









Einführung
Herkömmliche Methoden zur Datenverarbeitung und zum Datenempfang (wie Stapelverarbeitung und Polling) sind im Kontext von Microservices, wie sie in modernen Anwendungen eingesetzt werden, ineffizient. Diese Methoden verarbeiten große Datenmengen, was das Endergebnis verzögert und die Ansammlung erheblicher Datenmengen vor der eigentlichen Verarbeitung erfordert. Sie führen zu zusätzlicher Komplexität durch die notwendige Synchronisierung der Worker und können dazu führen, dass einige trotz Ressourcennutzung unterausgelastet bleiben. Im Gegensatz dazu ermöglicht Cloud Computing dank der schnellen Skalierbarkeit lokaler Ressourcen die Verarbeitung eingehender Daten in Echtzeit durch die parallele Zuweisung an mehrere Worker.
Event-Streaming ist ein Ansatz zur flexiblen Erfassung und Weiterleitung eingehender Ereignisse zur Verarbeitung bei gleichzeitig kontinuierlichem Datenfluss zwischen verschiedenen Systemen. Die Planung eingehender Daten zur sofortigen Verarbeitung gewährleistet maximale Ressourcennutzung und Echtzeit-Reaktionsfähigkeit. Event-Streaming trennt Produzenten und Konsumenten, sodass je nach aktueller Auslastung eine ungleichmäßige Anzahl beider Komponenten zur Verfügung steht. Dies ermöglicht unmittelbare Reaktionen auf dynamische Bedingungen in der Praxis.
Eine solche Reaktionsfähigkeit ist insbesondere in Bereichen wie Finanzhandel, Zahlungsüberwachung oder Verkehrsüberwachung von großer Bedeutung. Uber nutzt beispielsweise Event-Streaming, um Hunderte von Microservices zu verbinden, Ereignisdaten von Fahrgast- an Fahrer-Anwendungen in Echtzeit zu senden und für spätere Analysen zu archivieren.
Beim Event-Broadcasting wartet nicht mehr wie üblich ein Worker in regelmäßigen Abständen auf einen Datenstapel, sondern der Event-Broker benachrichtigt den Konsumenten (typischerweise einen Microservice) sofort nach dem Eintreten eines Ereignisses und stellt ihm die Ereignisdaten bereit. Der Event-Broker übernimmt das Routing, den Empfang und die Zustellung der Ereignisse. Er gewährleistet zudem Fehlertoleranz für den Fall, dass ein Worker ausfällt oder die Verarbeitung eines Ereignisses verweigert.
In diesem Konzeptpapier untersuchen wir den Ansatz des Event-Streamings und seine Vorteile. Wir stellen außerdem Apache Kafka, einen Open-Source-Event-Broker, vor und analysieren seine Rolle in diesem Ansatz.
Ereignisablaufarchitektur
Der Ereignisablauf ist im Kern eine Implementierung des Pub/Sub-Architekturmusters. Im Allgemeinen umfasst das Pub/Sub-Muster Folgendes:
- Die Themen, an die sich Nachrichten (einschließlich aller Daten, die Sie übermitteln möchten) richten.
- Verlage, die Botschaften produzieren
- Abonnenten, die Nachrichten erhalten und darauf reagieren
- Ein Message Broker, der Nachrichten von Herausgebern entgegennimmt und sie auf dem effizientesten Weg an Abonnenten zustellt.
Ein Thema ist vergleichbar mit einer Kategorie, der eine Nachricht zugeordnet ist. Themen speichern die Nachrichtenfolge dauerhaft und stellen sicher, dass neue Nachrichten immer am Ende der Folge hinzugefügt werden. Sobald eine Nachricht einem Thema hinzugefügt wurde, kann sie später nicht mehr geändert werden.
Bei der Event-Übertragung ist das Grundprinzip ähnlich, wenn auch spezialisierter:
- Ereignisse und zugehörige Metadaten werden als Nachrichten versendet.
- Ereignisse innerhalb eines Themas werden üblicherweise nach Ankunftszeit sortiert.
