in Schritt 4 erstellten OpenSearch-Cluster benötigt werden.
- VectorDatabaseIndex: Legen Sie den Namen des Index in Amazon OpenSearch fest, in dem Ihre Servicedaten gespeichert werden. Der in diesem Beispiel verwendete Indexname lautet carmanual.
Um die Erstellung des CloudFormation-Stacks nach der Aktualisierung der Parameterwerte durchzuführen, verwenden wir den folgenden AWS CLI-Befehl:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualNachdem Sie den oben genannten CloudFormation-Stack erfolgreich ausgeführt haben, rufen Sie die AWS-Konsole auf und öffnen Sie den Tab ‘CloudFormation-Ausgaben’ für den ecs-questionanswer-llm-Stack. Dort finden Sie alle notwendigen Informationen, einschließlich des API-Endpunkts. Nachfolgend sehen Sie ein Beispiel, wie die Ausgabe aussehen könnte:
Testen Sie die API
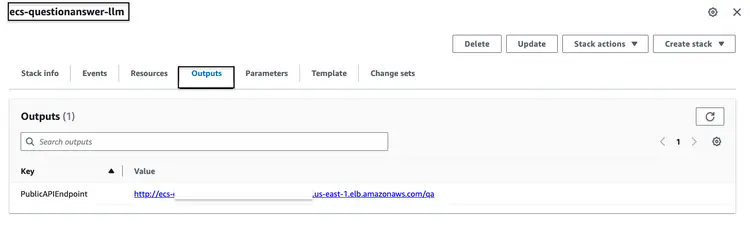
Wir können den API-Endpunkt mit dem curl-Befehl wie folgt testen:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
Wir werden eine Reaktion wie die untenstehende sehen.
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
Schritt 7 – Erstellen und Bereitstellen einer Website mit integriertem Chatbot
Anschließend folgen der letzte Schritt unserer Full-Stack-Pipeline: die Integration der API mit dem eingebetteten Chatbot in eine HTML-Website. Für diese Website und den eingebetteten Chatbot verwenden wir eine Node.js-Anwendung mit einer index.html-Datei, die mit dem Open-Source-Chatbot botkit.js integriert ist. Zur Vereinfachung habe ich ein Dockerfile erstellt und es zusammen mit dem Code im Ordner „homegrown_website_and_bot“ bereitgestellt. Wir verwenden die AWS CLI und die Docker CLI, um das Docker-Image für die Frontend-Website zu erstellen und in Amazon ECR hochzuladen. In allen folgenden Befehlen gilt: Ersetzen Sie dies durch die korrekte AWS-Kontonummer.
Rufen Sie ein Authentifizierungstoken ab und authentifizieren Sie den Docker-Client bei der Registry über die AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
Erstellen Sie das Docker-Image mit folgendem Befehl:
docker build -t web-chat-frontend .
Sobald der Build abgeschlossen ist, taggen Sie das Image, damit wir es in dieses Repository hochladen können:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Führen Sie den folgenden Befehl aus, um dieses Image in das neue Amazon ECR-Repository zu übertragen:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
Nachdem das Docker-Image für die Website in das ECR-Repository hochgeladen wurde, erstellen wir den CloudFormation-Stack für das Frontend, indem wir die Datei `Infrastructure\fargate-website-chatbot.yaml` ausführen. Die Parameter müssen an die AWS-Umgebung angepasst werden. Hier sind die wichtigsten Parameter, die im Befehl `aws cloudformation create-stack` aktualisiert werden müssen:
- DemoVPC: Dieser Parameter gibt die virtuelle private Cloud (VPC) an, in der Ihre Website bereitgestellt wird.
- PublicSubnetIds: Dieser Parameter erfordert eine Liste öffentlicher Subnetz-IDs, in denen Ihr Website-Loadbalancer und Ihre Aufgaben platziert werden.
- IMAGENAME: Geben Sie den Namen des Docker-Images in der Amazon Elastic Container Registry (ECR) für Ihre Website ein.
- QUESTRULD: Geben Sie die URL des in Schritt 6 bereitgestellten API-Endpunkts an. Das Format ist http:// Es ist /qa.
