









تينسور فلو
تينسور فلو إنها مكتبة للتعلم الآلي والتعلم العميق من جوجل، وقد استخدمتها جوجل في أماكن مختلفة لتوفير تجربة مستخدم أفضل لمستخدميها. على سبيل المثال، عندما تبدأ بحثًا، يُكمل جوجل نصك تلقائيًا.
يستخدم التعلم الآلي ثلاث فئات من الأشخاص: 1. الباحثون 2. علماء البيانات 3. المبرمجون. لتلبية احتياجات هؤلاء الأشخاص، أنشأ فريق Google Brain مكتبة TensorFlow. يمكن تشغيل TensorFlow على وحدات معالجة مركزية (CPU) ووحدات معالجة رسومية (GPU) مختلفة، ويمكن استخدامه مع لغات برمجة مختلفة مثل C++ وPython وJava. يمكن استخدام TensorFlow على الخوادم وحتى على الهواتف المحمولة.
تاريخ TensorFlow
ومع زيادة حجم البيانات، بدأ التعلم العميق يتفوق على خوارزميات التعلم العميق، وتوصلت جوجل إلى أنها يمكن أن تعزز خدماتها باستخدام هذه الشبكات العصبية العميقة وبدأت في بناء إطار عمل يسمى TensorFlow والذي يمكن أن يساعد المطورين والباحثين على العمل معًا على نماذج الذكاء الاصطناعي في وقت واحد.
عندما أصبح المشروع متطورًا بدرجة كافية وقابلًا للتوسع، تم إصداره للعامة في عام 2015. ومع ذلك، لم يتم إصدار الإصدار المستقر حتى عام 2017.
الميزة المهمة لـ TensorFlow هي أنه مفتوح المصدر ومرخص من Apache، ما يتيح لك استخدامه وتعديله ونشر توزيعك الخاص بسهولة. بل يمكنك حتى ربح المال منه دون الحاجة إلى الدفع لـ Google. .
هندسة TensorFlow
تتكون بنية TensorFlow من ثلاثة أجزاء: 1. معالجة البيانات مسبقًا 2. بناء النموذج 3. تدريب النموذج وتقديره. سبب تسمية TensorFlow بهذا الاسم هو استقباله مصفوفات متعددة الأبعاد كمدخلات، وأسماؤها هي موتر وبعد ذلك يمكنك تشغيل سلسلة من الرسوم البيانية للعمليات على بياناتك، والتي هي مخطط انسيابي نعم.
أين يتم ذلك؟
هناك مرحلتان لاستخدام هذه المكتبة:
مرحلة التطوير: هناك وقت تقوم فيه بتدريب النموذج، وهذه المرحلة عادة تتم على الكمبيوتر المحمول أو النظام الخاص بك.
مرحلة التنفيذ: بمجرد اكتمال التدريب، يمكنك تشغيل النموذج الخاص بك في أي مكان، من أجهزة الكمبيوتر المكتبية إلى الخوادم وحتى الهواتف المحمولة.
وبالتالي، يمكن تدريب النموذج وتشغيله على أجهزة مختلفة.
بالإضافة إلى استخدام وحدات المعالجة المركزية (CPU)، يمكنك أيضًا تشغيل TensorFlow على وحدات معالجة الرسومات (GPU).
في حسابات المصفوفة، نظرًا لأن نفس المشغل يتم إجراؤه على كمية كبيرة من المعلومات، فإن هذا النوع من الحسابات متوافق مع بنية وحدات معالجة الرسوميات، كما اكتشفه باحثو ستانفورد في أواخر عام 2010.
نقطة أخرى هي أن هذه المكتبة مكتوبة بلغة C++، لذا فهي سريعة جدًا. بالطبع، يمكنك استخدامها مع لغات أخرى، مثل بايثون.
الميزة المهمة لـ TensorFlow هي TensorBoard، التي تسمح لك برؤية ما يفعله TensorFlow.
