









مقدمة
لقد اجتاحت DeepSeek R1 مجتمع الذكاء الاصطناعي والتعلم الآلي في الأسابيع الأخيرة، لسبب وجيه، بل وامتدت إلى العالم أجمع، مخلفةً آثارًا بالغة على الاقتصاد والسياسات. ويعود ذلك بشكل رئيسي إلى طبيعة مجموعة النماذج مفتوحة المصدر والتكلفة المنخفضة للغاية للتدريب، مما أظهر للمجتمع الأوسع أن تدريب نماذج الذكاء الاصطناعي SOTA لا يتطلب رأس مال أو بحثًا متخصصًا بقدر ما كان يُعتقد سابقًا.
في الجزء الأول من هذه السلسلة، قدّمنا نموذج DeepSeek R1 وشرحنا كيفية تشغيله باستخدام Olama. في هذه المتابعة، سنبدأ بتعمق أكثر في ما يجعل R1 مميزًا حقًا. سنركز على تحليل نموذج التعلم التعزيزي الفريد لمعرفة كيف يمكن تعزيز قدرات الاستدلال في نماذج التعلم العميق (LLMs) من خلال التعلم التعزيزي فقط، ثم سنتحدث عن كيفية دمج هذه التقنيات في نماذج أخرى مما يسمح لنا بمشاركة هذه القدرات مع الإصدارات الحالية. سنختتم بعرض توضيحي قصير لكيفية إعداد نماذج DeepSeek R1 وتشغيلها باستخدام نموذج GPU Droplets بنقرة واحدة.
المتطلبات الأساسية
- التعلم العميق: تغطي هذه المقالة مواضيع من المتوسطة إلى المتقدمة تتعلق بتدريب الشبكات العصبية والتعلم المعزز.
- حساب DigitalOcean: سنستخدم على وجه التحديد نموذج GPU Droplets من HuggingFace 1-Click من DigitalOcean لاختبار R1.
نظرة عامة على DeepSeek R1
هدف مشروع البحث DeepSeek R1 إلى إعادة بناء قدرات التفكير المنطقي الفعالة التي أظهرتها نماذج التفكير المنطقي القوية، وتحديدًا نموذج OpenAI's O1. ولتحقيق هذا الهدف، سعى الباحثون إلى تحسين عملهم الحالي، DeepSeek-v3-Base، باستخدام التعلم التعزيزي الصرف. وقد أدى ذلك إلى ظهور DeepSeek R1 Zero، الذي يُظهر أداءً ممتازًا في مقاييس التفكير المنطقي، ولكنه يفتقر إلى قدرات التفسير البشري، ويُظهر بعض السلوكيات غير العادية مثل خلط اللغات.
لتحسين هذه المشكلات، اقترحوا DeepSeek R1، الذي يتضمن كمية صغيرة من بيانات البداية الباردة وخط أنابيب تدريب متعدد المراحل. حقق R1 سهولة قراءة وتطبيق SOTA LLM من خلال ضبط نموذج DeepSeek-v3-Base بدقة على آلاف عينات بيانات البداية الباردة، ثم إجراء جولة أخرى من التعلم التعزيزي، متبوعة بضبط دقيق مُشرف على مجموعة بيانات الحجج، وأخيرًا الانتهاء بجولة أخيرة من التعلم التعزيزي. ثم طبقوا هذه التقنية على نماذج أخرى من خلال الإشراف على ضبطها الدقيق للبيانات المجمعة من R1.
ترقبوا نظرة أعمق على مراحل التطوير هذه، ومناقشة حول كيفية تحسين النموذج بشكل متكرر للوصول إلى إمكانيات DeepSeek R1.
برنامج تعليمي لـ DeepSeek R1 Zero
لإنشاء DeepSeek R1 Zero، النموذج الأساسي الذي طُوِّر منه R1، طبّق الباحثون التعزيز التعزيز مباشرةً على النموذج الأساسي دون أي بيانات SFT. يُطلق على نموذج التعزيز التعزيز الذي اختاروه اسم تحسين السياسة النسبية للمجموعة (GRPO). هذه العملية مُقتبسة من ورقة DeepSeekMath.
