









Einführung
Stellen Sie sich eine Datenbank vor, die Daten nicht nur speichert, sondern sie auch versteht. In den letzten Jahren haben KI-Anwendungen nahezu alle Branchen revolutioniert und die Zukunft des Computings verändert.
Vektordatenbanken revolutionieren die Verwaltung unstrukturierter Daten und ermöglichen es uns, Wissen so zu speichern, dass Beziehungen, Ähnlichkeiten und Kontext erfasst werden. Im Gegensatz zu herkömmlichen Datenbanken, die primär auf strukturierten, tabellarisch gespeicherten Daten basieren und sich auf exakte Übereinstimmungen konzentrieren, erlauben Vektordatenbanken die Speicherung unstrukturierter Daten – wie Bilder, Texte und Audiodateien – in einem Format, das von Modellen des maschinellen Lernens verstanden und verglichen werden kann.
Anstatt sich auf exakte Übereinstimmungen zu verlassen, finden Vektordatenbanken die ähnlichsten Einträge und ermöglichen so das effiziente Auffinden alternativer oder semantisch ähnlicher Elemente. Im heutigen Zeitalter, in dem künstliche Intelligenz allgegenwärtig ist, sind Vektordatenbanken unverzichtbar geworden für Anwendungen wie große Sprachmodelle und Modelle des maschinellen Lernens, die Einbettungen generieren und verarbeiten.
Was genau ist also Embedding? Wir werden das in Kürze in diesem Artikel behandeln.
Ob für Empfehlungssysteme oder zur Unterstützung dialogorientierter KI – Vektordatenbanken haben sich zu einer leistungsstarken Datenspeicherlösung entwickelt, die es uns ermöglicht, auf neue und spannende Weise auf Daten zuzugreifen und mit ihnen zu interagieren.
Schauen wir uns nun an, welche Datenbanken am häufigsten verwendet werden:
- SQL: Speichert strukturierte Daten und verwendet Tabellen zur Speicherung von Daten mit einem definierten Schema. Die gängigsten Datenbanken sind MySQL, Oracle Database und PostgreSQL.
- NoSQL: Es handelt sich um eine sehr flexible, schemalose Datenbank. Sie ist außerdem bekannt für die Verarbeitung unstrukturierter und semistrukturierter Daten. Sie hat sich für viele Echtzeit-Webanwendungen und Big Data bestens bewährt. Die bekanntesten Beispiele sind MongoDB und Cassandra.
- Graph: Dann kam der Graph, der Daten als Knoten und Kanten speichert und für die Verwaltung vernetzter Daten konzipiert ist. Beispiele: Neo4j, ArangoDB.
- Vektordatenbanken: Datenbanken, die zum Speichern und Abfragen hochdimensionaler Vektoren entwickelt wurden und Ähnlichkeitssuchen sowie Datenerweiterungen für KI/ML-Aufgaben ermöglichen. Die gängigsten sind Pinecone, Weaviate und Chroma.
Voraussetzungen
- Kenntnisse über Ähnlichkeitsmaße: Verständnis von Maßen wie Kosinusähnlichkeit, euklidischer Distanz oder Skalarprodukt zum Vergleich von Vektordaten.
- Grundlegende ML- und KI-Konzepte: Kenntnisse über Modelle und Anwendungen des maschinellen Lernens, insbesondere solche, die Einbettungen generieren (z. B. NLP, Computer Vision).
- Kenntnisse über Datenbankkonzepte: Allgemeines Wissen über Datenbanken, einschließlich der Prinzipien der Indizierung, Abfrage und Datenspeicherung.
- Programmierkenntnisse: Fundierte Kenntnisse in Python oder ähnlichen Sprachen, die häufig in ML-Bibliotheken und Vektordatenbanken verwendet werden.
Warum verwenden wir Vektordatenbanken und worin unterscheiden sie sich?
Angenommen, wir speichern Daten in einer herkömmlichen SQL-Datenbank, in der jeder Datenpunkt in ein Embedding umgewandelt und gespeichert wird. Beim Erstellen einer Abfrage wird diese ebenfalls in ein Embedding umgewandelt. Anschließend versuchen wir, die relevantesten Abfrage-Embeddings zu finden, indem wir dieses Abfrage-Embedding mithilfe der Kosinusähnlichkeit mit den gespeicherten Embeddings vergleichen.