مكونات TensorFlow
الموتر
الموتر هو مصفوفة من مصفوفات ذات أبعاد N، يمكنها تمثيل أنواع مختلفة من المعلومات. تحمل كل قيمة في الموتر معلومات من نفس الشكل.
يمكن أن تكون الموترات مدخلاً أو مخرجاً لعملية حسابية.
الرسم البياني
في TensorFlow، تُنفَّذ جميع العمليات داخل رسم بياني. كل رسم بياني هو مجموعة من العمليات الحسابية التي تُنفَّذ بالتتابع. تُعرف كل عملية حسابية باسم عقدة عملية، وهي متصلة ببعضها البعض.
الآن لماذا الرسم البياني؟
- يمكن تشغيله على أنظمة مختلفة.
- يمكن حفظ الرسم البياني لاستخدامه لاحقًا.
- يتم إجراء كافة العمليات الحسابية في الرسم البياني عن طريق ربط المتجهات معًا.
- باختصار، في الرسوم البيانية، كل حافة هي قيمة (موتر) وكل عقدة هي عامل (مثل الجمع).
لماذا يعتبر TensorFlow مشهورًا؟
يُعد TensorFlow الأفضل لأنه مصمم للاستخدام العام، ويستخدم واجهات برمجة تطبيقات (APIs) قابلة للاستخدام على نطاقات مختلفة مع بنى التعلم العميق مثل RNN وCNN. ولأنه يعتمد على الحوسبة البيانية، فإنه يتمتع بالقدرة على تصور الشبكات العصبية داخل TensorBoard، وهو أمر مفيد جدًا لتصحيح الأخطاء. وبشكل عام، صُمم TensorFlow لضمان قابلية التوسع أثناء النشر.
والخبر السار هو أنه يتمتع بأكبر مجتمع بين أطر التعلم العميق المختلفة على GitHub.
كم عدد الخوارزميات التي يدعمها TensorFlow؟
- الانحدار الخطي: tf.estimator.LinearRegressor
- التصنيف: tf.estimator.LinearClassifier
- التصنيف العميق: tf.estimator.DNNClassifier
- مسح التعلم العميق والعميق: tf.estimator.DNNLinearCombinedClassifier
- انحدار شجرة التعزيز: tf.estimator.BoostedTreesRegressor
- تصنيف الشجرة المعززة: tf.estimator.BoostedTreesClassifier
بعض الأمثلة البسيطة
- 12استيراد numpy كـ np
- استيراد tensorflow كـ tf
في السطرين أعلاه، قمنا باستيراد مكتبات numpy وtensorflow.
في هذا المثال، نريد ضرب X_1 وX_2. أولًا، علينا إنشاء الرسم البياني ثم تشغيل جلسة TensorFlow لحساب النتيجة.
دعونا نبدأ.
الخطوة 1: تعريف المتغير
الخطوة الأولى هي إنشاء عقدتي الإدخال X_1 وX_2. في TensorFlow، نحتاج إلى تحديد نوع العقدة التي سننشئها، وهنا نختار نوع العنصر النائب.
العنصر النائب:
يقوم هذا النوع بتعيين قيمة جديدة للموتر في كل مرة نقوم فيها بإجراء عملية حسابية.
- X_1 = tf.placeholder(tf.float32، الاسم = “X_1”)
- X_2 = tf.placeholder(tf.float32، الاسم = “X_2”)
كما ترى، أدخلنا نوع هذه العقدة كـ float واسمها كاسم متغير.
الخطوة 2: تحديد الحساب
- 1الضرب = tf.multiply(X_1, X_2, الاسم = “ضرب”)
باستخدام الخط أعلاه، نقوم بإنشاء رأس يعمل كمشغل لمشغل الضرب.
ما هو مدخل الرؤوس التي نريد ضربها وأطلقنا عليه اسم الضرب.
لقد قمنا الآن بإنشاء الرسم البياني الأول لدينا.
الخطوة 3: تنفيذ العملية
لتنفيذ العملية، نحتاج إلى إنشاء جلسة. تُنشأ هذه الجلسة باستخدام tf.Session() وتُنفَّذ عند استخدام الأمر run.
