









مقدمة
تخيل أنك قادر على التفاعل مع بياناتك غير المنظمة واستخراج معلومات قيّمة بسهولة. في عالم اليوم الذي يعتمد على البيانات، لا يزال استخراج رؤى قيّمة من المستندات غير المنظمة يُمثل تحديًا، مما يُعيق اتخاذ القرارات والابتكار. في هذا البرنامج التعليمي، سنتعرف على التضمينات، ونستكشف استخدام أمازون أوبن سيرش كقاعدة بيانات متجهة، وندمج إطار عمل Langchain مع نماذج اللغة الكبيرة (LLMs) لبناء موقع ويب مُدمج فيه روبوت محادثة مُتخصص في معالجة اللغة الطبيعية (NLP). سنستعرض أساسيات نماذج اللغة الكبيرة لاستخراج رؤى قيّمة من مستند غير منظم بمساعدة نموذج لغة كبير مفتوح المصدر. بنهاية هذا البرنامج التعليمي، ستكون قد اكتسبت فهمًا شاملًا لكيفية الحصول على رؤى قيّمة من المستندات غير المنظمة، وستستخدم المهارات اللازمة لاستكشاف وابتكار حلول مماثلة قائمة على الذكاء الاصطناعي الكامل.
المتطلبات الأساسية
- يجب أن يكون لديك حساب AWS نشط. إذا لم يكن لديك حساب، يمكنك التسجيل عبر موقع AWS الإلكتروني.
- تأكد من تثبيت واجهة سطر أوامر AWS (CLI) على جهازك المحلي، ويجب تهيئتها بشكل صحيح باستخدام بيانات الاعتماد المطلوبة والمنطقة الافتراضية. يمكنك تهيئتها باستخدام أمر aws configure.
- نزّل وثبّت Docker Engine. اتبع تعليمات التثبيت الخاصة بنظام التشغيل لديك.
ماذا سنبني؟
في هذا المثال، سنحاول محاكاة مشكلة تواجهها العديد من الشركات. معظم بيانات اليوم غير مُهيكلة، بل هي بالأحرى غير مُهيكلة، وتأتي على شكل نصوص صوتية ومرئية، ومستندات PDF وWord، وأدلة، وملاحظات ممسوحة ضوئيًا، ونصوص من مواقع التواصل الاجتماعي، وغيرها. سنستخدم نموذج Flan-T5 XXL كمقياس للمستوى المطلوب. يُمكن لهذا النموذج إنشاء مُلخصات وأسئلة وأجوبة من نصوص غير مُهيكلة. تُظهر الصورة أدناه بنية وحدات البناء المختلفة.

دعونا نبدأ بالأساسيات.
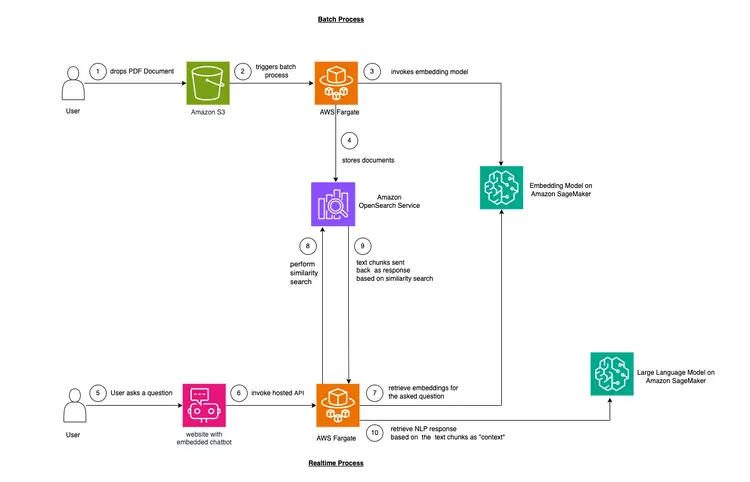
سنستخدم تقنية تُسمى التعلم السياقي لإضافة سياق خاص بالمجال أو الحالة إلى برنامج ماجستير إدارة الأعمال (LLM). في هذه الحالة، لدينا دليل PDF غير مُهيكل لسيارة نريد إضافته كسياق للبرنامج، ونريد من البرنامج الإجابة على أسئلة حول هذا الدليل. الأمر بهذه البساطة! هدفنا هو تطويره من خلال إنشاء واجهة برمجة تطبيقات (API) آنية تستقبل الأسئلة وترسلها إلى نظامنا الخلفي، ويمكن الوصول إليها عبر روبوت محادثة مفتوح المصدر مُدمج في الموقع. سيُمكّننا هذا البرنامج التعليمي من بناء تجربة مستخدم متكاملة واكتساب فهم أعمق للمفاهيم والأدوات المختلفة خلال العملية.
- الخطوة الأولى لتوفير التعلم النصي هي استيعاب مستند PDF وتحويله إلى أجزاء نصية، وإنشاء تمثيلات متجهية لهذه الأجزاء النصية تسمى "التضمينات"، وأخيرًا تخزين هذه التضمينات في قاعدة بيانات متجهية.