يُشبه نظام GRPO أنظمة التعلم المعزز المألوفة وغيرها، ولكنه يختلف عنها في جانب مهم واحد: فهو لا يستخدم نموذجًا حرجًا. بل يُقدّر GRPO خط الأساس من درجات المجموعة. يعتمد نظام نمذجة المكافآت على قاعدتين، تُكافئ كل منهما دقة القالب والتزامه بنمط مُحدد. تُشكّل المكافأة بعد ذلك مصدرًا لإشارات التدريب التي تُستخدم لتغيير اتجاه تحسين التعلم المعزز. يسمح هذا النظام القائم على القواعد لعملية التعلم المعزز بتحسين النموذج بشكل متكرر.

نموذج التدريب بحد ذاته عبارة عن صيغة مكتوبة بسيطة تُرشد النموذج الأساسي لاتباع تعليماتنا المحددة أعلاه. يقيس النموذج الاستجابات لمجموعة "الإعلانات" لكل خطوة من خطوات التعلم التعزيزي. "يُعدّ هذا إنجازًا هامًا، إذ يُبرز قدرة النموذج على التعلم والتعميم بفعالية من خلال التعلم التعزيزي وحده" (المصدر).
هذا التطور الذاتي للنموذج يُمكّنه من تطوير قدرات استدلالية قوية، تشمل التأمل الذاتي والتفكير في مناهج بديلة. ويتعزز ذلك بلحظة أثناء التدريب يُطلق عليها فريق البحث في النموذج "لحظة الإلهام". خلال هذه المرحلة، يتعلم DeepSeek-R1-Zero تخصيص وقت أطول للتفكير في المشكلة من خلال إعادة تقييم نهجه الأولي. لا يُعد هذا السلوك دليلاً على تنامي قدرات الاستدلال لدى النموذج فحسب، بل يُعد أيضًا مثالاً رائعاً على كيف يُمكن أن يُؤدي التعلم المُعزّز إلى نتائج غير متوقعة ومعقدة. (المصدر).
حقق DeepSeek R1 Zero أداءً ممتازًا في جميع الاختبارات، لكنه عانى كثيرًا من حيث سهولة القراءة والاستخدام مقارنةً ببرامج إدارة التعلم (LLM) المناسبة والسهلة الاستخدام. لذلك، اقترح فريق البحث DeepSeek R1 لتحسين النموذج بشكل أفضل للمهام التي تتطلب مهارات بشرية.
من DeepSeek R1 Zero إلى DeepSeek R1
للانتقال من DeepSeek R1 Zero غير المروض نسبيًا إلى DeepSeek R1 الأكثر وظيفية، قدم الباحثون عدة مراحل تدريبية.