Um die Erstellung des CloudFormation-Stacks nach der Aktualisierung der Parameterwerte durchzuführen, verwenden wir den folgenden AWS CLI-Befehl:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaSchritt 8 – Sehen Sie sich den Car Savvy KI-Assistenten an
Nachdem Sie den oben genannten CloudFormation-Stack erfolgreich erstellt haben, rufen Sie die AWS-Konsole auf und öffnen Sie den Tab „CloudFormation-Ausgaben“ für den Stack „ecs-website-chatbot“. Dort finden Sie den DNS-Namen des Application Load Balancers (ALB), der mit dem Frontend verknüpft ist. Nachfolgend sehen Sie ein Beispiel, wie die Ausgabe aussehen könnte:
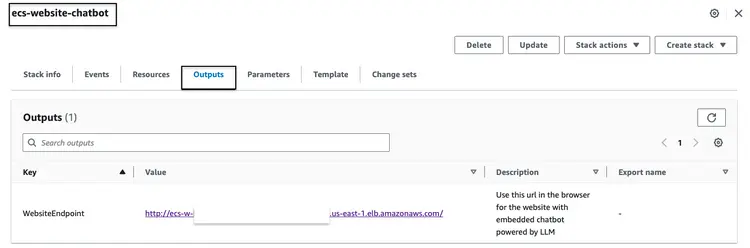
Rufen Sie die Endpunkt-URL im Browser auf, um sich die Website anzusehen. Stellen Sie dem integrierten Chatbot Fragen in natürlicher Sprache. Beispiele für solche Fragen sind: “Wie reinige ich meine Windschutzscheibe?”, “Wo finde ich die Fahrzeugidentifikationsnummer (FIN)?”, “Wie melde ich einen Sicherheitsmangel?”
Wie geht es weiter?

Ich hoffe, die obigen Ausführungen zeigen Ihnen, wie Sie Ihre eigenen produktionsreifen Pipelines für LLMs erstellen und diese mit Ihren Frontend-Chatbots und eingebetteter NLP integrieren können. Lassen Sie mich wissen, worüber Sie sonst noch gerne lesen möchten – zum Thema Open-Source-Technologien, Analytik, maschinelles Lernen und AWS!
Im weiteren Verlauf Ihres Lernprozesses empfehle ich Ihnen, sich eingehender mit Embeddings, Vektordatenbanken, LangChain und weiteren LLMs auseinanderzusetzen. Diese sind im Amazon SageMaker JumpStart sowie in den AWS-Tools verfügbar, die wir in diesem Tutorial verwendet haben, wie beispielsweise Amazon OpenSearch, Docker-Container und Fargate. Hier sind einige nächste Schritte, die Ihnen helfen, diese Technologien zu beherrschen:
- Amazon SageMaker: Machen Sie sich im Laufe Ihrer Arbeit mit SageMaker auch mit den anderen angebotenen Algorithmen vertraut.
- AMAZON-OPEN-SUCHE: Erfahren Sie mehr über den K-NN-Algorithmus und andere Distanzalgorithmen.
- Langchain: LangChain ist ein Framework, das die Erstellung von Anwendungen mit LLM vereinfachen soll.
- Einbettungen: Eine Einbettung ist eine numerische Darstellung einer Information, z. B. von Texten, Dokumenten, Bildern, Audiodateien usw.
- Amazon SageMaker JumpStart: SageMaker JumpStart bietet vortrainierte Open-Source-Modelle für eine breite Palette von Problemtypen, um Ihnen den Einstieg in das maschinelle Lernen zu erleichtern.
Löschen
- Melden Sie sich bei der AWS CLI an. Stellen Sie sicher, dass die AWS CLI ordnungsgemäß konfiguriert ist und über die erforderlichen Berechtigungen verfügt, um diese Aktionen auszuführen.
- Löschen Sie die PDF-Datei aus Ihrem Amazon S3-Bucket, indem Sie den folgenden Befehl ausführen. Ersetzen Sie „bucket-name“ durch den tatsächlichen Namen Ihres Amazon S3-Buckets und passen Sie gegebenenfalls den Pfad zu Ihrer PDF-Datei an.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
Löschen Sie die CloudFormation-Stacks. Ersetzen Sie die Stack-Namen durch die tatsächlichen Namen Ihrer CloudFormation-Stacks.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2Ergebnis
In diesem Tutorial haben wir einen Full-Stack-Fragen-und-Antworten-Chatbot mit AWS-Technologien und Open-Source-Tools entwickelt. Wir haben Amazon OpenSearch als Vektordatenbank und ein GPT-J 6B FP16-Einbettungsmodell integriert und Langchain mit einem LLM verwendet. Der Chatbot extrahiert Erkenntnisse aus unstrukturierten Dokumenten.