- تمكننا قواعد بيانات المتجهات من إجراء "عمليات بحث مماثلة" ضد تضمينات النصوص التي تخزنها.
- يوفر Amazon SageMaker JumpStart قوالب حلول نشر بنقرة واحدة لإعداد البنية التحتية للنماذج مفتوحة المصدر المُدرَّبة مسبقًا. سنستخدم Amazon SageMaker JumpStart لنشر نموذجي التضمين ونموذج اللغات الكبيرة.
- Amazon OpenSearch هو محرك بحث وتحليل يمكنه البحث عن أقرب الجيران للنقاط في مساحة متجهة، مما يجعله مناسبًا كقاعدة بيانات متجهة.
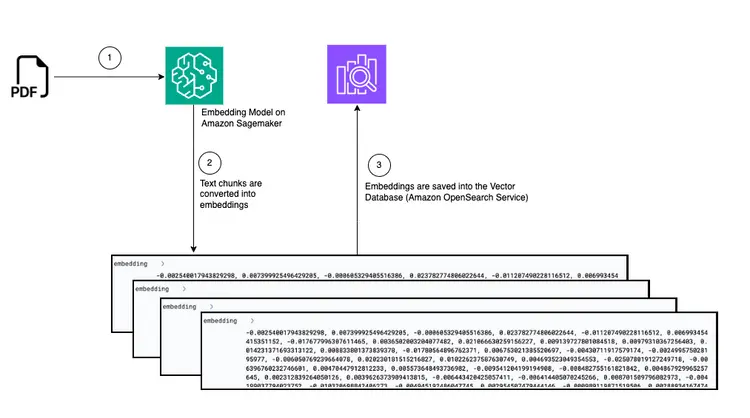
الرسم البياني: تحويل من PDF إلى تضمينه في قاعدة بيانات المتجهات
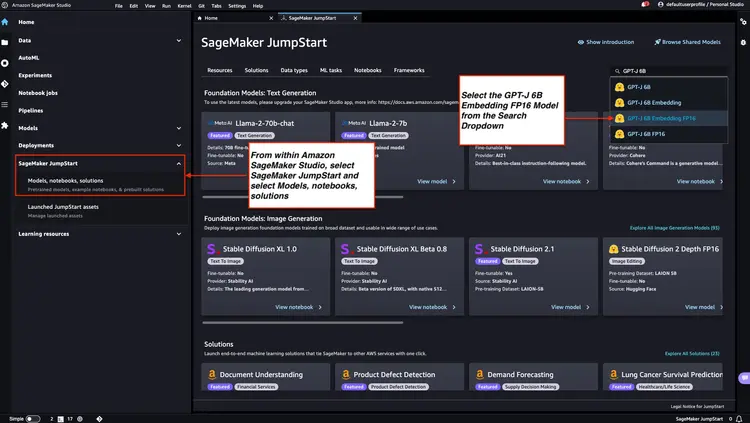
الخطوة 1 - نشر نموذج التضمين GPT-J 6B FP16 باستخدام Amazon SageMaker JumpStart
اتبع الخطوات المذكورة في وثائق Amazon SageMaker - افتح قسم JumpStart واستخدمه لتشغيل عقدة Amazon SageMaker JumpStart من القائمة الرئيسية لبرنامج Amazon SageMaker Studio. حدد "النماذج، دفاتر الملاحظات، الحلول"، ثم حدد نموذج التضمين GPT-J 6B Embedding FP16 كما هو موضح في الصورة أدناه. ثم انقر على "نشر" وسيتولى Amazon SageMaker JumpStart إعداد البنية التحتية لنشر هذا النموذج المُدرَّب مسبقًا في بيئة SageMaker.
الخطوة 2 - نشر Flan T5 XXL LLM باستخدام Amazon SageMaker JumpStart
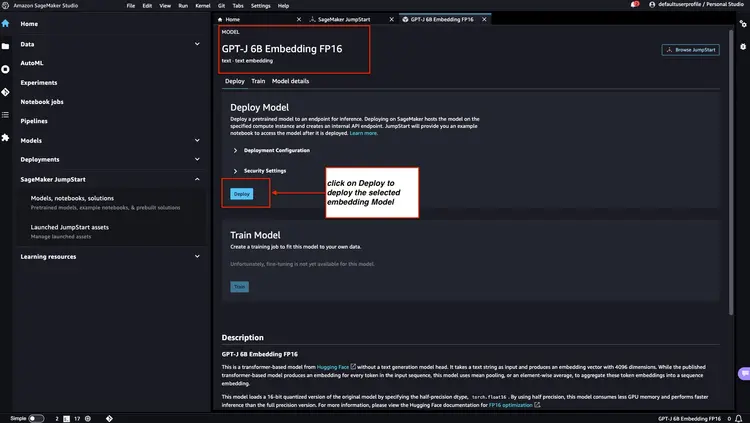
بعد ذلك، في Amazon SageMaker JumpStart، حدد Flan-T5 XXL LLM، ثم انقر فوق "نشر" لبدء إعداد البنية الأساسية التلقائي ونشر نقطة نهاية النموذج في بيئة Amazon SageMaker.
