









Einführung
Beim Entwurf einer Datenbank kann es vorkommen, dass Sie die in bestimmten Spalten zulässigen Daten einschränken möchten. Wenn Sie beispielsweise eine Tabelle mit Informationen über Wolkenkratzer erstellen, möchten Sie möglicherweise, dass die Spalte für die Höhe jedes Gebäudes keine negativen Werte zulässt.
Relationale Datenbankmanagementsysteme (RDBMS) ermöglichen es, mithilfe von Einschränkungen zu steuern, welche Daten einer Tabelle hinzugefügt werden. Eine Einschränkung ist eine spezielle Regel, die für eine oder mehrere Spalten – oder die gesamte Tabelle – gilt und die Änderungen, die an den Tabellendaten vorgenommen werden können, durch eine Anweisung begrenzt. EINFÜGEN, AKTUALISIEREN, oder LÖSCHEN Es schränkt ein.
Dieser Artikel untersucht detailliert, was Constraints sind und wie sie in relationalen Datenbankmanagementsystemen (RDBMS) verwendet werden. Er geht außerdem auf die fünf im SQL-Standard definierten Constraints ein und erläutert die entsprechenden Funktionen.
Welche Einschränkungen gibt es?
In SQL ist eine Einschränkung jede Regel, die auf eine Spalte oder Tabelle angewendet wird und die die einfügbaren Daten begrenzt. Immer wenn Sie versuchen, eine Operation durchzuführen, die die in der Tabelle gespeicherten Daten ändert – wie beispielsweise eine INSERT-, UPDATE- oder DELETE-Anweisung –, prüft das relationale Datenbankmanagementsystem (RDBMS), ob diese Daten gegen die bestehenden Einschränkungen verstoßen, und gibt gegebenenfalls einen Fehler zurück.
Datenbankadministratoren verwenden häufig Einschränkungen, um sicherzustellen, dass die Datenbank definierten Geschäftsregeln entspricht. Im Kontext einer Datenbank ist eine Geschäftsregel jede Richtlinie oder Vorgehensweise, die ein Unternehmen oder eine andere Organisation befolgt und deren Daten entsprechen müssen. Angenommen, Sie erstellen eine Datenbank, die den Lagerbestand eines Kundengeschäfts erfasst. Wenn der Kunde vorschreibt, dass jeder Produktdatensatz eine eindeutige Identifikationsnummer haben muss, können Sie eine Spalte mit einer UNIQUE-Einschränkung erstellen, die sicherstellt, dass keine zwei Einträge in dieser Spalte identisch sind.
Einschränkungen sind auch für die Wahrung der Datenintegrität nützlich. Datenintegrität ist ein weit gefasster Begriff, der häufig verwendet wird, um die allgemeine Genauigkeit, Konsistenz und Plausibilität der in einer Datenbank gespeicherten Daten, basierend auf ihren spezifischen Anwendungsfällen, zu beschreiben. Tabellen in einer Datenbank sind oft miteinander verknüpft, und Spalten einer Tabelle hängen von Werten in einer anderen Tabelle ab. Da die Dateneingabe häufig fehleranfällig ist, sind Einschränkungen in solchen Fällen hilfreich, da sie sicherstellen können, dass fehlerhaft eingegebene Daten keine solchen Beziehungen beeinträchtigen und somit die Integrität der Datenbankdaten gefährden.
Stellen Sie sich vor, Sie entwerfen eine Datenbank mit zwei Tabellen: eine für die aktuellen Schüler einer Schule und eine für die Mitglieder des Basketballteams dieser Schule. Sie können eine Fremdschlüsselbeziehung zwischen einer Spalte der Basketballteam-Tabelle und einer Spalte der Schultabelle herstellen. Dadurch wird eine Beziehung zwischen den beiden Tabellen geschaffen, indem jeder Eintrag in der Teamtabelle auf einen Eintrag in der Schülertabelle verweist.
Benutzer definieren Einschränkungen beim Erstellen einer Tabelle oder können sie später mit der ALTER TABLE-Anweisung hinzufügen, sofern diese nicht mit bereits vorhandenen Daten in Konflikt stehen. Beim Erstellen einer Einschränkung vergibt das Datenbanksystem automatisch einen Namen. In den meisten SQL-Implementierungen kann jedoch für jede Einschränkung ein benutzerdefinierter Name vergeben werden. Diese Namen werden verwendet, um in ALTER TABLE-Anweisungen auf die Einschränkungen zu verweisen, wenn diese geändert oder gelöscht werden.