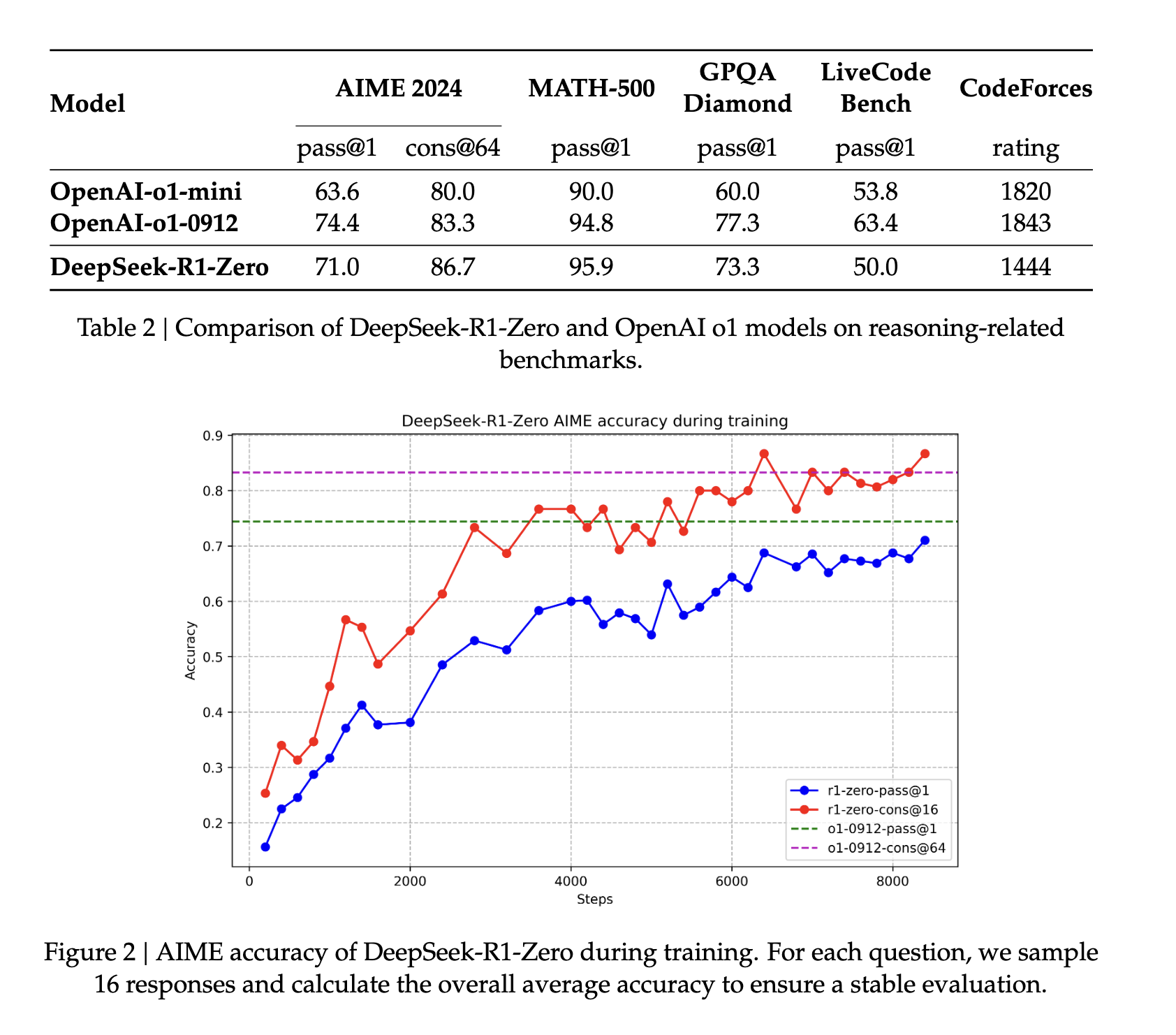
في البداية، تم ضبط قاعدة DeepSeek-v3-Base بدقة على آلاف من بيانات البداية الباردة قبل تشغيل نموذج التعلم المعزز نفسه المستخدم في DeepSeek R1 Zero، مع ميزة إضافية تتمثل في اتساق اللغة في المخرجات. عمليًا، تعمل هذه الخطوة على تحسين قدرات النموذج على التفكير المنطقي، وخاصةً في مهام التفكير المنطقي مثل البرمجة والرياضيات والعلوم والاستدلال المنطقي، والتي تتضمن مسائل محددة بدقة وحلولًا واضحة (المصدر).
بمجرد اكتمال مرحلة التعلم التعزيزي، يُستخدم النموذج الناتج لجمع بيانات جديدة للضبط الدقيق المُشرف عليه. «على عكس بيانات البداية الباردة، التي تُركز بشكل أساسي على التفكير المنطقي، تجمع هذه المرحلة بيانات من مجالات أخرى لتعزيز قدرات النموذج في الكتابة، وتقمص الأدوار، وغيرها من المهام العامة» (المصدر).