الخطوة 3 - التحقق من حالة نقاط نهاية النموذج المنشورة
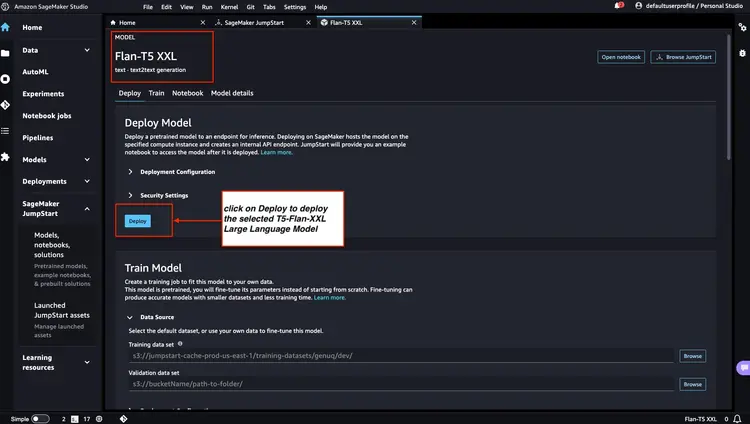
نتحقق من حالة نقاط نهاية النموذج المنشورة من الخطوتين 1 و2 في وحدة تحكم Amazon SageMaker، ونسجل أسماء نقاط النهاية الخاصة بها، حيث سنستخدمها في الكود. هكذا تبدو وحدة التحكم بعد نشر نقاط نهاية النموذج.
الخطوة 4 - إنشاء مجموعة البحث المفتوحة في أمازون
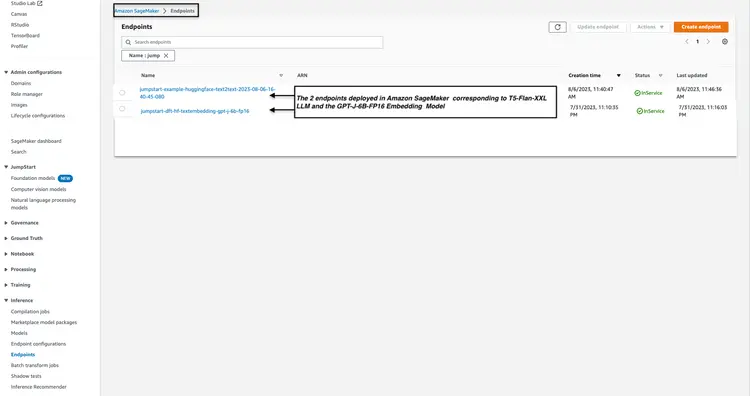
Amazon OpenSearch هي خدمة بحث وتحليل تدعم خوارزمية k-Nearest Neighbors (kNN). تُعد هذه الإمكانية بالغة الأهمية لعمليات البحث القائمة على التشابه، وتُمكّننا من استخدام OpenSearch بفعالية كقاعدة بيانات متجهة. لمزيد من الاستكشاف ومعرفة إصدارات Elasticsearch/OpenSearch التي تدعم إضافة kNN، يُرجى مراجعة الرابط التالي: وثائق إضافة k-NN.
نحن نستخدم AWS CLI لنشر ملف قالب AWS CloudFormation من موقع GitHub. البنية التحتية/opensearch-vectordb.yaml سوف نستخدم الأمر aws. إنشاء كومة معلومات سحابية قم بتنفيذ الأمر التالي لإنشاء مجموعة بحث أمازون المفتوح. يجب استبدال قيمك قبل تنفيذ الأمر. اسم المستخدم و كلمة المرور دعونا نفعل ذلك.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> الخطوة 5 - إنشاء سير عمل التقاط المستندات وتضمينها
في هذه الخطوة، سننشئ خط أنابيب استيعاب ومعالجة مُصمم لقراءة مستند PDF عند وضعه في حاوية Amazon Simple Storage Service (S3). سيُنفِّذ هذا الخط الأنابيب المهام التالية:
- استخراج النص من مستند PDF.
- تحويل أجزاء النص إلى تضمينات (تمثيلات متجهة).
- احفظ التضمينات في البحث المفتوح في Amazon.
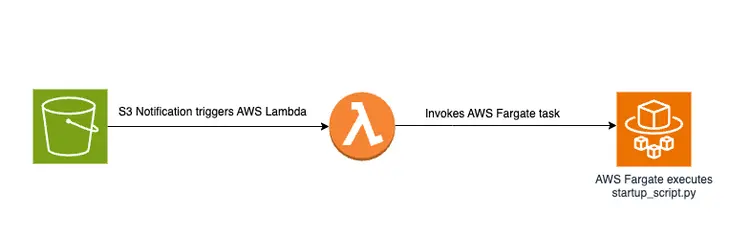
سيؤدي وضع ملف PDF في حاوية S3 إلى تشغيل سير عمل قائم على الأحداث يتضمن مهمة AWS Fargate. ستكون هذه المهمة مسؤولة عن تحويل النص إلى تضمينات وإدراجها في Amazon Open Search.