Diese Methode kann jedoch aus verschiedenen Gründen unwirksam werden:
- Hohe Dimensionalität: Einbettungen sind üblicherweise hochdimensional. Dies kann zu langsamen Abfragezeiten führen, da jeder Vergleich eine vollständige Suche in allen gespeicherten Einbettungen erfordern kann.
- Skalierbarkeitsprobleme: Der Rechenaufwand für die Berechnung der Kosinusähnlichkeit zwischen Millionen von Einbettungen wird bei großen Datensätzen prohibitiv. Herkömmliche SQL-Datenbanken sind für diese Aufgabe nicht optimiert, was die Echtzeitabfrage erschwert.
Daher stoßen herkömmliche Datenbanken bei effizienten, umfangreichen Suchvorgängen an ihre Grenzen. Zudem ist ein erheblicher Teil der täglich generierten Daten unstrukturiert und kann nicht in herkömmlichen Datenbanken gespeichert werden.

Um dieses Problem zu lösen, verwenden wir eine Vektordatenbank. In einer Vektordatenbank gibt es das Konzept des Index, der eine effiziente Ähnlichkeitssuche in hochdimensionalen Daten ermöglicht. Durch die Organisation von Vektoreinbettungen trägt er maßgeblich zur Beschleunigung von Abfragen bei und ermöglicht es der Datenbank, selbst in großen Datensätzen schnell ähnliche Vektoren zu finden. Vektorindizes reduzieren den Suchraum und ermöglichen die Skalierung auf Millionen oder Milliarden von Vektoren. Dies gewährleistet schnelle Abfrageantworten auch bei großen Datensätzen.
In herkömmlichen Datenbanken suchen wir nach Zeilen, die unserer Suchanfrage entsprechen. In Vektordatenbanken verwenden wir Ähnlichkeitsmaße, um den Vektor zu finden, der unserer Suchanfrage am ähnlichsten ist.
Vektordatenbanken nutzen eine Kombination von Algorithmen für die approximative Nächste-Nachbarn-Suche (ANN), die die Suche durch Hashing, Quantisierung oder graphenbasierte Methoden optimieren. Diese Algorithmen arbeiten in einer Pipeline zusammen, um schnelle und präzise Ergebnisse zu liefern. Da Vektordatenbanken nur eine approximative Übereinstimmung bieten, besteht ein Zielkonflikt zwischen Genauigkeit und Geschwindigkeit – höhere Genauigkeit kann die Abfrage verlangsamen.
Grundlagen der Vektordarstellung
Was sind Vektoren?
Vektoren lassen sich als Zahlenreihen in einer Datenbank verstehen. Beliebige Datentypen wie Bilder, Texte, PDF-Dateien und Audiodateien können in numerische Werte umgewandelt und als Zahlenreihe in einer Vektordatenbank gespeichert werden. Diese numerische Darstellung von Daten ermöglicht die sogenannte Ähnlichkeitssuche.
Bevor wir uns mit Vektoren beschäftigen, wollen wir uns mit semantischer Suche und Einbettungen auseinandersetzen.
Was ist semantische Suche?
Die semantische Suche sucht nach der Bedeutung von Wörtern und ihrem Kontext, anstatt nach exakten Phrasen zu suchen. Anstatt sich auf das Schlüsselwort zu konzentrieren, versucht die semantische Suche, die Bedeutung zu verstehen. Nehmen wir zum Beispiel das Wort “Python”. Bei einer herkömmlichen Suche würde das Wort “Python” möglicherweise Ergebnisse sowohl für Python-Programmierung als auch für Python-Schlangen liefern, da nur das Wort selbst erkannt wird. Die semantische Suche hingegen berücksichtigt den Kontext. Wenn kürzlich nach «Programmiersprachen» oder «maschinellem Lernen» gesucht wurde, würden wahrscheinlich Ergebnisse zur Python-Programmierung angezeigt. Bei Suchanfragen nach «seltsamen Tieren» oder «Reptilien» würde die Suchmaschine hingegen davon ausgehen, dass Pythons Schlangen sind, und die Ergebnisse entsprechend anpassen.

Durch die Identifizierung des Kontextes hilft die semantische Suche dabei, die relevantesten Informationen auf der Grundlage der tatsächlichen Absicht aufzudecken.