Der SQL-Standard definiert formal nur fünf Einschränkungen:
- Primärschlüssel
- Fremdschlüssel
- Einzigartig
- Rezension
- Es ist nicht leer.
Nachdem Sie nun ein allgemeines Verständnis dafür haben, wie Einschränkungen verwendet werden, wollen wir uns jede dieser fünf Einschränkungen genauer ansehen.
Primärschlüssel
Die PRIMARY KEY-Einschränkung erfordert, dass jeder Eintrag in einer bestimmten Spalte eindeutig und nicht NULL ist, sodass Sie diese Spalte verwenden können, um jede einzelne Zeile in der Tabelle zu identifizieren.
Im relationalen Modell ist ein Schlüssel eine Spalte oder eine Gruppe von Spalten in einer Tabelle, deren Werte garantiert eindeutig sind und keine NULL-Werte enthalten. Ein Primärschlüssel ist ein spezieller Schlüssel, dessen Werte zur Identifizierung einzelner Zeilen in einer Tabelle verwendet werden. Die Spalte oder Spalten, die den Primärschlüssel bilden, können zur Identifizierung der Tabelle im Rest der Datenbank verwendet werden.
Dies ist einer der wichtigsten Aspekte relationaler Datenbanken: Dank eines Primärschlüssels müssen Benutzer nicht wissen, dass ihre Daten physisch auf einem Rechner gespeichert sind. Ihr Datenbankmanagementsystem (DBMS) kann jeden Datensatz verfolgen und bei Bedarf abrufen. Das bedeutet wiederum, dass die Datensätze keine festgelegte logische Reihenfolge haben und Benutzer ihre Daten in beliebiger Reihenfolge oder mit beliebigen Filtern abrufen können.
In SQL können Sie einen Primärschlüssel mit einer PRIMARY KEY-Einschränkung erstellen, die im Wesentlichen eine Kombination aus UNIQUE- und NOT NULL-Einschränkungen darstellt. Sobald der Primärschlüssel definiert ist, erstellt das DBMS automatisch einen zugehörigen Index. Ein Index ist eine Datenbankstruktur, die den schnelleren Datenabruf aus einer Tabelle ermöglicht. Wie bei einem Index in einem Lehrbuch müssen Abfragen nur die Einträge der indizierten Spalte untersuchen, um die zugehörigen Werte zu finden. Dadurch dient der Primärschlüssel als eindeutiger Bezeichner für jede Zeile in der Tabelle.
Eine Tabelle kann nur einen Primärschlüssel haben, aber wie reguläre Schlüssel kann auch ein Primärschlüssel aus mehreren Spalten bestehen. Ein wesentliches Merkmal von Primärschlüsseln ist jedoch, dass sie nur die minimal notwendigen Attribute verwenden, um jede Zeile in einer Tabelle eindeutig zu identifizieren. Um dies zu veranschaulichen, stellen Sie sich eine Tabelle vor, die Informationen über Schüler einer Schule anhand der folgenden drei Spalten speichert:
studentIDWird verwendet, um die eindeutige Identifikationsnummer jedes Schülers zu speichern.VornameWird verwendet, um den Vornamen jedes Schülers zu speichernNachnameWird verwendet, um den Nachnamen jedes Schülers zu speichern.
Es ist möglich, dass mehrere Schüler einer Schule denselben Vornamen haben. In diesem Fall wäre die Spalte „Vorname“ als Primärschlüssel ungeeignet. Dasselbe gilt für die Spalte „Nachname“. Ein Primärschlüssel, der sowohl die Spalte „Vorname“ als auch die Spalte „Nachname“ umfasst, wäre zwar möglich, aber es besteht weiterhin die Möglichkeit, dass zwei Schüler denselben Vor- und Nachnamen haben.
Ein Primärschlüssel bestehend aus der Studenten-ID und den Spalten Vorname oder Nachname wäre zwar möglich, da die ID-Nummer jedes Studenten jedoch bereits eindeutig ist, wäre die Einbeziehung der Namensspalten in den Primärschlüssel redundant. Daher ist in diesem Fall die Spalte Studenten-ID allein die minimale Menge an Attributen, die jede Zeile eindeutig identifizieren kann und somit eine gute Wahl für den Primärschlüssel der Tabelle darstellt.