نظرة عامة تخطيطية
فيما يلي رسم تخطيطي يوضح خط أنابيب نقل المستندات لتخزين مقتطفات النصوص المضمنة في قاعدة بيانات متجه Amazon OpenSearch:
نص بدء التشغيل وبنية الملف
المنطق الرئيسي في الملف إنشاء-التضمينات-الحفظ-في-vectordb\startup_script.py يقع هذا البرنامج النصي Python في ملف startup_script.pyيُنفِّذ البرنامج النصي عدة مهام تتعلق بمعالجة المستندات، وتضمين النصوص، وإدراجها في مجموعة أمازون للبحث المفتوح. يُنزِّل البرنامج النصي مستند PDF من حزمة أمازون S3، ثم يُقسِّم المستند المُنزَّل إلى أجزاء نصية أصغر. لكل جزء، يُرسَل محتوى النص إلى نقطة نهاية نموذج التضمين GPT-J 6B FP16 المُستخدمة في أمازون SageMaker (المُسترجَع من متغير البيئة TEXT_EMBEDDING_MODEL_ENDPOINT_NAME) لإنشاء تضمينات نصية. تُوضَع التضمينات المُنشأة في فهرس أمازون للبحث المفتوح مع معلومات أخرى. يسترد البرنامج النصي معلمات التكوين والتحقق من الصحة من متغيرات البيئة، ويجعلها متسقة عبر البيئات. صُمِّم البرنامج النصي ليعمل بشكل موحد في حاوية Docker.
إنشاء ونشر صورة Docker
بعد فهم الكود في ملف startup_script.py، نقوم ببناء Dockerfile من المجلد إنشاء-التضمينات-الحفظ-في-vectordb سنرفع الصورة إلى سجل حاويات Amazon Elastic Container Registry (Amazon ECR). سجل حاويات Amazon Elastic Container Registry (Amazon ECR) هو سجل حاويات مُدار بالكامل، يوفر استضافة عالية الأداء، مما يسمح لنا بنشر صور التطبيقات وعناصرها بشكل موثوق في أي مكان. سنستخدم واجهة سطر أوامر AWS وواجهة سطر أوامر Docker لبناء صورة Docker ورفعها إلى Amazon ECR. في جميع الأوامر التالية، استبدله برقم حساب AWS الصحيح.
استرداد رمز المصادقة ومصادقة عميل Docker على السجل في AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com قم ببناء صورة Docker الخاصة بك باستخدام الأمر التالي.
docker build -t save-embedding-vectordb .
بمجرد اكتمال البناء، قم بوضع علامة على الصورة حتى نتمكن من دفع الصورة إلى هذا المستودع:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
قم بتشغيل الأمر التالي لدفع هذه الصورة إلى مستودع Amazon ECR الجديد:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
بمجرد تحميل صورة Docker إلى مستودع Amazon ECR، يجب أن تبدو مثل الصورة التالية:
إنشاء البنية الأساسية لسير عمل تضمين ملفات PDF المستند إلى الأحداث
يمكننا استخدام واجهة سطر أوامر AWS (AWS CLI) لإنشاء حزمة CloudFormation لسير عمل قائم على الأحداث باستخدام المعلمات المُقدمة. يتوفر قالب CloudFormation في مستودع GitHub على الرابط التالي: البنية التحتية/fargate-embeddings-vectordb-save.yaml نحن بحاجة إلى تجاهل المعلمات لتتناسب مع بيئة AWS.
فيما يلي المعلمات الرئيسية التي يجب تحديثها في الأمر إنشاء مجموعة معلومات aws السحابية وقد جاء فيه:
- BucketName: تمثل هذه المعلمة دلو Amazon S3 حيث سنسقط مستندات PDF.
- VpcId وSubnetId: تحدد هذه المعلمات المكان الذي سيتم فيه تشغيل مهمة Fargate.
- ImageName: هذا هو اسم صورة Docker في Amazon Elastic Container Registry (ECR) لـ save-embedding-vectordb.
- TextEmbeddingModelEndpointName: استخدم هذه المعلمة لتوفير اسم نموذج التضمين الذي تم نشره في Amazon SageMaker في الخطوة 1.
- VectorDatabaseEndpoint: حدد عنوان نقطة النهاية لنطاق Amazon OpenSearch.
- VectorDatabaseUsername وVectorDatabasePassword: هذه المعلمات مخصصة لبيانات الاعتماد المطلوبة للوصول إلى مجموعة Amazon Open Search التي تم إنشاؤها في الخطوة 4.
- VectorDatabaseIndex: تعيين اسم الفهرس في Amazon Open Search حيث يتم تخزين تضمينات مستندات PDF.