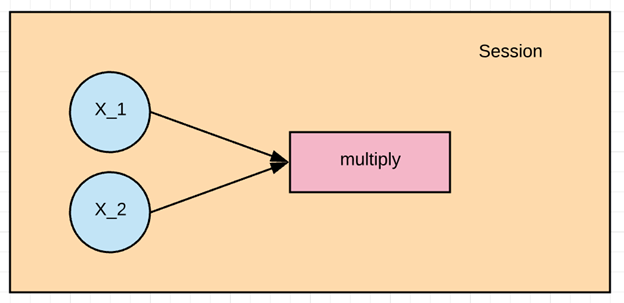
عند إجراء عملية الضرب، نحتاج إلى إدخال قيمتي الموترين x1 وx2. يتم ذلك بتعيين feed_dict. في هذا المثال، نُعيّن القيم من 1 إلى 3 إلى x1، ومن 4 إلى 6 إلى x2. ونطبع النتيجة.
- X_1 = tf.placeholder(tf.float32، الاسم = “X_1”)
- X_2 = tf.placeholder(tf.float32، الاسم = “X_2”)
- 1الضرب = tf.multiply(X_1, X_2, الاسم = “ضرب”)
- مع tf.Session() كجلسة:
- النتيجة = جلسة.تشغيل(ضرب، feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- طباعة (النتيجة)
- [ 4. 10. 18.]
طرق مختلفة لاستيراد البيانات إلى TensorFlow
حسنًا، إحدى الخطوات الأولى قبل تدريب النموذج هي استيراد البيانات، والتي لها وضعان:
- إدخال البيانات إلى ذاكرة الوصول العشوائي (RAM): هناك طريقة بسيطة لإدخال البيانات إلى مجموعة من الذاكرة، على سبيل المثال، عن طريق كتابة سطر من التعليمات البرمجية في بايثون.
- استخدام خط أنابيب بيانات TensorFlow: يحتوي TensorFlow على مجموعة من واجهات برمجة التطبيقات (APIs) التي تساعدك على استقبال البيانات، وإجراء سلسلة من العمليات عليها، ثم تغذيتها إلى خوارزميتك. هذه الطريقة فعّالة للغاية، خاصةً عندما تكون البيانات ضخمة جدًا. على سبيل المثال، الصور ضخمة ولا تتسع لذاكرة الوصول العشوائي (RAM). في هذه الحالة، يتولى خط أنابيب البيانات إدارة ذاكرة الوصول العشوائي (RAM).
السؤال الآن هو أي واحد نستخدم؟
إذا كانت بياناتك أقل من 10 جيجابايت، يمكنك بسهولة استخدام الطريقة الأولى، على سبيل المثال، مكتبة pandas الشهيرة. أما إذا كان لديك 30 جيجابايت من البيانات وذاكرة الوصول العشوائي (RAM) لديك 12 جيجابايت، فلا يمكنك استخدام هذه الطريقة، بل يجب عليك الانتقال إلى واجهة برمجة تطبيقات خط الأنابيب. يقوم خط الأنابيب بتجميع البيانات، وتُدخل كل دفعة فيه وتُستخدم لتعلم النموذج. يتيح لك استخدام خط الأنابيب استخدام المعالجة المتوازية، مما يعني أن TensorFlow يمكنه تدريب النموذج على عدة وحدات معالجة مركزية (CPU) مختلفة في الوقت نفسه.
باختصار، إذا كانت بياناتك صغيرة، فقم بتحميلها بالكامل إلى ذاكرة الوصول العشوائي (RAM)، على سبيل المثال باستخدام pandas. أما إذا كنت ترغب في استخدام وحدات معالجة مركزية متعددة، فاستخدم خط أنابيب TensorFlow.
إنشاء خط أنابيب في TensorFlow
الخطوة 1) إنشاء البيانات
نقوم بإنشاء رقمين عشوائيين باستخدام مكتبة numpy.