Besteht ein Schlüssel aus beobachtbaren, nutzbaren Daten (d. h. Daten, die reale Entitäten, Ereignisse oder Eigenschaften repräsentieren), spricht man von einem natürlichen Schlüssel. Wird der Schlüssel intern generiert und repräsentiert er nichts außerhalb der Datenbank, handelt es sich um einen künstlichen oder Ersatzschlüssel. Manche Datenbanksysteme raten von der Verwendung natürlicher Schlüssel ab, da sich selbst scheinbar feste Datenpunkte unvorhersehbar ändern können.
Fremdschlüssel
Die FOREIGN KEY-Einschränkung erfordert, dass jeder Eintrag in einer bestimmten Spalte bereits in einer bestimmten Spalte einer anderen Tabelle vorhanden sein muss.
Wenn Sie zwei Tabellen miteinander verknüpfen möchten, können Sie dies beispielsweise durch die Definition eines Fremdschlüssels mit einer FOREIGN KEY-Einschränkung erreichen. Ein Fremdschlüssel ist eine Spalte in einer Tabelle (der “Kindtabelle”), deren Werte aus einem Schlüssel in einer anderen Tabelle (der “Elterntabelle”) stammen. Dies ist eine Möglichkeit, eine Beziehung zwischen zwei Tabellen auszudrücken: Eine FOREIGN KEY-Einschränkung erfordert, dass die Werte in der Spalte, auf die sie sich bezieht, auch in der Spalte vorhanden sein müssen, auf die sie verweist.
Das folgende Diagramm veranschaulicht eine solche Beziehung zwischen zwei Tabellen: Eine dient der Erfassung von Informationen über die Mitarbeiter eines Unternehmens, die andere der Verfolgung der Umsätze. In diesem Beispiel wird der Primärschlüssel der Tabelle MITARBEITER durch den Fremdschlüssel der Tabelle UMSATZ referenziert.
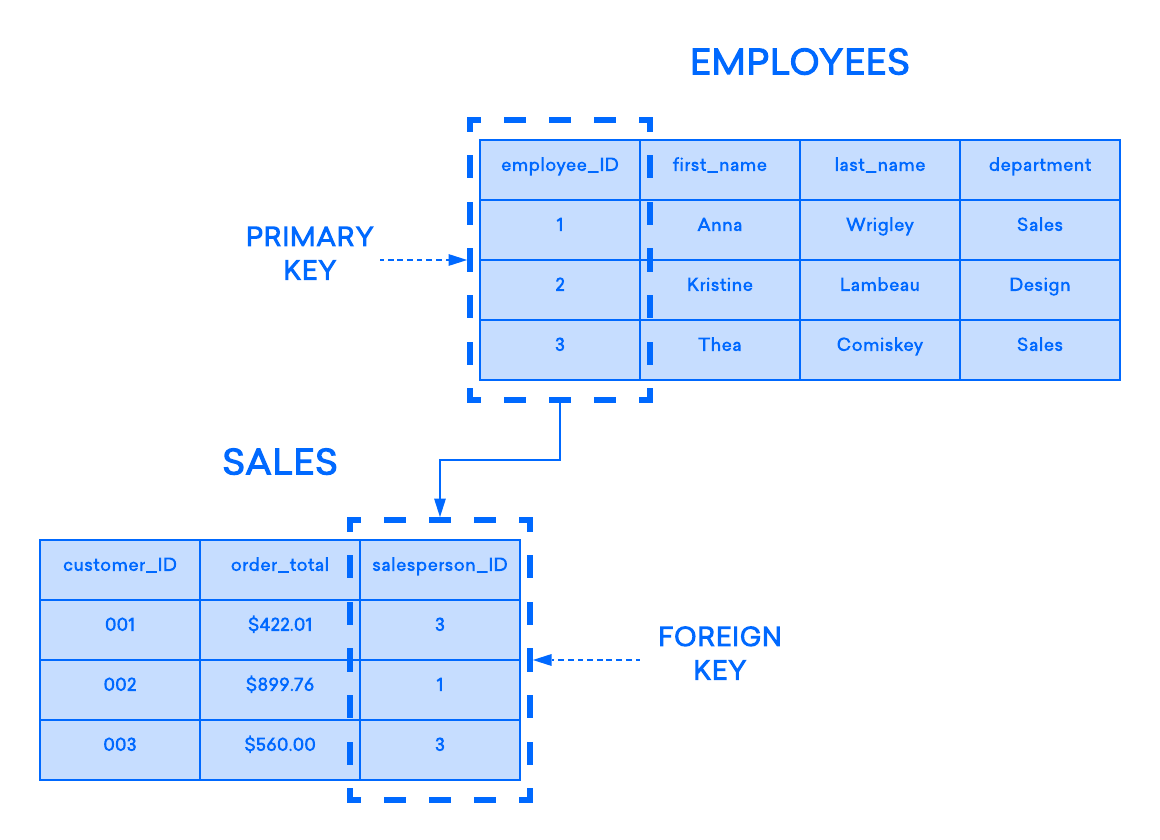
Wenn Sie versuchen, einen Datensatz in eine untergeordnete Tabelle einzufügen, und der in der Fremdschlüsselspalte eingegebene Wert nicht im Primärschlüssel der übergeordneten Tabelle vorhanden ist, ist die Einfügeanweisung ungültig. Dies trägt zur Wahrung der Integrität auf Beziehungsebene bei, da Zeilen aus beiden Tabellen immer korrekt miteinander verknüpft sind.