لتنفيذ إنشاء مجموعة CloudFormation، بعد تحديث قيم المعلمات، نستخدم أمر AWS CLI التالي:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualبإنشاء حزمة CloudFormation المذكورة أعلاه، نُنشئ حاوية S3 ونُنشئ إشعارات S3 تُشغّل دالة Lambda. تُشغّل هذه الدالة بدورها مهمة Fargate. تُنشئ مهمة Fargate حاوية Docker بالملف ملف startup-script.py تنفيذ مسؤول عن إنشاء التضمينات في Amazon OpenSearch ضمن فهرس OpenSearch جديد يسمى دليل السيارة إنها.
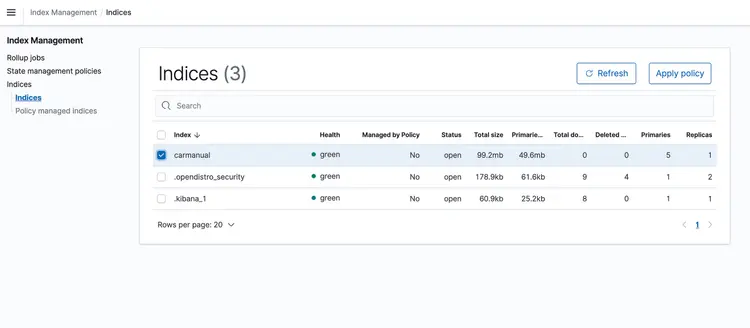
اختبار مع عينة PDF
بعد تشغيل حزمة CloudFormation، أضِف ملف PDF يُمثل دليل الجهاز إلى حزمة S3. نزّلتُ دليل الجهاز المتوفر هنا. بعد انتهاء تشغيل خط أنابيب النقل القائم على الأحداث، يجب أن تحتوي مجموعة Amazon Open Search على الملف التعريفي التالي: دليل السيارة مع التضمينات الموضحة أدناه.
الخطوة 6 - تنفيذ واجهة برمجة تطبيقات الأسئلة والأجوبة في الوقت الفعلي مع دعم Llm Text
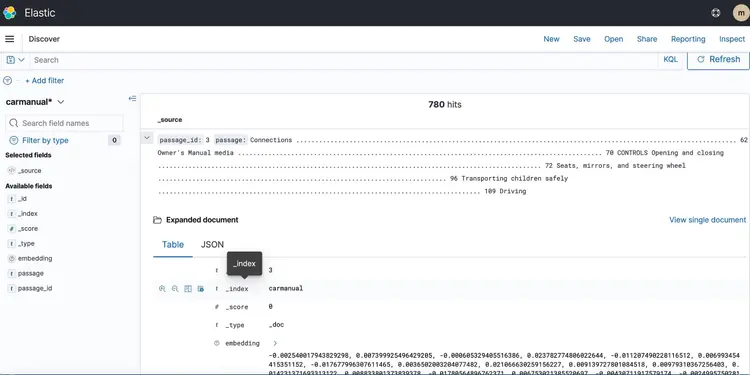
بعد أن أدرجنا نصنا في قاعدة بيانات متجهية مدعومة بـ Amazon Open Search، لننتقل إلى الخطوة التالية. هنا، سنستخدم إمكانيات T5 Flan XXL LLM لتوفير إجابات فورية حول دليل سيارتنا.
نستخدم البيانات المُضمَّنة المُخزَّنة في قاعدة بيانات المتجهات لتوفير سياق لبرنامج LLM. يُمكِّن هذا السياق برنامج LLM من فهم الأسئلة المتعلقة بدليل سيارتنا والإجابة عليها بفعالية. ولتحقيق ذلك، سنستخدم إطار عمل يُسمى LangChain، والذي يُبسِّط تنسيق المكونات المختلفة اللازمة لنظام الأسئلة والأجوبة الفوري والنصي الذي صممته LLM.
تُصوِّر التضمينات المُخزَّنة في قاعدة بيانات متجهات معاني الكلمات وعلاقاتها، وتُتيح لنا إجراء حسابات بناءً على أوجه التشابه الدلالي. بينما تُنشئ التضمينات تمثيلات متجهية لمقاطع نصية لالتقاط المعاني والعلاقات، يتخصص برنامج T5 Flan LLM في إنشاء إجابات ذات صلة بالسياق بناءً على السياق المُضاف إلى الطلبات والاستعلامات. الهدف هو مطابقة أسئلة المستخدم مع مقاطع نصية من خلال إنشاء تضمينات للأسئلة، ثم قياس مدى تشابهها مع التضمينات الأخرى المُخزَّنة في قاعدة بيانات المتجهات.
من خلال تمثيل مقتطفات النصوص واستعلامات المستخدم كمتجهات، يُمكننا إجراء حسابات رياضية للبحث عن التشابه مع مراعاة السياق. لقياس التشابه بين نقطتي بيانات، نستخدم مقاييس المسافة في فضاء متعدد الأبعاد.
يوضح الرسم البياني أدناه سير عمل الأسئلة والأجوبة في الوقت الفعلي الذي توفره LangChain وبرنامج T5 Flan LLM الخاص بنا.