- Abonnenten (auch Konsumenten genannt) können Ereignisse von jedem beliebigen Zeitpunkt im Thread bis zum aktuellen Moment übertragen.
- Im Gegensatz zum eigentlichen Pub/Subreddit können Veranstaltungen zu einem Thema für einen bestimmten Zeitraum oder auf unbestimmte Zeit (als Archiv) aufbewahrt werden.
Der Ereignisablauf legt keine Beschränkungen fest und trifft keine Annahmen über die Art eines Ereignisses. Für den zugrunde liegenden Broker bedeutet ein Ereignis lediglich, dass ein Produzent ihn darüber informiert hat, dass etwas passiert ist. Was genau passiert ist, müssen Sie in Ihrer Implementierung definieren und interpretieren. Daher werden Ereignisse aus Sicht des Brokers synonym als Nachrichten oder Datensätze bezeichnet.
Zur Veranschaulichung folgt hier ein detailliertes Diagramm der Kafka-Event-Stream-Architektur aus der Confluent-Dokumentation:
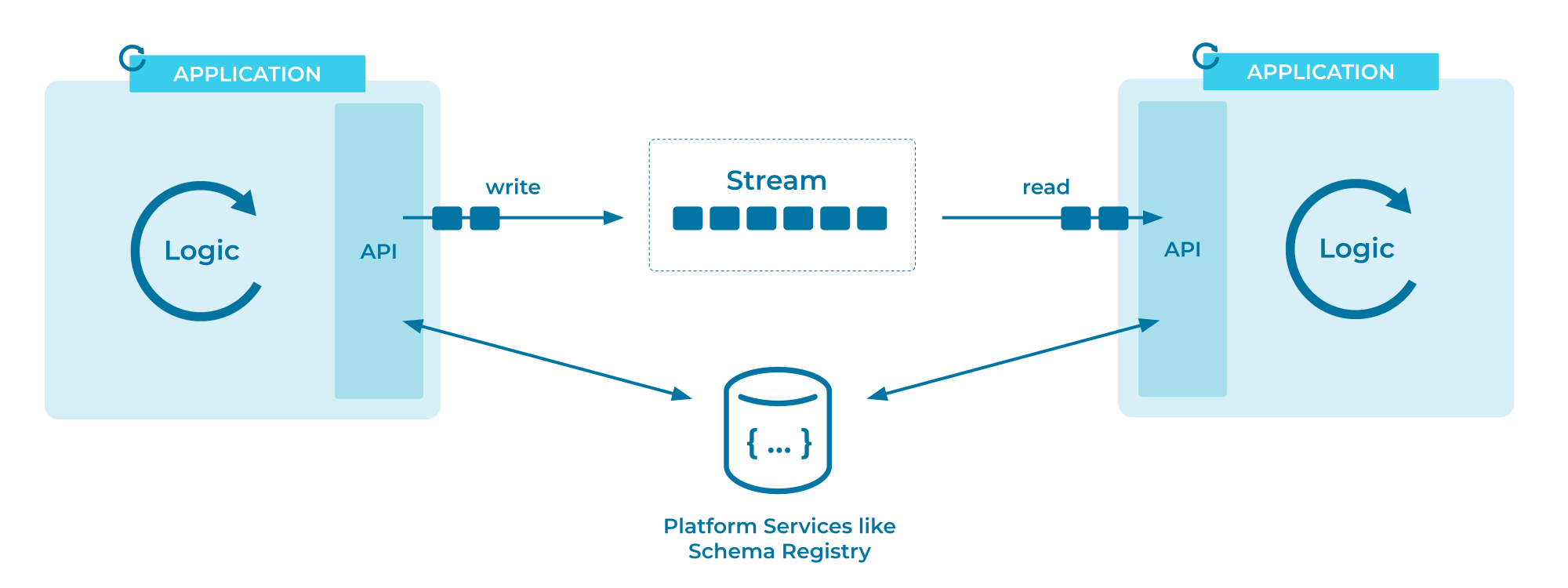
Es gibt zwei Modelle, wie Konsumenten Daten von einem Broker abrufen können: Push und Pull. Beim Push sendet der Event-Broker die Daten an einen zunächst verfügbaren Konsumenten, während beim Pull der Konsument nachfolgende verfügbare Datensätze vom Broker anfordert. Dieser Unterschied mag unproblematisch erscheinen, in der Praxis wird jedoch das Pull-Verfahren bevorzugt.