- 123استيراد numpy كـ np
- x_input = np.random.sample((1,2))
- طباعة (x_input)
- 1[[0.8835775 0.23766977]]
الخطوة 2) إنشاء عنصر نائب
في هذه الخطوة، نقوم بإنشاء عنصر نائب يسمى X على شكل مصفوفة تحتوي على عنصرين من نوع float.
- باستخدام عنصر نائب #
- x = tf.placeholder(tf.float32، الشكل = [1،2]، الاسم = 'X')
الخطوة 3: إنشاء مجموعة البيانات
في هذه المرحلة، نحتاج إلى تحديد مجموعة البيانات التي سنضع فيها قيمة العنصر النائب x.
- 1tf.data.Dataset.from_tensor_slices
- 1مجموعة البيانات = tf.data.Dataset.from_tensor_slices(x)
الخطوة 4: بناء خط الأنابيب
في هذه الخطوة، نحتاج إلى تهيئة خط الأنابيب. الخطوة الأولى هي إنشاء مُكرِّر لتكرار البيانات. باستخدام دالة get_next، نحصل على القيمة التالية. في هذا المثال، لدينا دفعة تحتوي على قيمتين فقط.
- 12المُكرر = dataset.make_initializable_iterator()
- get_next = iterator.get_next()
الخطوة 5: قم بإجراء الحساب
في الخطوة الأخيرة، نقوم بتشغيل جلسة يكون مدخلها عبارة عن مُكرر وقيم إدخال تم إنشاؤها بواسطة numpy، ولكل منها نطبع قيمتها.
- مع tf.Session() كجلسة:
- # قم بتغذية العنصر النائب بالبيانات
- جلسة.تشغيل(المُهيئ، feed_dict={ x: x_input })
- طباعة(الجلسة.تشغيل(الحصول على التالي))
- 1[0.8835775 0.23766978]
ملخص
TensorFlow هي أشهر مكتبة للتعلم العميق، يُمكنك استخدامها لبناء أي إطار عمل للتعلم العميق. طوّرت Google Brain هذا المشروع لسد الفجوة بين فرق البحث وفرق التطوير، وتستخدمه Google في جميع مشاريعها تقريبًا. من أهم أسباب استخدام TensorFlow سهولة التوسع أثناء النشر. يُمكن استخدام TensorFlow من خوادم قوية إلى هواتف Android وiOS.
يعمل TensorFlow في جلسة، حيث يتم تعريف كل جلسة بواسطة رسم بياني بحسابات مختلفة.
كمثال بسيط في TensorFlow، عملية الضرب هي كما يلي:
1. تعريف المتغير
- X_1 = tf.placeholder(tf.float32، الاسم = “X_1”)
- X_2 = tf.placeholder(tf.float32، الاسم = “X_2”)
2. تعريف الحساب
- 1الضرب = tf.multiply(X_1, X_2, الاسم = “ضرب”)
3. تنفيذ العمليات
- مع tf.Session() كجلسة:
- النتيجة = جلسة.تشغيل(ضرب، feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- طباعة (النتيجة)
الممارسة الشائعة في TensorFlow هي إنشاء خط أنابيب لتحميل البيانات إلى ذاكرة الوصول العشوائي (RAM)، ويتم ذلك من خلال الخطوات التالية:
1. إنشاء البيانات
- استيراد numpy كـ np
- x_input = np.random.sample((1,2))
- طباعة (x_input)
2. إنشاء عنصر نائب
- 1x = tf.placeholder(tf.float32، الشكل = [1،2]، الاسم = 'X')
3. تعريف طريقة مجموعة البيانات
- 1مجموعة البيانات = tf.data.Dataset.from_tensor_slices(x)
4. بناء خطوط الأنابيب
- 1المُكرر = dataset.make_initializable_iterator() get_next = iteraror.get_next()
5. تنفيذ البرنامج
- مع tf.Session() كجلسة:
- جلسة.تشغيل(المُهيئ، feed_dict={ x: x_input })
- طباعة(الجلسة.تشغيل(الحصول على التالي))