In den meisten Fällen ist der Fremdschlüssel einer Tabelle der Primärschlüssel der übergeordneten Tabelle, dies ist jedoch nicht immer der Fall. In den meisten relationalen Datenbankmanagementsystemen (RDBMS) kann jede Spalte der übergeordneten Tabelle, die eine UNIQUE- oder PRIMARY KEY-Einschränkung aufweist, über den Fremdschlüssel der untergeordneten Tabelle referenziert werden.
Einzigartig
Die UNIQUE-Beschränkung verhindert, dass doppelte Werte in die angegebene Spalte eingefügt werden.
Wie der Name schon sagt, erfordert eine UNIQUE-Einschränkung, dass jeder Eintrag in einer bestimmten Spalte ein eindeutiger Wert ist. Jeder Versuch, einen Wert hinzuzufügen, der bereits in der Spalte vorhanden ist, führt zu einem Fehler.
UNIQUE-Constraints sind nützlich, um Eins-zu-Eins-Beziehungen zwischen Tabellen zu erzwingen. Wie bereits erwähnt, kann man eine Beziehung zwischen zwei Tabellen mit einem Fremdschlüssel herstellen, aber es gibt verschiedene Arten von Beziehungen, die zwischen Tabellen bestehen können:
یک به یکEins zu vielenBei einer Viele-zu-Beliebig-Beziehung kann eine Zeile in der übergeordneten Tabelle mit mehreren Zeilen in der untergeordneten Tabelle verknüpft sein, aber jede Zeile in der untergeordneten Tabelle kann nur mit einer Zeile in der übergeordneten Tabelle verknüpft sein.Wie viele?Wenn Zeilen in der Elterntabelle mit mehreren Zeilen in der Kindtabelle verknüpft werden können und umgekehrt, spricht man von einer Viele-zu-Viele-Beziehung zwischen den beiden Tabellen.
Durch Hinzufügen einer UNIQUE-Beschränkung zu einer Spalte, auf die bereits eine FOREIGN KEY-Beschränkung angewendet wurde, kann sichergestellt werden, dass jeder Eintrag in der übergeordneten Tabelle nur einmal in der untergeordneten Tabelle vorkommt. Dadurch wird eine Eins-zu-Eins-Beziehung zwischen den beiden Tabellen hergestellt.
Beachten Sie, dass Sie UNIQUE-Constraints sowohl auf Tabellen- als auch auf Spaltenebene definieren können. Bei einer Definition auf Tabellenebene kann ein UNIQUE-Constraint auf mehrere Spalten angewendet werden. In diesem Fall können die Werte in den einzelnen Spalten des Constraints zwar doppelt vorkommen, jedoch muss jede Zeile eine eindeutige Kombination von Werten in den eingeschränkten Spalten aufweisen.
Rezension
Eine CHECK-Bedingung definiert eine Bedingung für eine Spalte, ein sogenanntes Prädikat, die jeder in diese Spalte eingegebene Wert erfüllen muss.