Einer der Hauptgründe, warum Push-Verfahren nicht weit verbreitet sind, ist, dass der Broker nicht sicher sein kann, ob der Konsument tatsächlich auf das Ereignis reagieren kann. Daher kann es passieren, dass das Ereignis unnötigerweise mehrfach gesendet wird, obwohl es trotzdem im Topic gespeichert werden muss. Der Broker sollte außerdem die Bündelung von Ereignissen für einen höheren Durchsatz in Betracht ziehen, was dem Prinzip der möglichst schnellen Übertragung widerspricht.
Wenn der Client Daten erst dann abruft, wenn sie zur Verarbeitung bereit sind, wird unnötiger Netzwerkverkehr reduziert und die Zuverlässigkeit erhöht. Dadurch wird sichergestellt, dass er Daten nur dann empfängt, wenn er sie verarbeiten kann. Die Verarbeitungszeit hängt von der Geschäftslogik ab und beeinflusst die Anzahl der Worker. In beiden Fällen muss der Broker speichern, welche Ereignisse der Client bestätigt hat.
Nachdem Sie nun wissen, was Event-Streaming ist und auf welcher Architektur es basiert, erfahren Sie mehr über die Vorteile dieses dynamischen Ansatzes.
Vorteile des Event-Streamings
Die wichtigsten Vorteile der Event-Übertragung sind:
- Konsistenz: Der Event-Broker stellt sicher, dass Ereignisse korrekt an alle interessierten Konsumenten gesendet werden.
- Fehlertoleranz: Wenn ein Konsument ein Ereignis nicht annehmen kann, kann es an eine andere Stelle umgeleitet werden, um sicherzustellen, dass kein Ereignis unbehandelt bleibt.
- Wiederverwendbarkeit: In einem Thread gespeicherte Ereignisse sind unveränderlich. Sie können vollständig oder ab einem bestimmten Zeitpunkt erneut abgespielt werden, sodass Sie Ereignisse erneut verarbeiten können, wenn sich Ihre Geschäftslogik ändert.
- Skalierbarkeit: Produzenten und Konsumenten sind separate Einheiten und müssen nicht aufeinander warten, was bedeutet, dass sie je nach Nachfrage dynamisch skaliert werden können.
- Benutzerfreundlichkeit: Der Event-Broker übernimmt das Event-Routing und die Speicherung, abstrahiert komplexe Logik und ermöglicht es Ihnen, sich auf die Daten selbst zu konzentrieren.
Jedes Ereignis sollte nur die notwendigen Details zum jeweiligen Vorkommnis enthalten. Ereignisbroker arbeiten im Allgemeinen sehr effizient, und obwohl empfohlen wird, Ereignisse nach dem Eintragen in ein Thema nicht ablaufen zu lassen, sollten sie nicht wie eine herkömmliche Datenbank behandelt werden.
Es wäre beispielsweise hilfreich, die Änderung der Aufrufzahlen eines Artikels anzuzeigen, ohne dabei den gesamten Artikel samt Metadaten zu speichern. Stattdessen könnte das Ereignis einen Verweis auf die Artikel-ID in einer externen Datenbank enthalten. So lässt sich der Verlauf nachverfolgen, ohne unnötige Informationen einzubinden und den Thread zu überladen.
Nun lernen Sie Apache Kafka und andere gängige Event-Broker kennen, wie sie sich vergleichen lassen und wie sie in das Event-Streaming-Ökosystem passen.