نظرة عامة بيانية على دعم الأسئلة والأجوبة في الوقت الفعلي من T5-Flan-XXL LLM
بناء واجهة برمجة التطبيقات
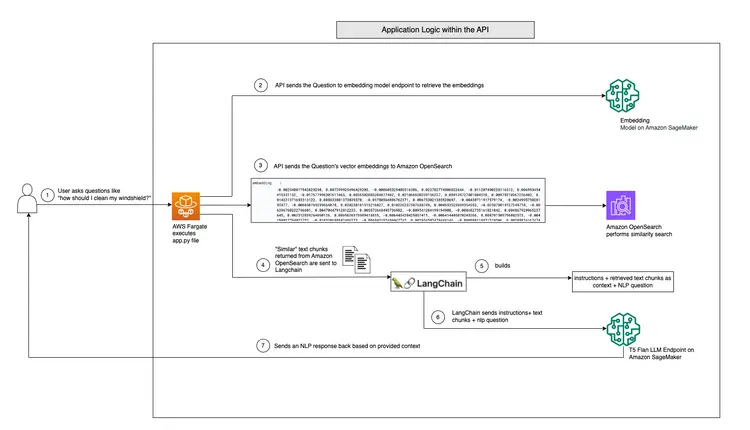
بعد أن استعرضنا سير عمل LangChain وT5 Flask LLM، لنبدأ بشرح شيفرة واجهة برمجة التطبيقات (API) التي تقبل أسئلة المستخدمين وتوفر إجابات مترابطة السياق. توجد واجهة برمجة التطبيقات للأسئلة والأجوبة الفورية هذه في مجلد RAG-langchain-questionanswer-t5-llm في مستودع GitHub، ومنطقها الأساسي موجود في ملف app.py. يُعرّف هذا التطبيق المُستند إلى Flask مسار /qa للإجابة على الأسئلة.
عندما يُرسل المستخدم استعلامًا إلى واجهة برمجة التطبيقات، فإنها تستخدم متغير البيئة TEXT_EMBEDDING_MODEL_ENDPOINT_NAME، وتُشير إلى نقطة نهاية Amazon SageMaker لتحويل الاستعلام إلى تمثيلات متجهية رقمية تُسمى تضمينات. تُجسّد هذه التضمينات المعنى الدلالي للنص.
تستفيد واجهة برمجة التطبيقات (API) أيضًا من Amazon OpenSearch لإجراء عمليات بحث متشابهة مع مراعاة السياق، مما يُمكّنها من جلب مقتطفات نصية ذات صلة من دليل عمل OpenSearch استنادًا إلى التضمينات المُستقاة من استعلامات المستخدم. بعد هذه الخطوة، تستدعي واجهة برمجة التطبيقات نقطة نهاية T5 Flan LLM، المُحددة بواسطة متغير البيئة T5FLAN_XXL_ENDPOINT_NAME، والمُستخدم أيضًا في Amazon SageMaker. تستخدم نقطة النهاية مقتطفات النصوص المُسترجعة من Amazon OpenSearch كسياق لتوليد الاستجابات. تُمثل هذه المقتطفات النصية المُستقاة من Amazon OpenSearch سياقًا قيّمًا لنقطة نهاية T5 Flan LLM، مما يسمح لها بتقديم استجابات مفيدة لاستفسارات المستخدم. يستخدم كود واجهة برمجة التطبيقات LangChain لتنظيم جميع هذه التفاعلات.
إنشاء ونشر صورة Docker لواجهة برمجة التطبيقات
بعد فهم الكود في ملف app.py، نبدأ ببناء ملف Dockerfile من مجلد RAG-langchain-questionanswer-t5-llm، ونرفع الصورة إلى Amazon ECR. سنستخدم واجهة سطر أوامر AWS وواجهة سطر أوامر Docker لبناء صورة Docker ورفعها إلى Amazon ECR. في جميع الأوامر التالية، استبدله برقم حساب AWS الصحيح.
استرداد رمز المصادقة ومصادقة عميل Docker على السجل في AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
قم ببناء صورة Docker باستخدام الأمر التالي.
docker build -t qa-container .
بمجرد اكتمال البناء، قم بوضع علامة على الصورة حتى نتمكن من دفع الصورة إلى هذا المستودع:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
قم بتشغيل الأمر التالي لدفع هذه الصورة إلى مستودع Amazon ECR الجديد:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
بمجرد تحميل صورة Docker إلى مستودع Amazon ECR، يجب أن تبدو مثل الصورة التالية:
إنشاء مجموعة CloudFormation لاستضافة نقطة نهاية واجهة برمجة التطبيقات
سنستخدم واجهة سطر أوامر AWS لإنشاء حزمة CloudFormation لمجموعة Amazon ECS التي تستضيف مهمة Fargate لعرض واجهة برمجة التطبيقات. يوجد قالب CloudFormation في مستودع GitHub على المسار Infrastructure/fargate-api-rag-llm-langchain.yaml. نحتاج إلى تجاوز المعلمات لتتوافق مع بيئة AWS. فيما يلي المعلمات الرئيسية التي يجب تحديثها في أمر aws cloudformation create-stack:
- DemoVPC: تحدد هذه المعلمة السحابة الخاصة الافتراضية (VPC) التي سيتم تشغيل الخدمة فيها.