CHECK-Constraint-Prädikate werden als Ausdruck geschrieben, der zu TRUE, FALSE oder möglicherweise zu „unbekannt“ ausgewertet werden kann. Wenn Sie versuchen, einen Wert in einen CHECK-Constraint einzugeben und dieser Wert dazu führt, dass die Anweisung zu TRUE oder „unbekannt“ ausgewertet wird (was bei NULL-Werten der Fall ist), ist die Operation erfolgreich. Ergibt die Auswertung des Ausdrucks jedoch FALSE, schlägt die Operation fehl.
CHECK-Prädikate verwenden häufig mathematische Vergleichsoperatoren (wie <, >, <=, OR >=), um den zulässigen Datenbereich in einer bestimmten Spalte einzuschränken. Ein gängiger Anwendungsfall für CHECK-Bedingungen ist beispielsweise, negative Werte in bestimmten Spalten zu verhindern, wenn diese keinen Sinn ergeben, wie im folgenden Beispiel.
Diese CREATE TABLE-Anweisung erstellt eine Tabelle namens productInfo mit Spalten für Name, ID-Nummer und Preis jedes Produkts. Da ein Produkt keinen negativen Preis haben kann, wendet diese Anweisung eine CHECK-Bedingung auf die Preisspalte an, um sicherzustellen, dass sie nur positive Werte enthält.
CREATE TABLE productInfo (
productID int,
name varchar(30),
price decimal(4,2)
CHECK (price > 0)
);In CHECK-Prädikaten dürfen keine mathematischen Vergleichsoperatoren verwendet werden. Typischerweise können Sie in einem CHECK-Prädikat jeden SQL-Operator verwenden, der zu „true“, „false“ oder „unbekannt“ ausgewertet werden kann, einschließlich LIKE, BETWEEN, IS NOT NULL usw. Einige, aber nicht alle SQL-Implementierungen erlauben sogar die Einbindung einer Unterabfrage in ein CHECK-Prädikat. Beachten Sie jedoch, dass die meisten Implementierungen keine Referenzierung einer anderen Tabelle in einer Anweisung zulassen.
Es ist nicht leer.
Die NOT NULL-Bedingung verhindert, dass NULL-Werte in die angegebene Spalte eingefügt werden.
In den meisten SQL-Implementierungen wird beim Einfügen einer Datenzeile ohne Angabe eines Werts für eine bestimmte Spalte der fehlende Wert standardmäßig als NULL dargestellt. In SQL ist NULL ein spezielles Schlüsselwort, das einen unbekannten, fehlenden oder nicht spezifizierten Wert repräsentiert. NULL ist jedoch selbst kein Wert, sondern beschreibt den Zustand eines unbekannten Werts.
Um diesen Unterschied zu verdeutlichen, stellen Sie sich eine Tabelle vor, die zur Verwaltung von Kunden in einer Künstleragentur verwendet wird und Spalten für Vor- und Nachnamen jedes Kunden enthält. Verwendet ein Kunde nur einen Namen – wie beispielsweise “Cher”, “Usher” oder “Beyoncé” –, trägt der Datenbankadministrator möglicherweise nur einen Namen in die Spalte “Vorname” ein. Dies würde dazu führen, dass das Datenbanksystem (DBMS) in der Spalte „Nachname“ den Wert NULL einfügt. Die Datenbank interpretiert den Nachnamen eines Kunden jedoch nicht als buchstäblich „null“. Es bedeutet lediglich, dass der Wert der Spalte „Nachname“ für diese Zeile unbekannt ist oder dass das Feld für diesen Datensatz nicht relevant ist.
Wie der Name schon sagt, verhindert die NOT NULL-Bedingung, dass ein Wert in der angegebenen Spalte NULL ist. Das bedeutet, dass Sie für jede Spalte mit einer NOT NULL-Bedingung beim Einfügen einer neuen Zeile einen Wert angeben müssen. Andernfalls schlägt der INSERT-Vorgang fehl.
Ergebnis
Einschränkungen sind ein unverzichtbares Werkzeug für alle, die eine Datenbank mit hoher Datenintegrität und -sicherheit entwerfen möchten. Durch die Beschränkung der in eine Spalte eingegebenen Daten können Sie sicherstellen, dass die Beziehungen zwischen Tabellen korrekt gewahrt bleiben und die Datenbank den Geschäftsregeln entspricht, die ihren Zweck definieren.