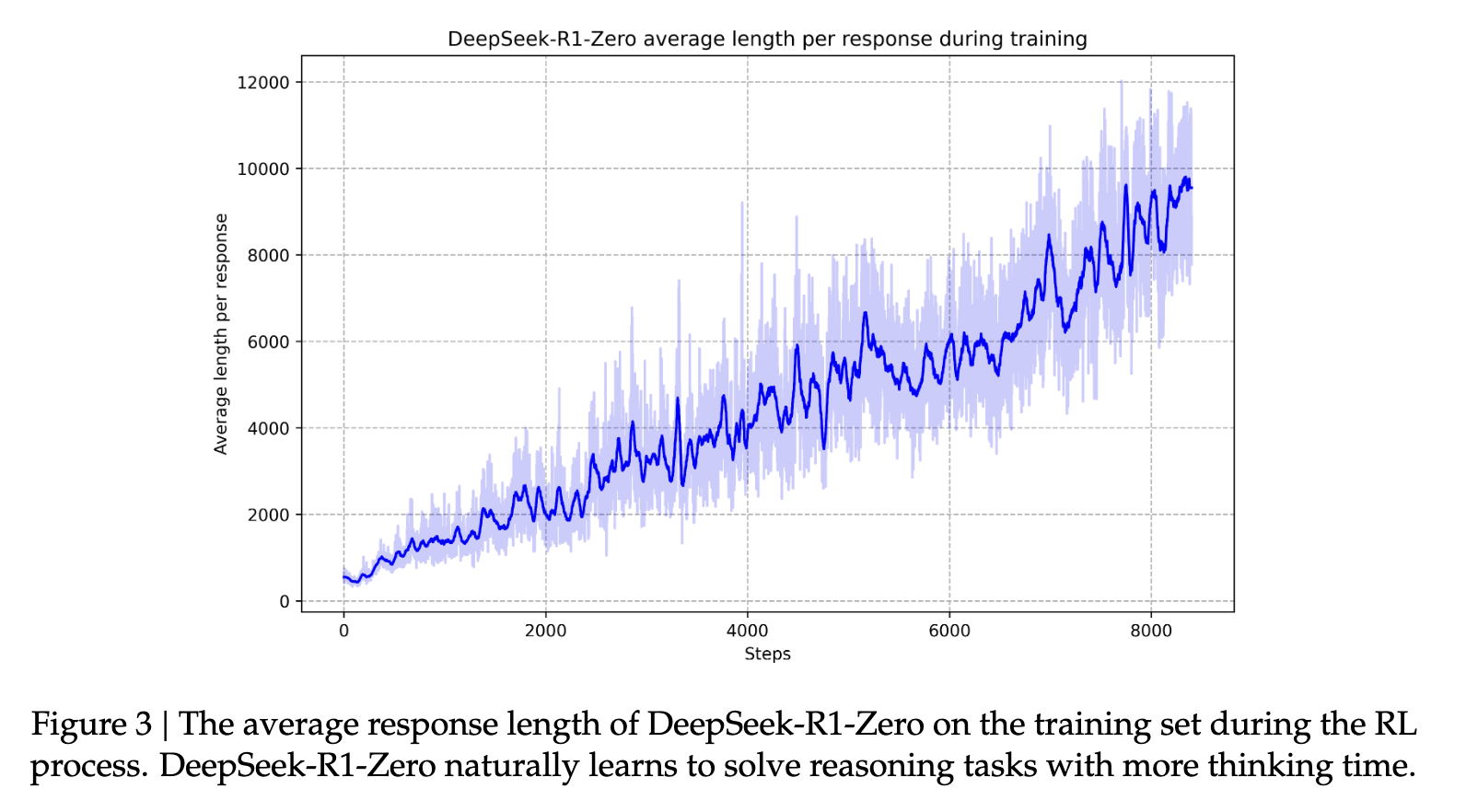
بعد ذلك، تُنفَّذ المرحلة الثانية من التعلم التعزيزي لتحسين "فائدة النموذج وسلامته، مع تحسين قدراته على التفكير المنطقي" (المصدر). من خلال تدريب النموذج بشكل أكبر على توزيعات سريعة متنوعة مع إشارات مكافأة، يُمكن تدريب نموذج يتفوق في التفكير المنطقي مع إعطاء الأولوية للفائدة والسلامة. هذا يُساعد النماذج على أن تُصبح "بشرية" في استجابتها، مما يُساعد النموذج على تطوير قدراته المنطقية المذهلة التي اشتهر بها. بمرور الوقت، تُساعد هذه العملية النموذج على تطوير سلاسل طويلة من التفكير المنطقي التي تُميزه.