Was sind Einbettungen?
Einbettungen sind eine Möglichkeit, Wörter als numerische Vektoren darzustellen (stellen wir uns Vektoren vorerst als Zahlenlisten vor; beispielsweise könnte das Wort «Katze» zu [.1,.8,.75,.85] werden). In einem hochdimensionalen Raum verarbeiten Computer diese numerische Repräsentation eines Wortes schnell.
Wörter haben unterschiedliche Bedeutungen und Beziehungen. Beispielsweise haben die Wörter “König” und “Königin” in Wortvektoren ähnliche Vektoren wie “König” und “Auto”.
Einbettungen erfassen den Kontext eines Wortes anhand seiner Verwendung in Sätzen. Beispielsweise kann “Bank” sowohl ein Finanzinstitut als auch ein Flussufer bezeichnen, und Einbettungen helfen, diese Bedeutungen anhand der umgebenden Wörter zu erkennen. Einbettungen sind eine intelligentere Methode für Computer, Wörter, Bedeutungen und Zusammenhänge zu verstehen.
Eine Möglichkeit, sich ein Embedding vorzustellen, besteht darin, die verschiedenen Merkmale eines Wortes abzubilden und jedem dieser Merkmale einen Wert zuzuordnen. Dies ergibt eine Zahlenfolge, einen sogenannten Vektor. Es gibt verschiedene Techniken zur Erstellung solcher Wort-Embeddings. Ein Vektor-Embedding ist somit eine Möglichkeit, einen Satz oder ein Dokument aus Wörtern durch Zahlen darzustellen, die Bedeutung und Beziehungen verdeutlichen. Vektor-Embeddings ermöglichen es, Wörter als Punkte im Raum darzustellen, wobei ähnliche Wörter nahe beieinander liegen.
Diese Vektoreinbettungen ermöglichen mathematische Operationen wie Addition und Subtraktion, mit denen sich Beziehungen darstellen lassen. Beispielsweise kann die bekannte Vektoroperation “König – Mann + Frau” einen Vektor ergeben, der dem Ausdruck “Königin” sehr nahe kommt.
Ähnlichkeitskriterien in Vektorräumen
Um die Ähnlichkeit der einzelnen Vektoren zu messen, werden mathematische Verfahren eingesetzt, um die Ähnlichkeit oder Unähnlichkeit zu quantifizieren. Einige davon sind im Folgenden aufgeführt:
- Kosinusähnlichkeit: Der Kosinus misst den Winkel zwischen zwei Vektoren und liegt zwischen -1 und 1. Dabei bedeutet -1, dass die Vektoren genau entgegengesetzt sind, 1, dass sie identisch sind, und 0, dass sie orthogonal oder unähnlich sind.
- Euklidische Distanz: Misst die geradlinige Entfernung zwischen zwei Punkten im Vektorraum. Kleinere Werte deuten auf größere Ähnlichkeit hin.
- Manhattan-Distanz (L1-Norm): Misst den Abstand zwischen zwei Punkten, indem die absolute Differenz ihrer entsprechenden Komponenten summiert wird.
- Minkowski-Distanz: Eine Verallgemeinerung der euklidischen und der Manhattan-Distanz.
Dies sind die gebräuchlichsten Distanz- oder Ähnlichkeitsmetriken, die in Algorithmen des maschinellen Lernens verwendet werden.