- PublicSubnetIds: تتطلب هذه المعلمة قائمة بمعرفات الشبكة الفرعية العامة التي سيتم وضع موازن التحميل والمهام فيها.
- IMAGENAME: قم بتوفير اسم صورة Docker في Amazon Elastic Container Registry (ECR) لحاوية qa.
- TextEmbeddingModelEndpointName: حدد اسم نقطة النهاية لنموذج التضمينات المنشور في Amazon SageMaker في الخطوة 1.
- T5FlanXXLEndpointName: قم بتعيين اسم نقطة نهاية T5-FLAN المنشورة على Amazon SageMaker في الخطوة 2.
- VectorDatabaseEndpoint: حدد عنوان نقطة النهاية لنطاق Amazon OpenSearch.
- VectorDatabaseUsername وVectorDatabasePassword: هذه المعلمات مخصصة للبيانات الاعتمادية المطلوبة للوصول إلى مجموعة OpenSearch التي تم إنشاؤها في الخطوة 4.
- VectorDatabaseIndex: عيّن اسم الفهرس في Amazon OpenSearch حيث سيتم تخزين بيانات خدمتك. اسم الفهرس الذي استخدمناه في هذا المثال هو carmanual.
لتنفيذ إنشاء مجموعة CloudFormation، بعد تحديث قيم المعلمات، نستخدم أمر AWS CLI التالي:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualبعد تشغيل حزمة CloudFormation المذكورة أعلاه بنجاح، انتقل إلى وحدة تحكم AWS وافتح علامة تبويب "مخرجات CloudFormation" الخاصة بحزمة ecs-questionanswer-llm. ستجد في هذه العلامة المعلومات اللازمة، بما في ذلك نقطة نهاية واجهة برمجة التطبيقات (API). فيما يلي مثال على شكل المخرجات:
اختبار واجهة برمجة التطبيقات
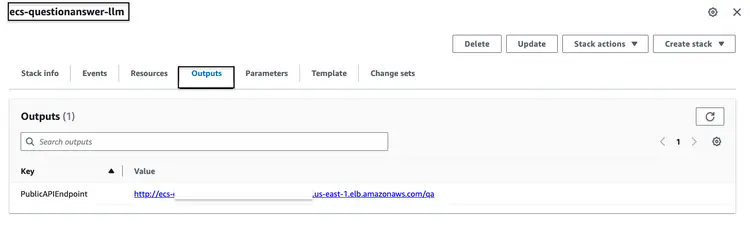
يمكننا اختبار نقطة نهاية API عبر أمر curl على النحو التالي:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
سوف نرى ردًا مثل الرد الموضح أدناه.
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
الخطوة 7 - إنشاء ونشر موقع ويب مع روبوت محادثة متكامل
ثم ننتقل إلى الخطوة الأخيرة في خط أنابيب التطوير الكامل، والذي يدمج واجهة برمجة التطبيقات (API) مع روبوت المحادثة المدمج في موقع ويب HTML. بالنسبة لهذا الموقع وروبوت المحادثة المدمج، فإن شيفرتنا المصدرية عبارة عن تطبيق Nodejs يتكون من ملف index.html مدمج مع ملف botkit.js مفتوح المصدر كربوت محادثة. لتسهيل الأمر، أنشأتُ ملف Dockerfile ووضعته مع الشيفرة في مجلد homegrown_website_and_bot. سنستخدم واجهة سطر أوامر AWS وواجهة سطر أوامر Docker لبناء نسخة Docker ورفعها إلى Amazon ECR لموقع الويب الأمامي. في جميع الأوامر التالية، استبدله برقم حساب AWS الصحيح.
استرداد رمز المصادقة ومصادقة عميل Docker على السجل في AWS CLI.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
قم ببناء صورة Docker باستخدام الأمر التالي:
docker build -t web-chat-frontend .
بمجرد اكتمال البناء، قم بوضع علامة على الصورة حتى نتمكن من دفع الصورة إلى هذا المستودع:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
قم بتشغيل الأمر التالي لدفع هذه الصورة إلى مستودع Amazon ECR الجديد:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
بعد إرسال صورة Docker الخاصة بالموقع الإلكتروني إلى مستودع ECR، نُنشئ حزمة CloudFormation للواجهة الأمامية بتشغيل ملف Infrastructure\fargate-website-chatbot.yaml. نحتاج إلى تجاوز المعلمات لتتوافق مع بيئة AWS. فيما يلي المعلمات الرئيسية التي يجب تحديثها في أمر aws cloudformation create-stack:
- DemoVPC: تحدد هذه المعلمة السحابة الخاصة الافتراضية (VPC) التي سيتم نشر موقع الويب الخاص بك عليها.
- PublicSubnetIds: تتطلب هذه المعلمة قائمة بمعرفات الشبكة الفرعية العامة حيث سيتم وضع موازن تحميل موقع الويب والمهام الخاصة بك.