Die Rolle von Apache Kafka
Apache Kafka ist ein Open-Source-Event-Broker, der in Java geschrieben und von der Apache Software Foundation betreut wird. Er besteht aus verteilten Servern und Clients, die über ein speziell angepasstes TCP-Netzwerkprotokoll kommunizieren, um maximale Leistung zu erzielen. Kafka ist hochzuverlässig und skalierbar und kann auf virtuellen Maschinen, Bare-Metal-Hardware, in Containern und anderen Cloud-Umgebungen ausgeführt werden.
Um eine hohe Zuverlässigkeit zu gewährleisten, wird Kafka als Cluster aus einem oder mehreren Servern bereitgestellt. Dieser Cluster kann sich über mehrere Cloud-Regionen und Rechenzentren erstrecken. Kafka-Cluster sind fehlertolerant. Das bedeutet, dass im Falle eines Serverausfalls oder einer Verbindungsunterbrechung die verbleibenden Server neu gruppiert werden, um eine hohe Verfügbarkeit des Betriebs ohne externe Auswirkungen und Datenverlust sicherzustellen.
Für maximale Effizienz erfüllen nicht alle Kafka-Server dieselbe Rolle. Einige Server sind gruppiert und fungieren als Vermittler, die eine Speicherschicht für Daten bilden. Andere lassen sich in bestehende Systeme integrieren und erfassen Daten als Ereignisströme mithilfe von Kafka Connect, einem Tool zum zuverlässigen Streaming von Daten aus bestehenden Systemen (wie relationalen Datenbanken) zu Kafka.
Kafka betrachtet Produzenten und Konsumenten als seine Clients. Wie bereits erwähnt, schreiben Produzenten Ereignisse an einen Kafka-Broker, der diese an interessierte Konsumenten weiterleitet. In der Standardkonfiguration garantiert Kafka, dass ein Ereignis letztendlich nur einmal von einem der Konsumenten verarbeitet wird.
In Kafka werden Topics partitioniert. Das bedeutet, dass ein Topic auf verschiedene Kafka-Broker verteilt wird, was Skalierbarkeit gewährleistet. Kafka garantiert außerdem, dass Ereignisse, die in einer bestimmten Kombination von Topics und ihren Partitionen gespeichert sind, immer in der Reihenfolge gelesen werden können, in der sie geschrieben wurden.
Beachten Sie, dass die bloße Partitionierung eines Themas keine Redundanz garantiert. Diese kann nur durch Replikation über Regionen und Rechenzentren hinweg erreicht werden. In einer Produktionsumgebung sind üblicherweise mindestens drei Kopien eines Clusters vorhanden, sodass stets drei Kombinationen aus Thema und Partition verfügbar sind.
Kafka-Integration
Wie bereits erwähnt, lassen sich Daten aus bestehenden Systemen mit Kafka Connect importieren und exportieren. Es eignet sich ideal für den Import ganzer Datenbanken, Berichte oder Metriken von Ihren Servern in Threads mit geringer Latenz. Kafka Connect bietet Konnektoren für verschiedene Datensysteme, die eine standardisierte Datenverwaltung ermöglichen. Ein weiterer Vorteil der Verwendung von Konnektoren gegenüber Eigenentwicklungen ist die standardmäßige Skalierbarkeit von Connect (mehrere Worker können gruppiert werden) und die automatische Fortschrittsverfolgung.
Es stehen zahlreiche Clients zur Verfügung, um über Ihre Anwendungen mit Kafka zu kommunizieren. Viele Programmiersprachen werden unterstützt, darunter Java, Scala, Python, .NET, C++, Go usw. Für Java und Scala ist außerdem die Clientbibliothek Kafka Streams verfügbar. Diese Bibliothek abstrahiert die internen Abläufe und ermöglicht Ihnen die einfache Verbindung zu einem Kafka-Server sowie den Empfang von Broadcast-Ereignissen.
Ergebnis
Dieser Artikel behandelt die Paradigmen des modernen Event-Stream-Ansatzes zur Daten- und Ereignisverarbeitung und seine Vorteile gegenüber traditionellen Datenkategorisierungsverfahren. Sie haben außerdem Apache Kafka als Event-Broker und sein Client-Ökosystem kennengelernt.