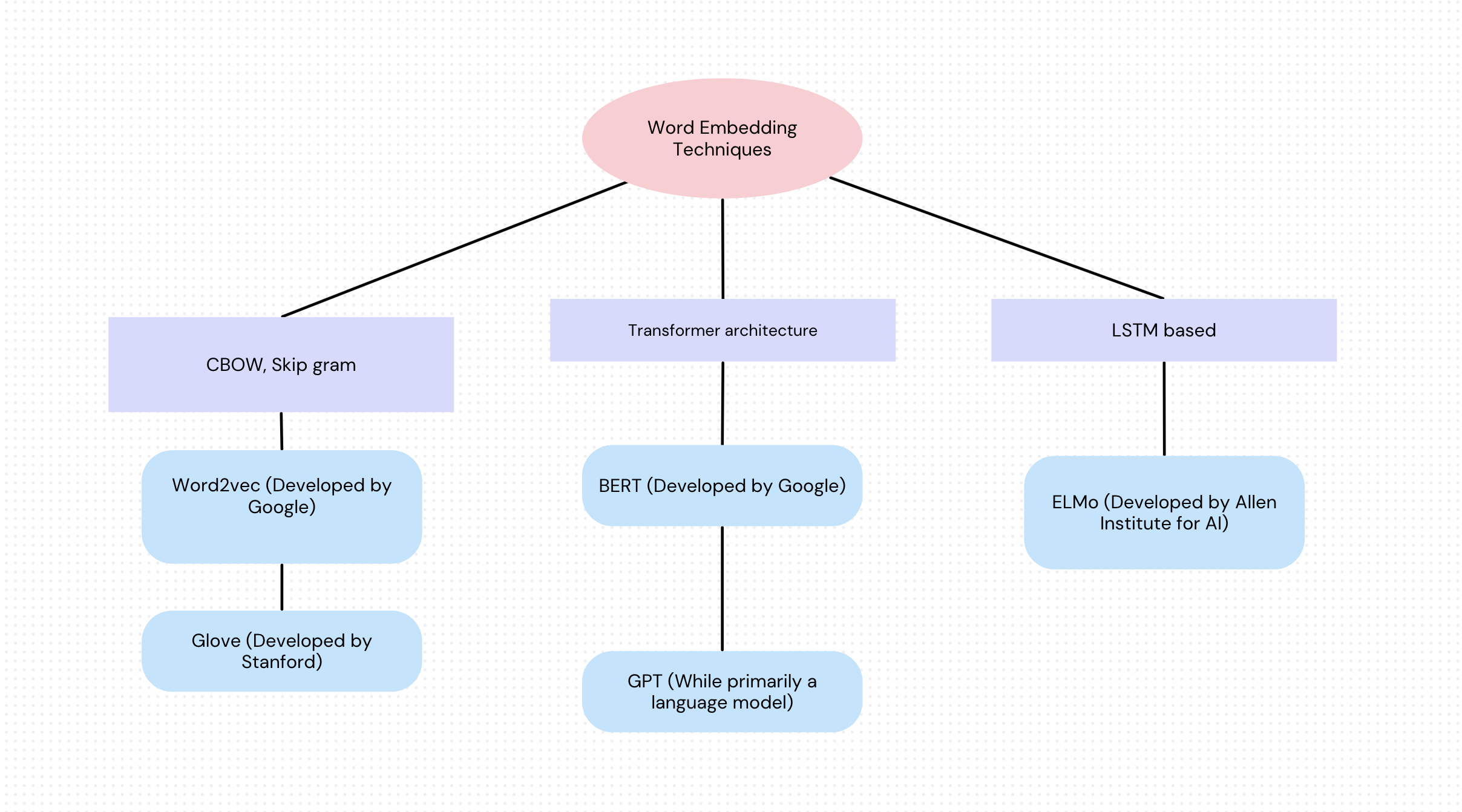
Beliebte Vektordatenbanken
Hier sind einige der beliebtesten Vektordatenbanken, die heute weit verbreitet sind:
- Pinecone: Eine vollständig verwaltete Vektordatenbank, die für ihre Benutzerfreundlichkeit, Skalierbarkeit und schnelle, approximative Nächste-Nachbarn-Suche (ANN) bekannt ist. Pinecone zeichnet sich durch seine Integration in Machine-Learning-Workflows aus, insbesondere in semantische Such- und Empfehlungssysteme.
- FAISS (Facebook AI Similarity Search): FAISS wurde von Meta (ehemals Facebook) entwickelt und ist eine hochoptimierte Bibliothek für die Ähnlichkeitssuche und das Clustering dichter Vektoren. Sie ist Open Source, effizient und wird häufig in der akademischen und industriellen Forschung eingesetzt, insbesondere für groß angelegte Ähnlichkeitssuchen.
- Weaviate: Eine Open-Source-Vektordatenbank für die Cloud, die Vektor- und Hybrid-Suchfunktionen unterstützt. Weaviate ist bekannt für seine Integration mit Modellen von Hugging Face, OpenAI und Cohere und eignet sich daher hervorragend für semantische Suche und NLP-Anwendungen.