- IMAGENAME: أدخل اسم صورة Docker في Amazon Elastic Container Registry (ECR) لموقع الويب الخاص بك.
- QUESTURL: حدد عنوان URL لنقطة نهاية واجهة برمجة التطبيقات التي تم نشرها في الخطوة 6. تنسيقها هو http:// إنه /qa.
لتنفيذ إنشاء مجموعة CloudFormation، بعد تحديث قيم المعلمات، نستخدم أمر AWS CLI التالي:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaالخطوة 8 - تحقق من مساعد الذكاء الاصطناعي Car Savvy
بعد بناء حزمة CloudFormation المذكورة أعلاه بنجاح، انتقل إلى وحدة تحكم AWS وافتح علامة تبويب "مخرجات CloudFormation" الخاصة بحزمة ecs-website-chatbot. في هذه العلامة، سنجد اسم DNS لموازن تحميل التطبيق (ALB) المرتبط بالواجهة الأمامية. فيما يلي مثال على شكل المُخرجات المُحتملة:
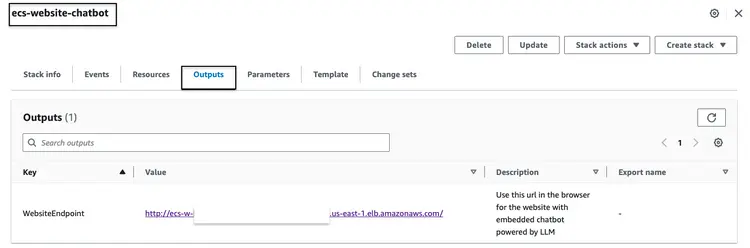
اتصل برابط نقطة النهاية في المتصفح لمشاهدة شكل الموقع. اطرح أسئلة بلغة طبيعية على روبوت المحادثة المدمج. من بين الأسئلة التي يمكننا طرحها: "كيف أنظف زجاج سيارتي الأمامي؟"، "أين أجد رقم تعريف المركبة؟"، "كيف أبلغ عن عيب في السلامة؟"“
ماذا بعد؟

نأمل أن يوضح لك ما سبق كيفية بناء خطوط أنابيب جاهزة للإنتاج لطلاب الماجستير في القانون، ودمجها مع روبوتات الدردشة الأمامية ومعالجة اللغة الطبيعية المدمجة. أخبرني بما ترغب بقراءته أيضًا حول استخدام تقنيات المصدر المفتوح، والتحليلات، والتعلم الآلي، وخدمات أمازون ويب (AWS)!
مع استمرار رحلتك التعليمية، أشجعك على التعمق أكثر في تقنيات التضمين، وقواعد بيانات المتجهات، وLangChain، والعديد من برامج ماجستير القانون الأخرى. تتوفر هذه التقنيات في Amazon SageMaker JumpStart، بالإضافة إلى أدوات AWS التي استخدمناها في هذا البرنامج التعليمي، مثل Amazon OpenSearch، وDocker Containers، وFargate. إليك بعض الخطوات التالية لمساعدتك على إتقان هذه التقنيات:
- Amazon SageMaker: مع تقدمك في استخدام SageMaker، تعرّف على الخوارزميات الأخرى التي يقدمها.
- البحث المفتوح في أمازون: تعرف على خوارزمية K-NN وخوارزميات المسافة الأخرى
- Langchain: LangChain هو إطار عمل مصمم لتبسيط إنشاء التطبيقات باستخدام LLM.
- التضمينات: التضمين هو تمثيل رقمي لقطعة من المعلومات، مثل النص، والمستندات، والصور، والصوت، وما إلى ذلك.
- Amazon SageMaker JumpStart: يوفر SageMaker JumpStart نماذج مفتوحة المصدر ومدربة مسبقًا لمجموعة واسعة من أنواع المشكلات لمساعدتك في البدء في استخدام التعلم الآلي.
مسح
- سجّل دخولك إلى واجهة سطر أوامر AWS. تأكد من تكوين واجهة سطر أوامر AWS بشكل صحيح مع الأذونات اللازمة لتنفيذ هذه الإجراءات.
- احذف ملف PDF من سلة Amazon S3 الخاصة بك بتنفيذ الأمر التالي. استبدل اسم السلة باسمها الأصلي، وعدّل مسار ملف PDF إذا لزم الأمر.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
احذف حزم CloudFormation. استبدل أسماء الحزم بأسماء حزم CloudFormation الحالية.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2نتيجة
في هذا البرنامج التعليمي، قمنا ببناء روبوت محادثة متكامل للأسئلة والأجوبة باستخدام تقنيات AWS وأدوات مفتوحة المصدر. دمجنا أمازون أوبن سيرش كقاعدة بيانات متجهة، ونموذج تضمين GPT-J 6B FP16، واستخدمنا Langchain مع شهادة ماجستير في القانون. يستخرج روبوت المحادثة رؤى من مستندات غير منظمة.