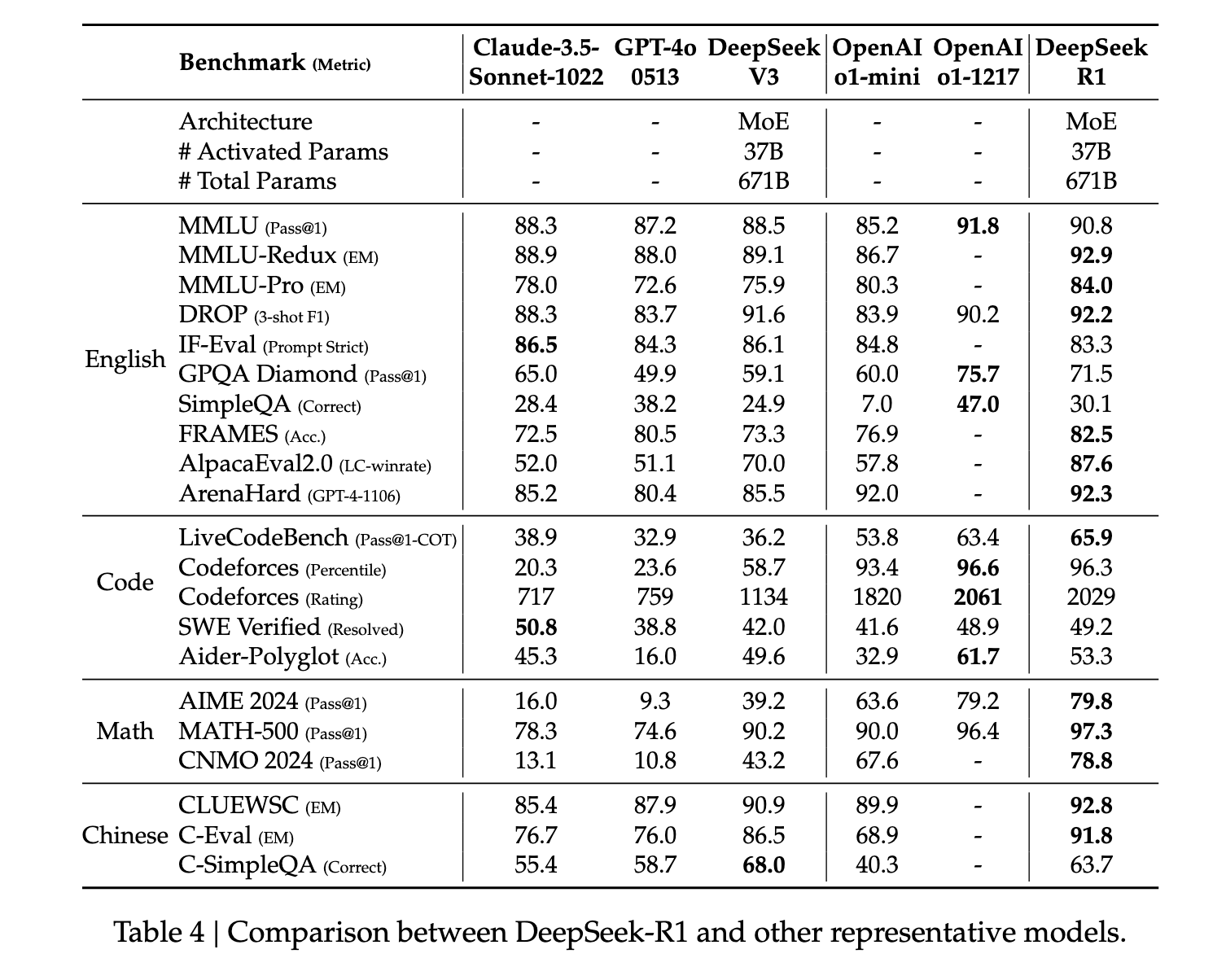
بشكل عام، يُظهر نموذج R1 أداءً متطورًا في مقاييس الاستدلال. في بعض المهام، مثل الرياضيات، تفوق حتى على معايير O1 المنشورة. بشكل عام، يُظهر النموذج أداءً قويًا جدًا في الأسئلة المتعلقة بالعلوم والتكنولوجيا والهندسة والرياضيات (STEM)، ويعزى ذلك أساسًا إلى التعلم التعزيزي واسع النطاق. بالإضافة إلى مواضيع العلوم والتكنولوجيا والهندسة والرياضيات (STEM)، يتميز النموذج بمهارة عالية في الإجابة على الأسئلة والمهام التعليمية والاستدلال المعقد. ويرى المؤلفون أن هذه التحسينات والقدرات المتزايدة تعود إلى تطور نماذج معالجة سلسلة الأفكار من خلال التعلم التعزيزي. تُستخدم بيانات سلسلة الأفكار الطويلة أثناء التعلم التعزيزي والضبط الدقيق لتشجيع النموذج على إنتاج نتائج أطول وأكثر تعمقًا.
نماذج DeepSeek R1 المقطرة