- Milvus: Eine Open-Source-Vektordatenbank mit hoher Skalierbarkeit, optimiert für umfangreiche KI-Anwendungen. Milvus unterstützt verschiedene Indexierungsmethoden und verfügt über ein breites Integrations-Ökosystem, wodurch es sich besonders für Echtzeit-Empfehlungssysteme und Aufgaben im Bereich Computer Vision eignet.
- Qdrant: Eine leistungsstarke Vektordatenbank mit Fokus auf Benutzerfreundlichkeit. Qdrant bietet Funktionen wie Echtzeit-Indexierung und verteilte Unterstützung. Sie ist für die Verarbeitung hochdimensionaler Daten konzipiert und eignet sich daher ideal für Empfehlungssysteme, Personalisierung und NLP-Aufgaben.
- Chroma: Als Open-Source-Software wurde Chroma speziell für LLM-Anwendungen entwickelt und bietet einen Einbettungsspeicher für LLMs sowie Unterstützung für ähnliche Suchvorgänge. Es wird häufig zusammen mit LangChain für dialogbasierte KI und andere LLM-basierte Anwendungen eingesetzt.
Dinge, die Sie verwenden sollten
Schauen wir uns nun einige Anwendungsfälle von Vektordatenbanken an.
- Vektordatenbanken eignen sich für Chatbots, die Langzeitspeicher benötigen. Mit Langchain lässt sich dies einfach implementieren und ermöglicht dem Chatbot, den Gesprächsverlauf abzufragen und in einer Vektordatenbank zu speichern. Während der Interaktion ruft der Bot kontextbezogene Ausschnitte aus früheren Gesprächen ab und verbessert so das Nutzererlebnis.
- Vektordatenbanken können für die semantische Suche und den Informationsabruf genutzt werden, indem sie semantisch ähnliche Dokumente oder Texte abrufen. Sie finden Inhalte, die textuell mit der Suchanfrage verwandt sind, anstatt exakte Übereinstimmungen mit Schlüsselwörtern zu finden.
- Plattformen wie E-Commerce, Musikstreaming oder soziale Medien nutzen Vektordatenbanken, um Empfehlungen zu generieren. Indem die Artikel und Präferenzen des Nutzers als Vektoren dargestellt werden, kann das System Produkte, Lieder oder Inhalte finden, die den bisherigen Interessen des Nutzers ähneln.
- Bild- und Videoplattformen nutzen Vektordatenbanken, um visuell ähnliche Inhalte zu finden.
Herausforderungen für Vektordatenbanken
- Skalierbarkeit und Leistung: Angesichts stetig wachsender Datenmengen kann es eine Herausforderung sein, Vektordatenbanken schnell und skalierbar zu halten und gleichzeitig die Genauigkeit zu gewährleisten. Auch die Balance zwischen Geschwindigkeit und Genauigkeit kann bei der Generierung präziser Suchergebnisse problematisch sein.
- Kosten- und Ressourcenintensität: Hochdimensionale Vektoroperationen können ressourcenintensiv sein und erfordern leistungsstarke Hardware sowie eine effiziente Indizierung, was die Speicher- und Rechenkosten erhöhen kann.
- Kompromiss zwischen Präzision und Approximation: Vektordatenbanken verwenden Nearest-Neighbor-Verfahren (ANN), um schnellere Suchvorgänge zu erreichen, was jedoch zu ungefähren statt exakten Übereinstimmungen führen kann.
- Integration mit traditionellen Systemen: Die Integration von Vektordatenbanken in bestehende traditionelle Datenbanken kann eine Herausforderung darstellen, da sie unterschiedliche Datenstrukturen und Abrufmethoden verwenden.
Ergebnis
Vektordatenbanken revolutionieren die Speicherung und Suche komplexer Daten wie Bilder, Audio, Text und Empfehlungen durch ähnlichkeitbasierte Suchen in hochdimensionalen Räumen. Im Gegensatz zu herkömmlichen Datenbanken, die exakte Übereinstimmungen erfordern, nutzen Vektordatenbanken Einbettungen und Ähnlichkeitswerte, um «ausreichend ähnliche» Ergebnisse zu finden. Dadurch eignen sie sich hervorragend für Anwendungen wie personalisierte Empfehlungen, semantische Suche und Anomalieerkennung.