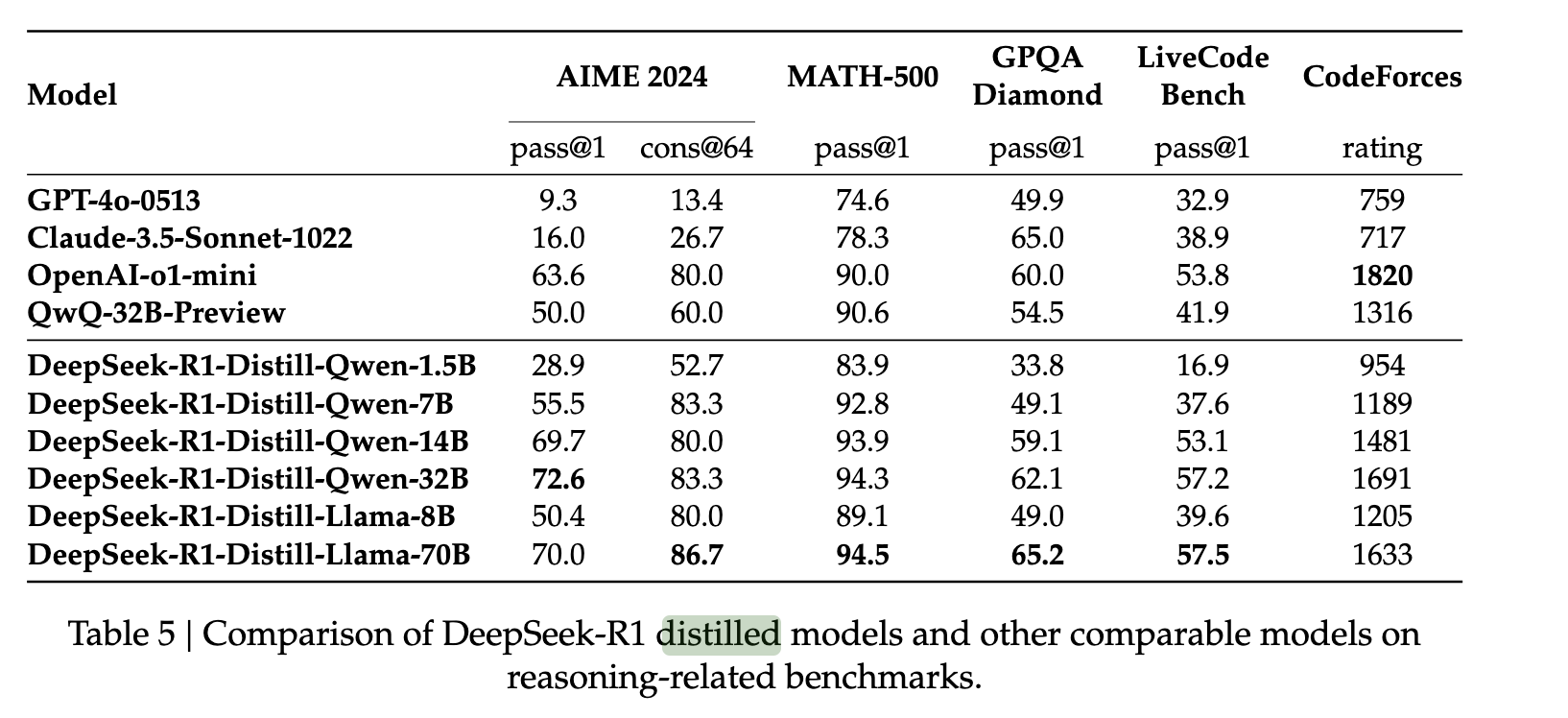 لتوسيع قدرات DeepSeek R1 لتشمل نماذج أصغر، جمع المؤلفون 800,000 نموذج من DeepSeek R1 واستخدموها لضبط نماذج مثل QWEN وLLAMA. ووجدوا أن طريقة التحليل البسيطة هذه سمحت بنقل قدرات R1 الاستدلالية إلى هذه النماذج الجديدة بنجاح كبير. وقد فعلوا ذلك دون أي تعلم تعزيز إضافي، مما يُظهر متانة استجابات النموذج الأصلي لعملية التحليل.
لتوسيع قدرات DeepSeek R1 لتشمل نماذج أصغر، جمع المؤلفون 800,000 نموذج من DeepSeek R1 واستخدموها لضبط نماذج مثل QWEN وLLAMA. ووجدوا أن طريقة التحليل البسيطة هذه سمحت بنقل قدرات R1 الاستدلالية إلى هذه النماذج الجديدة بنجاح كبير. وقد فعلوا ذلك دون أي تعلم تعزيز إضافي، مما يُظهر متانة استجابات النموذج الأصلي لعملية التحليل.
تشغيل DeepSeek R1 على GPU Droplets
إعداد DeepSeek R1 على GPU Droplets سهلٌ للغاية إذا كان لديك حساب DigitalOcean. تأكد من تسجيل الدخول قبل المتابعة.
نوفر الوصول إلى R1 كنموذج وحدة معالجة رسومات بنقرة واحدة. لتشغيله، ما عليك سوى فتح وحدة تحكم وحدة معالجة الرسومات، والانتقال إلى علامة التبويب "نماذج بنقرة واحدة" في نافذة اختيار النموذج، ثم تشغيل الجهاز!
من هناك، يُمكن الوصول إلى النموذج باتباع طريقتي HuggingFace أو OpenAI للتواصل معه. استخدم البرنامج النصي أدناه للتفاعل مع نموذجك باستخدام شيفرة بايثون.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)كبديل، أنشأنا مساعدًا شخصيًا مخصصًا يعمل على النظام نفسه. نوصي باستخدامه لهذه المهام لأنه يُختصر الكثير من تعقيد التفاعل المباشر مع النموذج من خلال عرض كل شيء في نافذة واجهة مستخدم رسومية أنيقة. لمزيد من المعلومات حول استخدام البرنامج النصي للمساعد الشخصي، يُرجى الاطلاع على هذا البرنامج التعليمي.
نتيجة
في الختام، يُعدّ R1 خطوةً للأمام لمجتمع تطوير برامج ماجستير الحقوق. وتَعِد عمليتهم بتوفير ملايين الدولارات من تكاليف التدريب، مع تقديم أداءٍ يُضاهي أو حتى يفوق نماذج المصادر المغلقة المتقدمة. سنراقب DeepSeek عن كثب لنرى كيف سيستمرون في النمو مع اكتساب نموذجهم شهرةً عالمية.









